利用Python爬取在线教程!并把它转为PDF,方便学习!
Posted sm123456
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用Python爬取在线教程!并把它转为PDF,方便学习!相关的知识,希望对你有一定的参考价值。


1、网站介绍
之前再搜资料的时候经常会跳转到如下图所示的在线教程:
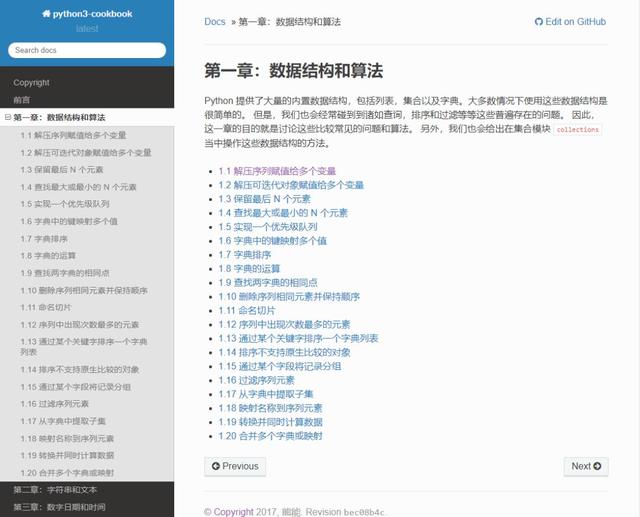
01.教程样式
包括一些github的项目也纷纷将教程链接指向这个网站。经过一番查找,该网站是一个可以创建、托管和浏览文档的网站,其网址为:https://readthedocs.org 。在上面可以找到很多优质的资源。
该网站虽然提供了下载功能,但是有些教程并没有提供PDF格式文件的下载,如图:
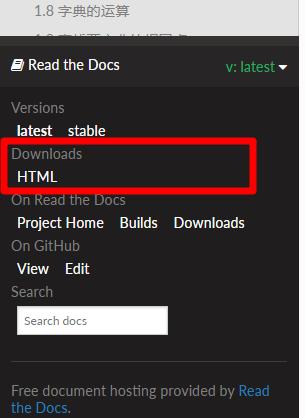
02.下载
该教程只提供了 HTML格式文件的下载,还是不太方便查阅,那就让我们动手将其转成PDF吧!

$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos


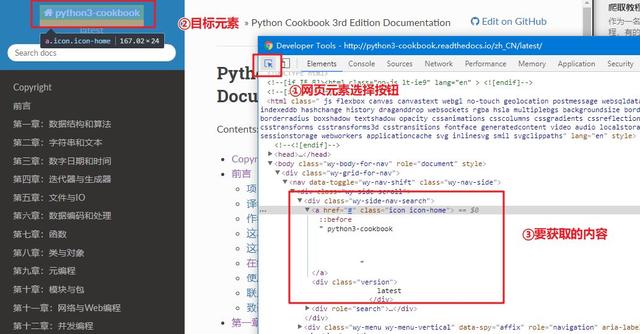

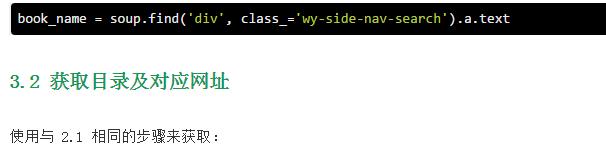
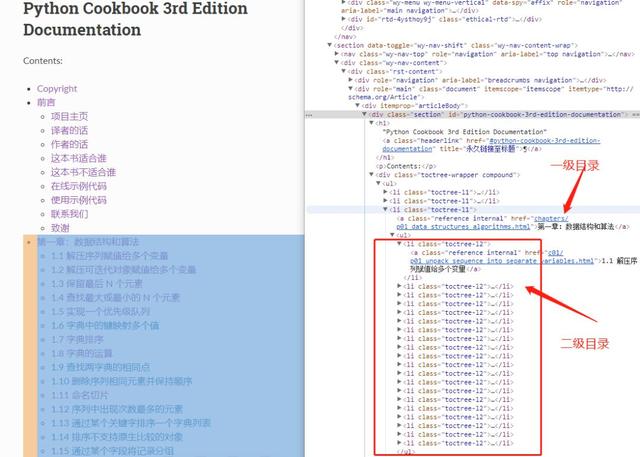

