基于Python Requests的数据驱动的HTTP接口测试
Posted peter200-ok
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Python Requests的数据驱动的HTTP接口测试相关的知识,希望对你有一定的参考价值。
发表于:2017-8-30 11:56 作者:顾翔 来源:51Testing软件测试网原创
http://www.51testing.com/html/69/n-3720769-2.html
1、测试金字塔
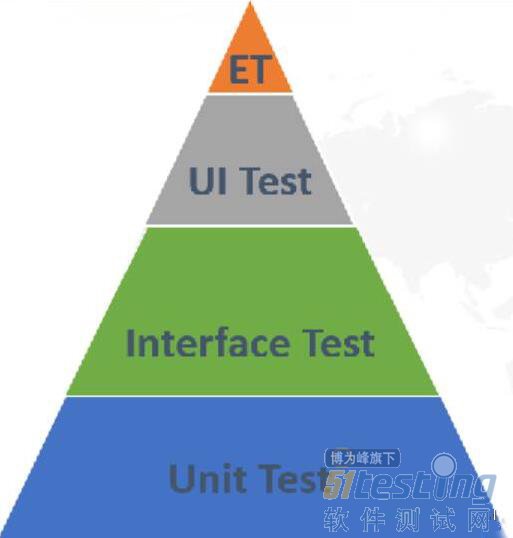
图 1软件测试金字塔
图 1是Main Cohn提出的软件测试金字塔,他认为作为一个测试工程师应该把大量的工作花在单元测试和接口测试,而其余的发在UI测试以及探索式测试。纵然,单元测试的优点很突出,它接近于代码本身,运行速度快,开发可以一边写产品代码一边写单元测试代码,一旦在单元测试中发现缺陷,可以马上找到对应的产品代码来进行修改。然而单元测试的缺点也很明显,就是你有多少产品代码,就要有相应的单元测试代码与它相对应,这样造成的结果是单元测试代码等于甚至超过与产品代码的数量,这也就是为什么单元测试在一般的中小型企业很难全面推广的原因。对于基于UI层面的测试由于需求变更,页面调整比较频繁,所以在许多企业,基于UI的自动化测试仅仅用于需求不带变化的核心功能的自动化,往往是一些冒烟测试用例。而基于两者之间的接口测试(Interface Test),基于代码量不是很多,变更比较少的优势下越来越得到各大企业的支持。
2、unittest
由于本文是介绍Django的,而Django是基于Python语言的,所以我们接下来介绍在这里我主要介绍基于Python Requests的软件接口测试。首先让我们来了解一下基于Python的unittest,unittest 原名为pytest,他是属于XUnit框架下的。先让我们来看一下一段产品代码。
Calculator.py
|
#!/usr/bin/env python
#coding:utf-8
class calculator:
def __init__(self, a, b):
self.a=int(a)
self.b=int(b)
def myadd(self):
return self.a+self.b
def mysubs(self):
return self.a-self.b
def mymultiply(self):
return self.a*self.b
def mydivide(self):
try:
return self.a/self.b
except ZeroDivisionError:
print ("除数不能为零")
return 9999999999999999
|
很显然这个代码实现的是加、减、乘、除四则运算的功能。类calculator有两个成员变量,self.a和self.b,myadd、mysubs、mymultiply、mydivide分别实现self.a+self.b、self.a-self.b、self.a*self.b、self.a/self.b四个功能,在mydivide中,如果被除数self.b为0,我们就进行对应的处理,打印"除数不能为零"的警告,然后返回一个很大的数:9999999999999999。现在让我们来看一看这段代码所对应的unittest框架的测试代码。
|
CalculatorTest.py
#!/usr/bin/env python
#coding:utf-8
import unittest
from Calculator import calculator
class calculatortest(unittest.TestCase):
def setUp(self):
print ("Test start!")
def test_base(self):
j=calculator(4,2)
self.assertEqual(j.myadd(),6)
self.assertEqual(j.mysubs(),2)
self.assertEqual(j.mymultiply(),8)
self.assertEqual(j.mydivide(),2)
def test_divide(self):
j=calculator(4,0)
self.assertEqual(j.mydivide(),9999999999999999)
def tearDown(self):
print ("Test end!")
