python—模块-re正则表达式
Posted 夜猫心理委员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python—模块-re正则表达式相关的知识,希望对你有一定的参考价值。
问题:从下面的文件中取出电话号

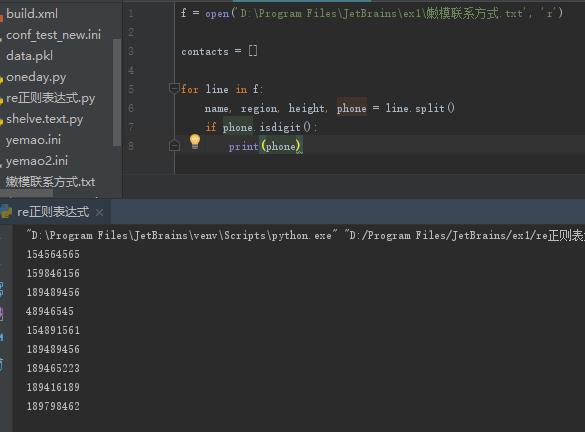
或者是下面这样:
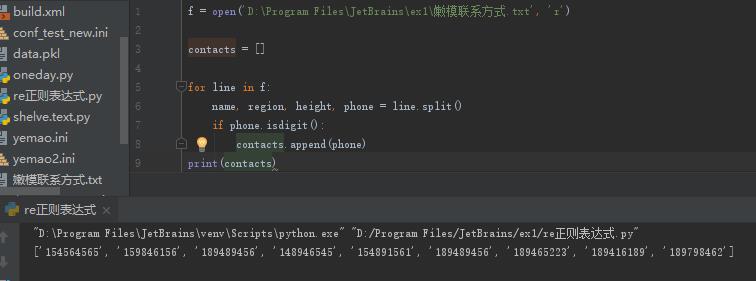
用正则表达式就可以简单一点儿,
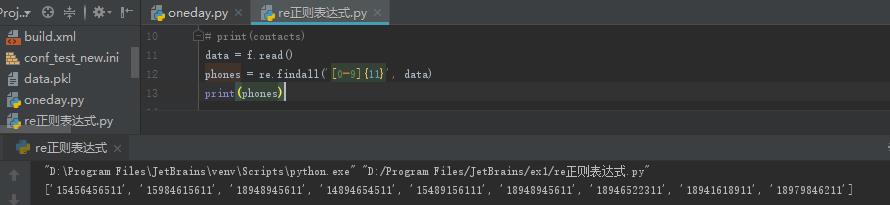
re模块
正则表达式就是字符串的匹配规则,在多数编程语言里都有相应的支持,python里对应的模块是re
常用的表达式规则
\'.\' 默认匹配除\\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 \'^\' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\\nabc\\neee",flags=re.MULTILINE) \'$\' 匹配字符结尾, 若指定flags MULTILINE ,re.search(\'foo.$\',\'foo1\\nfoo2\\n\',re.MULTILINE).group() 会匹配到foo1 \'*\' 匹配*号前的字符0次或多次, re.search(\'a*\',\'aaaabac\') 结果\'aaaa\' \'+\' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果[\'ab\', \'abb\'] \'?\' 匹配前一个字符1次或0次 ,re.search(\'b?\',\'alex\').group() 匹配b 0次 \'{m}\' 匹配前一个字符m次 ,re.search(\'b{3}\',\'alexbbbs\').group() 匹配到\'bbb\' \'{n,m}\' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果\'abb\', \'ab\', \'abb\'] \'|\' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果\'ABC\' \'(...)\' 分组匹配, re.search("(abc){2}a(123|45)", "abcabca456c").group() 结果为\'abcabca45\' \'\\A\' 只从字符开头匹配,re.search("\\Aabc","alexabc") 是匹配不到的,相当于re.match(\'abc\',"alexabc") 或^ \'\\Z\' 匹配字符结尾,同$ \'\\d\' 匹配数字0-9 \'\\D\' 匹配非数字 \'\\w\' 匹配[A-Za-z0-9] \'\\W\' 匹配非[A-Za-z0-9] \'\\s\' 匹配空白字符、\\t、\\n、\\r , re.search("\\s+","ab\\tc1\\n3").group() 结果 \'\\t\' \'(?P<name>...)\' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{\'province\': \'3714\', \'city\': \'81\', \'birthday\': \'1993\'}
>>> import re #. >>> re.search(\'.\',\'da854da\') <_sre.SRE_Match object; span=(0, 1), match=\'d\'> #^ >>> re.search(\'^a\',\'avcb\') <_sre.SRE_Match object; span=(0, 1), match=\'a\'> #或者 >>> re.match(\'av\',\'avcb\') <_sre.SRE_Match object; span=(0, 2), match=\'av\'> #或者 >>> re.search(\'\\Aab\',\'abc\') <_sre.SRE_Match object; span=(0, 2), match=\'ab\'> # $要求字符串以b结尾 >>> re.search(\'b$\',\'avcb\') <_sre.SRE_Match object; span=(3, 4), match=\'b\'> #如果是match,就是要求以b开头,并以b结尾,就只有一个字符 \'b\' #*匹配所有 >>> re.search(\'a*\',\'Alex\') <_sre.SRE_Match object; span=(0, 0), match=\'\'> >>> re.search(\'a*\',\'Alex\').group()#代表匹配了0次 \'\' >>> re.search(\'a*\',\'alex\') <_sre.SRE_Match object; span=(0, 1), match=\'a\'> >>> re.search(\'a*\',\'alex\').group() >>> re.search(\'a*\',\'aaaaalex\') <_sre.SRE_Match object; span=(0, 5), match=\'aaaaa\'>#代表匹配1次或多次 # \' |\' >>> re.search(\'alex|Alex\',\'alex\') <_sre.SRE_Match object; span=(0, 4), match=\'alex\'> >>> re.search(\'alex|Alex\',\'Alex\') <_sre.SRE_Match object; span=(0, 4), match=\'Alex\'> >>> re.search(\'[a|A]lex\',\'Alex\') <_sre.SRE_Match object; span=(0, 4), match=\'Alex\'> # (...)