Week8-python(线程进程协程)
Posted cirr-zhou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Week8-python(线程进程协程)相关的知识,希望对你有一定的参考价值。
week8
1 paramiko模块
paramiko是一个用于做远程控制的模块,使用该模块可以对远程服务器进行命令或文件操作,值得一说的是,fabric和ansible内部的远程管理就是使用的paramiko来现实。
1.Paramiko SSH连接远程主机(1)使用用户名密码连接远程主机(2)使用key连接远程主机2.Paramiko SFTP传送文件1.1 SSHClient:用于连接远程服务器并执行基本命令
1.1.1 基于用户名和密码连接
import paramiko # 创建SSH对象 ssh = paramiko.SSHClient() # 允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 连接服务器 ssh.connect(hostname=‘120.92.84.249‘, port=22, username=‘root‘, password=‘xxx‘) # 执行命令 stdin, stdout, stderr = ssh.exec_command(‘df‘) # 获取命令结果 result = stdout.read() print(result.decode(‘utf-8‘)) # 关闭连接 ssh.close()
1.1.2 基于公钥连接
定义:RSA--非对称秘钥验证 、公钥 public key---->私钥 private key
客户端文件名:id_rsa
服务端必须有文件名:authorized_keys(在用ssh-keygen时,必须制作一个authorized_keys,可以用ssh-copy-id来制作)
import paramiko private_key = paramiko.RSAKey.from_private_key_file(‘/tmp/id_rsa‘) # 创建SSH对象 ssh = paramiko.SSHClient() # 允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 连接服务器 ssh.connect(hostname=‘120.92.84.249‘, port=22, username=‘root‘, pkey=private_key) # 执行命令 stdin, stdout, stderr = ssh.exec_command(‘df‘) # 获取命令结果 result = stdout.read() print(result.decode(‘utf-8‘)) # 关闭连接 ssh.close()
1.2 SFTPClient:用于连接远程服务器并执行上传下载
1.2.1 基于用户名密码上传下载
mport paramiko transport = paramiko.Transport((‘120.92.84.249‘,22)) transport.connect(username=‘root‘,password=‘xxx‘) sftp = paramiko.SFTPClient.from_transport(transport) # 将location.py 上传至服务器 /tmp/test.py sftp.put(‘/tmp/id_rsa‘, ‘/etc/test.rsa‘) # 将remove_path 下载到本地 local_path sftp.get(‘remove_path‘, ‘local_path‘) transport.close()
1.2.1 基于公钥密钥上传下载
import paramiko private_key = paramiko.RSAKey.from_private_key_file(‘/tmp/id_rsa‘) transport = paramiko.Transport((‘120.92.84.249‘, 22)) transport.connect(username=‘root‘, pkey=private_key ) sftp = paramiko.SFTPClient.from_transport(transport) # 将location.py 上传至服务器 /tmp/test.py sftp.put(‘/tmp/id_rsa‘, ‘/tmp/a.txt‘) # 将remove_path 下载到本地 local_path sftp.get(‘remove_path‘, ‘local_path‘) transport.close()
概念
进程与线程
进程就是一个程序在一个数据集上的一次动态执行过程。进程一般由程序、数据集、进程控制块三部分组成,是最小的资源管理单元。
线程的出现是为了降低上下文切换的消耗,提高系统的并发性,线程也叫轻量级进程,也是程序执行过程中的最小单元。
进程和线程的关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)CPU分给线程,即真正在CPU上运行的是线程。
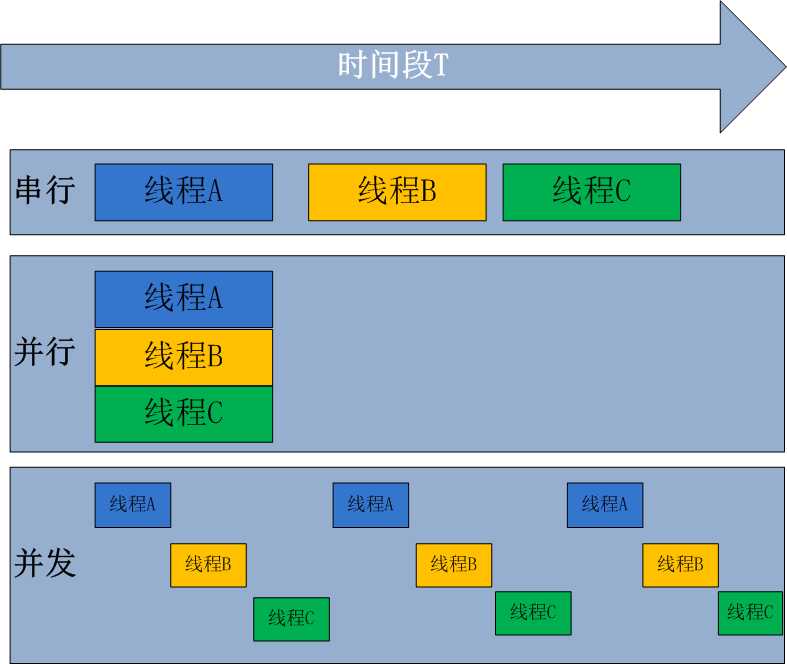
并行与并发
切换:切换的操作者是操作系统
进程/线程切换的原则:
1、时间片
2、遇到IO操作切换
3、优先级切换
并行处理(Parallel Processing)
是计算机系统中能同时执行两个或更多个处理的一种计算方法。并行处理可同时工作于同一程序的不同方面。并行处理的主要目的是节省大型和复杂问题的解决时间。
并发处理(concurrency Processing):
指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机(CPU)上运行,但任一个时刻点上只有一个程序在处理机(CPU)上运行
并发的关键是你有处理多个任务的能力,不一定要同时。并行的关键是你有同时处理多个任务的能力。所以说,并行是并发的子集。
同步与异步
在计算机领域,同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去;
异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率。
举个例子,打电话时就是同步通信,发短息时就是异步通信。
2 线程
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
eg.开启一个字处理软件进程,该进程肯定需要办不止一件事情,比如监听键盘输入,处理文字,定时自动将文字保存到硬盘,这三个任务操作的都是同一块数据,因而不能用多进程,只能在一个进程里并发地开启三个线程。
2.1 直接调用
import threading import time def Sayhi(name): #定义每个线程要运行的函数 print(‘what is your name:%s‘%name) time.sleep(3) if __name__ == ‘__main__‘: t1=threading.Thread(target=Sayhi,args=(‘zhouxy‘,)) #生成一个线程实例 t2=threading.Thread(target=Sayhi,args=(‘xyzhou‘,)) t1.start()#启动 t2.start() print(t1.getName()) #获取线程名 print(t2.getName())