if __name__==‘__main__‘:
#构造测试集
suite=unittest.TestSuite()
suite.addTest(calculatortest("test_base"))
suite.addTest(calculatortest("test_divide"))
#运行测试集合
runner=unittest.TextTestRunner()
runner.run(suite)
|
首先我们使用unittest测试框架必须先importunittest类,unittest类是Python自带的测试类,只要你安装了Python,这个类就自动安装上了。
然后我们引入被测试类:fromCalculator import calculator。
unittest的测试类参数必须为unittest.TestCase。
和其他XUnit测试框架一样,unittest也存在着一个初始化函数和清除函数,分别定义为def setUp(self):和def tearDown(self):,由于在这里没有具体实际性的操作我们仅仅在def setUp(self):函数中打印一个"Test start!"字符串;在def tearDown(self):函数中打印一个"Testend!"字符串。
unittest具体测试函数的函数名必须以test_开头,这个有点类似于JUnit3,j=calculator(4,2)先定义一个self.a =4和self.b = 2的类变量j,然后通过断言self.assertEqual()函数来验证是不是计算结果与预期结果一致。
在deftest_divide(self):函数中我们专门对被除数为0的情况进行了测试。
unittest的主函数为与其他主函数一样为if__name__==‘__main__‘:,先通过suite=unittest.TestSuite()来构造测试集,然后通过suite.addTest(calculatortest("test_base")),suite.addTest(calculatortest("test_divide"))把两个测试函数加进去,接下来通过runner=unittest.TextTestRunner(),runner.run(suite)来执行测试工作。
当许多测试文件需要批量运行的时候,我们可以进行如下操作:
1, 把这些测试文件的文件名定义成一个可以用正则函数匹配的模式,比如都以Test开始或结尾的.py文件。
2, 建立一个批处理py文件,比如runtest.py。
runtest.py
#!/usr/bin/env python
#coding:utf-8
import unittest
test_dir=‘./‘
discover=unittest.defaultTestLoader.discover(test_dir,pattern="*Test.py")
if __name__==‘__main__‘:
runner=unittest.TextTestRunner()
runner.run(discover)
test_dir:定义测试文件的路径,这里为当前路径。
discover=unittest.defaultTestLoader.discover(test_dir,pattern="*Test.py")为调用测试路径下以Test结尾的.py文件(pattern="*Test.py")
然后在主函数中通过调用runner=unittest.TextTestRunner(),runner.run(discover)两行代码来实现匹配的所有文件中的测试用例的执行。
既然介绍到了unittest的批量操作,在这里我很有必要来介绍一下如何通过unittest来生成一封好看的测试报告。
我们先到网站http://tungwaiyip.info/software/HTMLTestRunner.html下载HTMLTestRunner.py文件放入到%PYTHON_HOME%\Lib\目录下。如果你使用的是Python2.X就不需要进行修改,否则请作如下修改:
|
94行
import StringIO
改为
import io
539行
self.outputBuffer = StringIO.StringIO()
改为
self.outputBuffer = io.StringIO()
631行
print >>sys.stderr, ‘\nTime Elapsed: %s‘ % (self.stopTime-self.startTime)
改为
print (sys.stderr, ‘\nTime Elapsed: %s‘ % (self.stopTime-self.startTime))
642行
if not rmap.has_key(cls):
改为
if not cls in rmap:
766行
uo = o.decode(‘latin-1‘)
改为
uo = o
772行
ue = e.decode(‘latin-1‘)改为
ue = e
|
这样我们在runtest.py头部加入fromHTMLTestRunner import HTMLTestRunner,runner.run(discover)前面加上fp=open("result.html","wb"),runner=HTMLTestRunner(stream=fp,title=‘测试报告‘,description=‘测试用例执行报告‘),后面加上fp.close(),运行测试用例完毕就可以生成一份美观的基于HTML的测试报告了,最后的runtest.py代码如下。
|
runtest.py
#!/usr/bin/env python
#coding:utf-8
import unittest
from HTMLTestRunner import HTMLTestRunner
test_dir=‘./‘
discover=unittest.defaultTestLoader.discover(test_dir,pattern="*Test.py")
if __name__==‘__main__‘:
