常见的哈希算法和应用
Posted IT职场笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常见的哈希算法和应用相关的知识,希望对你有一定的参考价值。
哈希算法经常会被用到,比如我们Go里面的map,Java的HashMap,目前最流行的缓存Redis都大量用到了哈希算法。它们支持把很多类型的数据进行哈希计算,我们实际使用的时候并不用考虑哈希算法的实现。而其实不同的数据类型,所使用到的哈希算法并不一样。
DJB
下面是C语言实现。初始值是5381,遍历整个串,按照hash * 33 +c的算法计算。得到的结果就是哈希值。
unsigned long
hash(unsigned char *str)
unsigned long hash = 5381;
int c;
while (c = *str++)
hash = ((hash << 5) + hash) + c; /* hash * 33 + c */
return hash;
里面涉及到两个神奇的数字,5381和33。为什么是这两个数?我还特意去查了查,说是经过大量实验,这两个的结果碰撞小,哈希结果分散。
还有一个事情很有意思,乘以33是用左移和加法实现的。底层库对性能要求高啊。
DJB 在 Redis中的应用
在Redis中,它被用来计算大小写不敏感的字符串哈希。
static uint32_t dict_hash_function_seed = 5381; /* And a case insensitive hash function (based on djb hash) */ unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) unsigned int hash = (unsigned int)dict_hash_function_seed; while (len--) hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */ return hash;
算法和之前的一样,只是多了一个tolower函数把字符转成小写。
Java 字符串哈希
看了上面的再看Java内置字符串哈希就很有意思了。Java对象有个内置对象hash,它缓存了哈希结果,如果当前对象有缓存,直接返回。如果没有缓存,遍历整个字符串,按照hash * 31 + c的算法计算。
public int hashCode()
int h = hash;
if (h == 0 && value.length > 0)
char val[] = value;
for (int i = 0; i < value.length; i++)
h = 31 * h + val[i];
hash = h;
return h;
和DJB相比,初始值从5381变成了0,乘的系数从33变成了31。
FNV
字符串每一位都看成是一个数字,32位的话看成是16777169进制的数字,计算当前串的哈希值就是在把当前串转成10进制。
const primeRK = 16777619 // hashstr returns the hash and the appropriate multiplicative // factor for use in Rabin-Karp algorithm. func hashstr(sep string) (uint32, uint32) hash := uint32(0) for i := 0; i < len(sep); i++ hash = hash*primeRK + uint32(sep[i]) var pow, sq uint32 = 1, primeRK for i := len(sep); i > 0; i >>= 1 if i&1 != 0 pow *= sq // 只有32位,超出范围的会被丢掉 sq *= sq return hash, pow
这个算法的厉害之处在于他可以保存状态。比如有个字符串ab,它的哈希值是a*E+b=HashAB,如果计算bc的哈希值,可以利用第一次计算的结果(HashAB-a*E)*E+c=HashBC。这么一个转换例子里是两个字符效果不明显,如果当前串是100个字符,后移一位的哈希算法性能就会快很多。
在Golang里面字符串匹配算法查找用到了这个。
Thomas Wang’s 32 bit Mix Function
前面说的都是字符串的哈希算法,这次说整数的。
public int hash32shift(int key) key = ~key + (key << 15); // key = (key << 15) - key - 1; key = key ^ (key >>> 12); key = key + (key << 2); key = key ^ (key >>> 4); key = key * 2057; // key = (key + (key << 3)) + (key << 11); key = key ^ (key >>> 16); return key;
