.NET无侵入自动化探针原理和主流实现
Posted InCerry
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了.NET无侵入自动化探针原理和主流实现相关的知识,希望对你有一定的参考价值。
前言
最近,我在微信公众号和博客园分享了一篇关于.NET微服务系统迁移至.NET 6.0的故事的文章,引起了许多读者的关注。其中,许多人对基于 OpenTelemetry .NET 的观测指标和无侵入自动化探针颇感兴趣。事实上,我已计划抽出时间,与大家分享这方面的内容。
巧合的是,在二月末,我收到了来自 OpenTelemetry 中国社区的蒋志伟大佬的邀请,希望我能就 .NET 实现无侵入自动化探针的方法进行分享。因为关于Java等其他语言的自动化探针实现原理已有大量文章,但.NET领域却鲜有介绍,而社区对此也很感兴趣。
然而,因为 .NET 无侵入自动化探针的实现原理相当复杂,理解和完全掌握原理有很大差别。为确保文章质量和严谨性,撰写过程耗时较长,因此现在才能与大家见面。
APM探针
当我们提到 .NET 的 APM 时,许多人首先会想到 SkyWalking 。这是因为 SkyAPM-dotnet 是第一个支持.NET应用程序的开源非商业 APM 探针实现,目前很多 .NET 项目都采用了它。在此,我们要特别感谢刘浩杨等社区领袖的辛勤付出。
除了 SkyWalking 之外, Datadog APM 也是一款功能强大的商业应用性能监测工具,旨在帮助开发人员跟踪、优化并排查应用程序中的性能问题。Datadog APM 适用于多种编程语言和框架,包括 .NET 。通过使用 Datadog 丰富的功能和可视化仪表板,我们能够轻松地识别并改进性能瓶颈。