runner=unittest.TextTestRunner()
#以下用于生成测试报告
fp=open("result.html","wb")
runner =HTMLTestRunner(stream=fp,title=‘测试报告‘,description=‘测试用例执行报告‘)
runner.run(discover)
fp.close()
|
图2测试报表,当然这里的测试用例刚才介绍的要多。

图2 unittest测试报表
3、resuests对象介绍与使用
我们要是用request首先要先下载 requests,我们可以用老办法,通过pip命令下载
>pip install requests
首先我来介绍一下 requests对象的使用。
1) 通过requests发送GET请求。
response = requests.get(url,params=payload)
url为发送的地址,payload为请求的参数,格式为字典类型,前面变量名为params,response为返回变量。
比如:
url =http://www.a.com/user.jsp
payload={“id”:”1”,”name”:”Tom”}
data = requests.get(url,params=payload)
2) 通过requests发送POST请求。
response = requests.post(url,data=payload)
url为发送的地址,payload为请求的参数,格式为字典类型,前面变量名为data,response为返回变量。
比如:
url =http://www.b.com/login.jsp
payload={“username”:”Tom”,”password”:”123456”}
data = requests.post(url,data=payload)
3) requests的返回值
这里让我们来讨论下requests的返回值。见表1。
表1:requests的返回值
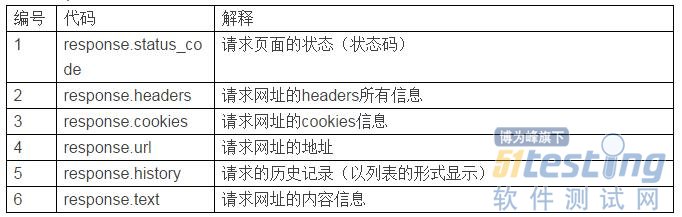
请求网址的内容信息
在这里介绍一下请求页面的状态(状态码),这个在基于HTTP协议的接口测试中经常作为一个验证点。
1XX:表示消息
这个比较少用
2XX:表示成功
经常使用的是:
200:正确
#3XX 表示重定向.
经常使用的是:
304: 没有改变
4XX 表示客户端错误
经常使用的是:
404: 网址不存在
5XX,6XX表示服务器错误.
经常使用的是:
500:服务器内部错误
4)有了上面这些知识,我们来看一下通过request如何来实现接口测试,我们这里以前面介绍的登录模块作为测试对象来设置测试用例。测试用例见表2。
表2:登录模块测试用例

进入登录后页面,出现“查看购物车”
假设我们的正确用户名为 jerry,正确密码为000000,这样我们设计测试代码
|
testLogin.py
import requests
#正确的用户名,错误的密码
url=“http://127.0.0.1:8000/login_action/
payload={{"username":"jerry","password":“000000"}}
data = requests.post(url,data=payload)
if (str(data.status_code)==‘200’) and (“用户名或者密码错误” in str(data.text))
print(“pass”)
else:
print(“Fail”)
#错误的用户名,正确的密码
url=“http://127.0.0.1:8000/login_action/
payload={{"username":“tom","password":“123456"}}
data = requests.post(url,data=payload)
if (str(data.status_code)==‘200’) and (“用户名或者密码错误” in str(data.text))
print(“pass”)
else:
print(“Fail”)
#错误的用户名,错误的密码
url=“http://127.0.0.1:8000/login_action/
payload={{"username":“tom","password":“000000"}}
data = requests.post(url,data=payload)
if (str(data.status_code)==‘200’) and (“用户名或者密码错误” in str(data.text))
print(“pass”)
else:
print(“Fail”)
#正确的用户名,正确的密码
url=“http://127.0.0.1:8000/login_action/
payload={{"username":“jerry","password":“123456"}}
data = requests.post(url,data=payload)
if (str(data.status_code)==‘200’) and (“查看购物车” in str(data.text))
print(“pass”)
else:
print(“Fail”)
|
这样的代码虽然可以测试,但是没有测试框架进行限制,代码不利于维护,更不利于批量地执行,我们用刚才介绍的unittest框架进行改造。
|
testLogin.py
import unittest,requests
class mylogin(unittest.TestCase):
def setUp(self):
print("--------测试开始--------")
def test_login_1:
url=“http://127.0.0.1:8000/login_action/
payload={{"username":“tom","password":“000000"}}
data = requests.post(url,data=payload)
self.assertEqual(‘200’,str(data.status_code))
