Python3.6爬虫入门到精通
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3.6爬虫入门到精通相关的知识,希望对你有一定的参考价值。
本教程是崔大大的爬虫实战教程的笔记:网易云课堂
Python3+Pip环境配置
Windows下安装Python: http://www.cnblogs.com/0bug/p/8228378.html
Linux以Ubuntu为例,一般是自带的,只需配置一下默认版本:http://www.cnblogs.com/0bug/p/8598273.html
virtualenv的安装:http://www.cnblogs.com/0bug/p/8598458.html
用到的IDE是PyCharm,Windows下到官网下载就行(Professional版本):http://www.jetbrains.com/pycharm/download/
Linux下以Ubuntu为例:http://www.cnblogs.com/0bug/p/8598673.html
Pycharm需要花钱,建议花钱买正版。
Mac我就不写了,因为我没有Mac
MongoDB环境配置
Windows下安装和配置:http://www.cnblogs.com/0bug/p/8290330.html
Linux以Ubuntu为例:sudo apt-get install mongodb
Redis环境配置
Windows&Ubuntu:http://www.cnblogs.com/0bug/p/8892711.html
MySQL环境配置
Windows&Ubuntu:http://www.cnblogs.com/0bug/p/8655363.html
爬虫的基本原理
什么是爬虫?
爬虫就是请求网站并提取数据的自动化程序
爬虫的基本流程
1.发起请求
2.解析请求
3.获取相应内容
4.保存数据
什么是Request和Response?
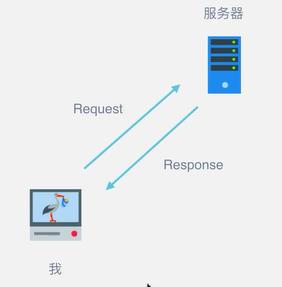
比如我们在浏览器中输入一个网址
浏览器就会发送消息给该网址所在的服务器,这个过程就叫做HTTP Request
服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处理,然后把消息回传给浏览器。这个过程叫做HTTP Response
浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后展示。
Request中包含什么?
1.请求方式:
主要有GET、POST两种类型,另外还有HEAD、PUT、DELETE、OPTIONS等。
HTTP协议中GET和POST方法的区别:http://www.cnblogs.com/0bug/p/8892959.html
2.请求URL
3.请求头如User-Agent、Host、Cookies等
HTTP协议中中常见请求头信息:http://www.cnblogs.com/0bug/p/8893038.html#_label1
4.请求体
Responst中包含什么?
1.响应状态
有多种响应状态如200代表成功,301代表跳转,404代表找不到页面,502代表服务器错误
2.响应头
如内容类型,内容长度,服务器消息,设置Cookie等等
3.响应体
主要的部分,包含了请求资源的内容,如网页HTML、图片二进制数据等。
能抓取怎样的数据?
1.网页文本:如HTML文档,Json格式文本等
2.图片:获取的是二进制文件,另存为图片格式
3.视频:同为二进制文件,保持为视频格式即可
4.其他:只有能请求,都能获取
解析方式
1.直接处理
2.Json解析
3.正则表达式
4.BeautifulSoup
5.PyQuery
6.Xpath
7.其他
怎样解决JavaScript渲染的问题
1.分析Ajax请求
2.Selenium/WebDriver
3.Splash
4.PyV8、Fhost.py
怎样保存数据
1.文本:纯文本、Json、Xml等
2.关系型数据库:如MySQL、Oracle、SQL Server等具有结构化表结构形式的存储
3.非关系型数据库:如MongoDB、Redis等Key-Value形式存储
4.二进制文件:如图片、视频、音频等等直接保存成特定格式即可
Urllib库基本使用
Ullib的基本使用:http://www.cnblogs.com/0bug/p/8893677.html
Requests库的基本使用
reuqests库的基本用法:http://www.cnblogs.com/0bug/p/8899841.html
正则表达式与re模块
正则表达式与re模块:http://www.cnblogs.com/0bug/p/8272233.html
BeautifulSoup库详解
Beautiful Soup库基础用法:http://www.cnblogs.com/0bug/p/8260834.html
PyQuery详解
PyQuery:http://www.cnblogs.com/0bug/p/8276717.html
Selenium详解
Selenium基础用法:http://www.cnblogs.com/0bug/p/8270552.html
Requests+正则表达式爬取猫眼电影
Requests+正则表达式爬取猫眼电影:http://www.cnblogs.com/0bug/p/8906490.html
以上是关于Python3.6爬虫入门到精通的主要内容,如果未能解决你的问题,请参考以下文章