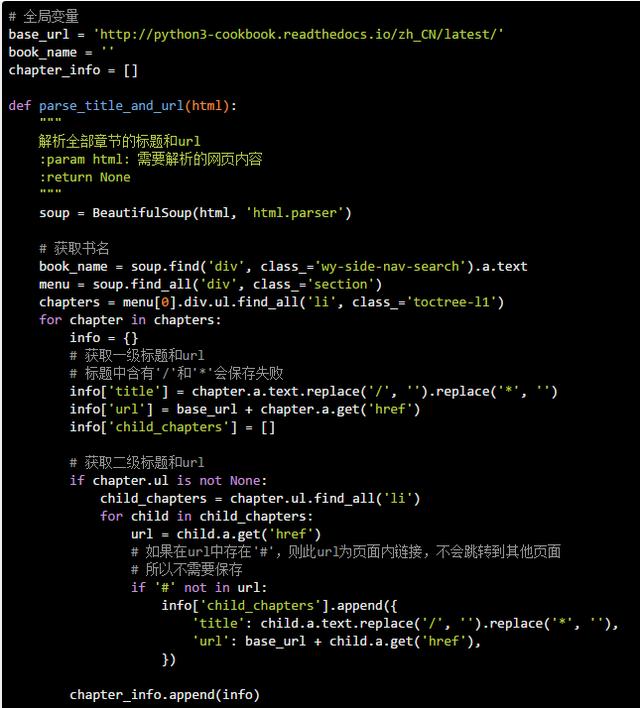
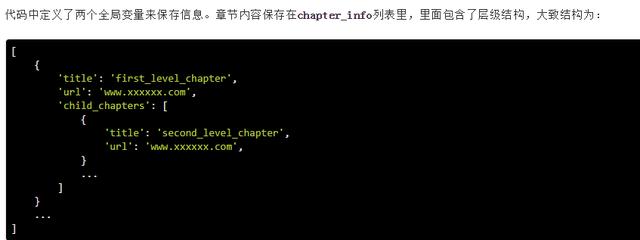
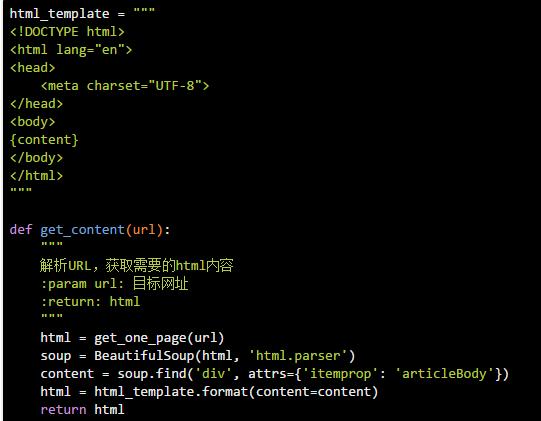
3.3 获取章节内容
还是同样的方法定位章节内容:
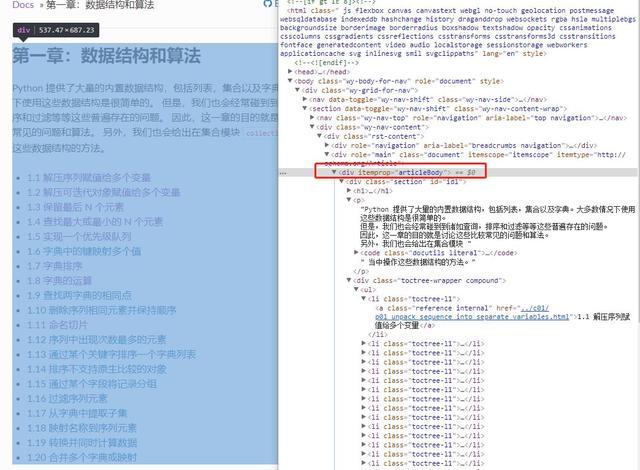

