文本处理工具
Posted m490545607
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本处理工具相关的知识,希望对你有一定的参考价值。
文本处理工具
文件查找
在文件系统上查找符合条件的文件
文件查找:
非实时查找(数据库查找):locate
实时查找:find
locate命令用于按照名称快速搜索文件所对应的位置,语法格式为“locate文件名称”。
使用find命令进行全盘搜索虽然更准确,但是效率有点低。如果仅仅是想找一些常见的且又知道大概名称的文件,不如试试locate命令。在使用locate命令时,先使用updatedb命令生成一个索引库文件,这个库文件的名字是/var/lib/mlocate/mlocate.db,后续在使用locate命令搜索文件时就是在该库中进行查找操作,速度会快很多。
第一次使用locate命令之前,记得先执行updatedb命令来生成索引数据库,然后再进行查找

常用选项
-i 不区分大小写搜索
-n N 只列举前N个匹配的文件
-r 使用基本正则表达式
搜索名称或路径包含“conf”的文件
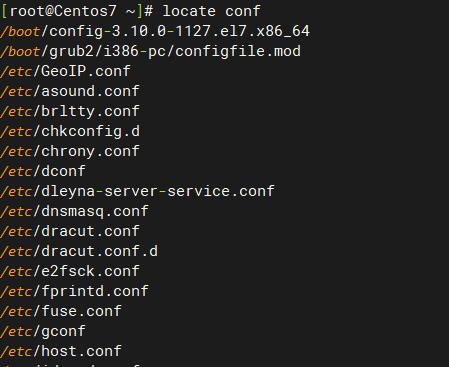
find命令
find命令用于按照指定条件来查找文件所对应的位置,语法格式为“find [查找范围] 寻找条件”。
本书中会多次提到“Linux系统中的一切都是文件”,接下来就要见证这句话的分量了。在Linux系统中,搜索工作一般都是通过find命令来完成的,它可以使用不同的文件特性作为寻找条件(如文件名、大小、修改时间、权限等信息),一旦匹配成功则默认将信息显示到屏幕。

head命令 – 显示文件开头的内容,head命令的功能是显示文件开头的内容,默认为前10行。
语法格式:head [参数] 文件
常用参数: -n <数字> 定义显示行数
-c <数字> 指定显示头部内容的字符数
-v 总是显示文件名的头信息
-q 不显示文件名的头信息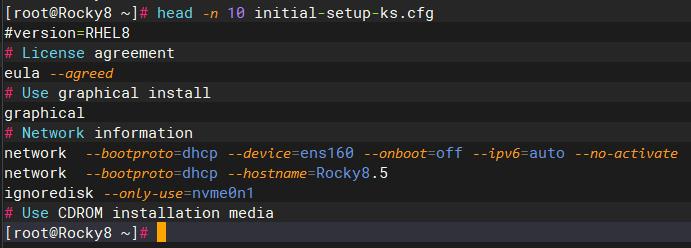
tac命令 – 反向显示文件内容,tac命令的功能是用于反向显示文件内容,即常见的查看文件内容命令cat的反写形式,当我们使用tac命令查看文件内容时,最先显示的是最后一行,倒数第二行,倒数第三行,以此类推到最后显示原本文件的第一行内容。
语法格式:tac [参数] 文件
常用参数:
-b 在行前而非行尾添加分隔标志
-r 将分隔标志视作正则表达式来解析
-s 使用指定字符串代替换行作为分隔标志
--help 显示此帮助信息并退出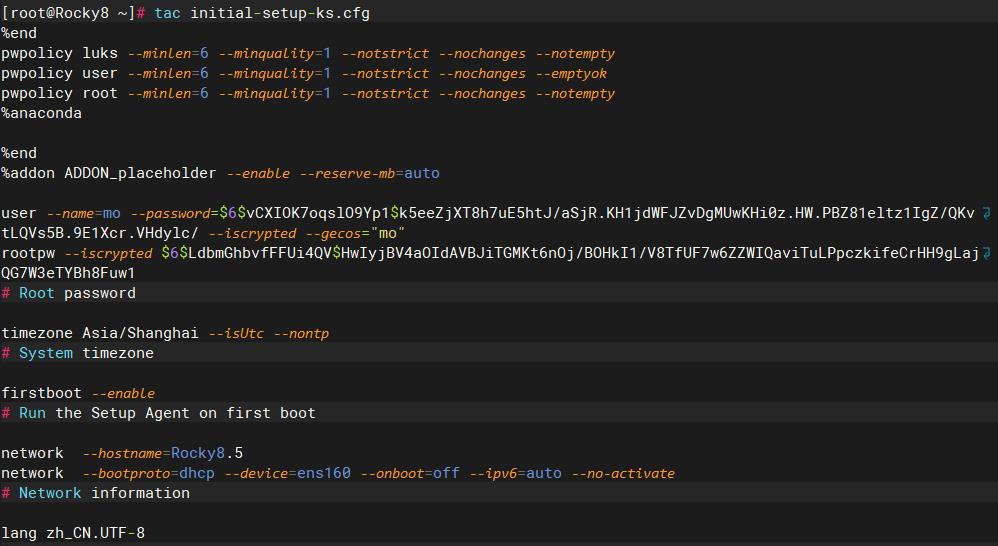
