此篇文章献给还处于Python零基础的小白们!保证你能入门不是问题
Posted python1234
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了此篇文章献给还处于Python零基础的小白们!保证你能入门不是问题相关的知识,希望对你有一定的参考价值。
更多案例请关注我的博客:home.cnblogs.com/u/Python1234
欢迎大家加入千人交流资源共享群:125240963
-
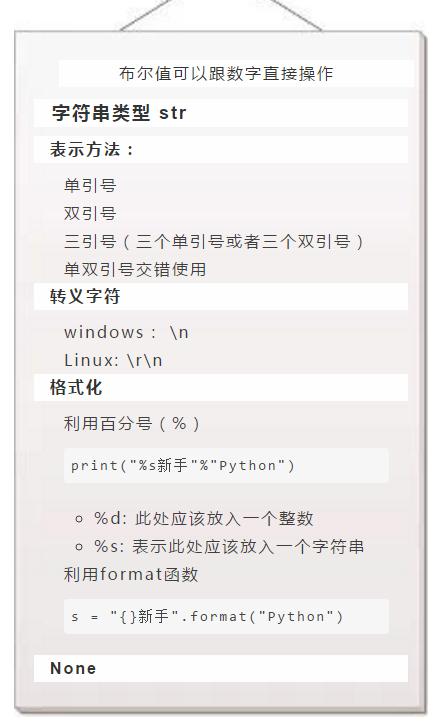
表示什么都没有
-
如果函数没有返回值,可以返回 None
-
用来占位
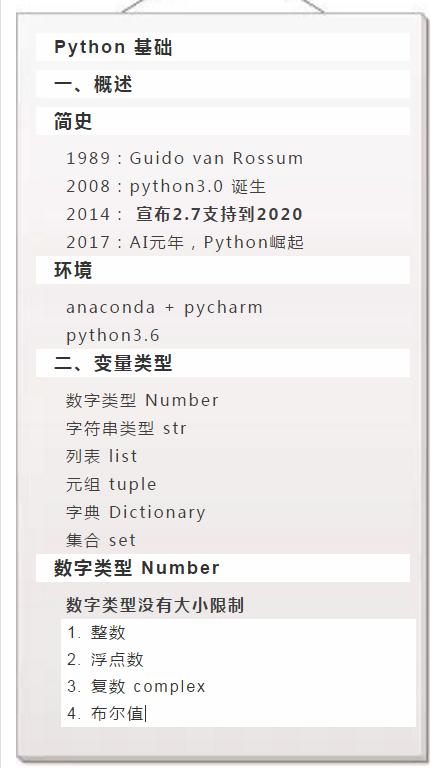
三、内置数据结构
-
list
-
set
-
dict
-
tuple
list(列表)
# 1, 创建空列表 l1 =
[]
# 2. 创建带值的列表 l2 = [ 100
]
# 3. 创建列表,带多个值 l3 = [ 2 , 3 , 1 , 4 , 6 , 4 , 6
]
# 4. 使用list() l4 = list()




-
# 用list a创建一个list b # 下面代码的含义是,对于所有a中的元素,逐个放入新列表b中 b = [i * 10 for i in
a]
# 还可以过滤原来list中的内容病放入新列表 # 比如原有列表a, 需要把所有a中的偶数生成新的列表b a = [x for x in range( 1 , 35 )] # 生成从1到34的一个列表 # 把a中所有偶数生成一个新的列表 b b = [m for m in a if m % 2 ==
0]
# 列表生成式可以嵌套 # 由两个列表a,b a = [i for i in range( 1 , 4 )] # 生成list a b = [i for i in range( 100 , 400 ) if i % 100 ==
0]
# 列表生成是可以嵌套,此时等于两个for循环嵌套 c = [ m + n for m in a for n in
b]
# 上面代码跟下面代码等价 for m in
a:
for n in
b:
print (m + n, end = " "
)
# 嵌套的列表生城市也可以用条件表达式 c = [ m + n for m in a for n in b if m + n < 250 ]
-
关于列表的常用函数
-
copy: 拷贝,此函数是浅拷贝
b = a.copy()
-
count:查找列表中指定值或元素的个数
a_len = a.count( 8 )
-
extend:扩展列表,两个列表,把一个直接拼接到后一个上
a = [ 1 , 2 , 3 , 4 , 5
]
b
= [ 6 , 7 , 8 , 9 , 10
]
a.extend(b)
-
remove:在列表中删除指定的值的元素(如果被删除的值没在list中,则报错)
-
clear:清空
-
reverse:翻转列表内容,原地翻转
a = [ 1 , 2 , 3 , 4 , 5
]
a.reverse()
-
del 删除
-
pop,从对位拿出一个元素,即把最后一个元素取出来
last_ele = a.pop()
-
insert: 制定位置插入
# insert(index, data), 插入位置是index前面 a.insert( 3 , 666 )
-
append 插入一个内容, 在末尾追加
a = [ i for i in range( 1 , 5
)]
a.append(
100 )
-
min
-
list:将其他格式的数据转换成list
# 把range产生的内容转换成list print (list(range( 12 , 19 )))
-
max:求列表中的最大值
b = [ ‘ man ‘ , ‘ film ‘ , ‘ python ‘
]
print (max(b))
-
len:求列表长度
a = [x for x in range( 1 , 100
)]
print (len(a))
tuple(元组)
# 创建空元组 t =
()
# 创建一个只有一个值的元组 t = ( 1
,)
t
= 1
,
# 创建多个值的元组 t = ( 1 , 2 , 3 , 4 , 5
)
t
= 1 , 2 , 3 , 4 , 5 # 使用其他结构创建 l = [ 1 , 2 , 3 , 4 , 5
