正则表达式c语言匹配汉字“银行”,怎么写啊???直接写“银行”匹配不出来,麻烦高手指点下,很急的
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式c语言匹配汉字“银行”,怎么写啊???直接写“银行”匹配不出来,麻烦高手指点下,很急的相关的知识,希望对你有一定的参考价值。
我是想把文件中的所有带 银行 字段的行写到另一个文件中,求解
[A-Za-z0-9\\u4E00-\\u9FA5]*银行[A-Za-z0-9\\u4E00-\\u9FA5]*
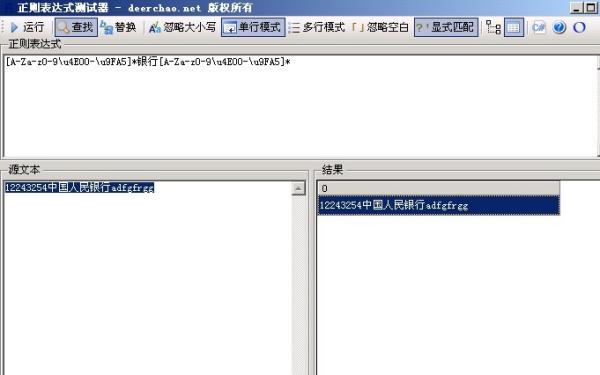
我知道这样匹配,直接写 银行 也行的,但是我这个程序是用c语言编写的,直接写 char* bank= “银行”,就什么都出不来了,需要怎么写呢??也就是说在
c中 银行 作为正则表达式怎么写?》》
char是单字节的
要用string
那用c语言的这个银行的正则表达式怎么写呢???
本回答被提问者采纳 参考技术B "银行”是字符串了,要用strcmp来匹配。追问我是说 用 正则表达式 怎么写匹配的模型。
追答这个还真没玩过。
http://see.xidian.edu.cn/cpp/html/1428.html
这个有说明和例子参考。希望能帮到你。
哦,谢谢,早就看了,真是没有办法了,哎,c的正则表达式中有匹配汉字的,但是具体匹配特定的汉字真没有找到相关的例子。弄了一下午了,数字和字母的能匹配出来,特定的汉字就不会写了,不过谢谢啊
PYDay9-正则表达式
1、什么是正则表达式?
正则表达式,又称规则表达式,是一门小型的语言,通常被用来检索、替换那些符合某个模式(规则)的文本。
2、匹配字符:
. 匹配除换行符以外的任意字符
\\w 匹配字母或数字或下划线或汉字
\\s 匹配任意的空白符
\\d 匹配数字
\\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
3、匹配次数:
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
4、常用方法
4.1 match
从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None


match(pattern, string, flags=0) # pattern: 正则模型 # string : 要匹配的字符串 # falgs : 匹配模式 X VERBOSE Ignore whitespace and comments for nicer looking RE\'s. I IGNORECASE Perform case-insensitive matching. M MULTILINE "^" matches the beginning of lines (after a newline) as well as the string. "$" matches the end of lines (before a newline) as well as the end of the string. S DOTALL "." matches any character at all, including the newline. A ASCII For string patterns, make \\w, \\W, \\b, \\B, \\d, \\D match the corresponding ASCII character categories (rather than the whole Unicode categories, which is the default). For bytes patterns, this flag is the only available behaviour and needn\'t be specified. L LOCALE Make \\w, \\W, \\b, \\B, dependent on the current locale. U UNICODE For compatibility only. Ignored for string patterns (it is the default), and forbidden for bytes patterns.
# 无分组 r = re.match("h\\w+", origin) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组结果 # 有分组 # 为何要有分组?提取匹配成功的指定内容(先匹配成功全部正则,再匹配成功的局部内容提取出来) r = re.match("h(\\w+).*(?P<name>\\d)$", origin) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组中所有执行了key的组 Demo
4.2 search
浏览整个字符串去匹配第一个,未匹配成功返回None
search(pattern, string, flags=0)
r = re.search("a\\w+", origin) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组结果 # 有分组 r = re.search("a(\\w+).*(?P<name>\\d)$", origin) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组中所有执行了key的组
4.3 findall
findall,获取非重复的匹配列表;如果有一个组则以列表形式返回,且每一个匹配均是字符串;如果模型中有多个组,则以列表形式返回,且每一个匹配均是元祖;空的匹配也会包含在结果中
findall(pattern, string, flags=0)
# 无分组 r = re.findall("a\\w+",origin) print(r) # 有分组 origin = "hello alex bcd abcd lge acd 19" r = re.findall("a((\\w*)c)(d)", origin) print(r)
4.4 sub
# sub,替换匹配成功的指定位置字符串
sub(pattern, repl, string, count=0, flags=0)
# pattern: 正则模型
# repl : 要替换的字符串或可执行对象
# string : 要匹配的字符串
# count : 指定匹配个数
# flags : 匹配模式
# 与分组无关 origin = "hello alex bcd alex lge alex acd 19" r = re.sub("a\\w+", "999", origin, 2) print(r)
4.5 split
split,根据正则匹配分割字符串
split(pattern, string, maxsplit=0, flags=0)
pattern: 正则模型
string : 要匹配的字符串
maxsplit:指定分割个数
flags : 匹配模式
origin = "hello alex bcd alex lge alex acd 19" r = re.split("alex", origin, 1) print(r) # 有分组 origin = "hello alex bcd alex lge alex acd 19" r1 = re.split("(alex)", origin, 1) print(r1) r2 = re.split("(al(ex))", origin, 1) print(r2)
4.6常用正则表达式
IP: ^(25[0-5]|2[0-4]\\d|[0-1]?\\d?\\d)(\\.(25[0-5]|2[0-4]\\d|[0-1]?\\d?\\d)){3}$ 手机号: ^1[3|4|5|8][0-9]\\d{8}$ 邮箱: [a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+
5、计算器实例代码:
#!/usr/bin/env python # -*- coding:utf-8 -*- import re origin = "11+22-(33/3)+4+(12+(66/3))" # print(eval(origin)) #使用eval 方法 def f1(*args): \'\'\' 计算()里面的内容 :param args: :return: \'\'\' return 1 while True: result = re.split("\\(([^()]+)\\)",origin,1) if len(result) == 3: before,content,after = result r = f1(content) new_str = before + str(r) + after origin = new_str print(origin) else: final = f1(origin) print(final) break
以上是关于正则表达式c语言匹配汉字“银行”,怎么写啊???直接写“银行”匹配不出来,麻烦高手指点下,很急的的主要内容,如果未能解决你的问题,请参考以下文章