Redis对于Key是整数类型时用了这个算法。
Murmur
就纯哈希算法来说,这个算法算是综合能力不错的算法了。碰撞小、性能好。
Hash Lowercase Random UUID Numbers ============= ============= =========== ============== Murmur 145 ns 259 ns 92 ns 6 collis 5 collis 0 collis FNV-1a 152 ns 504 ns 86 ns 4 collis 4 collis 0 collis FNV-1 184 ns 730 ns 92 ns 1 collis 5 collis 0 collis▪ DBJ2a 158 ns 443 ns 91 ns 5 collis 6 collis 0 collis▪▪▪ DJB2 156 ns 437 ns 93 ns 7 collis 6 collis 0 collis▪▪▪ SDBM 148 ns 484 ns 90 ns 4 collis 6 collis 0 collis** SuperFastHash 164 ns 344 ns 118 ns 85 collis 4 collis 18742 collis CRC32 250 ns 946 ns 130 ns 2 collis 0 collis 0 collis LoseLose 338 ns - - 215178 collis
一般在分布式系统中用的比较多。对于一个Key做哈希,把不同的请求转发到不同的服务器上面。
推荐一个Go的实现。
CRC32
CRC32的哈希碰撞和murmur的差不多,但是CRC32可以使用CPU的硬件加速实现哈希提速。
在Codis上就使用了这个哈希算法做哈希分片,SlotId= crc32(key) % 1024。
Codis使用Go语言实现,CRC32算法直接用了Go的原生包hash/crc32。这个包会提前判断当前CPU是否支持硬件加速:
func archAvailableIEEE() bool return cpu.X86.HasPCLMULQDQ && cpu.X86.HasSSE41
memhash
Go语言内置的哈希表数据结构map,也是一个哈希结构,它内置的哈希算法更讲究。
这里用到的哈希算法是memhash,源代码在runtime/hash32.go里面。它基于谷歌的两个哈希算法实现。大家有兴趣的可以去研究下具体实现。
// Hashing algorithm inspired by // xxhash: https://code.google.com/p/xxhash/ // cityhash: https://code.google.com/p/cityhash/
memhash在具体实现时也用到了硬件加速。如果硬件支持,会用AES哈希算法。如果不支持,才会去用memhash。
func memhash(p unsafe.Pointer, seed, s uintptr) uintptr if GOARCH == "386" && GOOS != "nacl" && useAeshash return aeshash(p, seed, s) h := uint32(seed + s*hashkey[0])
本文来自博客园,作者:IT随笔,转载请注明原文链接:https://www.cnblogs.com/binyue/p/17326639.html
哈希算法七大常见应用
0
将任意长度的二进制值串映射为固定长度的二进制值串,这个映射的规则就是哈希算法,而通过原始数据映射之后得到的二进制值串就是哈希值。但是,要想设计一个优秀的哈希算法并不容易,根据我的经验,我总结了需要满足的几点要求:
1、从哈希值不能反向推导出原始数据(所以哈希算法也叫单向哈希算法);
2、对输入数据非常敏感,哪怕原始数据只修改了一个Bit,最后得到的哈希值也大不相同;
3、散列冲突的概率要很小,对于不同的原始数据,哈希值相同的概率非常小;
4、哈希算法的执行效率要尽量高效,针对较长的文本,也能快速地计算出哈希值。
0
说到哈希算法的应用,最先想到的应该就是安全加密。最常用于加密的哈希算法是MD5(MD5 Message-Digest Algorithm,MD5消息摘要算法)和SHA(Secure Hash Algorithm,安全散列算法)。除了这两个之外,当然还有很多其他加密算法,比如DES(Data Encryption Standard,数据加密标准)、AES(Advanced Encryption Standard,高级加密标准)。
前面我讲到的哈希算法四点要求,对用于加密的哈希算法来说,有两点格外重要。第一点是很难根据哈希值反向推导出原始数据,第二点是散列冲突的概率要很小。第一点很好理解,加密的目的就是防止原始数据泄露,所以很难通过哈希值反向推导原始数据,这是一个最基本的要求。所以我着重讲一下第二点。实际上,不管是什么哈希算法,我们只能尽量减少碰撞冲突的概率,理论上是没办法做到完全不冲突的。为什么这么说呢?
