Bert变体--Deberta
Posted shiiiilong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Bert变体--Deberta相关的知识,希望对你有一定的参考价值。
解耦注意力的解码增强型BERT
Deberta
论文泛读126BERT 句子表示的自引导对比学习
贴一下汇总贴:论文阅读记录
论文链接:《Self-Guided Contrastive Learning for BERT Sentence Representations》
一、摘要
尽管 BERT 及其变体已经重塑了 NLP 格局,但仍不清楚如何最好地从此类预训练的 Transformer 中导出句子嵌入。在这项工作中,我们提出了一种对比学习方法,该方法利用自我指导来提高 BERT 句子表示的质量。我们的方法以自我监督的方式微调 BERT,不依赖于数据增强,并使通常的 [CLS] 标记嵌入能够用作句子向量。此外,我们重新设计了对比学习目标(NT-Xent)并将其应用于句子表示学习。我们通过大量实验证明,我们的方法在各种与句子相关的任务上比竞争基线更有效。我们还表明它在推理方面是有效的,并且对域转移具有鲁棒性。
二、结论
在本文中,我们提出了一种对比学习方法与自我引导改进BERT句子嵌入。通过大量的实验,我们已经证明了我们的方法可以享受对比学习的好处,而不依赖外部程序,如数据扩充或反向翻译,成功地生成比竞争基线更高质量的句子表示。
此外,我们的方法在推理方面是高效的,因为一旦训练完成,它不需要任何后处理,并且对域转移具有相对鲁棒性。
三、model
BERT通常需要某种类型的适应才能正确地应用于感兴趣的任务,所以如果没有微调,就从BERT直接派生句子嵌入可能是不理想的。
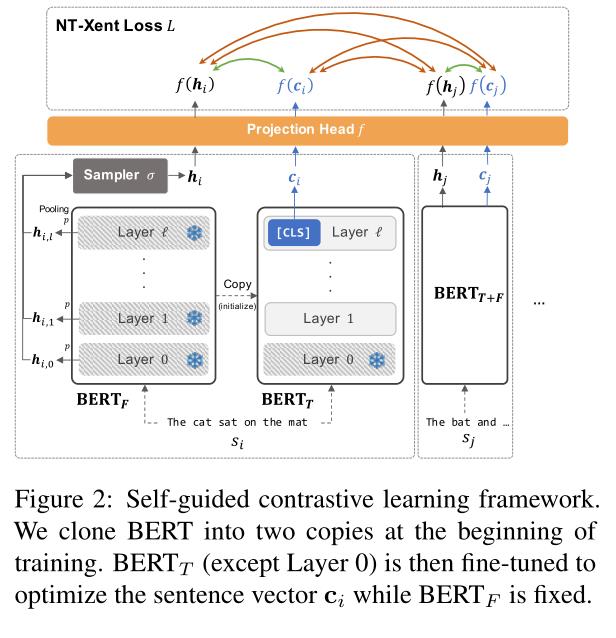
自我引导对比学习框架:
以上是关于Bert变体--Deberta的主要内容,如果未能解决你的问题,请参考以下文章