2.2 继承式调用
from threading import Thread import time class Sayhi(Thread): def __init__(self,name): super().__init__() #threading.Thread.__init__(self) self.name = name def run(self): #定义每个线程要运行的函数 print(‘what is your name:%s‘%self.name) time.sleep(3) if __name__ ==‘__main__‘: for i in range (2): t = Sayhi(‘t%s‘%i) t.start()
2.3 一个进程下多个线程和一个进程下多个字进程的区别
在主进程下开启线程:先执行子线程后执行主进程
在主进程下开启子进程:先执行主进程后执行子进程
from threading import Thread from multiprocessing import Process import os def work(): print(‘hello‘) if __name__ == ‘__main__‘: #在主进程下开启线程 t=Thread(target=work) t.start() print(‘主线程/主进程‘) ‘‘‘ 打印结果: hello 主线程/主进程 ‘‘‘ #在主进程下开启子进程 t=Process(target=work) t.start() print(‘主线程/主进程‘) ‘‘‘ 打印结果: 主线程/主进程 hello ‘‘‘
from threading import Thread from multiprocessing import Process import os def work(): print(‘hello‘,os.getpid()) if __name__ == ‘__main__‘: #part1:在主进程下开启多个线程,每个线程都跟主进程的pid一样 t1=Thread(target=work) t2=Thread(target=work) t1.start() t2.start() print(‘主线程/主进程pid‘,os.getpid()) #part2:开多个进程,每个进程都有不同的pid p1=Process(target=work) p2=Process(target=work) p1.start() p2.start() print(‘主线程/主进程pid‘,os.getpid())
from threading import Thread from multiprocessing import Process import os def work(): global n n=0 if __name__ == ‘__main__‘: # n=100 # p=Process(target=work) # p.start() # p.join() # print(‘主‘,n) #毫无疑问子进程p已经将自己的全局的n改成了0,但改的仅仅是它自己的,查看父进程的n仍然为100 n=1 t=Thread(target=work) t.start() t.join() print(‘主‘,n) #查看结果为0,因为同一进程内的线程之间共享进程内的数据
2.4 线程相关方法
Thread实例对象的方法 # isAlive(): 返回线程是否活动的。 # getName(): 返回线程名。 # setName(): 设置线程名。 threading模块提供的一些方法: # threading.currentThread(): 返回当前的线程变量。 # threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 # threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
2.4 守护线程
1.对主进程来说,运行完毕指的是主进程代码运行完毕
(主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束)
2.对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕。
(主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。)
‘‘‘
将线程声明为守护线程,必须在start() 方法调用之前设置,如果不设置为守护线程程序会被无限挂起。 当我们在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程 就分兵两路,分别运行,那么当主线程完成
想退出时,会检验子线程是否完成。如果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是只要主线程
完成了,不管子线程是否完成,都要和主线程一起退出,这时就可以 用setDaemon方法啦‘‘‘
from threading import Thread import time def sayhi(name): time.sleep(2) print(‘%s say hello‘ %name) if __name__ == ‘__main__‘: t=Thread(target=sayhi,args=(‘zhouxy‘,)) t.setDaemon(True) #必须在t.start()之前设置 t.start() print(‘主线程‘) print(t.is_alive()) ‘‘‘ 主线程 True ‘‘‘
2.5 GIL(Global Interpreter Lock)
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock
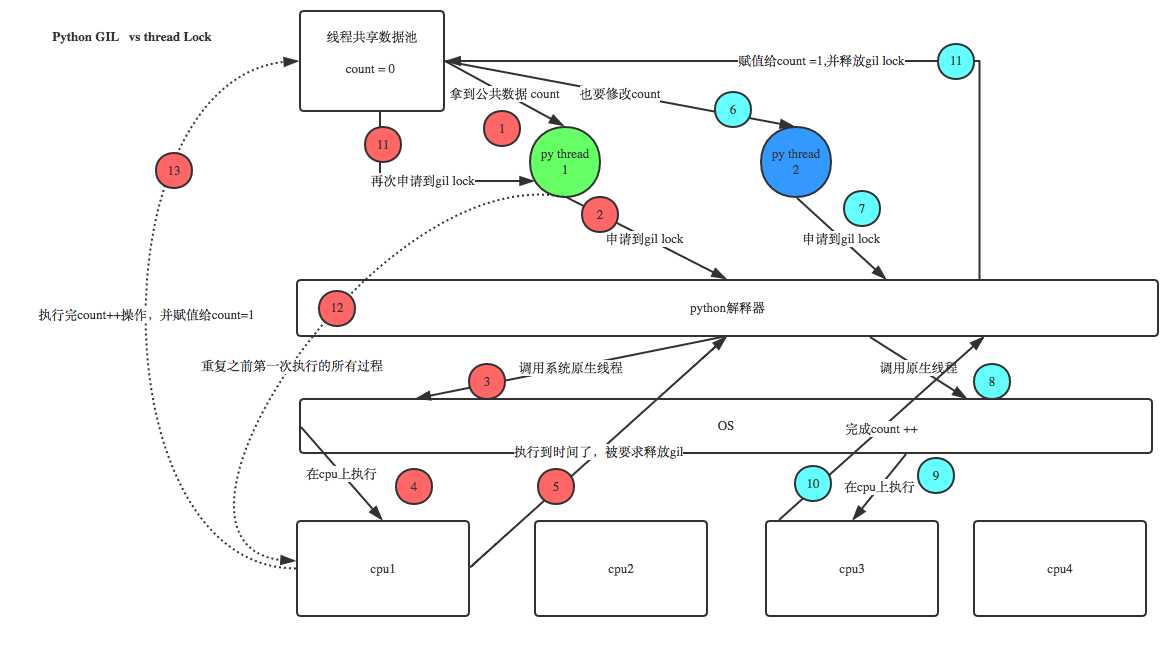
线程抢的是GIL锁,GIL锁相当于执行权限,拿到执行权限后才能拿到互斥锁Lock,其他线程也可以抢到GIL,但如果发现Lock仍然没有被释放则阻塞,即便是拿到执行权限GIL也要立刻交出来
t1.start() t1.join #在子线程完成运行之前,这个子线程的父线程将一直被阻塞 t2.start() t2.join() #这是串行执行,为何还要加Lock呢,需知join是等待t1所有的代码执行完,相当于锁住了t1的所有代码,而Lock只是锁住一部分操作共享数据的代码。
from threading import Thread import os,time def work(): global n temp=n time.sleep(0.1) n=temp-1 if __name__ == ‘__main__‘: n=100 l=[] #存线程实例 for i in range(100): p=Thread(target=work) l.append(p) #为了不组赛后面线程的启动,不在这里join,先放到一个列表里 p.start() for p in l: #循环线程实例列表,等待所有线程执行完毕 p.join() print(n) #结果可能为99
