python之集合深浅copy文件操作函数初识
Posted 独孤。。。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python之集合深浅copy文件操作函数初识相关的知识,希望对你有一定的参考价值。
本节内容:集合、深浅copy、文件操作、函数初识
1.小知识点补充
2.编码二
3.集合
4.深浅copy
5.文件操作
6.函数的初识
1、小知识点补充
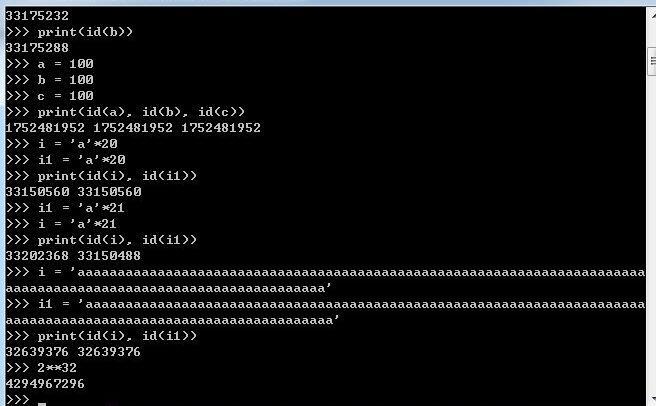
1.1 小数据池====str、int
小数据池存在的意义就是节省内存
节省内存,位多个变量开辟一个共享空间(str和int)
int:-5--256

int======>他们公用一个内存
字符串的内存换位的条件
1、不能含有特殊字符
2、单个元素*int不能超过21
2、编码二
2.1 二进制和程序的对照关系
ascii:数字、字母、特殊字符
字节:8位表示一个字节
字符: 你看到的最小单位
abc: a就是一个字符
中国: "中"就是一个字符
a:0000 1011

1、 不同编码之间的二进制对应关系互不通用,不能互相识别(对应的密码本不一样)
2、对于文件的存储和传输不能使用unicode(太占内存)
2.2 数据类型
=======python 3版本 str bool int dist tuple list ======


字符串的存储过程(unicode=====>非unicode====>存储/传输)
bytes:内部编码方式:(非unicode,utf-8,gbk.gb2312...)
str : 内部编码方式unicode
字母:
str:表现形式:s1 = \'alex\'
内部编码:unicode
bytes:表现形式:s2 = b\'alex\'
内部编码:非unicode
中文:
str:表现形式:s1 = \'中国\'
内部编码:unicode
bytes:表现形式:b1 = b\'\\xe4\\xb8\\xad\\xe5\\x9b\\xbd\'
内部编码:非unicode
bytes 虽然具有str 类型所有的功能特性,但是bytes 处理中文展示的时候,是我们看不懂的,
所以这也是str还存在的意义下面是str和bytes 类型转化:
1.encode编码


s1 = \'alex\' b1 = s1.encode(\'utf-8\') print(b1) ===》输出 b\'alex\' b2 = s1.encode(\'gbk\') print(b2) ===》输出 b\'alex\'
2.decode 解码(你用什么方式编码的那么就是相应的方式解码)
s1 = \'alex\' # str ---> bytes encode 编码 b1 = s1.encode(\'utf-8\') print(b1) #bytes---> str decode 解码 s2 = b1.decode(\'utf-8\') print(s2) ===》输出 b\'alex\' alex s1 = \'alex\' b2 = s1.encode(\'gbk\') s3 = b2.decode(\'gbk\') print(b2) print(s3) ===>输出 b\'alex\' alex
【注意】utf-8和gbk 的英文部分引用的是ascall 码,在做英文的转化的时候可以混用(强烈不推荐),
但是在设计英文意外的数据类型的时候就会报错了具体展示如下:
s1 = \'alex\' b1 = s1.encode(\'utf-8\') s2 = b1.decode(\'gbk\') print(s2) ===》输出 alex s4 = \'中国\' b4 = s4.encode(\'utf-8\') print(b4) ===》输出 b\'\\xe4\\xb8\\xad\\xe5\\x9b\\xbd\' s5 = b4.decode(\'gbk\') print(s5) ===》输出 直接报错
考题:如何将代码中的utf-8=====>转化成gbk的代码格式
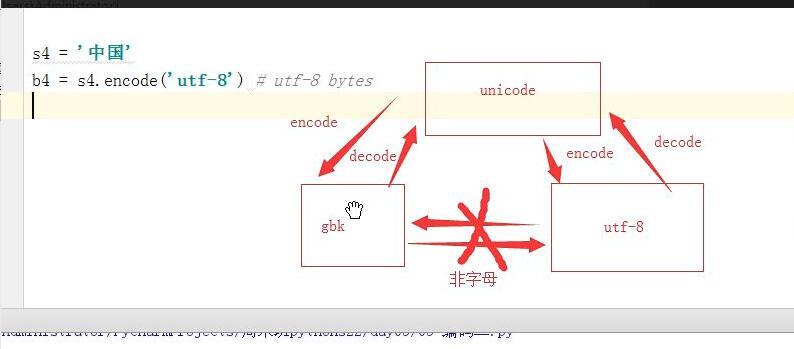
s4 = \'中国\' b4 = s4.encode(\'utf-8\') # utf-8 bytes print(b4) b6 = b4.decode(\'utf-8\').encode(\'gbk\') print(b6) ===》输出 b\'\\xe4\\xb8\\xad\\xe5\\x9b\\xbd\' b\'\\xd6\\xd0\\xb9\\xfa\'
3.集合
