Elasticsearch搜索功能的实现--搜索引擎为什么选ES
Posted gdwkong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch搜索功能的实现--搜索引擎为什么选ES相关的知识,希望对你有一定的参考价值。
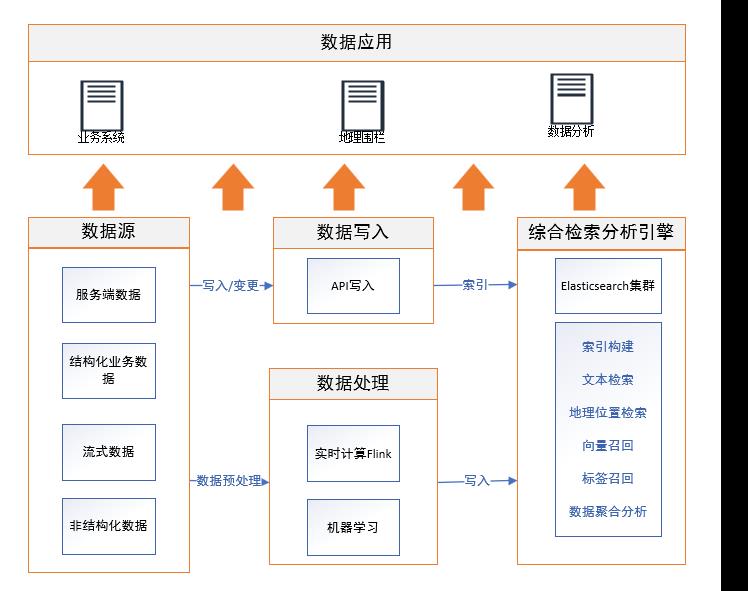
一、应用场景
Elasticsearch 具有广泛的应用场景,包括全文搜索、日志分析、运维监控、安全分析等。
Elasticsearch 是开源的实时分布式搜索分析引擎,内部使用 Lucene 做索引与搜索。适用场景包含信息检索、舆情分析、推荐系统、广告系统等多种对综合检索&召回有需求的场景。
二、为什么 Elasticsearch倒排索引快
正排索引是从文档到关键字的映射(已知文档求关键字);
倒排索引是从关键字到文档的映射(已知关键字求文档);
1、正向索引
正向索引(正排索引):正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
“文档1”的ID > 关键词1:出现次数,出现位置列表;关键词2:出现次数,出现位置列表;…………。
“文档2”的ID > 此文档出现的关键词列表。
| 文档ID | 内容所切分出的关键词 |
|---|---|
| 文档1 | 关键词1、关键词2、关键词5、关键词11......关键词L |
| 文档2 | 关键词3、关键词5、关键词7......关键词M |
| 文档3 | 关键词2、关键词4、关键词8......关键词N |
| 文档4 | 关键词61、关键词9、关键词10......关键词O |
| ...... | ...... |
| 文档n | 关键词9、关键词15、关键词21......关键词P |
优点:易于维护:新增的话直接跟在原来的后面,删除的话直接删除某一条即可
缺点:查询时间长,检索效率低下
例如:当用户搜索关键词的时候,比如用户搜索关键词5,会按照id顺序依次找到有关键词5的页面,服务器还需要对所有索引的页面进行检索,消耗的资源非常大。
如果用户搜索的是长尾词,比如说“关键词2+关键词5”,这种相关性的计算资源消耗就更大了,耗时也更长!