from threading import Thread,Lock import os,time def work(): global n lock.acquire() temp=n time.sleep(0.1) n=temp-1 lock.release() if __name__ == ‘__main__‘: lock=Lock() n=100 l=[] for i in range(100): p=Thread(target=work) l.append(p) p.start() for p in l: p.join() print(n) #结果肯定为0,由原来的并发执行变成串行,牺牲了执行效率保证了数据安全
重点:
#1.100个线程去抢GIL锁,即抢执行权限 #2. 肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire() #3. 极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL #4.直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程
#不加锁:并发执行,速度快,数据不安全 from threading import current_thread,Thread,Lock import os,time def task(): global n print(‘%s is running‘ %current_thread().getName()) temp=n time.sleep(0.5) n=temp-1 if __name__ == ‘__main__‘: n=100 lock=Lock() threads=[] start_time=time.time() for i in range(100): t=Thread(target=task) threads.append(t) t.start() for t in threads: t.join() stop_time=time.time() print(‘主:%s n:%s‘ %(stop_time-start_time,n)) ‘‘‘ Thread-1 is running Thread-2 is running ...... Thread-100 is running 主:0.5216062068939209 n:99 ‘‘‘ #不加锁:未加锁部分并发执行,加锁部分串行执行,速度慢,数据安全 from threading import current_thread,Thread,Lock import os,time def task(): #未加锁的代码并发运行 time.sleep(3) print(‘%s start to run‘ %current_thread().getName()) global n #加锁的代码串行运行 lock.acquire() temp=n time.sleep(0.5) n=temp-1 lock.release() if __name__ == ‘__main__‘: n=100 lock=Lock() threads=[] start_time=time.time() for i in range(100): t=Thread(target=task) threads.append(t) t.start() for t in threads: t.join() stop_time=time.time() print(‘主:%s n:%s‘ %(stop_time-start_time,n)) ‘‘‘ Thread-1 is running Thread-2 is running ...... Thread-100 is running 主:53.294203758239746 n:0 ‘‘‘ #有的同学可能有疑问:既然加锁会让运行变成串行,那么我在start之后立即使用join,就不用加锁了啊,也是串行的效果啊 #没错:在start之后立刻使用jion,肯定会将100个任务的执行变成串行,毫无疑问,最终n的结果也肯定是0,是安全的,但问题是 #start后立即join:任务内的所有代码都是串行执行的,而加锁,只是加锁的部分即修改共享数据的部分是串行的 #单从保证数据安全方面,二者都可以实现,但很明显是加锁的效率更高. from threading import current_thread,Thread,Lock import os,time def task(): time.sleep(3) print(‘%s start to run‘ %current_thread().getName()) global n temp=n time.sleep(0.5) n=temp-1 if __name__ == ‘__main__‘: n=100 lock=Lock() start_time=time.time() for i in range(100): t=Thread(target=task) t.start() t.join() stop_time=time.time() print(‘主:%s n:%s‘ %(stop_time-start_time,n)) ‘‘‘ Thread-1 start to run Thread-2 start to run ...... Thread-100 start to run 主:350.6937336921692 n:0 #耗时是多么的恐怖 ‘‘‘
2.6 递归锁(Rlock)
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁。就是在一个大锁中还要再包含子锁。
在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
import threading, time def run1(): print("grab the first part data") lock.acquire() global num num += 1 lock.release() return num def run2(): print("grab the second part data") lock.acquire() global num2 num2 += 1 lock.release() return num2 def run3(): lock.acquire() res = run1() print(‘--------between run1 and run2-----‘) res2 = run2() lock.release() print(res, res2) if __name__ == ‘__main__‘: num, num2 = 0, 0 lock = threading.RLock() for i in range(10): t = threading.Thread(target=run3) t.start() while threading.active_count() != 1: print(threading.active_count()) else: print(‘----all threads done---‘) print(num, num2)
