如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)相关的知识,希望对你有一定的参考价值。

前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入。
一、代码实现
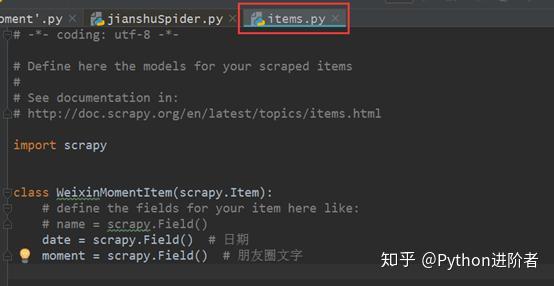
1、修改Scrapy项目中的items.py文件。我们需要获取的数据是朋友圈和发布日期,因此在这里定义好日期和动态两个属性,如下图所示。
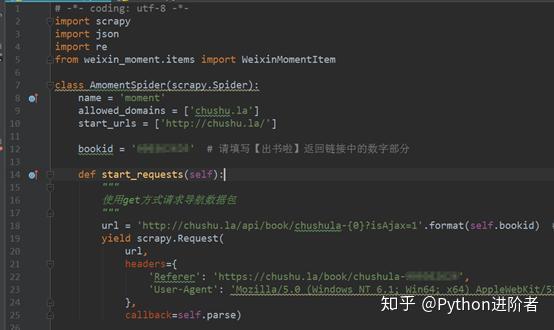
2、修改实现爬虫逻辑的主文件moment.py,首先要导入模块,尤其是要主要将items.py中的WeixinMomentItem类导入进来,这点要特别小心别被遗漏了。之后修改start_requests方法,具体的代码实现如下图。
3、修改parse方法,对导航数据包进行解析,代码实现稍微复杂一些,如下图所示。
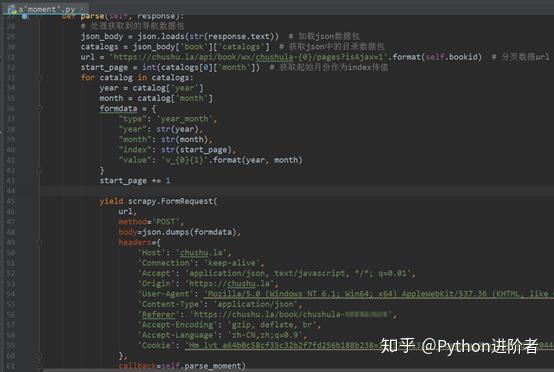
l需要注意的是从网页中获取的response是bytes类型,需要显示的转为str类型才可以进行解析,否则会报错。
l在POST请求的限定下,需要构造参数,需要特别注意的是参数中的年、月和索引都需要是字符串类型的,否则服务器会返回400状态码,表示请求参数错误,导致程序运行的时候报错。
l在请求参数还需要加入请求头,尤其是Referer(反盗链)务必要加上,否则在重定向的时候找不到网页入口,导致报错。
l上述的代码构造方式并不是唯一的写法,也可以是其他的。
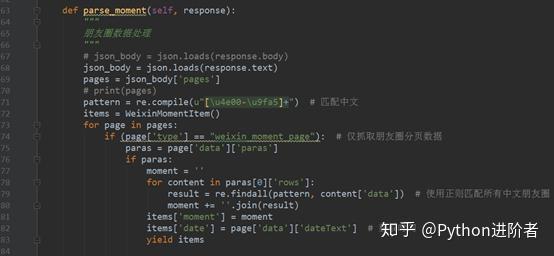
4、定义parse_moment函数,来抽取朋友圈数据,返回的数据以JSON加载的,用JSON去提取数据,具体的代码实现如下图所示。
5、在setting.py文件中将ITEM_PIPELINES取消注释,表示数据通过该管道进行处理。
6、之后就可以在命令行中进行程序运行了,在命令行中输入scrapy crawl moment -o moment.json,之后可以得到朋友圈的数据,在控制台上输出的信息如下图所示。
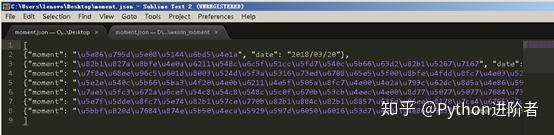
7、尔后我们得到一个moment.json文件,里面存储的是我们朋友圈数据,如下图所示。
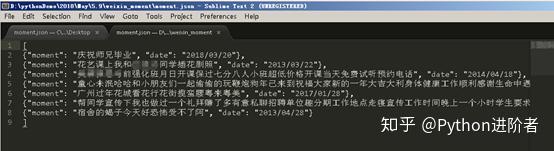
8、嗯,你确实没有看错,里边得到的数据确实让人看不懂,但是这个并不是乱码,而是编码的问题。解决这个问题的方式是将原来的moment.json文件删除,之后重新在命令行中输入下面的命令:scrapy crawl moment -o moment.json -s FEED_EXPORT_ENCODING=utf-8,此时可以看到编码问题已经解决了,如下图所示。
下一篇文章,小编带大家将抓取到的朋友圈数据进行可视化展示,敬请关注~~
以上是关于如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)的主要内容,如果未能解决你的问题,请参考以下文章
如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例
如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例
如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例
如何利用Python词云和wordart可视化工具对朋友圈数据进行可视化展示