分组匹配 #分别取到alex 123,方法一 >>> re.search(\'[a-z]+[0-9]+\',\'alex123\') <_sre.SRE_Match object; span=(0, 7), match=\'alex123\'> >>> re.search(\'[a-z]+[0-9]+\',\'alex123\').group() \'alex123\' #第二种方法 >>> re.search(\'([a-z]+)([0-9]+)\',\'alex123\').groups() (\'alex\', \'123\') # \\d >>> re.search(\'\\d+\',\'alex231231\') <_sre.SRE_Match object; span=(4, 10), match=\'231231\'> >>> re.search(\'\\d+\',\'alex231231fds231\') <_sre.SRE_Match object; span=(4, 10), match=\'231231\'>#只能匹配一次,在遇到就不会管 了 # \\w >>> re.search(\'\\w+\',\'alex231231fds231\') <_sre.SRE_Match object; span=(0, 16), match=\'alex231231fds231\'> >>> re.search(\'\\w+\',\'alex2@#31231fds231\') <_sre.SRE_Match object; span=(0, 5), match=\'alex2\'> >>> re.search(\'\\w\',\'alex2@#31231fds231\') <_sre.SRE_Match object; span=(0, 1), match=\'a\'> # \\s >>> re.findall(\'\\s\',\'alex\\njack\\tdd\\rmack\') [\'\\n\', \'\\t\', \'\\r\'] #(?P<name>...)分组匹配 >>> re.search(\'(?P<province>\\d{3})(?P<city>\\d{3})(?P<born_year>\\d{4})\',s).groups() (\'130\', \'704\', \'2000\') >>> res.groupdict() {\'province\': \'130\', \'city\': \'704\', \'born_year\': \'2000\'}
re的匹配语法有以下几种
- re.match 从头开始匹配
- re.search 匹配包含
- re.findall 把所有匹配到的字符放到以列表中的元素返回
- re.split 以匹配到的字符当做列表分隔符
- re.sub 匹配字符并替换
- re.fullmatch 全部匹配
re.match(pattern, string, flags=0)
从起始位置开始根据模型去字符串中匹配指定内容,匹配单个
- pattern 正则表达式
- string 要匹配的字符串
- flags 标志位,用于控制正则表达式的匹配方式
#re.match >>> import re >>> s = \'abc1d3c\' >>> re.match(\'[0-9]\',s)# 从头开始匹配,匹配一个字符 >>> print(re.match(\'[0-9]\',s))#相当于函数,没有匹配到,就会返回None None >>> re.match(\'[0-9]\',\'1bdfd\') <_sre.SRE_Match object; span=(0, 1), match=\'1\'> >>> re.match(\'[0-9]\',\'115bdfd\') <_sre.SRE_Match object; span=(0, 1), match=\'1\'>
上面用match无法匹配到需要的字符,下面是search,这个是全局搜索,找到就返回
re.search(pattern, string, flags=0)
根据模型去字符串中匹配指定内容,匹配单个
#re.search >>> import re >>> s = \'abc1d3c\' >>> re.search(\'[0-9]\',s) <_sre.SRE_Match object; span=(3, 4), match=\'1\'># (3,4)是索引,指的是从3到4 >>> re.search(\'[0-9]\',s).group()#加上group就能拿到结果 \'1\'
所以正确的做法应该是线判断一下返回值没有,有的话再取
match_res = re.search(\'[0-9]\', s) if match_res: print(match_res.group())#拿到匹配结果
但是上面两种都不能把数字都拿到,所以用到findall
re.findall(pattern, string, flags=0)
match and search均用于匹配单值,即:只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall。
#re.findall >>> import re >>> re.findall(\'[0-9]\',s) [\'1\', \'3
其中,findall返回的是列表,而search返回的是对象
re.split(pattern, string, maxsplit=0, flags=0)
#re.split (以数字分开) >>> s = \'alex22jack23rian31\' >>> s.split() [\'alex22jack23rian31\'] >>> re.split(\'\\d\',s) [\'alex\', \'\', \'jack\', \'\', \'rian\', \'\', \'\'] >>> re.split(\'\\d+\',s) [\'alex\', \'jack\', \'rian\', \'\'] #和findall是相反的效果 >>> re.findall(\'\\d+\',s) [\'22\', \'23\', \'31\'] >>> s = \'alex22jack23rian31#mack-oldboy\' >>> re.split(\'\\d+|#|\',s)#根据数字或者#或者-分割 [\'alex\', \'jack\', \'rian\', \'\', \'mack-oldboy\'] >>> s = \'alex22jack23rian31|mack-oldboy\' >>> re.split(\'|\',s) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "D:\\Users\\10213\\Anaconda3\\lib\\re.py", line 