这里就基于组合数学中一个非常基础的理论,鸽巢原理(也叫抽屉原理)。这个原理本身很简单,它是说,如果有10个鸽巢,有11只鸽子,那肯定有1个鸽巢 中的鸽子数量多于1个,换句话说就是,肯定有2只鸽子在1个鸽巢内。有了鸽巢原理的铺垫之后,我们再来看,为什么哈希算法无法做到零冲突?我们知道,哈希算法产生的哈希值的长度是固定且有限的。比如前面举的MD5的例子,哈希值是固定的128位二进制串,能表示的数据是有限的,最多能表 示2^128个数据,而我们要哈希的数据是无穷的。基于鸽巢原理,如果我们对2^128+1个数据求哈希值,就必然会存在哈希值相同的情况。这里你应该能想 到,一般情况下,哈希值越长的哈希算法,散列冲突的概率越低。
我先来举一个例子。如果要在海量的图库中,搜索一张图是否存在,我们不能单纯地用图片的元信息(比如图片名称)来比对,因为有可能存在名称相同但图片内容不同,或者名称不同图片内容相同的情况。那我们该如何搜索呢?我们知道,任何文件在计算中都可以表示成二进制码串,所以,比较笨的办法就是,拿要查找的图片的二进制码串与图库中所有图片的二进制码串一一比对。如果相同,则说明图片在图库中存在。但是,每个图片小则几十KB、大则几MB,转化成二进制是一个非常长的串,比对起来非常耗时。有没有比较快
的方法呢?
我们可以给每一个图片取一个唯一标识,或者说信息摘要。比如,我们可以从图片的二进制码串开头取100个字节,从中间取100个字节,从最后再取100个字 节,然后将这300个字节放到一块,通过哈希算法(比如MD5),得到一个哈希字符串,用它作为图片的唯一标识。通过这个唯一标识来判定图片是否在图库 中,这样就可以减少很多工作量。如果还想继续提高效率,我们可以把每个图片的唯一标识,和相应的图片文件在图库中的路径信息,都存储在散列表中。当要查看某个图片是不是在图库中的时候,我们先通过哈希算法对这个图片取唯一标识,然后在散列表中查找是否存在这个唯一标识。如果不存在,那就说明这个图片不在图库中;如果存在,我们再通过散列表中存储的文件路径,获取到这个已经存在的图片,跟现在要插入的图片做全量的比对,看是否完全一样。如果一样,就说明已经存在;如果不一样,说明两张图片尽管唯一标识相同,但是并不是相同的图片。
电驴这样的BT下载软件你肯定用过吧?我们知道,BT下载的原理是基于P2P协议的。我们从多个机器上并行下载一个2GB的电影,这个电影文件可能会被分割成很多文件块(比如可以分成100块,每块大约20MB)。等所有的文件块都下载完成之后,再组装成一个完整的电影文件就行了。我们知道,网络传输是不安全的,下载的文件块有可能是被宿主机器恶意修改过的,又或者下载过程中出现了错误,所以下载的文件块可能不是完整的。如果我们没有能力检测这种恶意修改或者文件下载出错,就会导致最终合并后的电影无法观看,甚至导致电脑中毒。现在的问题是,如何来校验文件块的安全、正确、完整呢?具体的BT协议很复杂,校验方法也有很多,我来说其中的一种思路。我们通过哈希算法,对100个文件块分别取哈希值,并且保存在种子文件中。我们在前面讲过,哈希算法有一个特点,对数据很敏感。只要文件块的内容有一 丁点儿的改变,最后计算出的哈希值就会完全不同。所以,当文件块下载完成之后,我们可以通过相同的哈希算法,对下载好的文件块逐一求哈希值,然后 跟种子文件中保存的哈希值比对。如果不同,说明这个文件块不完整或者被篡改了,需要再重新从其他宿主机器上下载这个文件块
HashTable中用到的散列函数,在某种情况下可以使用哈希算法代替散列函数。
前面讲了很多哈希算法的应用,实际上,散列函数也是哈希算法的一种应用。我们前两节讲到,散列函数是设计一个散列表的关键。它直接决定了散列冲突的概率和散列表的性能。不过,相对哈希算法的其他应用,散列函数对于散列算法冲突的要求要低很多。即便出现个别散列冲突,只要不是过于严重,我们都可以通过开放寻址法或者链表法解决。不仅如此,散列函数对于散列算法计算得到的值,是否能反向解密也并不关心。散列函数中用到的散列算法,更加关注散列后的值是否能平均分布,也就是,一组数据是否能均匀地散列在各个槽中。除此之外,散列函数执行的快慢,也会影响散列表的性能,所以,散列函数用的散列算法一般都比较简单,比较追求效率。
1、如果客户端很多,映射表可能会很大,比较浪费内存空间;
2、客户端下线、上线,服务器扩容、缩容都会导致映射失效,这样维护映射表的成本就会很大;
1.如何统计“搜索关键词”出现的次数?