#结论:现在的计算机基本上都是多核,python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。 IO相当于原材料,cpu相当于工人
每个cpu一旦遇到I/O阻塞,仍然需要等待,所以多核对I/O操作没什么用处
2.7 信号量(Semaphore)
互斥锁同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据。
Semaphore管理一个内置的计数器,每当调用acquire()时内置计数器-1;调用release() 时内置计数器+1;计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
import threading,time def run(n): semaphore.acquire() time.sleep(1) print("run the thread: %s\\n" %n) semaphore.release() if __name__ == ‘__main__‘: num= 0 semaphore = threading.BoundedSemaphore(5) #最多允许5个线程同时运行 for i in range(20): t = threading.Thread(target=run,args=(i,)) t.start() while threading.active_count() != 1: pass #print threading.active_count() else: print(‘----all threads done---‘) print(num)
2.8 事件(Event)
在初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象,而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行。
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
import threading,time def Light(): # if not event.isSet(): #如果没有设置标志 # event.set() #设置标志,绿灯状态 # count = 0 event.set() count = 0 while True: if count < 5: print(‘\\033[42;1m 绿灯行 \\033[0m‘) time.sleep(0.1) elif count < 8: print(‘\\033[43;1m 黄灯等 \\033[0m‘) time.sleep(0.1) elif count < 15: event.clear() #清空标志 print(‘\\033[41;1m 红灯停 \\033[0m‘) time.sleep(0.1) else: count=0 event.set() #再次设置标志 count +=1 def Car(n): while True: time.sleep(0.5) if event.isSet(): print(‘第%s俩车通过‘%n) else: print(‘有%s俩车等待绿灯‘%n) if __name__ == ‘__main__‘: event = threading.Event() light= threading.Thread(target=Light) light.start() for i in range(50): c = threading.Thread(target=Car,args=(i,)) c.start()
2.9 队列(queue)
2.9.1 class queue.Queue(maxsize=0) #先入先出
import queue q=queue.Queue(maxsize=2) q.put(1) q.put(2) q.put(block=False) #q.put(timeout=1) print(q.get()) print(q.get()) print(q.get(block=False)) # print(q.get(timeout=1))
import queue q=queue.Queue(maxsize=2) q.put(‘first‘) q.put(‘second‘) print(q.get()) q.put(‘third‘) print(q.qsize()) print(q.get()) print(q.get()) print(q.qsize()) ‘‘‘ first 2 second third 0 ‘‘‘
2.9.2 class queue.LifoQueue(maxsize=0) #last in fisrt out 后进先出
import queue q=queue.LifoQueue() q.put(‘first‘) q.put(‘second‘) q.put(‘third‘) print(q.get()) print(q.get()) print(q.get()) ‘‘‘ 结果(后进先出): third second first ‘‘‘
2.9.3 class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
import queue q=queue.PriorityQueue() #put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高 q.put((20,‘a‘)) q.put((10,‘b‘)) q.put((30,‘c‘)) print(q.get()) print(q.get()) print(q.get()) ‘‘‘ 结果(数字越小优先级越高,优先级高的优先出队): (10, ‘b‘) (20, ‘a‘) (30, ‘c‘) ‘‘‘
生产者消费者模型
import threading,time import queue def Producer(name): count = 1 while True: q.put(count) print(‘%s生产了%s个包子‘%(name,count)) time.sleep(0.2) def Customer(name): while True: if q.qsize()>0: print(‘%s吃了%s个包子‘%(name,q.get())) time.sleep(1) else: print(‘%s等待包子出笼‘%name) time.sleep(0.1) q = queue.Queue(maxsize=10) t1 = threading.Thread(target=Producer,args=(‘zhouxy‘,)) t2 = threading.Thread(target=Customer,args=‘甲‘,) t3 = threading.Thread(target=Customer,args=‘乙‘,) t1.start() t2.start() t3.start()
3 进程
程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。
3.1 进程的并发
进程并发的实现在于,硬件中断一个正在运行的进程,把此时进程运行的所有状态保存下来,为此,操作系统维护一张表格,即进程表(process table),每个进程占用一个进程表项(这些表项也称为进程控制块)。