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。
以下是集合最重要的两点:
1、去重,把一个列表变成集合,就自动去重了。
2、关系测试,测试两组数据之前的交集、差集、并集等关系。
set1 = {\'alex\', \'wusir\', \'taibai\', \'alex\'}
set2 = {\'alex\', \'wusir\', \'taibai\', \'alex\',[1, 2, 3]}
print(set1)
print(set2)
===》输出
{\'alex\', \'taibai\', \'wusir\'}#去重
===》输出
set2报错
3.1 列表的去重:set
l1 = [1, 1, 2, 2, 3, 4, 4, 5]
print(list(set(l1)))
=====>输出
[1, 2, 3, 4, 5]
3.2 集合的增
set1 = {\'alex\', \'wusir\', \'ritian\', \'egon\', \'barry\'}
set1.add(\'文周\')
print(set1)
===》输出
{\'ritian\', \'alex\', \'egon\', \'barry\', \'wusir\', \'文周\'}
set1.update(\'abc\')
print(set1)
===》输出
{\'b\', \'egon\', \'ritian\', \'c\', \'barry\', \'wusir\', \'a\', \'alex\'}
3.3 集合的删
set1 = {\'alex\', \'wusir\', \'ritian\', \'egon\', \'barry\'}
set1.pop() #随机删除
print(set1)
===》输出
{\'barry\', \'ritian\', \'egon\', \'alex\'}
set1.remove(\'alex\') # 按照元素删除
set1.remove(\'alex1\') # 按照元素删除,没有会报错
print(set1)
===》输出
{\'wusir\', \'egon\', \'barry\', \'ritian\'}
set1.clear() #清空
print(set1) # set()
===》输出
set()
del set1 #删除列表
print(set1)
=====》输出
报错
3.4 集合的查
set1 = {\'alex\', \'wusir\', \'ritian\', \'egon\', \'barry\'}
for i in set1:
print(i)
====》输出
ritian
wusir
barry
egon
alex
3.5 集合的其他操作
3.5.1 交集(& 或者 intersection)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
print(set1 & set2)
print(set1.intersection(set2))
====>输出
{4, 5}
{4, 5}
3.5.2 并集(|或者union)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
print(set1 | set2)
print(set1.union(set2))
====>输出
{1, 2, 3, 4, 5, 6, 7, 8}
{1, 2, 3, 4, 5, 6, 7, 8}
3.5.3 差集(-或者difference)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
print(set1 - set2)
print(set1.difference(set2))
print(set2 - set1)
====》输出
{1, 2, 3}
{1, 2, 3}
{8, 6, 7}
3.5.4 反交集(^ 或者 symmetric_difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2) ===》# {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2))===》# {1, 2, 3, 6, 7, 8}
3.5.5 子集与超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。
====》输出
True
True
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
====》输出