另一个比较知名的选择是 OpenTelemetry-dotnet-contrib ,这是 CNCF-OpenTelemetry 的 .NET 应用程序 APM 探针实现。虽然它的推出时间比 SkyAPM 和 Datadog APM 稍晚,但由于其开放的标准和开源的实现,许多 .NET 项目也选择使用它。
关于 APM 探针的实现原理,我们主要分为两类来介绍:平台相关指标和组件相关指标。接下来,我们将讨论如何采集这两类指标。
平台相关指标采集
那么APM探针都是如何采集 .NET 平台相关指标呢?其实采集这些指标在 .NET 上是非常简单的,因为.NET提供了相关的API接口,我们可以直接获得这些指标,这里指的平台指标是如 CPU 占用率、线程数量、GC 次数等指标。
比如在 SkyAPM-dotne t项目中,我们可以查看 SkyApm.Core 项目中的 Common 文件夹,文件夹中就有诸如里面有 CPU 指标、GC 指标等平台相关指标采集实现帮助类。

同样,在 OpenTelemetry-dotnet-contrib 项目中,我们可以在 Process 和 Runtime 文件夹中,查看进程和运行时等平台相关指标采集的实现。
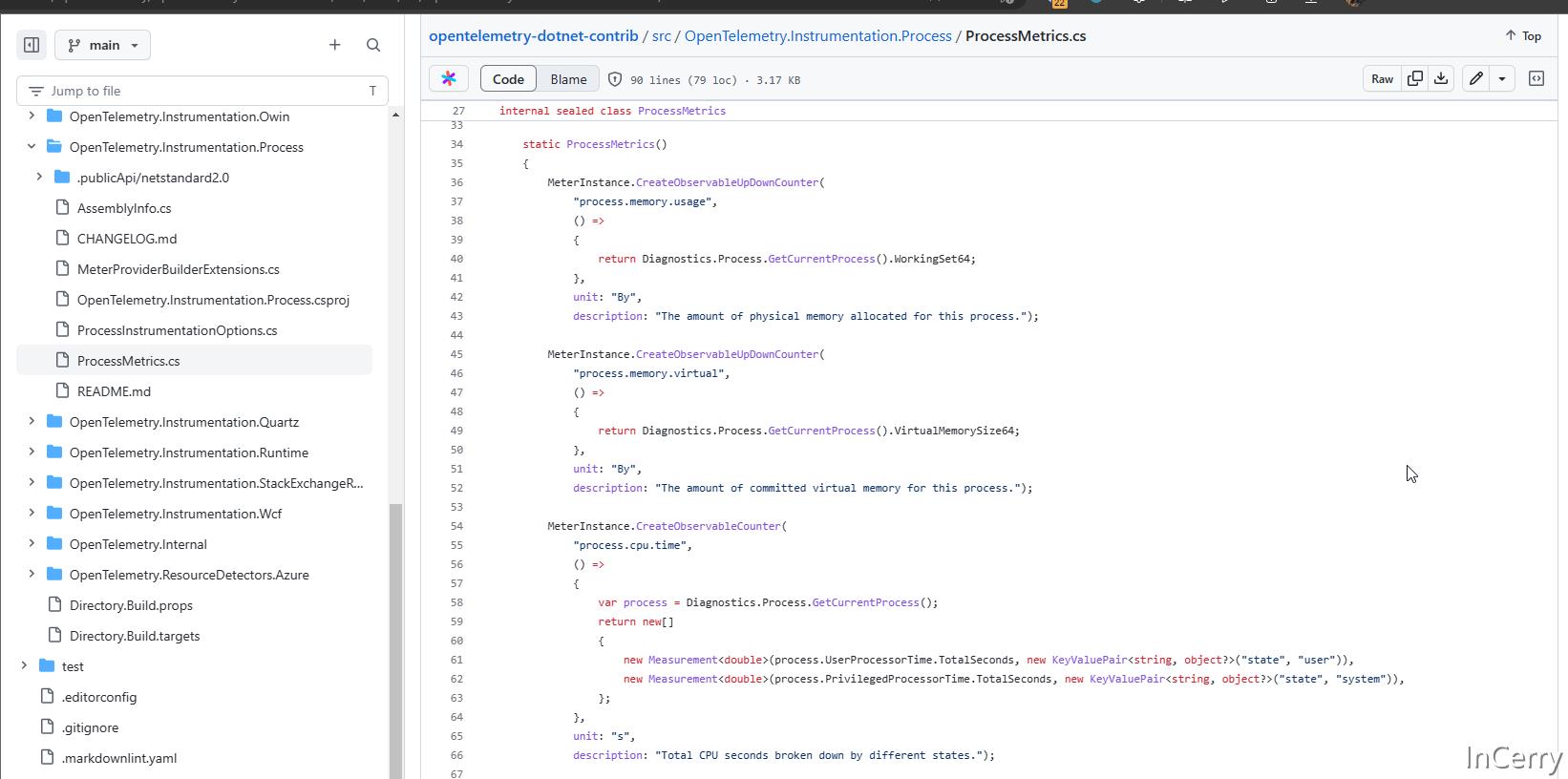
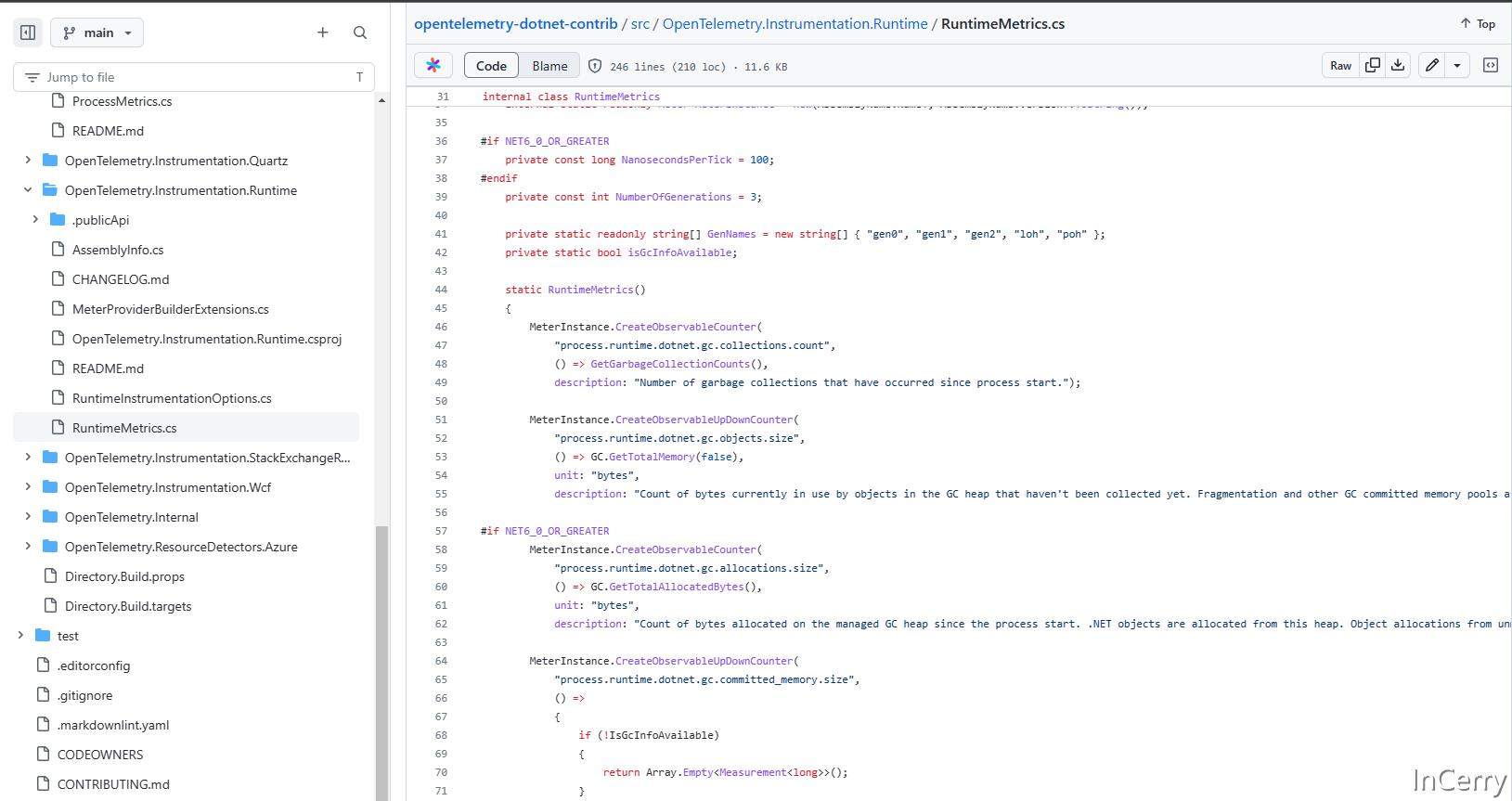
这些都是简单的 API 调用,有兴趣的同学可以自行查看代码,本文就不再赘述这些内容。
组件相关指标采集
除了平台相关指标采集,还有组件相关的指标,这里所指的组件相关指标拿 ASP.NET Core 应用程序举例,我们接口秒并发是多少、一个请求执行了多久,在这个请求执行的时候访问了哪些中间件( Redis 、MySql 、Http 调用、RPC 等等),访问中间件时传递的参数(Redis 命令、Sql 语句、请求响应体等等)是什么,访问中间件花费了多少时间。
