Hadoop 压缩从理论到实战
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop 压缩从理论到实战相关的知识,希望对你有一定的参考价值。
参考技术A在大数据领域,无论上层计算引擎采用的是什么,在存储过程中,压缩都是一个避不开的问题。合适的压缩选择可以降低存储成本、减少网络传输I/O。而错误的压缩选择则可能让 cpu 负荷达到瓶颈、降低并发度等等,所以是否选择压缩、选择什么压缩格式在大数据存储环节中都是一个至关重要的问题。
点评:压缩时间和压缩率之间的取舍本质上是 cpu 资源和存储资源的取舍。是否需要支持分片也不是绝对的,如果单个文件大小均小于 splitSize,则没必要支持分片。
点评:一阶段考虑尽可能支持分片(单个文件大于 splitSize 时)。二阶段考虑尽可能快的压缩速度。三阶段根据是作为长期归档(几乎不用)or 作为下一作业输入,考虑尽可能高的压缩能力 or 支持分片。
点评:有两点需要注意,第一点:这里的速度和压缩率没有具体测试数据,而是给出了一个模糊的表达。因为即使具体测试了速度和压缩率,也会因数据不同而结果有很大的差异。后面会给出测试的脚本,大家可以结合自己的表数据自行测试。第二点:有些压缩格式性能参数很相似,为什么 Hadoop 中要搞这么多种?较为直观的一个原因是:不同存储格式支持的压缩是不一样的,比如 orc 存储格式只支持 zlib 和 snappy 两种压缩 [8] ,parquet 虽然支持很多压缩格式,但是不支持 bzip2 [7]
以下摘自《Hadoop The Definitive Guide》
重点阅读文中加粗片段。大致意思是:因为 gzip 压缩格式使用的 DEFLATE 压缩算法没办法做到随机任意读取,必须同步顺序读取。也就意味着没办法为每一个 block 创建一个分片(split),然后为该分片启一个 mapper 去读取数据。所以即使 gzip 文件有很多 block,MR 程序也只会启动一个 Mapper 去读取所有的 block。也即 gzip 这种压缩格式不支持分片。相反的,如果压缩格式使用的算法支持随机任意读取,那么就可以为每一个 block 创建一个分片,同时启动一个 mapper 去读取数据,这样有多少个 block 就有多少个分片,就有多少个 mapper ,这些 mapper 并行读取数据,效率大大提升。上述涉及到几个小概念,接下来分别进行详述。
一句话总结: zlib、gzip 在大数据语境中都是一种 压缩格式 ,他们使用相同的 压缩算法: DEFLATE,DefaultCodec 是 zlib 使用的 编解码器 ,Gzip 使用的编解码器是 GzipCodec
我们知道,Hadoop 在任务切分时,是按照文件的粒度进行的。即一个文件一个文件进行切分。而每一个文件切分成几块,取决于 splitSize 的大小。比如两个文件,第一个文件 300M,第二个文件150M。分片大小是128M,那么对于第一个文件将会切分成3片(128M,128M,44M),第二个文件会切分成2片(128M,22M)。共计5片。所以分片数量除了由文件数决定,另一个决定因素就是 splitSize 即分片大小。
splitSize 如何计算?
几个前提:
影响参数:
接下来进行实际验证:
经过了 2.4.2 中的一系列实验,验证了一个结论:当一个输入格式支持分片时,mapper 数量是无限制的,反之 mapper 数量小于等于文件的数量。所以我们可以通过设置参数来试图调小分片大小来增加 mapper 数量看其上限是否等于文件数量即可。假如输入的文件个数只有一个,那么当 mapper 数量大于1的时候,说明该输入格式是支持分片的。
大家可以根据自己数据集和想测试的压缩和存储格式自行修改脚本。通过以上脚本跑出来的结果如下:
由 2.1 中评价压缩的三项指标可知,压缩率、压缩/解压速度、是否支持分片是衡量压缩最重要的三项指标。3.1.1小节中只对压缩率进行了测试。压缩/解压速度可以通过跑一些查询语句进一步测试。这里就不展开测试了。业界中常用的存储格式一般是 parquet, orc,所以上面测试除了纯文本只测试了这两种存储格式。
我们可以通过 hive> set io.compression.codecs; 来查看当前Hadoop集群支持的压缩,在公司的集群中查询得到的结果是:
可以看到 lzo 有两种编解码器: LzoCodec 和 LzopCodec。他们之间有什么区别呢?
