Python基础知识 Python编码变量if和while语句
Posted zhangiwei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础知识 Python编码变量if和while语句相关的知识,希望对你有一定的参考价值。
Python入门知识
一、第一句Python代码
在Linux下/home/test目录下创建hello.py文件,内容如下:
[[email protected] ~]# mkdir /home/test [[email protected] ~]# cd /home/test [[email protected] test]# cat hello.py print("Hello World!")
执行hello.py文件,得到以下内容:
[[email protected] test]# python hello.py
Hello World!
将hello.py文件改为hello.text后执行:
[[email protected] test]# mv hello.py hello.text #<==Linux下改文件名可用mv命令 [[email protected] test]# ll 总用量 4 -rw-r--r-- 1 root root 22 4月 29 20:14 hello.text [[email protected] test]# python hello.text Hello World!
由此可见,文件后缀名对执行结果并无影响,但为了规范,也为了后期方便交接工作(如果你离职或者调离部门),强烈建议什么语言编写的开发脚本就用什么样的后缀名,如同shell脚本的.sh后缀名一样。
二、解释器
在上述的执行过程中,我们明确的指出hello.py文件由python解释器来执行的,如果想要类似于执行shell脚本一样执行python脚本,例如. /home/test/test.sh,那么就需要在hello.py文件的头部指定解释器,首先我们来看一下shell脚本的执行:
[[email protected] test]# ls -l test.sh -rwxr--r-- 1 root root 32 4月 30 19:16 test.sh #<==拥有可执行权限 [[email protected] test]# cat test.sh #!/bin/bash #<==指定解释器 echo "Hello World!" [[email protected] test]# ./test.sh Hello World!
接下来我们对比上述的操作执行hello.py文件
[[email protected] test]# cat hello.py #<==Linux下编辑文件可以用vi或vim命令 #!/usr/bin/env python #<==python解释器已经指定 print("Hello World!") [[email protected] test]# ./hello.py -bash: ./hello.py: 权限不够 #<==提示权限不够,因为没有给文件加相应的权限
给hello.py文件加上权限后即可执行:
[[email protected] test]# ls -l hello.py -rw-r--r-- 1 root root 44 4月 30 19:25 hello.py #<==未加权限时的权限位明细 [[email protected] test]# chmod u+x hello.py [[email protected] test]# ls -l hello.py -rwxr--r-- 1 root root 44 4月 30 19:25 hello.py #<==加上权限位后多了可执行权限x [[email protected] test]# ./hello.py Hello World!
三、字符编码
1、ASCII
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ASCII)。
ASCII(发音: /??ski/ ASS-kee,American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCOO则可以部分支持其他西欧语言,并等同于国际标准ISO/IEC 646。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),0 - 255被用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码。
ASCII最多只能用 8 位(二进制数)来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
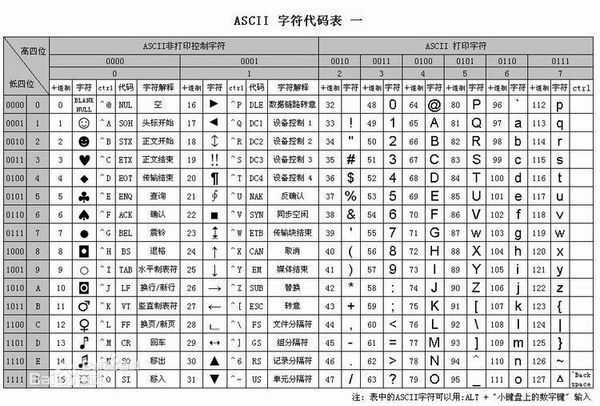
但我们发现ASCII码是没有中文编码的,显然在天朝是不够用的,于是GB2312诞生了。
2、GB2312
《信息交换用汉字编码字符集》是由中国国家标准总局1980年发布,1981年5月1日开始实施的一套国家标准,标准号是GB 2312-1980。
GB2312编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312。