]
t
= tuple(l)
元组的特性
-
是序列表,有序
-
元组数据值可以访问,不能修改
-
元组数据可以是任意类型
-
list所有特性,除了可修改外,元组都具有
元组的函数
-
len: 获取元组的长度
-
max, min:最大最小值
-
count: 计算制定数据出现的次数
-
index:求制定元素在元组中的索引位置
set(集合)
# 集合的定义 s =
set()
# 此时,大括号内一定要有值,否则定义出的是一个dict s = { 1 , 2 , 3 , 4 , 5 , 6 , 7
}
# 如果只是用大括号定义,则定义的是一个dict类型 d = {}
集合的特征
-
集合内数据无序,即无法使用索引和分片
-
集合内部数据元素具有唯一性,可以用来排除重复数据
-
集合内的数据,str, int, float, tuple,冰冻集合等,即内部只能放置可哈希数据
集合序列操作
-
成员检测(in,not in)
-
遍历
# for 循环 s = { 4 , 5 , " i "
}
for i in
s:
print (i, end = " "
)
# 带有元组的集合遍历 s = {( 1 , 2 , 3 ), ( " just " , " for " , " fun " ), ( 4 , 5 , 6
)}
for k,m,n in
s:
print (k, " -- " , m, " -- "
, n)
for k in
s:
print (k)
集合的内涵
# 普通集合内涵 # 以下集合在初始化后自动过滤掉重复元素 s = { 23 , 223 , 545 , 3 , 1 ,2 , 3 , 4 , 3 , 2 , 3 , 1 , 2 , 4 , 3
}
# 普通集合内涵 ss = {i for i in
s}
# 带条件的集合内涵 sss = {i for i in s if i % 2 ==
0}
# 多循环的集合内涵 s1 = { 1 , 2 , 3 , 4
}
s2
= { " just " , " for " , " fun "
}
s
= {m * n for m in s2 for n in
s1}
s
= {m * n for m in s2 for n in s1 if n == 2 }
集合函数
-
len, max, min
-
set:生成一个集合
-
add:向集合内添加元素
-
clear
-
copy
-
remove:移除制定的值,直接改变原有值,如果要删除的值不存在,报错
-
discard:移除集合中指定的值,跟 remove 一样,但是入股要删除的话,不报错
-
pop 随机移除一个元素
-
函数
-
intersection: 交集
-
difference:差集
-
union: 并集
-
issubset: 检查一个集合是否为另一个子集
-
issuperset: 检查一个集合是否为另一个超集
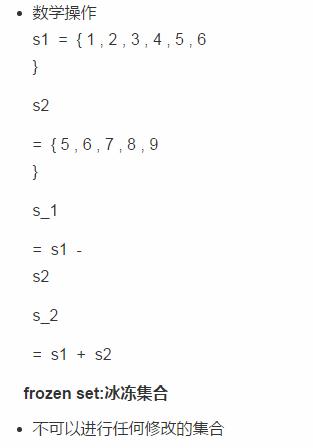
-
# 创建 s = frozenset()
dict(字典)
-
没有顺序的组合数据,数据以键值对形式出现
# 字典的创建 # 创建空字典1 d =
{}
# 创建空字典2 d =
dict()
# 创建有值的字典, 每一组数据用冒号隔开, 每一对键值对用逗号隔开 d = { " one " : 1 , " two " : 2 , " three " : 3
}
# 用dict创建有内容字典1 d = dict({ " one " : 1 , " two " : 2 , " three " : 3
})
# 用dict创建有内容字典2 # 利用关键字参数 d = dict(one = 1 , two = 2 , three = 3
)
# d = dict( [( " one " , 1 ), ( " two " , 2 ), ( " three " , 3 )])
字典的特征
-
字典是序列类型,但是是无序序列,所以没有分片和索引
-
字典中的数据每个都有键值对组成,即kv对
-
key: 必须是可哈希的值,比如int,string,float,tuple, 但是,list,set,dict 不行
-
value: 任何值
字典常见操作
# 访问数据 d = { " one " : 1 , " two " : 2 , " three " : 3
}