如果你阅读过关于 Hadoop 压缩的文章,应该可以看到,绝大多数文章中对于 snappy 是否支持分片都是直接给出的否定的答案。 CDH 的文档中也指出来 snappy 是不支持分片的。
看文中加粗片段,虽然 snappy 本身是不支持分片的,但是如果 snappy 存储在一些特定的存储格式比如 SequenceFile 或者 Avro 中,那么是可以支持分片的。也就是说 snappy 是否支持分片是分情况讨论的。不能说使用了 snappy 压缩就一定不支持分片。前面提到了,业界中常用的存储格式一般是 parquet 或者 orc,而上面 CDH 的文章中恰恰没有提到 parquet 和 orc 是否支持,接下来以 parquet 为例,进行测试。测试内容即为 parquet + snappy 组合,是否支持分片。
首先准备数据,因为之前做压缩率测试,已经有了 parquet + snappy 文件了,这里直接拿来用。
一共3个输入文件,启了6个mapper,说明输入文件是可以分片的。即 parquet + snappy 的组合是支持分片的。在《Hadoop The Definitive Guide》中也对 parquet 是否支持分片有说明:
以 mapreduce.output.fileoutputformat.compress.codec 为例,这个参数可以在三个地方配置:
那么当三者都设置时,以哪个为准呢?按照经验来看,一定是粒度小的优先级大于粒度大的优先级。经过测试也验证了这种猜测。即:表级别 > hive > hadoop
初学者往往容易混淆存储格式和压缩格式之间的关系,其实二者是完全独立的。如果完整的阅读了该篇文章,应该已经消除了这一块理解对误区。这里总结一下:比如 parquet, orc,他们都是常见的 存储格式 。是否使用压缩,使用何种压缩都是可以设置的。而 zlib、gzip、lzo、lz4、snappy 等等这些都是常见的 压缩格式 ,他们既可以依附于某些 存储格式 ,比如之前提到的 parquet + snappy,orc + zlib 等等。也可以脱离特定的 存储格式 ,比如纯文本文件进行压缩,text + parquet, text + bzip2 等等。
Docker最全教程——从理论到实战
原文:Docker最全教程——从理论到实战(八)在本系列教程中,笔者希望将必要的知识点围绕理论、流程(工作流程)、方法、实践来进行讲解,而不是单纯的为讲解知识点而进行讲解。也就是说,笔者希望能够让大家将理论、知识、思想和指导应用到工作的实际场景和实践之中,而不是拿着字典写文章,抱着宝典写代码。至于很多具体的语法、技术细节,除了常用的知识点,笔者更希望大家阅读官方文档——毕竟看官网比看书靠谱多了,官网会一直更新和改进,而书和教程自出版或发布之后,基本上就“死“了。
本系列教程预计全部完成还需要2到3个月的时间。在这个过程中,您可以加入我们一起讨论、交流和分享这一块的技术。我们也希望得到大家的支持,请多多点赞,你们的支持是我们前进的最大动力!
使用Azure DevOps来完成CI
Azure DevOps,以前叫VSTS,现在被微软改名部正式更名为Azure DevOps,说明微软云为先之心仍然蠢蠢欲动。不过和VSTS一样,微软都提供了免费的使用额度,对于小团队和个人开发者来说,完全是足够了。

什么是DevOps?