假如我们有1T的日志文件,这里面记录了用户的搜索关键词,我们想要快速统计出每个关键词被搜索的次数,该怎么做呢? 我们来分析一下。这个问题有两个难点,第一个是搜索日志很大,没办法放到一台机器的内存中。第二个难点是,如果只用一台机器来处理这么巨大的数据,处理时间会很长。针对这两个难点,我们可以先对数据进行分片,然后采用多台机器处理的方法,来提高处理速度。具体的思路是这样的:为了提高处理的速度,我们用n台机器并行处理。我们从搜索记录的日志文件中,依次读出每个搜索关键词,并且通过哈希函数计算哈希值,然后再跟n取模,最终得到的值,就是应该被分配到的机器编 号。这样,哈希值相同的搜索关键词就被分配到了同一个机器上。也就是说,同一个搜索关键词会被分配到同一个机器上。每个机器会分别计算关键词出现的次数,最后合并起来就是最终的结果。
实际上,这里的处理过程也是MapReduce的基本设计思想。
2.如何快速判断图片是否在图库中?
如何快速判断图片是否在图库中?上一节我们讲过这个例子,不知道你还记得吗?当时我介绍了一种方法,即给每个图片取唯一标识(或者信息摘要),然后构建散列表。假设现在我们的图库中有1亿张图片,很显然,在单台机器上构建散列表是行不通的。因为单台机器的内存有限,而1亿张图片构建散列表显然远远超过了单台机 器的内存上限。我们同样可以对数据进行分片,然后采用多机处理。我们准备n台机器,让每台机器只维护某一部分图片对应的散列表。我们每次从图库中读取一个图片,计算唯 一标识,然后与机器个数n求余取模,得到的值就对应要分配的机器编号,然后将这个图片的唯一标识和图片路径发往对应的机器构建散列表。当我们要判断一个图片是否在图库中的时候,我们通过同样的哈希算法,计算这个图片的唯一标识,然后与机器个数n求余取模。假设得到的值是k,那就去编 号k的机器构建的散列表中查找。现在,我们来估算一下,给这1亿张图片构建散列表大约需要多少台机器。散列表中每个数据单元包含两个信息,哈希值和图片文件的路径。假设我们通过MD5来计算哈希值,那长度就是128比特,也就是16字节。文件路径长度的上限 是256字节,我们可以假设平均长度是128字节。如果我们用链表法来解决冲突,那还需要存储指针,指针只占用8字节。所以,散列表中每个数据单元就占 用152字节(这里只是估算,并不准确)。假设一台机器的内存大小为2GB,散列表的装载因子为0.75,那一台机器可以给大约1000万(2GB*0.75/152)张图片构建散列表。所以,如果要对1亿张图片构建 索引,需要大约十几台机器。在工程中,这种估算还是很重要的,能让我们事先对需要投入的资源、资金有个大概的了解,能更好地评估解决方案的可行性。
实际上,针对这种海量数据的处理问题,我们都可以采用多机分布式处理。借助这种分片的思路,可以突破单机内存、CPU等资源的限制。
现在互联网面对的都是海量的数据、海量的用户。我们为了提高数据的读取、写入能力,一般都采用分布式的方式来存储数据,比如分布式缓存。我们有海量的数据需要缓存,所以一个缓存机器肯定是不够的。于是,我们就需要将数据分布在多台机器上。
该如何决定将哪个数据放到哪个机器上呢?我们可以借用前面数据分片的思想,即通过哈希算法对数据取哈希值,然后对机器个数取模,这个最终值就是应该存储的缓存机器编号。但是,如果数据增多,原来的10个机器已经无法承受了,我们就需要扩容了,比如扩到11个机器,这时候麻烦就来了。因为,这里并不是简单地加个机器就可以 了。原来的数据是通过与10来取模的。比如13这个数据,存储在编号为3这台机器上。但是新加了一台机器中,我们对数据按照11取模,原来13这个数据就被分配 到2号这台机器上了。
因此,所有的数据都要重新计算哈希值,然后重新搬移到正确的机器上。这样就相当于,缓存中的数据一下子就都失效了。所有的数据请求都会穿透缓存,直接去请求数据库。这样就可能发生雪崩效应,压垮数据库。所以,我们需要一种方法,使得在新加入一个机器后,并不需要做大量的数据搬移。
这时候,一致性哈希算法就要登场了。
什么是一致性哈希??
