《python核心编程》——正则表达式学习笔记(课后练习)
Posted panpanblog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《python核心编程》——正则表达式学习笔记(课后练习)相关的知识,希望对你有一定的参考价值。
1. 识别后续的字符串:“bat”,“bit”,“but”,“hat”,“hit”或者“hut”。
[bh][aiu]t
2. 匹配由单个空格分割的任意单词对,也就是姓和名。
[A-Za-z]+\\s[A-Za-z]+
3. 匹配由单个逗号和单个空白符分隔的任何单词和单个字母,如姓氏的首字母
[A-Za-z]+,\\s[A-Za-z]
4. 匹配所有的有效的Python标识符集合
[A-Za-z_]\\w+ # 匹配任意以字母和下划线开头,标识符可以包括字母,下划线和数字。
5. 根据美国接到地址格式,匹配街道地址。美国街道地址使用如下格式:1180 Bordeaux Drive。使你的正则表达式足够灵活,以支持多单词的街道名称,如3120 De la Cruz Boulevard
\\d+[a-zA-Z\\s]+
6. 匹配以“www”起始且以“.com”结尾的简单Web域名:例如,www://www.yahoo.com。
^www[^\\s]+[com|edu|net]$
7. 匹配所有能够表示Python整数的字符串集
[-+]?\\d+ # 有正负符号或无
8. 匹配所有能够表示Python长整数的字符串集
[-+]?\\d+[lL] # 长整型,整数后面跟大写或小写的L
9. 匹配所有能够表示Python浮点数的字符串集
[-+]?\\d+\\.\\d*
10. 表示所有能够表示Python复数的字符集
-?\\d+\\+[\\+-]\\d+j
11. 匹配所有能够表示有效电子邮件的集合
[^\\s][email protected](\\w+\\.?)+
12. 匹配所有能够表示有效网址的集合(URL)
(http://([A-Za-z0-9\\-]+\\.?)+)
13. 创建一个能从字符串中提取实际类型名称的正则表达式。函数将对于<type ‘int‘>字符串返回int
<type\\s\\‘(\\w+)\\‘>
14. 处理日期,常见一个正则表达式来表示标准日历中剩余三个月的数字
1[012]
15. 处理信用卡号码
(\\d{4}-\\d{6}-\\d{5}|\\d{4}-\\d{4}-\\d{4}-\\d{4})
16. 为gendata.py更新代码,是数据直接输出到redata.txt而不是屏幕
# !/usr/bin/env python # gendata.py from random import randrange, choice from string import ascii_lowercase as lc # from sys import int from time import ctime tlds = (‘com‘, ‘edu‘, ‘net‘, ‘org‘, ‘gov‘) with open(‘path\\redata.txt‘, ‘w‘) as fp: for i in range(randrange(5,11)): dtint = randrange(2**32) # pick date dtstr = ctime(dtint) # date string llen = randrange(4, 8) # login is shorter login = ‘‘.join(choice(lc) for j in range(llen)) dlen = randrange(llen, 13) # domain is longer dom = ‘‘.join(choice(lc) for j in range(dlen)) print(‘%s::%[email protected]%s.%s::%d-%d-%d‘ % (dtstr, login, dom, choice(tlds), dtint, llen, dlen)) str = ‘%s::%[email protected]%s.%s::%d-%d-%d‘ % (dtstr, login, dom, choice(tlds), dtint, llen, dlen) fp.write(str+‘\\n‘)
17. 判断redata.txt中一周的每一天出现的次数
import re week = {"Mon": 0, "Tue": 0, "Wed": 0, "Thu": 0, "Fri": 0, "Sat": 0, "Sun": 0} with open(‘path\\redata.txt‘, ‘r‘) as fp: data = fp.readlines() for line in data: day = re.match(‘^\\w{3}‘, line) key = day.group() week[key] = week[key] + 1 print(week)
18. 提取
# 判断数据是否损坏Sat Jun 22 09:14:03 1985:: import re with open(‘path\\redata.txt‘, ‘r‘) as fp: data = fp.readlines() for line in data: time = re.match(‘^\\w{3}\\s\\w{3}\\s{1,2}\\d{1,2}\\s\\d{2}:\\d{2}:\\d{2}\\s\\d{4}‘, line) if time is not None: print(‘未损毁‘) else: print(‘存在数据损毁‘)
19-25. 创建正则表达式
# 19-27练习 import re times = [] emails = [] months = [] years = [] clocks = [] lnames = [] dnames = [] with open(‘path\\redata.txt‘, ‘r‘) as fp: data = fp.readlines() for line in data: time = re.match(‘(\\w{3}\\s(\\w{3})\\s{1,2}\\d{1,2}\\s(\\d{2}:\\d{2}:\\d{2})\\s(\\d{4}))::((\\w+)@((\\w+\\.?)+))::‘, line) # 提取时间戳 if time is not None: times.append(time.group(1)) # 提取完整时间戳 months.append(time.group(2)) # 提取月份 years.append(time.group(4)) # 提取年份 clocks.append(time.group(3)) # 提取时间 emails.append(time.group(5)) # 提取邮件 lnames.append(time.group(6)) # 提取登录名 dnames.append(time.group(7)) # 提取域名 print(‘完整时间:‘, times) print(‘月份:‘, months) print(‘年份:‘, years) print(‘时间点:‘, clocks) print(‘邮件地址:‘, emails) print(‘登录名:‘, lnames) print(‘域名:‘, dnames)
结果:

26. 使用自己的电子邮件地址替换没一行数据中的电子邮件地址
import re with open(‘path\\redata2.txt‘, ‘r‘) as fp: data = fp.readlines() for line in data: print(re.sub(‘\\[email protected](\\w+.?)+‘, ‘[email protected]‘, line).rstrip())
结果:
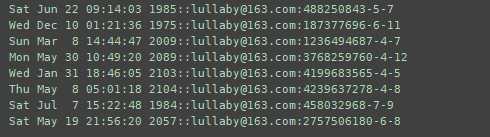
27. 从时间戳中提取月、日、年,然后以“月、日、年”的格式。
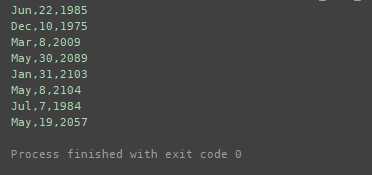
import re f = open(‘redata.txt‘,‘r‘) with open(‘path\\redata2.txt‘, ‘r‘) as fp: data = fp.readlines() for line in data: m = re.match(‘^\\w{3}\\s(\\w{3})\\s{1,2}(\\d{1,2})\\s\\d{2}:\\d{2}:\\d{2}\\s(\\d{4})‘, line) print(‘%s,%s,%s‘ % (m.group(1), m.group(2), m.group(3)))
结果:
以上是关于《python核心编程》——正则表达式学习笔记(课后练习)的主要内容,如果未能解决你的问题,请参考以下文章