3.2 多进程multiprocessing
from multiprocessing import Process import time def f(name): time.sleep(2) print(‘hello‘, name) if __name__ == ‘__main__‘: p = Process(target=f, args=(‘bob‘,)) p.start() p.join()
每个进程都存在父进程。
from multiprocessing import Process import os def info(title): print(title) print(‘module name:‘, __name__) print(‘parent process:‘, os.getppid()) #父进程id print(‘process id:‘, os.getpid()) #自己进程id print("\\n\\n") def f(name): info(‘\\033[31;1mfunction f\\033[0m‘) print(‘hello‘, name) if __name__ == ‘__main__‘: info(‘\\033[32;1mmain process line\\033[0m‘) p = Process(target=f, args=(‘bob‘,)) p.start() p.join()
3.4 进程间通信
3.4.1 Queues
from multiprocessing import Process, Queue def f(q): q.put([42, None, ‘hello‘]) if __name__ == ‘__main__‘: q = Queue() p = Process(target=f, args=(q,)) p.start() print(q.get()) # prints "[42, None, ‘hello‘]" p.join()
3.4.2 Pipes(管道)
from multiprocessing import Process, Pipe def f(conn): conn.send([42, None, ‘hello‘]) conn.close() if __name__ == ‘__main__‘: parent_conn, child_conn = Pipe() p = Process(target=f, args=(child_conn,)) p.start() print(parent_conn.recv()) # prints "[42, None, ‘hello‘]" p.join()
3.4.3 Managers
进程间数据是独立的,可以借助于队列或管道实现通信,二者都是基于消息传递的。 虽然进程间数据独立,但可以通过Manager实现数据共享,事实上Manager的功能远不止于此。
from multiprocessing import Process, Manager import os def f(d, l): d[1] = ‘1‘ d[‘2‘] = 2 d[0.25] = None l.append(os.getpid()) print(l) if __name__ == ‘__main__‘: with Manager() as manager: d = manager.dict() #生成一个字典,可在多个进程间共享和传递 l = manager.list(range(5)) #生成一个列表,可在多个进程间共享和传递 p_list = [] for i in range(10): p = Process(target=f, args=(d, l)) p.start() p_list.append(p) for res in p_list: res.join() print(d) print(l) ‘‘‘ [0, 1, 2, 3, 4, 13220] [0, 1, 2, 3, 4, 13220, 9652] [0, 1, 2, 3, 4, 13220, 9652, 7400] [0, 1, 2, 3, 4, 13220, 9652, 7400, 14868] [0, 1, 2, 3, 4, 13220, 9652, 7400, 14868, 13348] [0, 1, 2, 3, 4, 13220, 9652, 7400, 14868, 13348, 2228] [0, 1, 2, 3, 4, 13220, 9652, 7400, 14868, 13348, 2228, 8312] [0, 1, 2, 3, 4, 13220, 9652, 7400, 14868, 13348, 2228, 8312, 15800] [0, 1, 2, 3, 4, 13220, 9652, 7400, 14868, 13348, 2228, 8312, 15800, 15868] [0, 1, 2, 3, 4, 13220, 9652, 7400, 14868, 13348, 2228, 8312, 15800, 15868, 18592] {1: ‘1‘, ‘2‘: 2, 0.25: None} [0, 1, 2, 3, 4, 13220, 9652, 7400, 14868, 13348, 2228, 8312, 15800, 15868, 18592] ‘‘‘
3.4.5 进程同步锁
3.4.5.1 多个进程共享同一打印终端
#并发运行,效率高,但竞争同一打印终端,带来了打印错乱 from multiprocessing import Process import os,time def work(): print(‘%s is running‘ %os.getpid()) time.sleep(2) print(‘%s is done‘ %os.getpid()) if __name__ == ‘__main__‘: for i in range(3): p=Process(target=work) p.start()
#由并发变成了串行,牺牲了运行效率,但避免了竞争 from multiprocessing import Process,Lock import os,time def work(lock): lock.acquire() print(‘%s is running‘ %os.getpid()) time.sleep(2) print(‘%s is done‘ %os.getpid()) lock.release() if __name__ == ‘__main__‘: lock=Lock() for i in range(3): p=Process(target=work,args=(lock,)) p.start()
3.4.5.2 多个进程共享同一文件
