python3 爬取qq音乐作者所有单曲 并且下载歌曲
Posted 二郎神
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3 爬取qq音乐作者所有单曲 并且下载歌曲相关的知识,希望对你有一定的参考价值。
1 import requests 2 import re 3 import json 4 import os 5 6 7 8 # 便于存放作者的姓名 9 zuozhe = [] 10 11 headers = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36\'} 12 13 14 def get_singermid(): 15 name = input(\'请输入你要下载歌曲的作者:\') 16 zuozhe.append(name) 17 if not os.path.exists(name): 18 os.mkdir(name) 19 url = \'https://c.y.qq.com/soso/fcgi-bin/client_search_cp\' 20 headers = {\'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36\'} 21 data = { 22 \'w\': name, 23 \'jsonpCallback\': \'MusicJsonCallback885332333726736\',} 24 response = requests.get(url,headers=headers,params=data).text 25 patt = re.compile(\'MusicJsonCallback\\d+\\((.*?)\\}\\)\') 26 singermid = re.findall(patt,response)[0] 27 singermid = singermid+\'}\' 28 dic = json.loads(singermid) 29 return dic[\'data\'][\'song\'][\'list\'][0][\'singer\'][0][\'mid\'] 30 31 32 def get_page_html(singermid): 33 url = \'https://c.y.qq.com/v8/fcg-bin/fcg_v8_singer_track_cp.fcg\' 34 params = { 35 \'g_tk\': 5381, 36 \'jsonpCallback\': \'MusicJsonCallbacksinger_track\', 37 \'loginUin\': 0, 38 \'hostUin\': 0, 39 \'format\': \'jsonp\', 40 \'inCharset\': \'utf8\', 41 \'outCharset\': \'utf-8\', 42 \'notice\': 0, 43 \'platform\': \'yqq\', 44 \'needNewCode\': 0, 45 \'singermid\': singermid, 46 \'order\': \'listen\', 47 \'begin\': 0,# 页数 0 30 60 48 \'num\': 30, 49 \'songstatus\': 1, 50 } 51 response = requests.get(url,headers=headers,params=params) 52 return response.text 53 54 55 def get_vkey_data(songmid,strMediaMid,name): 56 url = \'https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg\' 57 strMediaMid1 = \'C400\'+strMediaMid+\'.m4a\' 58 data = { 59 \'g_tk\': 5381, 60 \'jsonpCallback\': "MusicJsonCallback4327043425715609", 61 \'loginUin\': 0, 62 \'hostUin\': 0, 63 \'format\': \'json\', 