self.assertIn((“用户名或者密码错误”,str(data.text))
def test_login_2:
url=“http://127.0.0.1:8000/login_action/
payload={{"username":“jerry","password":“123456"}}
data = requests.post(url,data=payload)
self.assertEqual(‘200’,str(data.status_code))
self.assertIn((“用户名或者密码错误”,str(data.text))
def test_login_3:
url=“http://127.0.0.1:8000/login_action/
payload={{"username":“tom","password":“000000"}}
data = requests.post(url,data=payload)
self.assertEqual(‘200’,str(data.status_code))
self.assertIn((“用户名或者密码错误”,str(data.text))
def test_login_4:
url=“http://127.0.0.1:8000/login_action/
payload={{"username":“jerry","password":“000000"}}
data = requests.post(url,data=payload)
self.assertEqual(‘200’,str(data.status_code))
self.assertIn((“查看购物车”,str(data.text))
def tearDown(self):
print("--------测试结束--------")
if __name__==‘__main__‘:
#构造测试集
suite=unittest.TestSuite()
suite.addTest(mylogin(" test_login_1 "))
suite.addTest(mylogin(" test_login_2 "))
suite.addTest(mylogin(" test_login_3 "))
suite.addTest(mylogin(" test_login_4 "))
#运行测试集合
runner=unittest.TextTestRunner()
runner.run(suite)
|
程序通过self.assertEqual(‘200’,str(data.status_code)),来判断返回码是不是与预期的相同;通过self.assertIn((“用户名或者密码错误”,str(data.text))来判断返回的文本中是不是包括指定的字符串。测试用例test_login_1、test_login_2和test_login_3为错误情况的测试用来,将在返回页面中出现“用户名或者密码错误”的提示,test_login_4为正确的测试用例,登录满足需求,页面跳入到登录商品列表后页面,并且显示“查看购物车”的连接,所以我们以返回页面中是否存在“查看购物车”来判断测试是否成功。
4、数据驱动的自动化接口测试
数据驱动的自动化测试是HP在其著名的产品QTP中进行提出,并且成为了业内自动化测试的一个标准,所谓数据驱动可以理解为测试数据参数化。由于Python读取XML的技术相当成熟,我们可以把测试数据放在XML里来进行设计数据驱动的自动化接口测试。首先来看一下我是如何设计XML文件的。
|
loginConfig.xml
<node>
<case>
<TestId>testcase001</TestId>
<Title>用户登录</Title>
<Method>post</Method>
<Desc>正确用户名,错误密码</Desc>
<Url>http://127.0.0.1:8000/login_action/</Url>
<InptArg>{"username":"jerry","password":"12345"}</InptArg>
<Result>200</Result>
<CheckWord>用户名或者密码错误</CheckWord>
</case>
<case>
<TestId>testcase002</TestId>
<Title>用户登录</Title>
<Method>post</Method>
<Desc>错误用户名,正确密码</Desc>
<Url>http://127.0.0.1:8000/login_action/</Url>
<InptArg>{"username":"smith","password":"knyzh158"}</InptArg>
<Result>200</Result>
<CheckWord>用户名或者密码错误</CheckWord>
</case>
<case>
<TestId>testcase003</TestId>
<Title>用户登录</Title>
<Method>post</Method>
<Desc>错误用户名,错误密码</Desc>
<Url>http://127.0.0.1:8000/login_action/</Url>
<InptArg>{"username":"smith","password":"12345"}</InptArg>
<Result>200</Result>
<CheckWord>用户名或者密码错误</CheckWord>
</case>
<case>
<TestId>testcase004</TestId>
<Title>用户登录</Title>
<Method>post</Method>
<Desc>正确用户名,正确密码</Desc>
<Url>http://127.0.0.1:8000/login_action/</Url>
<InptArg>{"username":"jerry","password":"knyzh158"}</InptArg>
<Result>200</Result>