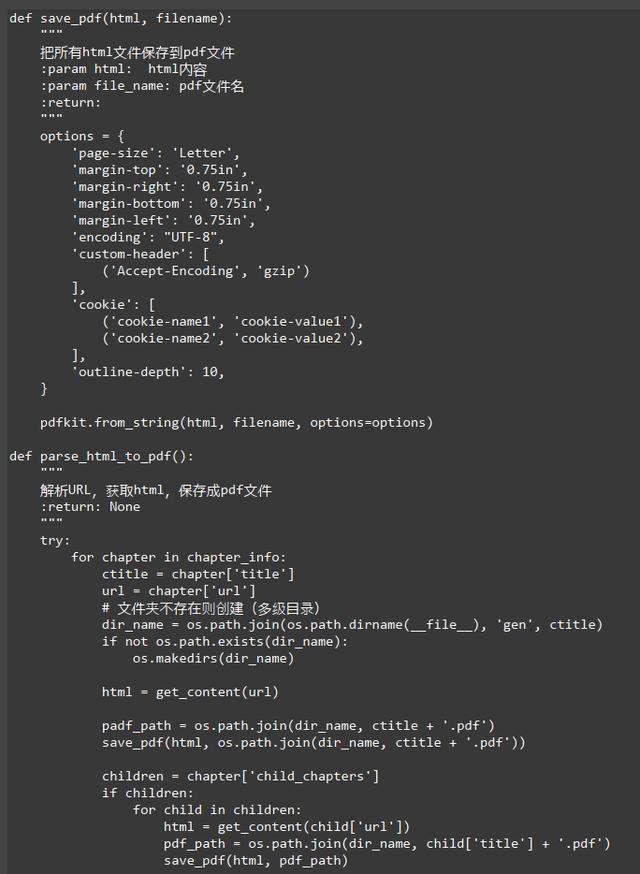
3.4 保存pdf
3.5 合并pdf
经过上一步,所有章节的pdf都保存下来了,最后我们希望留一个pdf,就需要合并所有pdf并删除单个章节pdf。
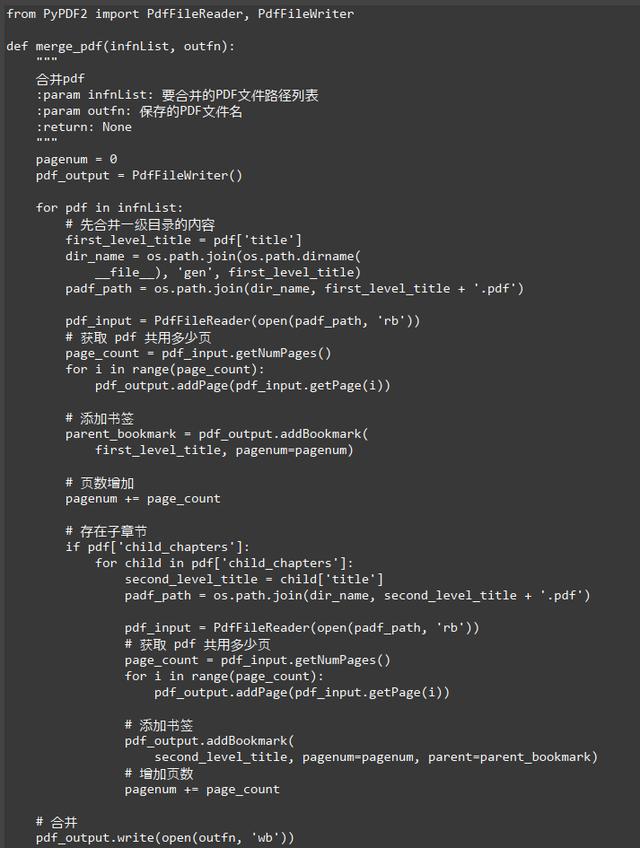
本来PyPDF2库中有一个类PdfFileMerger专门用来合并pdf,但是在合并过程中会抛出异常,网上有人也遇到同样的问题,解决办法是修改库源码,本着“不动库源码”的理念,毅然选择了上面这种比较笨的办法,代码还是比较好理解的。
经过以上几个步骤,我们想要的pdf文件已经生成,一起来欣赏一下劳动成果:

06.保存成果
欢迎大家关注我的博客:https://home.cnblogs.com/u/sm123456/ 答疑互动交流尽在博客园
欢迎大家加入千人交流答疑群:125240963
以上是关于利用Python爬取在线教程!并把它转为PDF,方便学习!的主要内容,如果未能解决你的问题,请参考以下文章