True
True
3.5.6 frozenset不可变集合,让集合变成不可变类型。
set1 = {1, 2, 3}
print(frozenset(set1))
====》输出
frozenset({1, 2, 3})
4.深浅copy
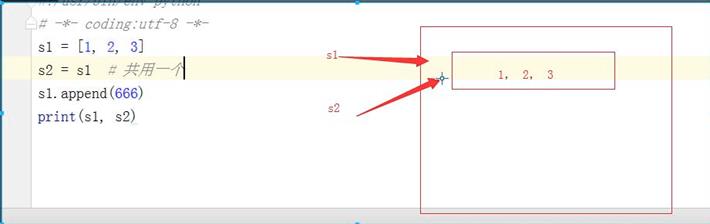
4.1 赋值运算补充,赋值运算中公用一个内存空间
s1 = [1, 2, 3] s2 = s1 # 共用一个 s1.append(666) print(s1, s2) ====>输出 [1, 2, 3, 666] [1, 2, 3, 666]
4.2 浅拷贝copy。
s1 = [1, 2, 3] s2 = s1.copy() s1.append(666) print(s1, s2) ====》输出 [1, 2, 3, 666] [1, 2, 3] s1 = [1, 2, 3,[11,22]] s2 = s1.copy() s1[-1].append(666) print(s1, s2) #[1, 2, 3, [11, 22, 666]] [1, 2, 3, [11, 22, 666]] print(id(s1), id(s2)) #38526216 38526920 print(id(s1[-1]), id(s2[-1])) #38526856 38526856 # 浅copy 第一层各自独立,从第二层开始,共用一个内存地址。
对于浅copy来说,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性。
4.3 深拷贝deepcopy。
import copy s1 = [1, 2, 3,[11,22]] s2 = copy.deepcopy(s1) s1.append(666) print(s1, s2) ====》输出 [1, 2, 3, [11, 22], 666] [1, 2, 3, [11, 22]] s1 = [1, 2, 3,[11,22]] s2 = copy.deepcopy(s1) s1[-1].append(666) print(s1, s2) ====》输出 [1, 2, 3, [11, 22, 666]] [1, 2, 3, [11, 22]]
对于深copy来说,两个是完全独立的,改变任意一个的任何元素(无论多少层),另一个绝对不改变。
4.4 切片 浅copy
s1 = [1, 2, 3, [11, 22]] s2 = s1[:] # s1.append(666) s1[-1].append(666) print(s1, s2) ====>输出 [1, 2, 3, [11, 22, 666]] [1, 2, 3, [11, 22, 666]]
5.文件操作
计算机系统分为:计算机硬件,操作系统,应用程序三部分。
我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及
到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统
把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操
作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
f1 = open(r\'d:/a.txt\', encoding=\'gbk\', mode=\'r\') print(f1.read()) f1.close() f1 = open(\'log1\', encoding=\'gbk\', mode=\'r\') print(f1.read()) f1.close() """ f1 文件句柄,f,file,file_hander,f_h.... open()调用的内置函数,内置函数调用的系统内部的open, 一切对文件进行的操作都是基于文件句柄f1. 执行流程: 1,打开文件,产生文件句柄。 f=open(\'a.txt\',\'r\',encoding=\'utf-8\') #默认打开模式就为r 2,对文件句柄进行操作。 data=f.read() 3,关闭文件句柄。 f.close()
5.1 常见报错
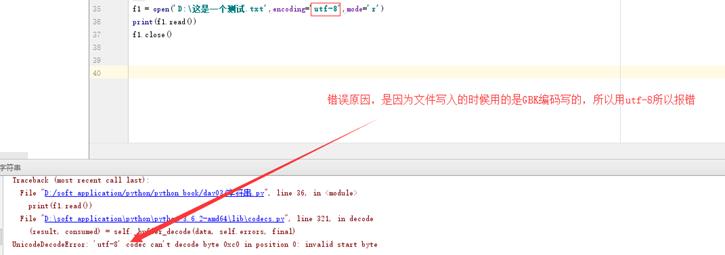

5.2 读 r
5.2.1 read() 全部读出来
f1 = open(\'log1\', encoding=\'utf-8\') content = f1.read() print(content) f1.close()
5.2.2 read(n) 读一部分