from multiprocessing import Process,Lock import time,json,random def search(): dic=json.load(open(‘db.txt‘)) print(‘\\033[43m剩余票数%s\\033[0m‘ %dic[‘count‘]) def get(): dic=json.load(open(‘db.txt‘)) time.sleep(0.1) #模拟读数据的网络延迟 if dic[‘count‘] >0: dic[‘count‘]-=1 time.sleep(0.2) #模拟写数据的网络延迟 json.dump(dic,open(‘db.txt‘,‘w‘)) print(‘\\033[43m购票成功\\033[0m‘) def task(lock): search() lock.acquire() get() lock.release() if __name__ == ‘__main__‘: lock=Lock() for i in range(100): #模拟并发100个客户端抢票 p=Process(target=task,args=(lock,)) p.start()
3.4.6 进程持(Pool)
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中有两个方法:
- apply
- apply_async
from multiprocessing import Pool import os,time def work(n): print(‘%s run‘ %os.getpid()) time.sleep(1) return n**2 def Bar(arg): print(‘all done‘,arg) if __name__ == ‘__main__‘: p=Pool(3) #进程池中从无到有创建三个进程,以后一直是这三个进程在执行任务 res_l=[] # 同步调用,直到本次任务执行完毕拿到res,等待任务work执行的过程中可能有阻塞也可能没有阻塞,但不管该任务是否存在阻塞,同步调用都会在原地等着,
只是等的过程中若是任务发生了阻塞就会被夺走cpu的执行权限 for i in range(10): # res=p.apply(work,args=(i,)) # res_l.append(res) # print(res_l) # 异步apply_async用法:如果使用异步提交的任务,主进程需要使用jion,等待进程池内任务都处理完,然后可以用get收集结果,否则,主进程结束,进程池可能还没来得及执行,
也就跟着一起结束了 res = p.apply_async(work, args=(i,),callback=Bar) # callback 回调函数 res_l.append(res) p.close() #关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成 p.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束 for res in res_l: print(res.get()) #使用get来获取apply_aync的结果,如果是apply,则没有get方法,因为apply是同步执行,立刻获取结果,也根本无需get
回调函数:
进程池中任何一个任务一旦处理完了,就立即告知主进程:我好了,你可以处理我的结果了。主进程则调用一个函数去处理该结果,该函数即回调函数。
我们可以把耗时间(阻塞)的任务放到进程池中,然后指定回调函数(主进程负责执行),这样主进程在执行回调函数时就省去了I/O的过程,直接拿到的是任务的结果。
4 协程
线程和进程的操作是由程序触发系统接口,最后的执行者是系统;协程的操作则是程序员。
协程存在的意义:对于多线程应用,CPU通过切片的方式来切换线程间的执行,线程切换时需要耗时(保存状态,下次继续)。协程,则只使用一个线程,在一个线程中规定某个代码块执行顺序。协程是一种用户态的轻量级线程。
协程的适用场景:当程序中存在大量不需要CPU的操作时(IO),适用于协程。
优点:
#1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级 #2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点:
#1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程 #2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
4.1 greenlet
协程的特点:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
import time import queue def consumer(name): print("--->starting eating baozi...") while True: new_baozi = yield print("[%s] is eating baozi %s" % (name,new_baozi)) #time.sleep(1) def producer(): r = con.__next__() r = con2.__next__() n = 0 while n < 5: n +=1 con.send(n) con2.send(n) print("\\033[32;1m[producer]\\033[0m is making baozi %s" %n ) if __name__ == ‘__main__‘: con = consumer("c1") con2 = consumer("c2") p = producer()
from greenlet import greenlet def test1(): print(12) gr2.switch() print(34) gr2.switch() def test2(): print(56) gr1.switch() print(78) gr1 = greenlet(test1) gr2 = greenlet(test2) gr1.switch() #可以使在任意函数之间随意切换,而不需把这个函数先声明为generator
4.2 gevent
g1=gevent.spawn(func,1,,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的 g2=gevent.spawn(func2) g1.join() #等待g1结束 g2.join() #等待g2结束 #或者上述两步合作一步:gevent.joinall([g1,g2]) g1.value#拿到func1的返回值
import gevent def eat(name): print(‘%s eat 1‘ %name) gevent.sleep(2) print(‘%s eat 2‘ %name) def play(name): print(‘%s play 1‘ %name) gevent.sleep(1) print(‘%s play 2‘ %name) g1=gevent.spawn(eat,‘egon‘) g2=gevent.spawn(play,name=‘egon‘) g1.join() g2.join() #或者gevent.joinall([g1,g2]) print(‘主‘)
time.sleep(2)或其他的阻塞。gevent是不能直接识别的需要用下面一行代码,打补丁。
from gevent import monkey;monkey.patch_all()必须放到被打补丁者的前面,如time,socket模块之前。
gevent网页爬虫:
from gevent import monkey;monkey.patch_all() import gevent import requests import time def get_page(url): print(‘GET: %s‘ %url) response=requests.get(url) if response.status_code == 200: print(‘%d bytes received from %s‘ %(len(response.text),url)) start_time=time.time() gevent.joinall([ gevent.spawn(get_page,‘https://www.python.org/‘), gevent.spawn(get_page,‘https://www.yahoo.com/‘), gevent.spawn(get_page,‘https://github.com/‘), ]) stop_time=time.time() print(‘run time is %s‘ %(stop_time-start_time))
gevent多并发socket:
from gevent import monkey;monkey.patch_all() from socket import * import gevent #如果不想用money.patch_all()打补丁,可以用gevent自带的socket # from gevent import socket # s=socket.socket() def server(server_ip,port): s=socket(AF_INET,SOCK_STREAM) s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind((server_ip,port)) s.listen(5) while True: conn,addr=s.accept() gevent.spawn(talk,conn,addr) def talk(conn,addr): try: while True: res=conn.recv(1024) print(‘client %s:%s msg: %s‘ %(addr[0],addr[1],res)) conn.send(res.upper()) except Exception as e: print(e) finally: conn.close() if __name__ == ‘__main__‘: server(‘127.0.0.1‘,8080) 服务端
from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect((‘127.0.0.1‘,8080)) while True: msg=input(‘>>: ‘).strip() if not msg:continue client.send(msg.encode(‘utf-8‘)) msg=client.recv(1024) print(msg.decode(‘utf-8‘))
多并发客户端:
from threading import Thread from socket import * import threading def client(server_ip,port): c=socket(AF_INET,SOCK_STREAM) #套接字对象一定要加到函数内,即局部名称空间内,放在函数外则被所有线程共享,则大家公用一个套接字对象,那么客户端端口永远一样了 c.connect((server_ip,port)) count=0 while True: c.send((‘%s say hello %s‘ %(threading.current_thread().getName(),count)).encode(‘utf-8‘)) msg=c.recv(1024) print(msg.decode(‘utf-8‘)) count+=1 if __name__ == ‘__main__‘: for i in range(500): t=Thread(target=client,args=(‘127.0.0.1‘,8080)) t.start()
5 事件驱动
目前大部分的UI编程都是事件驱动模型,如很多UI平台都会提供onClick()事件,这个事件就代表鼠标按下事件。事件驱动模型大体思路如下:
1. 有一个事件(消息)队列;
2. 鼠标按下时,往这个队列中增加一个点击事件(消息);
3. 有个循环,不断从队列取出事件,根据不同的事件,调用不同的函数,如onClick()、onKeyDown()等;
4. 事件(消息)一般都各自保存各自的处理函数指针,这样每个消息都有独立的处理函数。
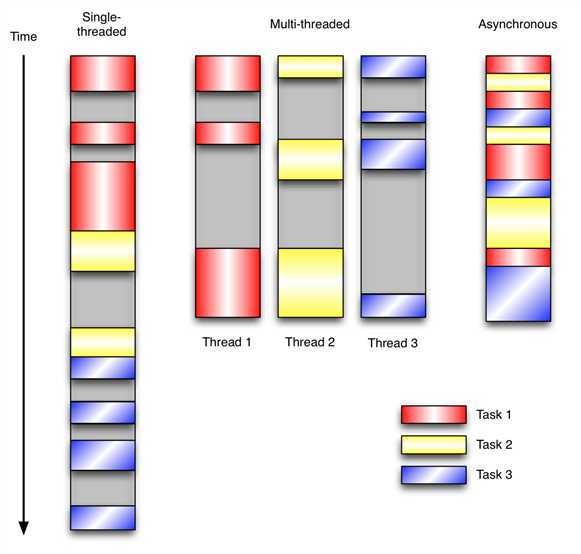
在单线程同步模型中,任务按照顺序执行。如果某个任务因为I/O而阻塞,其他所有的任务都必须等待,直到它完成之后它们才能依次执行。这种明确的执行顺序和串行化处理的行为是很容易推断得出的。如果任务之间并没有互相依赖的关系,但仍然需要互相等待的话这就使得程序不必要的降低了运行速度。
在多线程版本中,这3个任务分别在独立的线程中执行。这些线程由操作系统来管理,在多处理器系统上可以并行处理,或者在单处理器系统上交错执行。这使得当某个线程阻塞在某个资源的同时其他线程得以继续执行。与完成类似功能的同步程序相比,这种方式更有效率,但程序员必须写代码来保护共享资源,防止其被多个线程同时访问。多线程程序更加难以推断,因为这类程序不得不通过线程同步机制如锁、可重入函数、线程局部存储或者其他机制来处理线程安全问题,如果实现不当就会导致出现微妙且令人痛不欲生的bug。
在事件驱动版本的程序中,3个任务交错执行,但仍然在一个单独的线程控制中。当处理I/O或者其他昂贵的操作时,注册一个回调到事件循环中,然后当I/O操作完成时继续执行。回调描述了该如何处理某个事件。事件循环轮询所有的事件,当事件到来时将它们分配给等待处理事件的回调函数。这种方式让程序尽可能的得以执行而不需要用到额外的线程。事件驱动型程序比多线程程序更容易推断出行为,因为程序员不需要关心线程安全问题。
6 IO模型
对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
- 等待数据准备 (Waiting for the data to be ready)
- 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
正式因为这两个阶段,linux系统产生了下面五种网络模式的方案:
- 阻塞 I/O(blocking IO)
- 非阻塞 I/O(nonblocking IO)
- I/O 多路复用( IO multiplexing)
- 信号驱动 I/O( signal driven IO)
- 异步 I/O(asynchronous IO)
注:由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
6.1 阻塞 I/O(blocking IO)
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
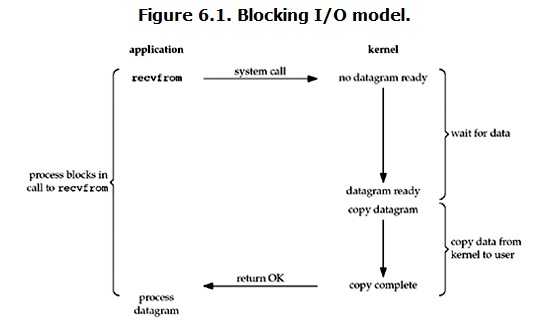