tr命令 – 字符转换工具;tr命令来自于英文单词transform的缩写,中文译为转换,其功能是用于字符转换。tr命令是一款批量字符转换、压缩、删除的文本工具,但仅能从标准输入中读取文本内容,需要与管道符或输入重定向操作符搭配使用。
语法格式:tr [参数] 字符串1 字符串2
常用参数:
-c 反选字符串1的补集(取反)
-d 删除字符串1中出现的所有字符
-s 删除所有重复出现的字符序列
uniq命令 – 去除文件中的重复内容行;uniq命令来自于英文单词unique的缩写,中文译为独特的、唯一的,其功能是用于去除文件中的重复内容行。uniq命令能够去除掉文件中相邻的重复内容行,如果两端相同内容中间夹杂了其他文本行,则需要先使用sort命令进行排序后再去重复,这样保留下来的内容就都是唯一的了。
语法格式:uniq [参数] 文件
常用参数:
-c 打印每行在文本中重复出现的次数
-d 每个重复纪录只出现一次
-u 只显示没有重复的纪录
grep命令 – 强大的文本搜索工具
通常将grep命令与正则表达式搭配使用,参数作为搜索过程中的补充或对输出结果的筛选,命令模式十分灵活。 与之容易混淆的是egrep命令和fgrep命令。如果把grep命令当作是标准搜索命令,那么egrep则是扩展搜索命令,等价于“grep -E”命令,支持扩展的正则表达式。而fgrep则是快速搜索命令,等价于“grep -F”命令,不支持正则表达式,直接按照字符串内容进行匹配。
语法格式: grep [参数] 文件名
常用参数:
-i 忽略大小写
-c 只输出匹配行的数量
-l 只列出符合匹配的文件名
-n 列出所有的匹配行并显示行号
-h 查询多文件时不显示文件名
-s 不显示没有匹配文本的错误信息
-v 显示不包含匹配文本的所有行
-w 匹配整词
-x 匹配整行
-r 递归搜索
-q 禁止输出任何结果
-b 显示匹配行距文件头部的偏移量
-o 显示匹配的词据文件头部的偏移量
-F 匹配固定字符串的内容
-E 支持扩展的正则表达式


shell编程文本处理工具
文本处理工具:
Linux上文本处理三剑客:
grep, egrep, fgrep:文本过滤工具(模式:pattern)工具;
grep:基本正则表达式,-E,-F
egrep:扩展正则表达式, -G,-F
fgrep:不支持正则表达式,
sed:stream editor, 流编辑器;文本编辑工具;
awk:Linux上的实现为gawk,文本报告生成器(格式化文本);
正则表达式:Regual Expression, REGEXP
由一类特殊字符及文本字符所编写的模式,其中有些字符不表示其字面意义,而是用于表示控制或通配的功能;
分两类:
基本正则表达式:BRE
扩展正则表达式:ERE
元字符:\(hello[[:space:]]\+\)\+
grep: Global search REgular expression and Print out the line.