一致性Hash算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性Hash算法是对2^32取模,什么意思呢?简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下:
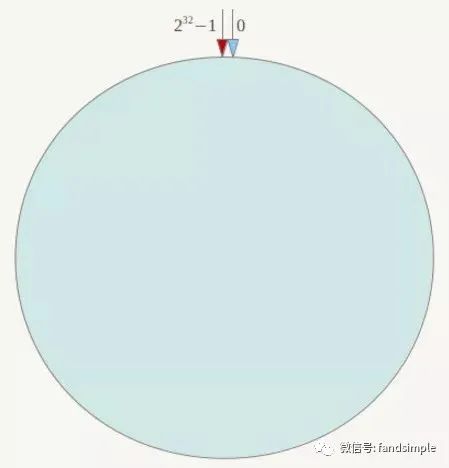
整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
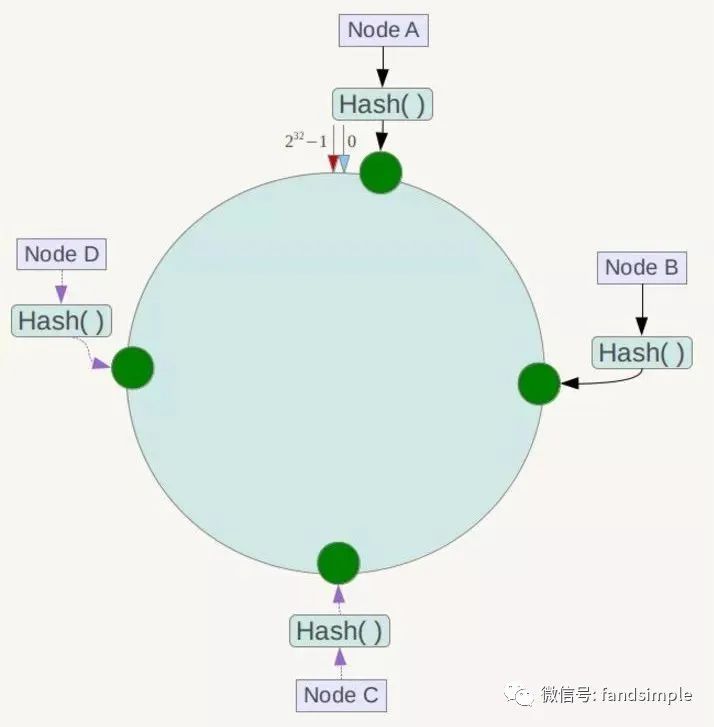
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器!
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
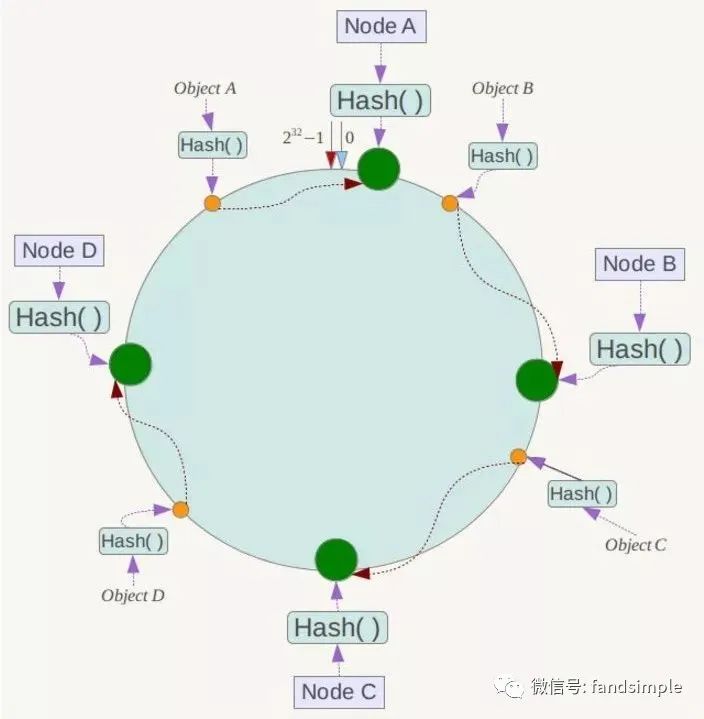
根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
一致性Hash算法的容错性和可扩展性
现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响,如下所示:
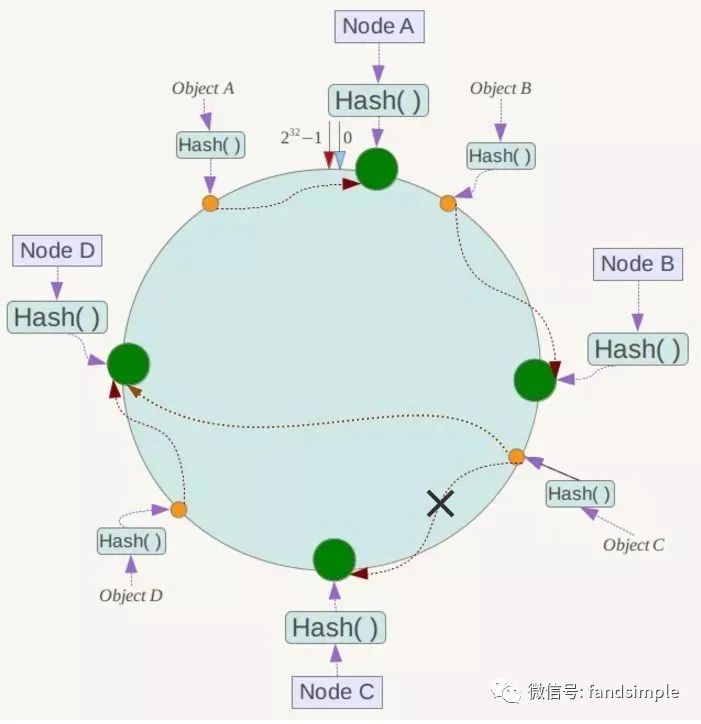
下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:
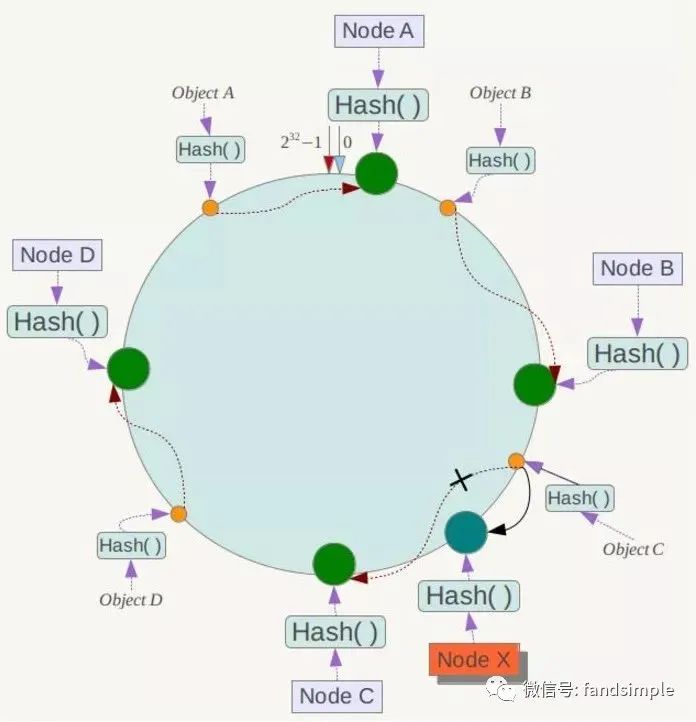
此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X !一般的,在一致性Hash算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器,其环分布如下:
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器IP或主机名的后面增加编号来实现。
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
总结:
上文中,我们一步步分析了什么是一致性Hash算法,主要是考虑到分布式系统每个节点都有可能失效,并且新的节点很可能动态的增加进来的情况,如何保证当系统的节点数目发生变化的时候,我们的系统仍然能够对外提供良好的服务,这是值得考虑的!
以上是关于常见的哈希算法和应用的主要内容,如果未能解决你的问题,请参考以下文章