64 \'inCharset\': \'utf8\', 65 \'outCharset\': \'utf-8\', 66 \'notice\': 0, 67 \'platform\': \'yqq\', 68 \'needNewCode\': 0, 69 \'cid\': 205361747, 70 \'callback\': \'MusicJsonCallback4327043425715609\', 71 \'uin\': 0, 72 \'songmid\': songmid, 73 \'filename\': strMediaMid1, 74 \'guid\': 4428680404, 75 } 76 response = requests.get(url,headers=headers,params=data).text 77 try: 78 patt = re.compile(\'\\"vkey\\":\\"(.*?)\\"\') 79 vkey = re.findall(patt,response)[0] 80 patt = re.compile(\'\\"filename\\":\\"(.*?)\\"\') 81 filename = re.findall(patt, response)[0] 82 url1 = \'http://dl.stream.qqmusic.qq.com/\' + filename + \'?vkey=\' + vkey + \'&guid=4428680404&uin=0&fromtag=66\' 83 yingyue = requests.get(url1,headers=headers).content 84 with open(zuozhe[0]+\'/\'+name+\'.m4a\',\'wb\') as f: 85 f.write(yingyue) 86 f.close() 87 print(\'下载完成《\'+name+\'》\') 88 except Exception as e: 89 print(e) 90 pass 91 92 93 def get_detail_html(html): 94 if html: 95 patt = re.compile(\'data\\":{\\"list\\":(.*?),\\"singer_id\',re.S) 96 json_html = re.findall(patt,html)[0] 97 data_html = json.loads(json_html) 98 for data in data_html: 99 name = data[\'musicData\'][\'songname\'] 100 songmid = data[\'musicData\'][\'songmid\'] 101 strMediaMid = data[\'musicData\'][\'strMediaMid\'] 102 print(\'正在下载《\' + name + \'》......\') 103 get_vkey_data(songmid,strMediaMid,name) 104 105 def main(): 106 # 获取 singermid 107 singermid = get_singermid() 108 html = get_page_html(singermid) 109 get_detail_html(html) 110 111 112 if __name__ == \'__main__\': 113 main()
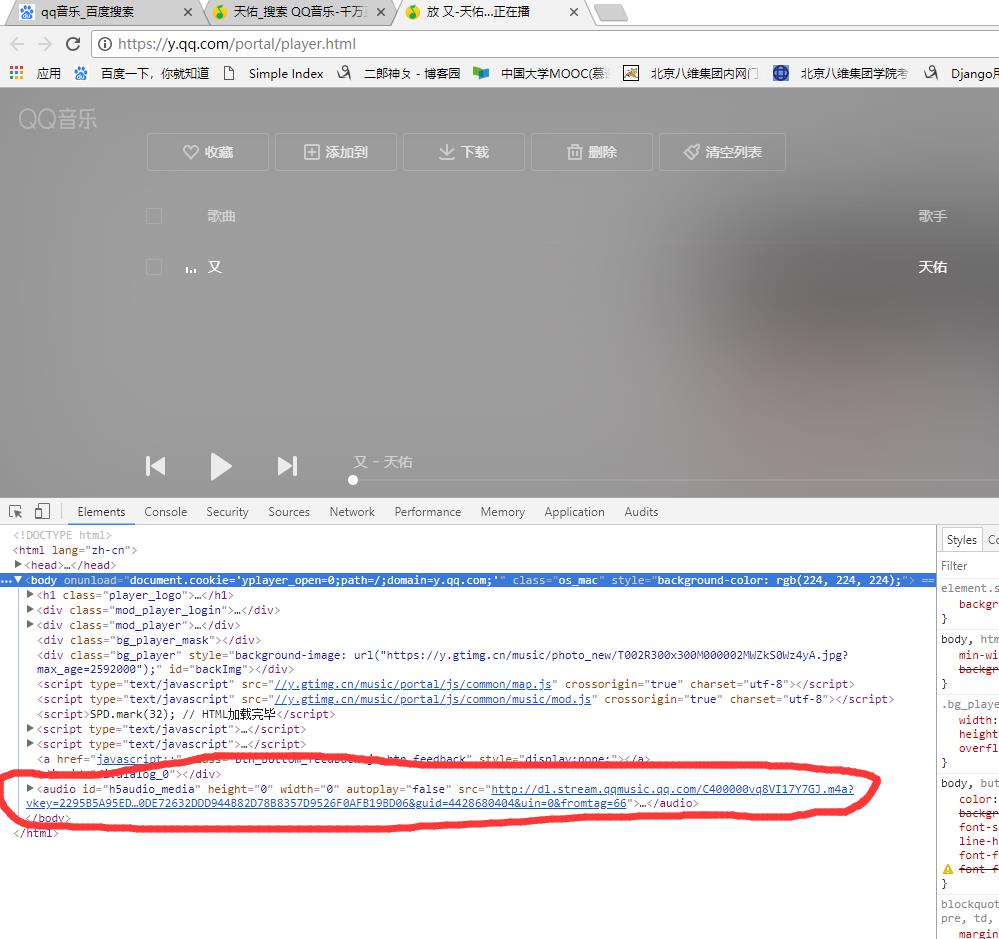
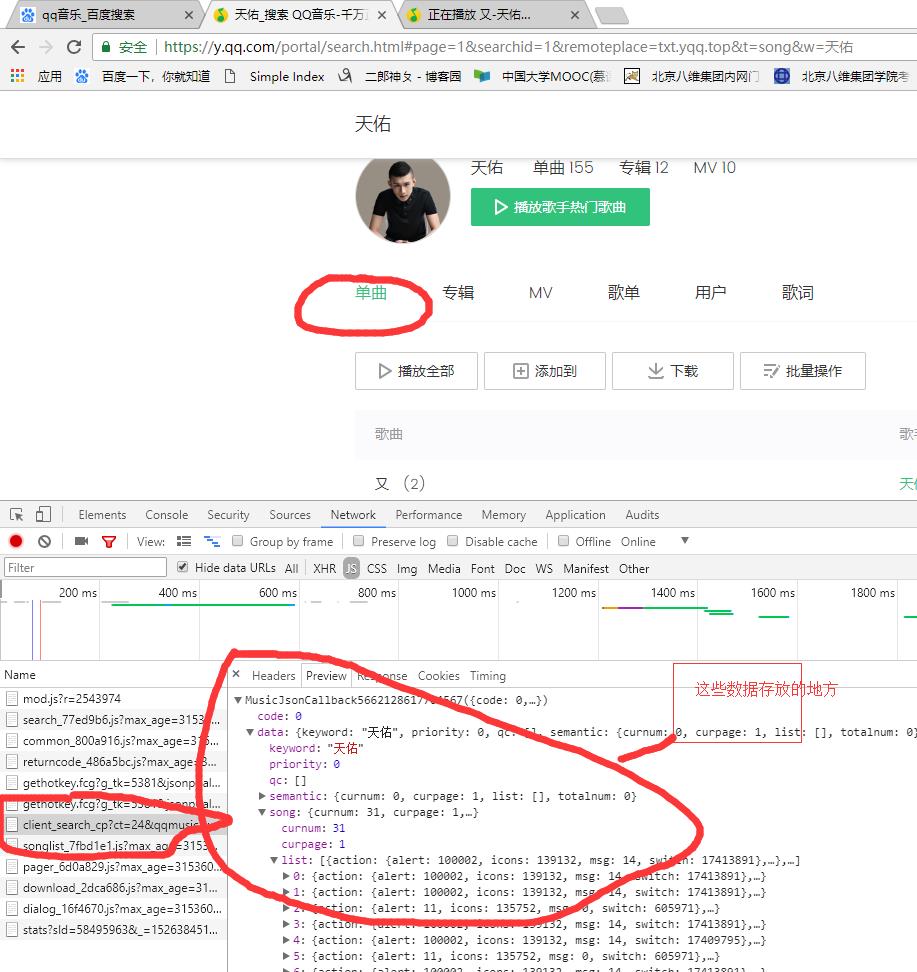
爬取qq音乐首先得找到\'http://dl.stream.qqmusic.qq.com/\' + filename + \'?vkey=\' + vkey + \'&guid=4428680404&uin=0&fromtag=66\'这个链接 然后其中只有filename 和vkey 在变化 然后就在列表页寻找这两个参数,找到以后拼接到这个url,然后请求就可以了 。
代码在上面只供参考
python3 可以直接复制然后运行
以上是关于python3 爬取qq音乐作者所有单曲 并且下载歌曲的主要内容,如果未能解决你的问题,请参考以下文章