<CheckWord>查看购物车</CheckWord>
</case>
</node>
|
在这里<node></node>是根标识,<case>…</case>表示一个测试用例,这里面有四个<case>…</case>对,分别上述表示四个测试用例。在<case>…</case>对中,有些数据是为了我们读起来比较方便,有些数据是程序中要是用的,下面来进行分别的介绍。
<Desc>…</Desc> :测试用例描述
<Url></Url> :测试的URL地址(程序用到)
<InptArg>…</InptArg> :请求参数,用{}括起来,为符合Python字典格式的值参对(程序用到)
<Result>…</Result> :返回码(程序用到)
<CheckWord>…</CheckWord> :验证字符串(程序用到)
在py文件中我们通过调用from xml.dom import minidom来引入minidom类;dom = minidom.parse(‘loginConfig.xml‘)来获取所需要读取的xml文件; root = dom.documentElement来开始获取文件中节点的内容,然后通过语句aaa = root.getElementsByTagName(‘AAA‘)来获得文件中的所有叶子节点<AAA>…</AAA>对中的数据,因为文件中有多个<AAA>…</AAA>对,所以返回参数aaa为一个对象列表对,然后通过
for keyin aaa:
aaaValue = key.firstChild.data
print(aaaValue)
来获取每一个<AAA>…</AAA>对中的参数。但是由于XML文件中的标签往往不止一个,且对出现,真像我们文件所以loginConfig.xml中的<TestId>…<TestId>、<Title >…
|
<Title> 、<Method>…</Method> …,所以我们可以这样来获得。
aaa = root.getElementsByTagName(‘AAA‘)
bbb = root.getElementsByTagName(‘BBB‘)
ccc = root.getElementsByTagName(‘CCC‘)
i = 0
for keyin AAA:
aaaValue = aaa[i].firstChild.data
bbbValue = bbb[i].firstChild.data
cccValue = ccc[i].firstChild.data
print(aaaValue)
print(bbbValue)
print(cccValue)
i =i+1
|
我们来看一下测试代码。
|
loginConfig.xml
#!/usr/bin/env python
#coding:utf-8
import unittest,requests
from xml.dom import minidom
class mylogin(unittest.TestCase):
def setUp(self):
print("--------测试结束--------")
#从XML中读取数据
dom = minidom.parse(‘loginConfig.xml‘)
root = dom.documentElement
TestIds = root.getElementsByTagName(‘TestId‘)
Titles = root.getElementsByTagName(‘Title‘)
Methods = root.getElementsByTagName(‘Method‘)
Descs = root.getElementsByTagName(‘Desc‘)
Urls = root.getElementsByTagName(‘Url‘)
InptArgs = root.getElementsByTagName(‘InptArg‘)
Results = root.getElementsByTagName(‘Result‘)
CheckWords =root.getElementsByTagName(‘CheckWord‘)
i = 0
mylists=[]
for TestId in TestIds:
mydicts={}
#获取每一个数据,形成字典
mydicts["TestId"] = TestIds[i].firstChild.data
mydicts["Title"] = Titles[i].firstChild.data
mydicts["Method"] = Methods[i].firstChild.data
mydicts["Desc"] = Descs[i].firstChild.data
mydicts["Url"] = Urls[i].firstChild.data
mydicts["InptArg"] = InptArgs[i].firstChild.data
mydicts["Result"] = Results[i].firstChild.data
mydicts["CheckWord"] =CheckWords[i].firstChild.data
mylists.append(mydicts)
i = i+1
self.mylists = mylists
def test_login(self):
for mylist in self.mylists:
payload = eval(mylist["InptArg"])
url=mylist["Url"]
#发送请求
try:
if mylist["Method"] == "post":
data = requests.post(url,data=payload)
elif mylist["Method"] == "get":
data = requests.get(url,params=payload)
else:
print ("Method 参数获取错误")
except Exception as e:
self.assertEqual(mylist["Result"],"404")
else:
