在python中单线程,多线程,多进程对CPU的利用率实测以及GIL原理分析
Posted __S k y L a r k
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在python中单线程,多线程,多进程对CPU的利用率实测以及GIL原理分析相关的知识,希望对你有一定的参考价值。
首先关于在python中单线程,多线程,多进程对cpu的利用率实测如下:
单线程,多线程,多进程测试代码使用死循环。
1)单线程:
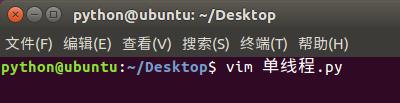
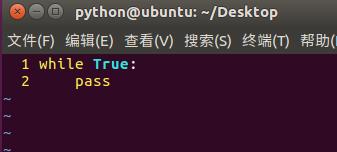
2)多线程:
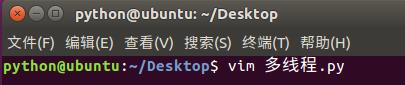

3)多进程:
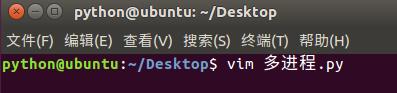

查看cpu使用效率:
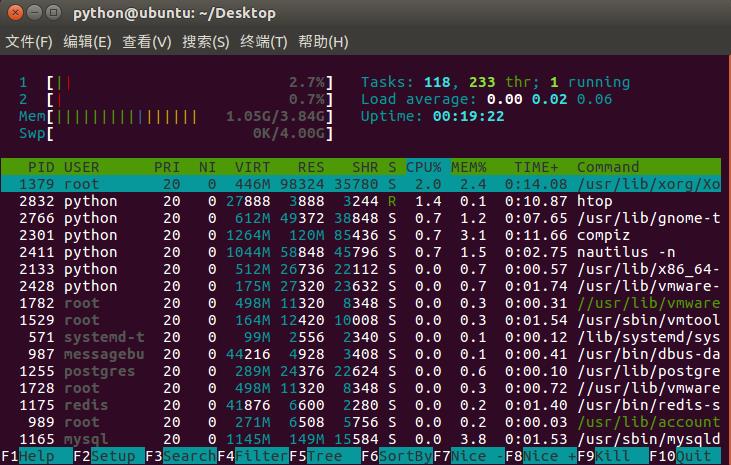
开始观察分别执行时候cpu的使用效率:
1)单线程执行的时候:
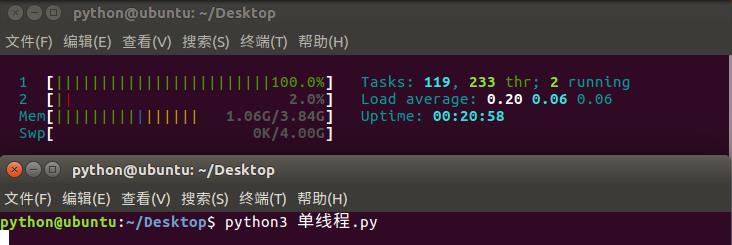
2)多线程执行的时候:

3)多进程执行的时候:

总结:
1)单进程单线程时,对于双核CPU的利用率只能利用一个核,没有充分利用两个核。
2)单进程多线程时,对于双核CPU的来说,虽然两个核都用到的,不过很明显没有充分利用两个核,这里要说一个GIL(全局解释器锁)的概念:
GIL不同于线程之间的互斥锁,GIL并不是Python的特性,而是Cpython引入的一个概念。(Jpython,PYPY)
Python的代码由Python的解释器执行(CPython)。那么我们的代码什么时候被python解释器执行,由我们的GIL也就是全局解释器锁进行控制。
当我们有一个线程开始访问解释器的时候,GIL会将这把锁上锁,也就是说,其他线程无法再访问解释器,也就意味着,其他的线程无法再被执行。
GIL执行流程:
-
加锁GIL。
-
切换到一个线程去执行。
-
运行。
-
解锁GIL。
再次重复以上步骤。
对于下列代码GIL的执行流程:
import threading
import time
# 写两个函数,分别让两个线程去执行
# 这个两个函数,都要访问我的全局变量
number = 0
def test1(count):
global number
for i in range(count):
number += 1
print(number)
def test2(count):
global number
for i in range(count):
number += 1
print(number)
def main():
th1 = threading.Thread(target=test1,args= (1000000,))
th2 = threading.Thread(target=test2, args=(1000000,))
th1.start()
th2.start()
time.sleep(5)
print(number)
if __name__ == \'__main__\':
main()
运行结果(这里充分的说明了多线程资源抢占问题):

流程图如下:

线程1在执行到对全局变量加一操作的时候全局解释器锁被收回,线程2申请并得到了全局解释器锁开始运行,在线程2执行完加一操作以后对全局变量进行了修改并释放了全局解释器锁。
这时线程1再次得到了全局解释器锁,从上次释放全局解释器锁的地方开始继续执行对全局变量加一的操作,记住,这里线程1中的全局变量还是开始的0,虽然线程2已经对其进行了加一的操作,但是线程1并不知道,线程1还是会接着上一次的位置开始执行,所以线程1在执行完加一操作的时候同样把1再次赋值给了全局变量num,也就是说,线程2执行完加一操作之后赋值过去的1又被线程1赋值过去的1所覆盖,加了两次等于加了一次!类似于协程,只是做了一个执行代码来回切换的操作!
所以在Python中,同一时刻,只能有一个线程被执行。所以Python中的多线程是假的。
既然这样我们为什么还要用多线程呢?
其实多线程也有它的好处,例如我们在进行IO操作的时候,有效的组织了程序的阻塞,不至于一直无限的等待。
3)多进程时,对于双核CPU来说,每个进程的优先级都是同等的,所分配的资源也是相等的,两个进程的时候完全可以充分的利用双核CPU,而且由于计算密集型的任务完全是依靠于cpu的核数,所以需要尽量的完全利用cpu,这时候多进程的好处就能够完美的体现出来。
以上是关于在python中单线程,多线程,多进程对CPU的利用率实测以及GIL原理分析的主要内容,如果未能解决你的问题,请参考以下文章