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
6.2 非阻塞 I/O(nonblocking IO)
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
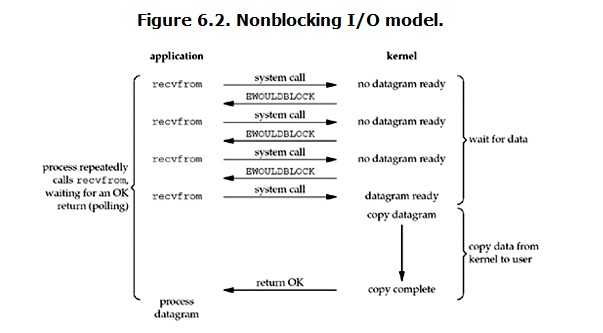
所以,nonblocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有。
6.3 I/O 多路复用( IO multiplexing)
IO multiplexing就是我们说的select/poll/epoll,有些地方也称这种IO方式为event driven IO。select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
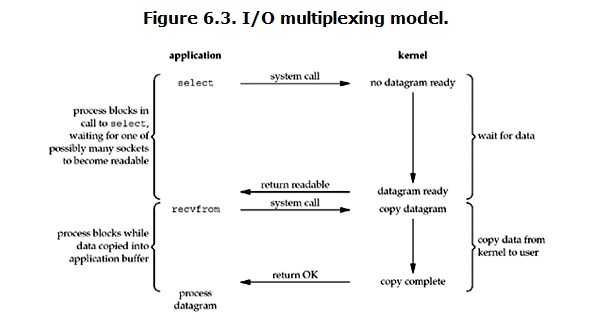
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
所以,I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
6.4 异步 I/O(asynchronous IO)
inux下的asynchronous IO其实用得很少。先看一下它的流程:
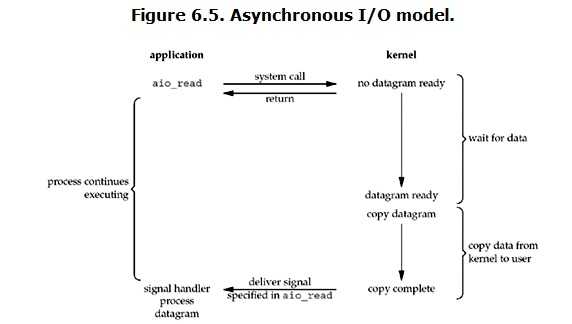
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
总结:
blocking和non-blocking的区别
调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。
synchronous IO和asynchronous IO的区别
两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。

通过上面的图片,可以发现non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
7 Select\\Poll\\Epoll异步IO
select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
7.1 select
select(rlist, wlist, xlist, timeout=None)
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述副就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以 通过遍历fdset,来找到就绪的描述符。
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。select的一 个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但是这样也会造成效率的降低。
import os import queue import select import socket server = socket.socket() server.bind((‘localhost‘,10000)) server.listen(100) msg_dict = {} server.setblocking(False) # 必须处于非阻塞的情况 inputs = [server] #inputs = [server,conn] outputs = [] #[r1],[r2] while True: readable,writeable,exceptional = select.select(inputs,outputs,inputs) # select监测链接 print(readable,writeable,exceptional) for r in readable: if r is server: #代表接入一个新链接 conn,addr = server.accept() # 没有新链接会报错 print(conn, addr) inputs.append(conn) # 因为新建立的链接还没发数据,并处于为阻塞的状态,现在接收数据则报错,需要让select监测conn msg_dict[conn] =queue.Queue() # 初始化一个队列,后面存要返回给这个客户端的数据 else: data = r.recv(1024) print(‘接收数据‘,data) msg_dict[r].put(data) #r.send(data) outputs.append(r) # 放入返回的链接队列里 for w in writeable: # 要返回给客户端的链接列表 data_to_client = msg_dict[w].get() w.send(data_to_client) #返回给客户端源数据 outputs.remove(w) #确保下次循环writeable,不返回已经处理完的链接 for e in exceptional: if e in outputs: outputs.remove(e) inputs.remove(e) del msg_dict[e]
7.2 selector模块
import selectors import socket sel = selectors.DefaultSelector() def accept(sock, mask): conn, addr = sock.accept() # Should be ready print(‘accepted‘, conn, ‘from‘, addr) conn.setblocking(False) #非阻塞 sel.register(conn, selectors.EVENT_READ, read) # 新建立的链接注册read回调函数 def read(conn, mask): data = conn.recv(1000) # Should be ready if data: print(‘echoing‘, repr(data), ‘to‘, conn) conn.send(data) # Hope it won‘t block else: print(‘closing‘, conn) sel.unregister(conn) conn.close() sock = socket.socket() sock.bind((‘localhost‘, 10000)) sock.listen(100) sock.setblocking(False) sel.register(sock, selectors.EVENT_READ, accept) while True: events = sel.select() # 默认是阻塞,有活动链接就返回活动的链接列表 for key, mask in events: callback = key.data # 相当于调accept callback(key.fileobj, mask) # key.fileobj= 文件句柄相当于还没建立链接的r
以上是关于Week8-python(线程进程协程)的主要内容,如果未能解决你的问题,请参考以下文章