# 注意访问格式 # 中括号内是键值 print (d[ " one "
])
d[
" one " ] = " eins " # 删除某个操作 # 使用del操作 del d[ " one "
]
# 成员检测, in, not in # 成员检测检测的是key内容 d = { " one " : 1 , " two " : 2 , " three " : 3
}
if 2 in
d:
print ( " value "
)
if " two " in
d:
print ( " key "
)
if ( " two " , 2 ) in
d:
print ( " kv "
)
# 按key来使用for循环 d = { " one " : 1 , " two " : 2 , " three " : 3
}
# 使用for循环,直接按key值访问 for k in
d:
(k, d[k])
# 上述代码可以改写成如下 for k in
d.keys():
(k, d[k])
# 只访问字典的值 for v in
d.values():
(v)
# 注意以下特殊用法 for k,v in
d.items():
print (k, ‘ -- ‘ ,v)
字典生成式
d = { " one " : 1 , " two " : 2 , " three " : 3
}
# 常规字典生成式 dd = {k:v for k,v in
d.items()}
# 加限制条件的字典生成式 dd = {k:v for k,v in d.items() if v % 2 == 0}
字典相关函数
-
len, max, min, dict
-
str(字典): 返回字典的字符串格式
-
clear: 清空字典
-
items: 返回字典的键值对组成的元组格式
-
keys:返回字典的键组成的一个结构
-
values: 同理,一个可迭代的结构
-
get: 根据制定键返回相应的值
d = { " one " : 1 , " two " : 2 , " three " : 3
}
print (d.get( " on333 "
))
# get默认值是None,可以设置 print (d.get( " one " , 100 ))
-
fromkeys: 使用指定的序列作为键,使用一个值作为字典的所有的键的值
l = [ " eins " , " zwei " , " drei "
]
# 注意fromkeys两个参数的类型 # 注意fromkeys的调用主体 d = dict.fromkeys(l, " oops " )
四、表达式
运算符
-
算数运算符
-
比较或者关系运算符
-
赋值运算符
-
逻辑运算符
-
位运算
-
成员运算
-
身份运算符
算数运算符
-
加 +
-
减 -
-
乘 *
-
除 /
-
取余 %
-
取商(地板除) //
-
幂运算 **
-
:warning:Python 没有自增自减运算符
比较运算符
-
==
-
!=
-
>=
-
<=
-
比较的结果是布尔值(True/False)
赋值运算符
-
+= (-=, ×=, /=, //=, %=, **=)
逻辑运算符
-
and 逻辑与
-
or 逻辑或
-
not 逻辑非
-
结果如果是0则为False, 否则为True
-
短路
-
Python 中没有异或运算
成员运算符号
-
用来检测某一个变量是否是另一个变量的成员
-
in
-
not in
身份运算
-
is: 用来检测两个变量是否是同一个变量
-
is not: 两个变量不是同一个变量
运算符的优先级
-
括号具有最高优先级
** 指数 (最高优先级)
~ + - 按位翻转
,
一元加号和减号 (最后两个的方法名为 [email protected] 和 [email protected])
* / % // 乘,除,取模和取整除
+ - 加法减法
\\>> << 右移,左移运算符
& 位 ‘AND‘
^ | 位运算符
<
= < > > =
比较运算符
<>
== ! =
等于运算符
= % = / = // = - = + = * = ** =
赋值运算符
is is not 身份运算符
in not in 成员运算符
not or and 逻辑运算符
五、程序结构
顺序
分支
-
基本语法
# 表达式后面的冒号不能少 # 用缩进来表示同一个代码块 if
条件表达式:
语句1
语句2
语句3
..