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查;打印匹配到的行;
模式:由正则表达式的元字符及文本字符所编写出的过滤条件;
正则表达式引擎;
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
OPTIONS:
--color=auto:对匹配到的文本着色后高亮显示;
-i:ignorecase,忽略字符的大小写;
-o:仅显示匹配到的字符串本身;
-v, --invert-match:显示不能被模式匹配到的行;
-E:支持使用扩展的正则表达式元字符;
-q, --quiet, --silent:静默模式,即不输出任何信息;
-A #:after, 后#行
-B #:before,前#行
-C #:context,前后各#行
基本正则表达式元字符:
字符匹配:
. :匹配任意单个字符;
[]:匹配指定范围内的任意单个字符;
[^]:匹配指定范围外的任意单个字符;
[:digit:]、[:lower:]、[:upper:]、[:alpha:]、[:alnum:]、[:punct:]、[:space:]
匹配次数:用在要指定其出现的次数的字符的后面,用于限制其前面字符出现的次数;默认工作于贪婪模式;
*:匹配其前面的字符任意次;0,1,多次;
例如:grep "x\+y"
abxy
aby
xxxxxy
yab
.*:匹配任意长度的任意字符
\?:匹配其前面的字符0次或1次;即其前面的字符是可有可无的;
\+:匹配其前面的字符1次或多次;即其面的字符要出现至少1次;
\{m\}:匹配其前面的字符m次;
\{m,n\}:匹配其前面的字符至少m次,至多n次;
\{0,n\}:至多n次
\{m,\}:至少m次
位置锚定:
^:行首锚定;用于模式的最左侧;
$:行尾锚定;用于模式的最右侧;
^PATTERN$:用于PATTERN来匹配整行;
^$:空白行;
^[[:space:]]*$:空行或包含空白字符的行;
单词:非特殊字符组成的连续字符(字符串)都称为单词;
\< 或 \b:词首锚定,用于单词模式的左侧;
\> 或 \b:词尾锚定,用于单词模式的右侧;
\<PATTERN\>:匹配完整单词;
练习:
1、显示/etc/passwd文件中不以/bin/bash结尾的行;
~]# grep -v "/bin/bash$" /etc/passwd
2、找出/etc/passwd文件中的两位数或三位数;
~]# grep "\<[0-9]\{2,3\}\>" /etc/passwd
3、找出/etc/rc.d/rc.sysinit或/etc/grub2.cfg文件中,以至少一个空白字符开头,且后面非空白字符的行;
~]# grep "^[[:space:]]\+[^[:space:]]" /etc/grub2.cfg
4、找出"netstat -tan"命令的结果中以‘LISTEN‘后跟0、1或多个空白字符结尾的行;
~]# netstat -tan | grep "LISTEN[[:space:]]*$"
分组及引用
\(\):将一个或多个字符捆绑在一起,当作一个整体进行处理;
\(xy\)*ab
Note:分组括号中的模式匹配 到的内容会被正则表达式引擎自动记录于内部的变量中,这些变量为:
\1:模式从左侧起,第一个左括号以及与之匹配的右括号之间的模式所匹配到的字符;
\2:模式从左侧起,第二个左括号以及与之匹配的右括号之间的模式所匹配到的字符;
\3
...
He loves his lover.
He likes his lover.
She likes her liker.
She loves her liker.
~]# grep "\(l..e\).*\1" lovers.txt
后向引用:引用前面的分组括号中的模式所匹配到的字符;
egrep:
支持扩展的正则表达式实现类似于grep文本过滤功能;grep -E
egrep [OPTIONS] PATTERN [FILE...]
选项:
-i, -o, -v, -q, -A, -B, -C
-G:支持基本正则表达式
扩展正则表达式的元字符:
字符匹配:
.:任意单个字符
[]:指定范围内的任意单个字符
[^]:指定范围外的任意单个字符
次数匹配:
*:任意次,0,1或多次;
?:0次或1次,其前的字符是可有可无的;
+:其前字符至少1次;
{m}:其前的字符m次;
{m,n}:至少m次,至多n次;
{0,n}
{m,}
位置锚定
^:行首锚定;
$:行尾锚定;
\<, \b:词首锚定;
\>, \b:词尾锚定;
分组及引用:
():分组;括号内的模式匹配到的字符会被记录于正则表达式引擎的内部变量中;
后向引用:\1, \2, ...
或:
a|b:a或者b;
C|cat:C或cat
(c|C)at:cat或Cat
练习:
1、找出/proc/meminfo文件中,所有以大写或小写S开头的行;至少有三种实现方式;
~]# grep -i "^s" /proc/meminfo
~]# grep "^[sS]" /proc/meminfo
~]# grep -E "^(s|S)" /proc/meminfo
2、显示当前系统上root、centos或user1用户的相关信息;
~]# grep -E "^(root|centos|user1)\>" /etc/passwd
3、找出/etc/rc.d/init.d/functions文件中某单词后面跟一个小括号的行;
~]# grep -E -o "[_[:alnum:]]+\(\)" /etc/rc.d/init.d/functions
4、使用echo命令输出一绝对路径,使用egrep取出基名;
~]# echo /etc/sysconfig/ | grep -E -o "[^/]+/?$"
进一步:取出其路径名;类似于对其执行dirname命令的结果;
5、找出ifconfig命令结果中的1-255之间的数值;
~]# ifconfig | grep -E -o "\<([1-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\>"
6、课外作业:找出ifconfig命令结果中的IP地址;
7、添加用户bash, testbash, basher以及nologin(其shell为/sbin/nologin);而后找出/etc/passwd文件中用户名同shell名的行;
~]# grep -E "^([^:]+\>).*\1$" /etc/passwd
fgrep:不支持正则表达式元字符;
当无需要用到元字符去编写模式时,使用fgrep必能更好;
以上是关于文本处理工具的主要内容,如果未能解决你的问题,请参考以下文章