前言
有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息。selenium的page_source方法可以获取到页面源码。
selenium的page_source方法很少有人用到,小编最近看api不小心发现这个方法,于是突发奇想,这里结合python的re模块用正则表达式爬出页面上所有的url地址,可以批量请求页面url地址,看是否存在404等异常
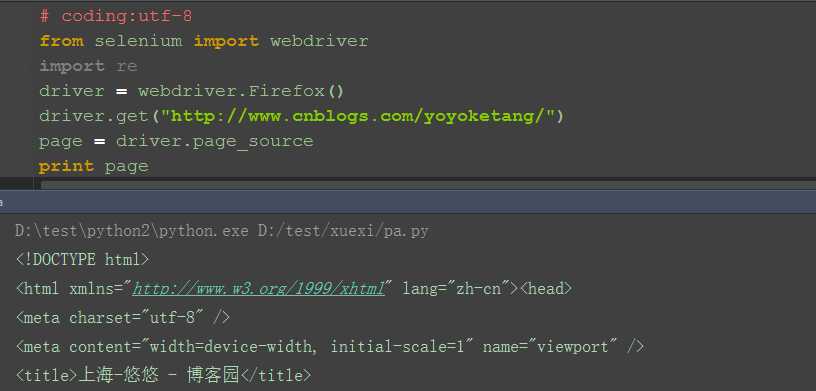
一、page_source
1.selenium的page_source方法可以直接返回页面源码
2.重新赋值后打印出来
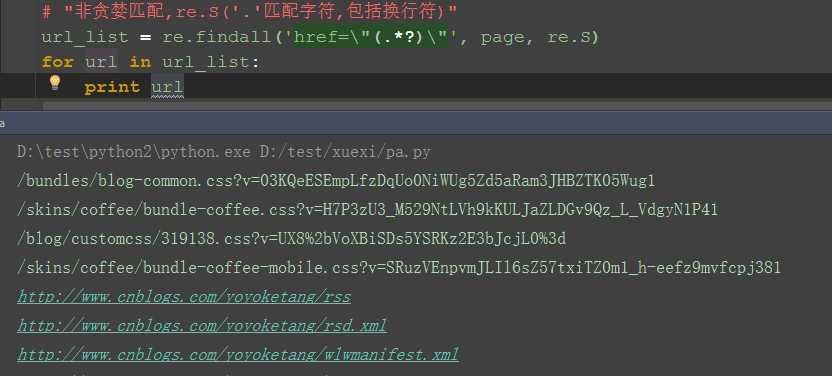
二、re非贪婪模式
1.这里需导入re模块
2.用re的正则匹配:非贪婪模式
3.findall方法返回的是一个list集合
4.匹配出来之后发现有一些不是url链接,可以删选下
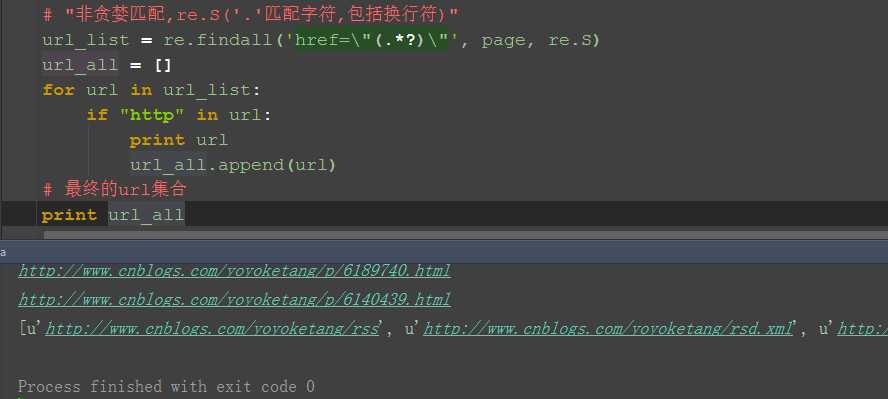
三、删选url地址出来
1.加个if语句判断,‘http’在url里面说明是正常的url地址了
2.把所有的url地址放到一个集合,就是我们想要的结果啦
四、参考代码
# coding:utf-8
from selenium import webdriver
import re
driver = webdriver.Firefox()
driver.get("http://www.cnblogs.com/yoyoketang/")
page = driver.page_source
# print page
# "非贪婪匹配,re.S(‘.‘匹配字符,包括换行符)"
url_list = re.findall(‘href=\\"(.*?)\\"‘, page, re.S)
url_all = []
for url in url_list:
if "http" in url:
print url
url_all.append(url)
# 最终的url集合
print url_all