-
双向分支
# if 和 else 一个层级,其余语句一个层级 if
条件表达式:
语句1
语句2
else
:
语句1
语句2
-
多路分支
if
条件表达式:
语句1
.
elif
条件表达式:
语句1
elif
条件表达式:
语句1
..
else
:
语句1
.
-
Python 没有 switch-case 语句
循环
for 循环
for 变量 in
序列:
语句1
语句2
range
-
生成一个数字序列
-
范围:[m,n)
# 打印 1~10 for i in range( 1 , 11
):
print (i)
for-else
-
当for循环结束的时候,会执行else语句
-
else语句可选
while 循环
while
条件表达式:
语句块
# 另外一种表达方法 while
条件表达式:
语句块1
else
:
语句块2
循环之break,continue,pass
-
break: 无条件结束整个循环,简称循环猝死
-
continue:无条件结束本次循环,从新进入下一轮循环
-
pass:表示略过,通常用于站位,没有跳过功能
六、函数
-
def关键字
-
代码缩进
# 定义 def
func():
print ( " 这是一个函数 "
)
# 调用 func()
函数的参数和返回值
-
参数: 负责给函数传递一些必要的数据或者信息
-
形参(形式参数): 在函数定义的时候用到的参数没有具体值,只是一个占位的符号,成为形参
-
实参(实际参数): 在调用函数的时候输入的值
-
返回值: 函数的执行结果
-
使用 return 关键字
-
如果没有 return ,默认返回一个 None
-
函数一旦执行 return 语句,则无条件返回,即结束函数的执行
# return语句的基本使用 # 函数打完招呼后返回一句话 def
hello(person):
print ( " {0}, 你肿么咧 "
.format(person))
print ( " Sir, 你不理额额就走咧 "
)
return " 我已经跟{0}打招呼了,{1}不理我 "
.format(person, person)
p
= " 明月 " rst =
hello(p)
print (rst)
# 定义一个函数,打印一行九九乘法表 def
printLine(row):
for col in range( 1 , row + 1
):
# print函数默认任务打印完毕后换行 print ( row * col, end = " "
)
print ( ""
)
# 九九乘法表 # version 2.0 for row in range( 1 , 10
):
printLine(row)
参数详解
-
参数分类
-
普通参数
-
默认参数
-
关键字参数
-
收集参数
-
普通参数
-
参见上例
-
定义的时候直接定义变量名
-
调用的时候直接把变量或者值放入指定位置
def 函数名(参数1, 参数2,
.):
函数体
# 调用 函数名(value1, value2,
.)
-
默认参数
-
形参带有默认值
-
调用的时候,如果没有对相应形参赋值,则使用默认值
def func_name(p1 = v1, p2 = v2
.):
func_block
# 调用1
func_name()
# 调用2 value1 = 100 value2 = 200 func_name(value1,value2)
-
关键字参数
def func(p1 = v1, p2 = v2
..):
func_body
# 调用函数: func(p1 = value1, p2 = value2
.)
-
收集参数
-
把没有位置,不能和定义时的参数位置相对应的参数,放入一个特定的数据结构中
def func( *
args):
func_body
# 按照list使用方式访问args得到传入的参数 # 调用: func(p1, p2, p3,
..)