2、倒排索引
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
倒排索引的结构如下:
“关键词1”:“文档1”的ID,“文档2”的ID,…………。
“关键词2”:带有此关键词的文档ID列表。
| 关键词 | 文档 |
|---|---|
| 关键词1 | 文件1、文件2、文件5、文件11......文件L |
| 关键词2 | 文件3、文件5、文件7......文件M |
| 关键词3 | 文件2、文件4、文件8......文件N |
| 关键词4 | 文件61、文件9、文件10......文件O |
| ...... | ...... |
| 关键词n | 文件9、文件15、文件21......文件P |
优点:检索的快速响应是一个最为关键的性能
缺点:倒排表的建立和维护都较为复杂(索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率)
这样一来,当用户搜索关键词2+关键词5 的时候,搜索引擎只需要将包含关键词2且包含关键词5的文件调用出来,然后计算它们的相关度和权重。倒排索引的应用,大大加快了呈现排名的速度,减轻了服务器计算的压力。
倒排索引中,不仅会记录相应关键词文件的ID,还会记录关键词频次、关键词出现在文件中的位置、关键词对应的文档更新频率等信息,在排名的时候,这些信息会被进行加权处理。
Elasticsearch | 深入理解
Elasticsearch | 深入理解(一)
- 简介:Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。Elasticsearch使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTfulAPI 来隐藏Lucene的复杂性,从而让全文搜索变得简单
- 特性:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
- 安装(单节点安装)
-
要求 java环境

-
你可以从 es 下载最新版本的Elasticsearch
-
安装Marvel
Marvel是Elasticsearch的管理和监控工具,在开发环境下免费使用(可选) -
安装es需要新建es用户不能直接用root用户启动
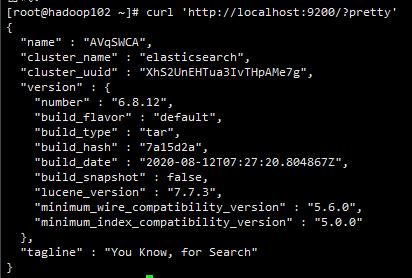
adduser elasticsearchpasswd elasticsearchchown -R elasticsearch elasticsearch-6.8.12su elasticsearch./elasticsearch -d守护进程启动curl \'http://localhost:9200/?pretty\'测试
-
es2.x版本删除了_shutdown api
- 关闭
- 前台模式 直接ctrl+c
- 守护进程 查找pid + kill -9
- 安装(多节点集群安装)
- 准备环境 3台Linux机器
- 安装jdk
- 安装es
rpm -ivh elasticsearch-6.5.4.rpm或者解压包自己安装 - 系统安装配置es路径 自己安装在目录
conf下
/etc/elasticsearch/elasticsearch.yml # els的配置文件 /etc/elasticsearch/jvm.options # JVM相关的配置,内存大小等等 /etc/elasticsearch/log4j2.properties # 日志系统定义 /usr/share/elasticsearch # elasticsearch 默认安装目录 /var/lib/elasticsearch # 数据的默认存放位置- 创建用于存放数据与日志的目录
- 数据文件会随着系统的运行飞速增长,所以默认的日志文件与数据文件的路径不能满足我们的需求,那么手动创建日志与数据文件路径,可以使用NFS、可以使用Raid等等方便以后的管理与扩展
mkdir -p /opt/elasticsearch/data mkdir -p /opt/elasticsearch/log chown -R elasticsearch.elasticsearch /opt/elasticsearch/* - 集群配置
- 集群配置中最重要的两项是
node.name与network.host,每个节点都必须不同。其中node.name是节点名称主要是在Elasticsearch自己的日志加以区分每一个节点信息。
discovery.zen.ping.unicast.hosts是集群中的节点信息,可以使用IP地址、可以使用主机名(必须可以解析)
vim /etc/elasticsearch/elasticsearch.yml cluster.name: my-els # 集群名称 node.name: els-node1 # 节点名称,仅仅是描述名称,用于在日志中区分 path.data: /opt/elasticsearch/data # 数据的默认存放路径 path.logs: /opt/elasticsearch/log # 日志的默认存放路径 network.host: 192.168.60.201 # 当前节点的IP地址 http.port: 9200 # 对外提供服务的端口,9300为集群服务的端口 #添加如下内容 #culster transport port transport.tcp.port: 9300 transport.tcp.compress: true discovery.zen.ping.unicast.hosts: ["192.168.60.201", "192.168.60.202","192.168.60.203"] # 集群个节点IP地址,也可以使用els、els.shuaiguoxia.com等名称,需要各节点能够解析 discovery.zen.minimum_master_nodes: 2 # 为了避免脑裂,集群节点数最少为 半数+1 - 集群配置中最重要的两项是
- JVM配置
- 由于Elasticsearch是Java开发的,所以可以通过
/etc/elasticsearch/jvm.options配置文件来设定JVM的相关设定。如果没有特殊需求按默认即可
不过其中还是有两项最重要的-Xmx1g与-Xms1gJVM的最大最小内存。如果太小会导致Elasticsearch刚刚启动就立刻停止。太大会拖慢系统本身
vim /etc/elasticsearch/jvm.options -Xms1g # JVM最大、最小使用内存 -Xmx1g - 由于Elasticsearch是Java开发的,所以可以通过
- 创建用于存放数据与日志的目录
- 数据文件会随着系统的运行飞速增长,所以默认的日志文件与数据文件的路径不能满足我们的需求,那么手动创建日志与数据文件路径,可以使用NFS、可以使用Raid等等方便以后的管理与扩展
mkdir -p /opt/elasticsearch/data mkdir -p /opt/elasticsearch/log chown -R elasticsearch.elasticsearch /opt/elasticsearch/*
bash bin/elasticsearch
以上是关于Elasticsearch搜索功能的实现--搜索引擎为什么选ES的主要内容,如果未能解决你的问题,请参考以下文章