212, in split return _compile(pattern, flags).split(string, maxsplit) ValueError: split() requires a non-empty pattern match. #希望以管道符分隔开,但是它本身就是一个语法,这时需要加一个\\ 就会当成字符串而不是语法 >>> re.split(\'\\|\',s) [\'alex22jack23rian31\', \'mack-oldboy\'] >>> s = \'alex22jack23rian31\\mack-oldboy\' >>> s \'alex22jack23rian31\\\\mack-oldboy\' >>> re.split(\'\\\\\\\\\',s) [\'alex22jack23rian31\', \'mack-oldboy\'] >>> s = \'9-2*5/3+7/3*99/4*29+10*58/14\' >>> s \'9-2*5/3+7/3*99/4*29+10*58/14\' >>> re.split(\'[-\\*/+]\',s) [\'9\', \'2\', \'5\', \'3\', \'7\', \'3\', \'99\', \'4\', \'29\', \'10\', \'58\', \'14\'] >>> re.split(\'[-\\*/+]\',s,maxsplit=2) [\'9\', \'2\', \'5/3+7/3*99/4*29+10*58/14\']
re.sub(pattern, repl, string, count=0, flags=0)
用于替换匹配的字符串
#re.sub >>> s = \'alex22jack23rian31\\mack-oldboy\' >>> re.sub(\'\\d+\',\'_\',s) \'alex_jack_rian_\\\\mack-oldboy\' >>> re.sub(\'\\d+\',\'_\',s,count=2) \'alex_jack_rian31\\\\mack-oldboy\'
re.fullmatch(pattern, string, flags=0)
整个字符串匹配成功就返回re object, 否则返回None
#re.fullmatch >>> re.fullmatch(\'alex\',\'alex123\') >>> re.fullmatch(\'alex124\',\'alex123\') >>> re.fullmatch(\'alex123\',\'alex123\') <_sre.SRE_Match object; span=(0, 7), match=\'alex123\'> >> re.fullmatch(\'\\w+@\\w+\\.(com|cn|edu)\',\'alex@oldboyedu.cn\') _sre.SRE_Match object; span=(0, 17), match=\'alex@oldboyedu.cn\'>
re.compile(pattern, flags=0)
#re.compile >>> re.compile(\'\\w+@\\w+\\.(com|cn|edu)\') re.compile(\'\\\\w+@\\\\w+\\\\.(com|cn|edu)\') #返回了一个对象 >>>pattern = re.compile(\'\\w+@\\w+\\.(com|cn|edu)\') #pattern是格式的意思 >>> pattern re.compile(\'\\\\w+@\\\\w+\\\\.(com|cn|edu)\') >>> pattern.fullmatch(\'alex@oldboyedu.cn\') <_sre.SRE_Match object; span=(0, 17), match=\'alex@oldboyedu.cn\'> #相当于把规则写好,然后给规则返回了一个对象,通过这个对象做#fullmatch,和先写fullmatch再写内容是一样的
Flags标志符
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- M(MULTILINE): 多行模式,改变\'^\'和\'$\'的行为
- S(DOTALL): 改变\'.\'的行为,make the \'.\' special character match any character at all, including a newline; without this flag, \'.\' will match anything except a newline.
- X(re.VERBOSE) 可以给你的表达式写注释,使其更可读,下面这2个意思一样
#re.I >>> re.search(\'a\',\'alex\') <_sre.SRE_Match object; span=(0, 1), match=\'a\'> >>> re.search(\'a\',\'Alex\') >>> re.search(\'a\',\'Alex\',re.I) <_sre.SRE_Match object; span=(0, 1), match=\'A\'>
#re.M >>> re.search(\'foo.$\',\'fool\\nfoo2\\n\') <_sre.SRE_Match object; span=(5, 9), match=\'foo2\'> >>> re.search(\'foo.$\',\'fool\\nfoo2\\n\',re.M) <_sre.SRE_Match object; span=(0, 4), match=\'fool\'> #不加M意思是不管有多少个换行符只看最后的,加上M就把它看成多行,取得是第一行的末尾
#re.S >>> re.search(\'.\',\'\\n\')#并没有匹配上 >>> re.search(\'.\',\'\\n\',re.S) <_sre.SRE_Match object; span=(0, 1), match=\'\\n\'>#匹配了任意字符
#re.X >>> re.search(\'. #text\',\'alex\',re.X) <_sre.SRE_Match object; span=(0, 1), match=\'a\'>
总结:
1.常用的公式
2.5种语法
以上是关于python—模块-re正则表达式的主要内容,如果未能解决你的问题,请参考以下文章