收集参数混合调用的顺序问题
-
收集参数,关键字参数,普通参数可以混合使用
-
使用规则就是,普通参数和关键字参数优先
-
定义的时候一般找普通参数,关键字参数,收集参数 tuple,收集参数 dict
返回值
-
函数和过程的区别
-
有无返回值
-
需要用return显示返回内容,
-
如果没有返回,则默认返回None
递归函数
-
python对递归深度有限制,超过限制报错
# 斐波那契额数列 # 一列数字,第一个值是1, 第二个也是1, 从第三个开始,每一个数字的值等于前两个数字出现的值的和 # 数学公式为: f(1) = 1, f(2) = 1, f(n) = f(n-1) + f(n-2) # 例如: 1,1,2,3,5,8,13.。。。。。。。。 # n表示求第n个数子的斐波那契数列的值 def
fib(n):
if n == 1
:
return 1 if n == 2
:
return 1 return fib(n - 1 ) + fib(n - 2
)
print (fib( 3
))
print (fib( 10 ))
-
汉诺塔问题
-
规则:
-
方法:
-
n=1: 直接把A上的一个盘子移动到C上, A->C
-
n=2:
-
n=3:
-
n = n:
-
把小盘子从A放到B上, A->B
-
把大盘子从A放到C上, A->C
-
把小盘子从B放到C上, B->C
-
把A上的两个盘子,通过C移动到B上去, 调用递归实现
-
把A上剩下的一个最大盘子移动到C上, A->C
-
把B上两个盘子,借助于A,挪到C上去, 调用递归
-
把A上的n-1个盘子,借助于C,移动到B上去,调用递归
-
把A上的最大盘子,也是唯一一个,移动到C上,A->C
-
把B上n-1个盘子,借助于A,移动到C上, 调用递归
-
每次移动一个盘子
-
任何时候大盘子在下面,小盘子在上面
def
hano(n, a, b, c):
‘‘‘
汉诺塔的递归实现
n:代表几个盘子
a:代表第一个塔,开始的塔
b:代表第二个塔,中间过渡的塔
c:代表第三个塔, 目标塔
‘‘‘ if n == 1
:
print (a, " --> "
, c)
return
None
‘‘‘
if n == 2:
print(a, "-->", b)
print(a, "-->", c)
print(b, "-->", c)
return None
‘‘‘ # 把n-1个盘子,从a塔借助于c塔,挪到b塔上去 hano(n - 1
, a, c, b)
print (a, " --> "
, c)
# 把n-1个盘子,从b塔,借助于a塔,挪到c塔上去 hano(n - 1 ,b, a, c)
a = " A " b = " B " c = " C " n = 1
hano(n, a, b, c)
n
= 2
hano(n, a, b, c)
n
= 3 hano(n, a, b, c)
查找函数帮助文档
-
用 help 函数
help( print )
-
使用__doc__
def
stu(name, age):
‘‘‘
这是文档的文字内容
:param name: 表示学生的姓名
:param age: 表示学生的年龄
:return: 此函数没有返回值
‘‘‘ pass print
(help(stu))
print ( " * " * 20
)
print (stu. __doc__ )
七、变量作用域
-
分类:按照作用域分类
-
全局(global): 在函数外部定义
-
局部(local):在函数内部定义
-
LEGB原则
-
L(Local)局部作用域
-
E(Enclosing function locale)外部嵌套函数作用域
-
G(Global module)函数定义所在模块作用域
-
B(Buildin): python内置魔抗的作用域
提升局部变量为全局变量(使用global)
def
fun():
global
b1
b1
= 100 print
(b1)
print ( " I am in fun "
)
# b2的作用范围是fun b2 = 99 print
(b2)
fun()
print (b1)
globals, locals函数
-
可以通过globals和locals显示出局部变量和全局变量
# globals 和 locals # globals 和 locals 叫做内建函数 a = 1 b = 2 def
fun(c,d):
e
= 111 print ( " Locals={0} "
.format(locals()))
print ( " Globals={0} "
.format(globals()))
fun(
100 , 200 )
eval()函数
-
把一个字符串当成一个表达式来执行, 返回表达式执行后的结果
eval(string_code, globals = None, locals = None)
exec()函数
跟eval功能类似, 但是,不返回结果
exec (string_code, globals = None, locals = None)
以上是关于此篇文章献给还处于Python零基础的小白们!保证你能入门不是问题的主要内容,如果未能解决你的问题,请参考以下文章
历时三个月,少说有三十多万字的《从零开始学习Java设计模式》小白零基础设计模式入门导读(强烈建议收藏)
历时三个月,少说有三十多万字的《从零开始学习Java设计模式》小白零基础设计模式入门导读(强烈建议收藏)