python学习 —— B站抢楼原理
Posted darkchii
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python学习 —— B站抢楼原理相关的知识,希望对你有一定的参考价值。
注意声明:本篇仅基于兴趣以及技术研究而对B站曾经发生过的抢楼事件背后的技术原理进行解析。请不要将其作为私利而对B站以及B站用户体验造成影响!谢谢合作!若本文对B站带来困扰,本人将自行删除本文。
虽然说是技术研究,但实际上并没有什么太深的东西在里面,你只需要懂一点http协议的请求格式、懂python、会使用python requests package就能完成这个简单的任务了。
如果你不懂,并想要弄懂这几点知识,可以试试:
1.http协议的请求格式我推荐看看这两篇:https://blog.csdn.net/a19881029/article/details/14002273、https://blog.csdn.net/Stream__/article/details/78604937。
2.python2/3学习:网上学吧,如果你有其他语言编程基础,应该很快就能上手使用python,否则,就认真从基础开始学习python这门语言。
3.python requests package文档:http://docs.python-requests.org/zh_CN/latest/
最后你肯定得有一个浏览器,我推荐Chrome —— 个人喜好。最好还有一个PyCharm或者其他python编辑器,如果你只喜欢用python自带的命令行也行。
然后说一点,现在B站为了防止抢楼,把番剧下所有视频的评论区都合并了,以前每一个视频下都会有对应的评论区,现在所有视频的评论全部在一起的。。。所以就算要抢也只有对新番第一集抢楼可能才有‘意义’了。
工具都准备好了,让我们开始吧:
这里随便选了一部老番《D.C.Ⅱ S.S.》又称《初音岛》作为测试。
来到番剧剧集页面,先F12准备监控一会儿发送请求数据的网络状态:
当我们要进行这个任务的时候,我们必须要先知道:我们该向什么地方发送的请求?难道就直接对番剧页面发送就可以了吗?如果有做过网站的经验就会知道,一个网站的前端展示页面基本上都是通过 js + ajax 等通过后台的业务逻辑调用数据库中的数据加载到对应的jsp文件中的html标签中自动生成的。比如评论区,肯定有一个 post 的API接口来接受用户发送的数据,并将数据存入到数据库中,然后展示页面 + js + 数据库 + 后台业务逻辑等一套服务,最后我们用户才能在前端中看到丰富的内容,才能看到实时更新的数据,说实时更新不太对,但总之你每次刷新页面,网站后台就会做这些事情。
这些有什么用呢?至少我知道了当我在B站评论区编辑好要发送的消息并点击发送评论的时候,肯定是通过一个特地编写好的接口来post data,而这个post接口的url会在我们点击按钮的动作后显示在浏览器的网络监控中,所以,我们要找到这个接口的url就要先发送一个消息试一试:
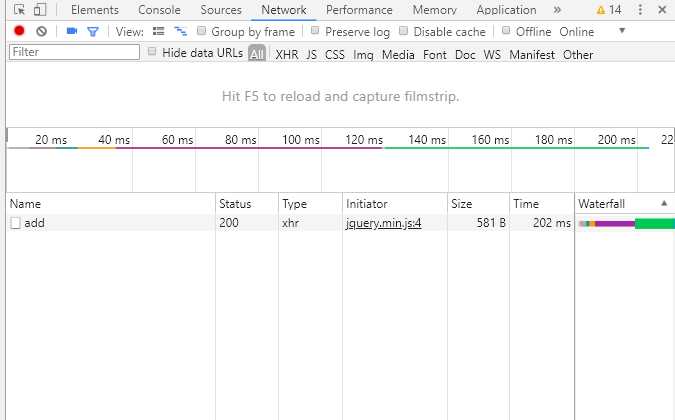
最好就是在浏览器加载完该页面的数据后按F12打开监控台,这样比较干净,点击发表评论后,很快就可以注意到我们的动作的回馈,点一下看看内容:
显然,它是通过http post动词来提交的,从中我找到了这个add接口的url:
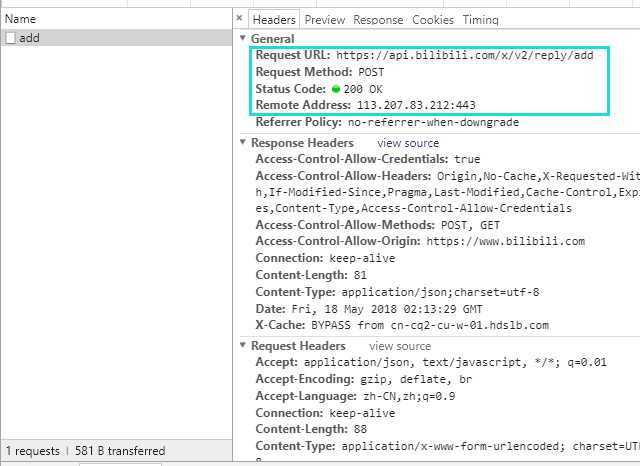
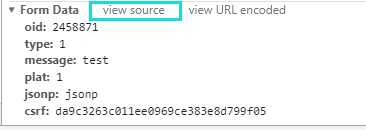
到这里已经可以宣告结束了。注意到Request Headers中就是我们需要自定义添加的请求头内容,然后,很关键的地方就是发送内容,它一般在Chrome监控台最下面:
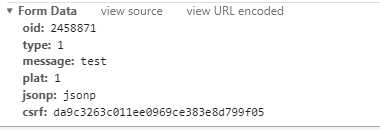
oid对应当前视频的av号,这样才能确定是对哪一个视频进行的评论,可以在视频页面这里获取它:
这里type的含义不重要,message显然是我们要发送的东西,注意message如何是中文,那么将会进行url编码,可以参考:http://www.w3school.com.cn/tags/html_ref_urlencode.html
后面几个除csrf外的含义在这里也并不重要,不知道是不是B站换了(之前的不是这个,还是因为不同番剧下的csrf不一样,如果是不同番剧下的csrf不一样的话,这可能说明,对于一部新番,使用这样的方法我们第一集并不能强到楼。。。不过我也不知道使用同样的csrf能不能有效,但同一部番剧下的所有视频应该可以使用同样的csrf,不过这也只是我的想法,我并没有验证过。。。
ps:刚才我对新番Comic Girls用同样的csrf试了一下,成功了:

B站评论区效果:
但其实我更觉得比较侥幸的是,B站的发送评论并没有做非常复杂的验证,假如有一个服务器端的系统时间的key-value段,那么我就跪了...我们在python中使用它们:
data = {
‘oid‘: ‘2458871‘,
‘type‘: ‘1‘,
‘message‘: ‘test~‘,
‘plat‘: ‘1‘,
‘jsonp‘: ‘jsonp‘,
‘csrf‘: ‘da9c3263c011ee0969ce383e8d799f05‘
}
然后利用浏览器中的Request Headers写好我们的请求头:
headers = {
‘Accept‘: ‘application/json, text/javascript, */*; q=0.01‘,
‘Accept-Encoding‘: ‘gzip, deflate, br‘,
‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘,
‘Connection‘: ‘keep-alive‘,
‘Content-Length‘: ‘xxx‘, # 这里对应的就是我们的data数据的长度
‘Cookie‘: ‘xxx‘,
‘Host‘: ‘api.bilibili.com‘,
‘Referer‘: ‘https://www.bilibili.com/bangumi/play/ep86125‘,
‘User-Agent‘: ‘xxx‘,
}
这里上面注释中的长度可以这样获取,来到浏览器:
点击蓝色区域变为:

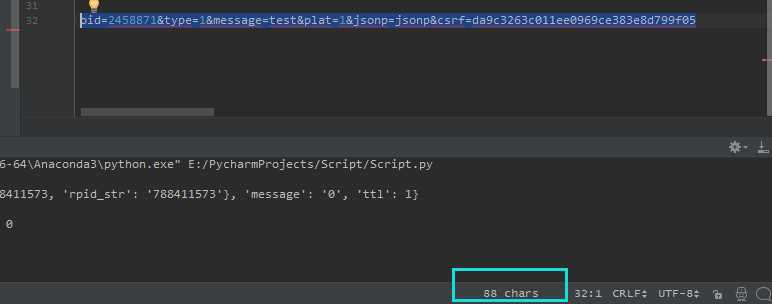
当然你可以肉眼一个个字符的数,但我还是选择复制一下这段字符串,然后到粘贴到PyCharm中,选中粘贴上去的那段字符串,然后蓝色框住的部分就是字符串的长度,也就是这里我们的Content-Length的长度:
但这是测试过后得到了add中的data信息才能知道长度,如果对一部没有add信息的视频,还是自己将data转换为浏览器中的拼接参数格式的字符串,然后用python len算一下字符串长度:
content_length = len(str(data).replace(‘: ‘, ‘=‘).replace(‘,‘, ‘&‘).replace(‘\\‘‘, ‘‘))
或者直接len(str(data)),因为Content-Length对于填写并不严格,但虽然Content-Length对于填写并不严格,但就算随便填写长度也必须要比实际长度大,因为这样从推断上请求内容就应该是损坏的。
删除这段字符串,开始使用requests post:
r = request.post(url, data=data, headers=headers, timeout=1, ) print(r.status_code) print(r.json()) # r.text
值得注意的一点是,有些接口的请求内容是data参数,data参数仅仅就是转换为字符串,而还有一些接口的请求内容格式是json,这时就只需要将data改为使用json即可,详细的可以对准post方法 Ctrl + 左键 看看源码:
r = request.post(url, json=json)
到这里,这样就完成了发送评论,但我想再提一点:有兴趣你可以去掉请求头试试效果,然后考虑一下哪些headers中的key-value可以去掉,哪些不能?
------------------- 提出上面思考的主要原因 ---------------------
我试过这样写:
from requests import Session
request = Session()
url = ‘https://api.bilibili.com/x/v2/reply/add‘
data = {
‘oid‘: ‘2458871‘,
‘type‘: ‘1‘,
‘message‘: ‘test~‘,
‘plat‘: ‘1‘,
‘jsonp‘: ‘jsonp‘,
‘csrf‘: ‘da9c3263c011ee0969ce383e8d799f05‘
}
r = request.post(url, data=data, auth=(‘user‘, ‘pw‘), timeout=1, )
print(r.status_code)
print(r.json()) # r.text
显然被残酷的拒绝了:

这就是没有做好Cookie的原因了。Cookie中包含了登录用户的信息,所以Cookie必不可少,我们光用auth模拟登录是行不通的,因为B站还有登录验证呢...
最后,看似很顺利的过程,其中也包含了许多知识点,还有许多细节还得要自己去体会...要学的还有很多~ 我一直想要下载B站的视频,但一直没能完成。。。
以上是关于python学习 —— B站抢楼原理的主要内容,如果未能解决你的问题,请参考以下文章