DevOps(Development和Operations的组合词)是一组过程、方法与系统的统称,用于促进开发(应用程序/软件工程)、技术运营和质量保障(QA)部门之间的沟通、协作与整合。它是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。它的出现是由于软件行业日益清晰地认识到:为了按时交付软件产品和服务,开发和运营工作必须紧密合作。
DevOps的引入能对产品交付、测试、功能开发和维护(包括──曾经罕见但如今已屡见不鲜的──“热补丁”)起到意义深远的影响。在缺乏DevOps能力的组织中,开发与运营之间存在着信息“鸿沟”──例如运营人员要求更好的可靠性和安全性,开发人员则希望基础设施响应更快,而业务用户的需求则是更快地将更多的特性发布给最终用户使用。这种信息鸿沟就是最常出问题的地方。

DevOps经常被描述为“开发团队与运营团队之间更具协作性、更高效的关系”。由于团队间协作关系的改善,整个组织的效率因此得到提升,伴随频繁变化而来的生产环境的风险也能得到降低。
总之,通过DevOps,各专业团队之间的协调和协作得到改善,缩短了将更改提交到系统与将更改投入到生产之间的时间。它还可确保此过程符合安全性和可靠性标准。结果:产品质量改善、交付速度加快、客户满意度提升。
DevOps对应用程序发布的影响
在很多企业中,应用程序发布是一项涉及多个团队、压力很大、风险很高的活动。然而在具备DevOps能力的组织中,应用程序发布的风险很低,原因如下:
- 减少变更范围
与传统的瀑布式开发模型相比,采用敏捷或迭代式开发意味着更频繁的发布、每次发布包含的变化更少。由于部署经常进行,因此每次部署不会对生产系统造成巨大影响,应用程序会以平滑的速率逐渐生长。
- 加强发布协调
靠强有力的发布协调人来弥合开发与运营之间的技能鸿沟和沟通鸿沟;采用电子数据表、电话会议、即时消息、企业门户(wiki、sharepoint)等协作工具来确保所有相关人员理解变更的内容并全力合作。
- 自动化
强大的部署自动化手段确保部署任务的可重复性、减少部署出错的可能性。
与传统开发方法那种大规模的、不频繁的发布(通常以“季度”或“年”为单位)相比,敏捷方法大大提升了发布频率(通常以“天”或“周”为单位)。减少变更范围与传统的瀑布式开发模型相比,采用敏捷或迭代式开发意味着更频繁的发布、每次发布包含的变化更少。由于部署经常进行,因此每次部署不会对生产系统造成巨大影响,应用程序会以平滑的速率逐渐生长。加强发布协调靠强有力的发布协调人来弥合开发与运营之间的技能鸿沟和沟通鸿沟;采用电子数据表、电话会议、即时消息、企业门户(wiki、sharepoint)等协作工具来确保所有相关人员理解变更的内容并全力合作。强大的自动化部署手段能够确保部署任务的可重复性、减少部署出错的可能性。
适用于容器的 CI/CD 流程
使用容器,可轻松地持续生成和部署应用程序。
Azure DevOps 可以通过设置持续版本以生成容器映像和业务流程,让我们能更快、更可靠地进行部署。以下是一个适用于容器和Azure的CI/CD 流程:
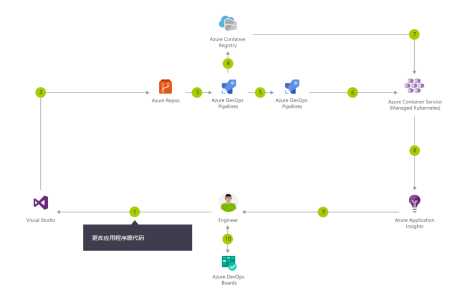
步骤说明:

使用Azure DevOps来配置一个简单的CI流程