GB 2312标准共收录7445个字符,包括6763个汉字和非汉字图形字符682个,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。
GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。但对于人名、古汉语等方面出现的罕用字和繁体字,GB 2312不能处理,因此后来GBK及GB 18030汉字字符集相继出现以解决这些问题。
3、GBK
GBK全称《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification) ,中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司、电子工业部科技与质量监督司1995年12月15日联合以技监标函1995 229号文件的形式,将它确定为技术规范指导性文件。这一版的GBK规范为1.0版。
GBK 共收入 21886 个汉字和图形符号,包括:
- GB 2312 中的全部汉字、非汉字符号;
- BIG5 中的全部汉字;
- 与 ISO 10646 相应的国家标准 GB 13000 中的其它 CJK 汉字,以上合计 20902 个汉字;
- 其它汉字、部首、符号,共计 984 个。
GBK 向下与 GB 2312 完全兼容,向上支持 ISO 10646 国际标准,在前者向后者过渡过程中起到的承上启下的作用。
4、GB18030
国家标准GB18030-2005《信息技术 中文编码字符集》是我国继GB2312-1980和GB13000.1-1993之后最重要的汉字编码标准,是我国计算机系统必须遵循的基础性标准之一。
GB18030有两个版本:GB18030-2000和GB18030-2005。GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字。GB18030-2005的主要特点是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字。
该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
5、Unicode
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
Unicode 是为了解决传统的字符编码方案的局限而产生的,通常用两个字节表示一个字符,这样理论上一共最多可以表示216(即65536)个字符。基本满足各种语言的使用。原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。
6、UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码Unicode字符。用在网页上可以统一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
如果UNICODE字符由2个字节表示,则编码成UTF-8很可能需要3个字节。而如果UNICODE字符由4个字节表示,则编码成UTF-8可能需要6个字节。用4个或6个字节去编码一个UNICODE字符可能太多了,但很少会遇到那样的UNICODE字符。
实际表示ASCII字符的Unicode字符,将会编码成1个字节,并且UTF-8表示与ASCII字符表示是一样的。
注:想更深入了解ASCII,GB2312,GBK,Unicode,UTF-8,大家可以参考这篇文章:https://blog.csdn.net/softwarenb/article/details/51994943
四、设定Python编码
因为Python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串‘ABC‘在Python内部都是ASCII编码的,因此,如果执行如下代码的话,会出现报错:
[[email protected] test]# ls -l hello.py -rwxr--r-- 1 root root 39 5月 1 01:50 hello.py [[email protected] test]# cat hello.py #!/usr/bin/env python print("你好!") [[email protected] test]# ./hello.py File "./hello.py", line 2 SyntaxError: Non-ASCII character ‘\\xe4‘ in file ./hello.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
改正:我们应该告诉python解释器,用什么编码来执行源代码,即:
[[email protected] test]# ls -l hello.py -rwxr--r-- 1 root root 61 5月 1 01:52 hello.py [[email protected] test]# cat hello.py #!/usr/bin/env python #-*- coding:utf-8 -*- print("你好!") [[email protected] test]# ./hello.py 你好!
提示:上述操作环境是在2.6版本的基础上进行的,如果在3.0版本以上呢?