f1 = open(\'log1\', encoding=\'utf-8\') content = f1.read(3) print(content) f1.close()
5.2.3 rb模式
r 模式 read(n) n 按照字符读取。
rb 模式 read(n) n 按照字节读取。
f1 = open(\'log1\', mode=\'rb\') print(f1.read(3).decode(\'utf-8\')) f1.close()
5.2.4 readline() 按行读取
f1 = open(\'log1\', encoding=\'utf-8\') print(f1.readline()) print(f1.readline()) print(f1.readline()) f1.close()
5.2.5 readlines()多行读取
f1 = open(\'log1\', encoding=\'utf-8\') print(f1.readlines()) f1.close()
5.2.6 for 循环
f1 = open(\'log1\', encoding=\'utf-8\') for line in f1: print(line) f1.close()
5.2.7 r+ 读写 先读后写
f1 = open(\'log1\', encoding=\'utf-8\', mode=\'r+\') # print(f1.read()) # f1.write(\'666\') f1.write(\'a\') print(f1.read()) f1.close()
5.3 写 w
w 没有文件,新建文件写入内容
有原文件,先清空内容,在写入新内容。
f1 = open(\'log2\', encoding=\'utf-8\', mode=\'w\') f1.write(\'桃白白fdksagdfsa\') f1.close() #图片的读取及写入 f1 = open(\'1.jpg\', mode=\'rb\') content = f1.read() f2 = open(\'2.jpg\', mode=\'wb\') f2.write(content) f1.close() f2.close()
5.3.1 w+先写后读
f1 = open(\'log2\', encoding=\'utf-8\', mode=\'w+\') f1.write(\'两款发动机了\') f1.seek(0) print(f1.read()) f1.close()
5.4 追加 a
a没有文件,新建文件写入内容
f1 = open(\'log3\', encoding=\'utf-8\', mode=\'a\') # f1.write(\'alex 666\') f1.write(\'\\nalex 666\') f1.close()
5.4.1 a+
f1 = open(\'log3\', encoding=\'utf-8\', mode=\'a\') # f1.write(\'alex 666\') f1.write(\'\\nalex 666\') f1.close() #在后面追加
5.5 其他操作方法
readable 是否可读 writable 是否可写 f1.seek(12) # 任意调整 f1.seek(0,2) #光标调整到最后 f1.seek(0) #光标调整到开头 f1.tell() # 告诉光标的位置 f1.truncate(3) # 按照字节对原文件进行截取 必须在a 或 a+ 模式 ====================== f1 = open(\'log3\', encoding=\'utf-8\', mode=\'a+\') # f1.write(\'python22期\') # print(f1.read()) print(f1.readable()) print(f1.writable()) f1.close() ====================== f1 = open(\'log2\', encoding=\'utf-8\') f1.read() print(f1.tell()) print(f1.seek(0)) print(f1.seek(0,2)) f1.seek(12) # 任意调整 f1.seek(0,2) #光标调整到最后 f1.seek(0) #光标调整到开头 print(f1.tell()) # 告诉光标的位置 f1.close() ======================= f1 = open(\'log3\', encoding=\'utf-8\', mode=\'a+\') f1.truncate(3)