self.assertEqual(mylist["Result"],str(data.status_code))
self.assertIn(mylist["CheckWord"],str(data.text))
def tearDown(self):
print("--------测试结束--------")
if __name__==‘__main__‘:
#构造测试集
suite=unittest.TestSuite()
suite.addTest(mylogin("test_login"))
#运行测试集合
runner=unittest.TextTestRunner()
runner.run(suite)
|
setUp(self)主要把XML里的所有叶子节点数据获取到,放在一个名为mylists的列表变量中,并且返回给self.mylists变量,列表中每一项为一个字典类型的数据,key为XML里的所有叶子节点标签,key所对应的值为XML标签的内容。最后self. mylists传给每个测试函数中使用。
现在我们来看一下函数test_login(self)。
for mylistin self.mylists:把刚才在初始化里面定义的self.mylists每一项分别取出。
payload =eval(mylist["InptArg"]):为获取标签为InptArg中的数据,由于在XML格式定义的时候,这一项用{}括起来,里面是个值参对,由于mylist["InptArg"]返回的是一个{}括起来的具有字典格式的字符串,所以我们必须通过函数eval()进行转移成字典变量赋给payload。
url=mylist["Url"]为发送HTTP的地址。
然后通过判断mylist["Method"]是等于”post”还是等于”get”,选择使用data = requests.post(url,data=payload)或者data =requests.get(url,params=payload)来发送信息,接受信息放在变量data中。
最后通过self.assertEqual(mylist["Result"],str(data.status_code))来判断返回代码是否符合期望结果,以及self.assertIn(mylist["CheckWord"],str(data.text))期望代码mylist["CheckWord"]是否在返回内容str(data.text)中来判断测试是否成功。在这里特别指出在程序中except Exception as e中通过self.assertEqual(mylist["Result"],"404")来判断是否期望结果不存在。在这个项目中我们也加上类似的runtest.py来运行所有的测试用例。格式与前面相同,再次不在重复介绍。图3是加上注册接口测试代码的测试报告。
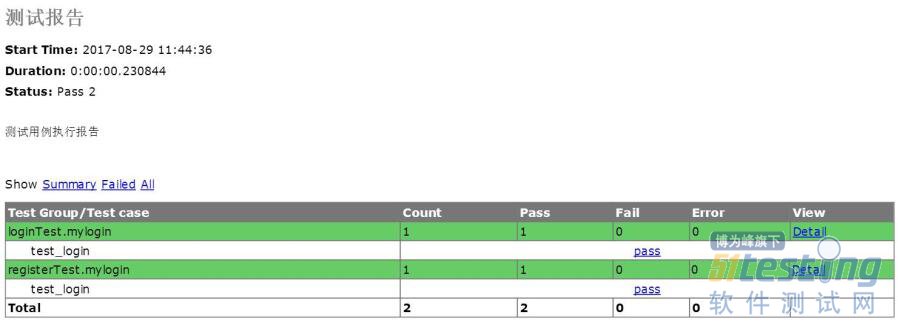
图3基于Python Requests的HTTP接口测试报告
5、进一步优化
细心的同学可能会发现,上面程序中setUp函数我们可以进行一些封装优化,我们建立一个单独的py文件getXML.py,内容如下:
|
getXML.py
#!/usr/bin/env python
#coding:utf-8
from xml.dom import minidom
class GetXML():
def getxmldata(xmlfile):
#从XML中读取数据
dom = minidom.parse(xmlfile)
root = dom.documentElement
TestIds = root.getElementsByTagName(‘TestId‘)
Titles = root.getElementsByTagName(‘Title‘)
Methods = root.getElementsByTagName(‘Method‘)
Descs = root.getElementsByTagName(‘Desc‘)
Urls = root.getElementsByTagName(‘Url‘)
InptArgs = root.getElementsByTagName(‘InptArg‘)
Results = root.getElementsByTagName(‘Result‘)
CheckWords =root.getElementsByTagName(‘CheckWord‘)
i = 0
mylists=[]
for TestId in TestIds:
mydicts={}
#获取每一个数据,形成字典
mydicts["TestId"] = TestIds[i].firstChild.data
mydicts["Title"] = Titles[i].firstChild.data
mydicts["Method"] = Methods[i].firstChild.data
mydicts["Desc"] = Descs[i].firstChild.data
mydicts["Url"] = Urls[i].firstChild.data
mydicts["InptArg"] = InptArgs[i].firstChild.data
mydicts["Result"] = Results[i].firstChild.data
mydicts["CheckWord"] =CheckWords[i].firstChild.data
mylists.append(mydicts)
i = i+1
return mylists
|
这样在loginTest.py改为setUp函数只需要改为:
|
loginConfig.xml
…
from getXML import GetXML #引入刚才建立的类
…
class mylogin(unittest.TestCase):
def setUp(self):
print("--------测试开始--------")
self.mylists = GetXML.getxmldata("loginConfig.xml")#调用类中的函数
…
|