Azure DevOps服务涵盖了整个开发生命周期,可帮助开发人员更快地高质量地交付软件,其提供了Azure Pipelines、Azure Boards、Azure Artifacts、Azure Repos和Azure Test Plans。关于Azure DevOps我们就介绍到这里,毕竟是免费介绍。
现在,我们需要侧重介绍的是Pipelines,也就是代码流水线。看,多形象,所以以前自诩为码农是错误的,我们应该是码工,广大流水线工人的一环,无产阶级之一,共产主义接班人。不好意思,又偏题了,我们继续:
首先,我们需要定义一个流水线,为了便于演示,我这里就定义一些针对Docker的简单步骤,大家可以按需添加步骤,比如单元测试步骤等等。
如图所示,步骤很简单,首先设置代码源,这里我们直接对接Magicodes.Admin框架的git库地址。Git库地址大家可以在这里找到:https://gitee.com/xl_wenqiang/Magicodes.Admin.Core。
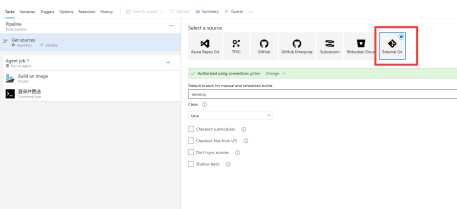
因为代码是托管再码云,所以我们选择如上图所示的最后一种方式,并且选择对应的分支。
接下来,我们需要添加job和task。job添加一个默认的即可,无需设置什么条件和参数。接下来我们添加task,实际上就是步骤。
第一步,构建镜像。
我们需要添加一个docker task:
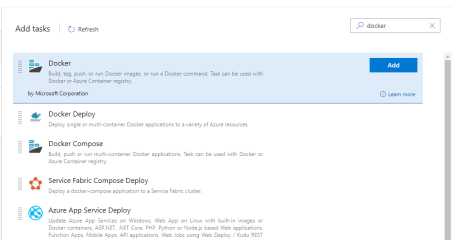
然后设置command命令为build,也就是构建:
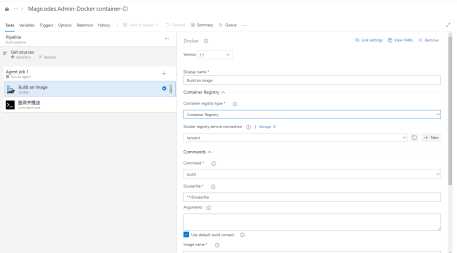
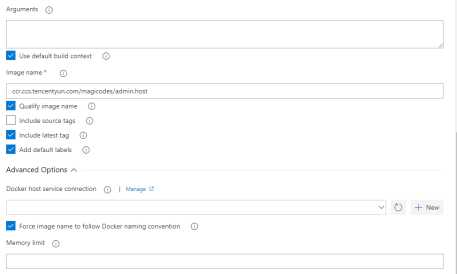
构建配置我们可以根据自己的需求来设置,比如根据分支设置镜像版本等等。
第二步,登录腾讯云镜像仓库并且推送。
这一步,就有点门槛了,原生的docker命令并不好使,因为task之间的上下文是断开的,也就是login了你也没法push。这时候,还是命令行靠谱,简单粗暴。所以我们需要添加一个Command line task:
然后编写命令脚本:
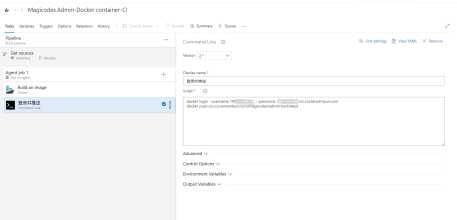
简单粗暴的两个步骤就搞定了,大家可以根据自己的持续集成流程来定制,毕竟微软在开发者服务这块淫荡多年,还是相当给力的。我们可以初步看看支持的task:
非常之多,足够我们随便玩了。而且玩坏了还不用赔钱。
接下来,跑起来:
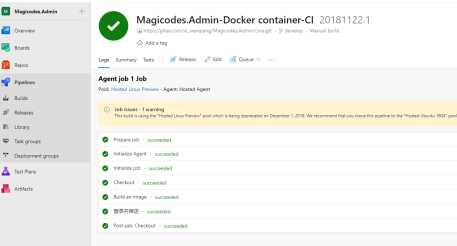
点开还能看到详细的过程:
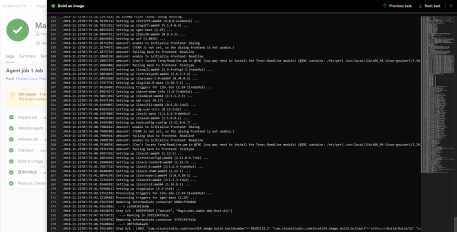
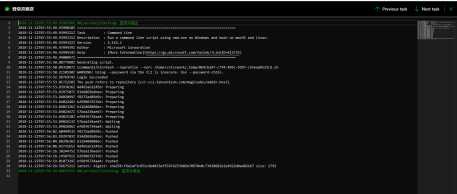
激不激动,简单不简单?就这么几下就搞定了。产品很强大,就是拉取代码有点慢,看起来是托管在国外。顺手一查,额,美国:
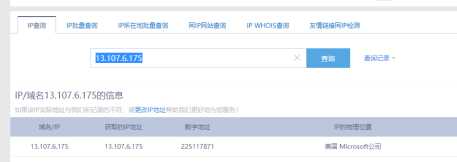
因此,我们不是很推荐使用Azure DevOps来完成CI,网络的延迟足够拖垮我们焦虑的神经。但是如果我们的代码托管在Github,那么使用Azure DevOps是不错的选择。在接下来的教程中,我们会讲解如何打造自己的Github开源库的CI流程——不仅完全自动化,而且还支持在readme页面添加各种动态图标。
以上是关于Hadoop 压缩从理论到实战的主要内容,如果未能解决你的问题,请参考以下文章