python学习笔记——爬虫的抓取策略
Posted gengyi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python学习笔记——爬虫的抓取策略相关的知识,希望对你有一定的参考价值。
1 深度优先算法
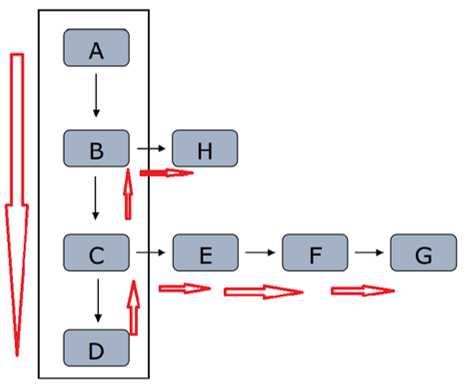
2 广度/宽度优先策略
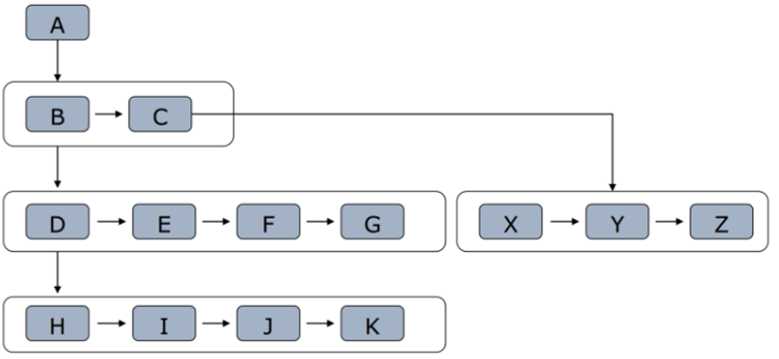
3 完全二叉树遍历结果
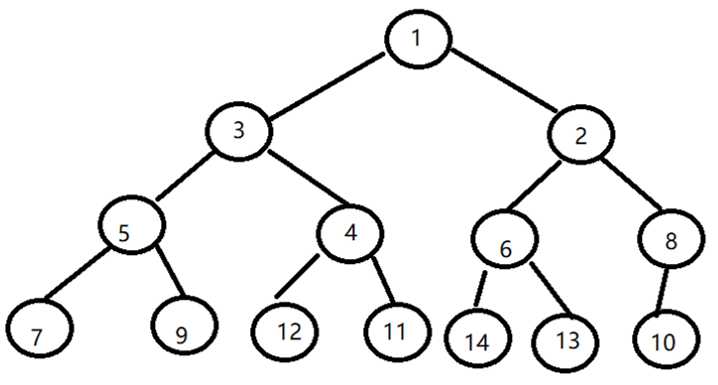
深度优先遍历的结果:[1, 3, 5, 7, 9, 4, 12, 11, 2, 6, 14, 13, 8, 10]
广度优先遍历的结果:[1, 3, 2, 5, 4, 6, 8, 7, 9, 12, 11, 14, 13, 10]
4 实践中怎么来组合爬取策略
(1)一般来说,重要的网页距离入口站点的距离很近;
(2)广度/宽度优先有利于多爬虫并行进行合作;
(3)可以考虑将深度与广度/宽度相结合的方式来实现抓取的策略:优先考虑广度优先,对深度进行限制最大深度。
5 一个通用爬虫的流程如下
(1)设置种子站点、宽度及深度
(2)一个已下载的队列来记录所有已经完成下载的url
(3)实现一个函数,取得当前url的内容以及所有的外链接
(4)递归调用这个函数,来遍历网站
(5)错误日志处理
以上是关于python学习笔记——爬虫的抓取策略的主要内容,如果未能解决你的问题,请参考以下文章