[[email protected] test]# python -V #<==上述操作环境 Python 2.6.6
#!/usr/bin/env python print("你好!") /Library/Frameworks/Python.framework/Versions/3.6/bin/python3.6 /Users/xxxxxxx/PycharmProjects/all_study/day02/test.py 你好! #<==通过上述可见,Python3.0以上版本已经有好的支持中文了 Process finished with exit code 0
五、变量
变量来源于数学,是计算机语言中能储存计算结果或能表示值抽象概念。变量可以通过变量名访问。在指令式语言中,变量通常是可变的;但在纯函数式语言(如Haskell)中,变量可能是不可变(immutable)的。
变量存储在内存中的值。这就意味着在创建变量时会在内存中开辟一个空间。
基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中。
因此,变量可以指定不同的数据类型,这些变量可以存储整数,小数或字符。
1、声明变量
[[email protected] test]# cat hello.py #!/usr/bin/env python #-*- coding:utf-8 -*- name = ‘zhang‘ print(name)
在上述的代码中,我们声明了一个变量,变量名为name,变量name的值为zhang,"="表示赋值的意思。
提示:在Python代码中,“=”表示赋值,而“==”表示等于。
2、变量定义的规则
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名:
[‘and‘, ‘as‘, ‘assert‘, ‘break‘, ‘class‘, ‘continue‘, ‘def‘, ‘del‘, ‘elif‘, ‘else‘, ‘except‘, ‘exec‘, ‘finally‘, ‘for‘, ‘from‘, ‘global‘, ‘if‘, ‘import‘, ‘in‘, ‘is‘, ‘lambda‘, ‘not‘, ‘or‘, ‘pass‘, ‘print‘, ‘raise‘, ‘return‘, ‘try‘, ‘while‘, ‘with‘, ‘yield‘]
六、if条件语句
1、嵌套式
#!/usr/bin/env python # _*_ coding:utf8 _*_ # Date: 2018/5/1 testname = input("Please input your name:") if testname == ‘zhang‘: testage = input("Please input your age:") if testage == ‘22‘: print("Yes,you are right!") else: print("Sorry,you are wrong!") else: print("Try again!")
2、if..else型
#!/usr/bin/env python # _*_ coding:utf8 _*_ # Date: 2018/5/1 count = 5 if count == 1: pass elif count == 2: pass elif count == 3: pass elif count == 4: pass else: print("haha")
3、and..or型
#!/usr/bin/env python # _*_ coding:utf8 _*_ # Date: 2018/5/1 name=input("Please input your name:") age=input("Please input your age:") if name == "zhang" or age == "22": print("YES") else: print("----END----")
七、while型语句
#!/usr/bin/env python # _*_ coding:utf8 _*_ # Date: 2018/5/1 count = 1 while count < 10: print(count) count = count + 1
八、习题
1、使用while循环输出1、2、3、4、5、6、8、9


#!/usr/bin/env python # _*_ coding:utf8 _*_ # Date: 2018/4/28 count = 1 while count < 10: if count == 7: pass else: print(count) count = count + 1
2、求1-100的所有数的和
#!/usr/bin/env python # _*_ coding:utf8 _*_ # Date: 2018/4/28 SUM = 0 a = 1 while a < 101: SUM = SUM + a print(SUM) a = a + 1
3、输出1-100内的所有的奇数
#!/usr/bin/env python # _*_ coding:utf8 _*_ # Date: 2018/4/28 a = 1 while a < 101: s = a%2 if s == 1: print(a) else: pass a= a + 1
4、输出1-100内的所有偶数
#!/usr/bin/env python # _*_ coding:utf8 _*_ # Date: 2018/4/28 a = 1 while a < 101: s = a%2 if s == 0: print(a) else: pass a = a + 1
5、求1-2+3-4....99的所有数的和
#!/usr/bin/env python # _*_ coding:utf8 _*_ # Date: 2018/4/28 a = 1 SUM = 0 while a < 100: surplus = a % 2 if surplus == 0: SUM = SUM - a else: SUM = SUM + a a = a + 1 print(SUM)
6、用户登录(三次机会尝试)
#!/usr/bin/env python # _*_ coding:utf8 _*_ # Date: 2018/4/28 time = 1 while time < 4: name=input(">>>Please input your name:") passwd=input(">>>Please input your passwd:") if name == ‘zhang‘ and passwd == ‘12345‘: print("Yes,you are right!") break else: print(">>>Try again.") time = time + 1 continue
以上是关于Python基础知识 Python编码变量if和while语句的主要内容,如果未能解决你的问题,请参考以下文章