在 SkyAPM-dotnet 项目中,我们可以直接在src目录找到这些组件相关指标采集的实现代码。
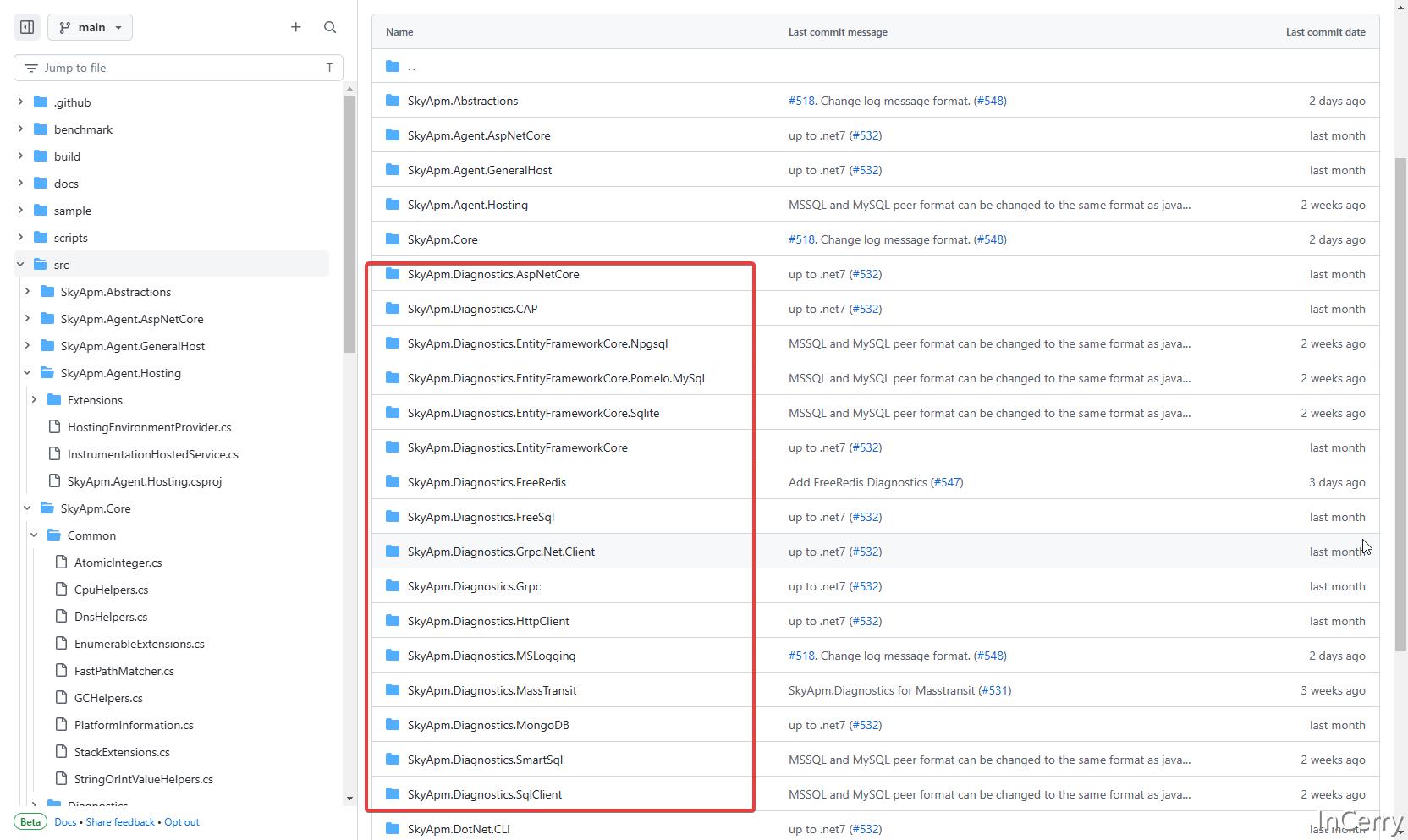
同样在 OpenTelemetry-dotnet-contrib 项目中,我们也可以在src目录找到这些组件相关指标采集代码。
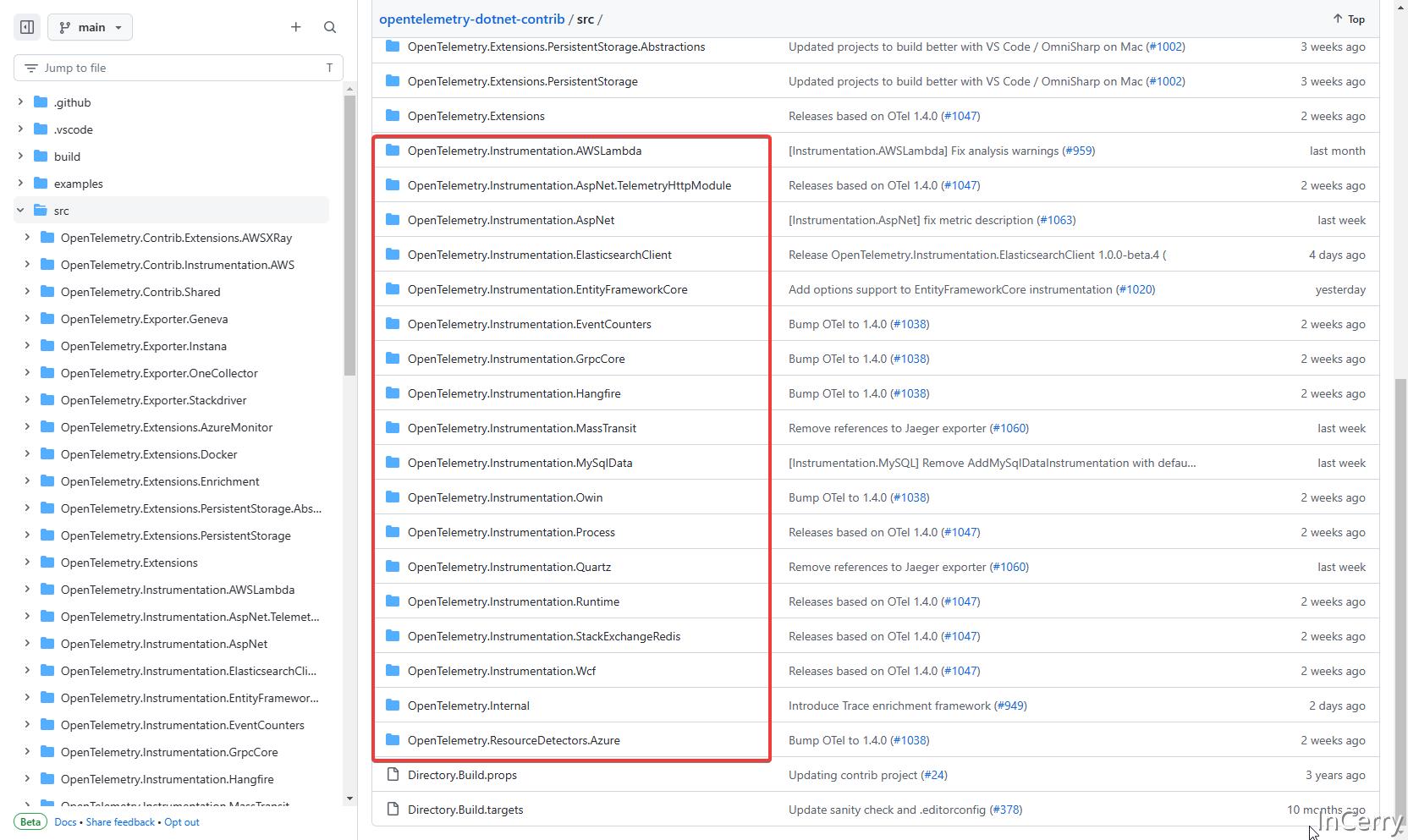
如果看过这两个APM探针实现的朋友应该都知道,组件指标采集是非常依赖DiagnosticSource技术。.NET官方社区一直推荐的的方式是组件开发者自己在组件的关键路径进行埋点,使用DiagnosticSource的方式将事件传播出去,然后其它监测软件工具可以订阅DiagnosticListener来获取组件运行状态。
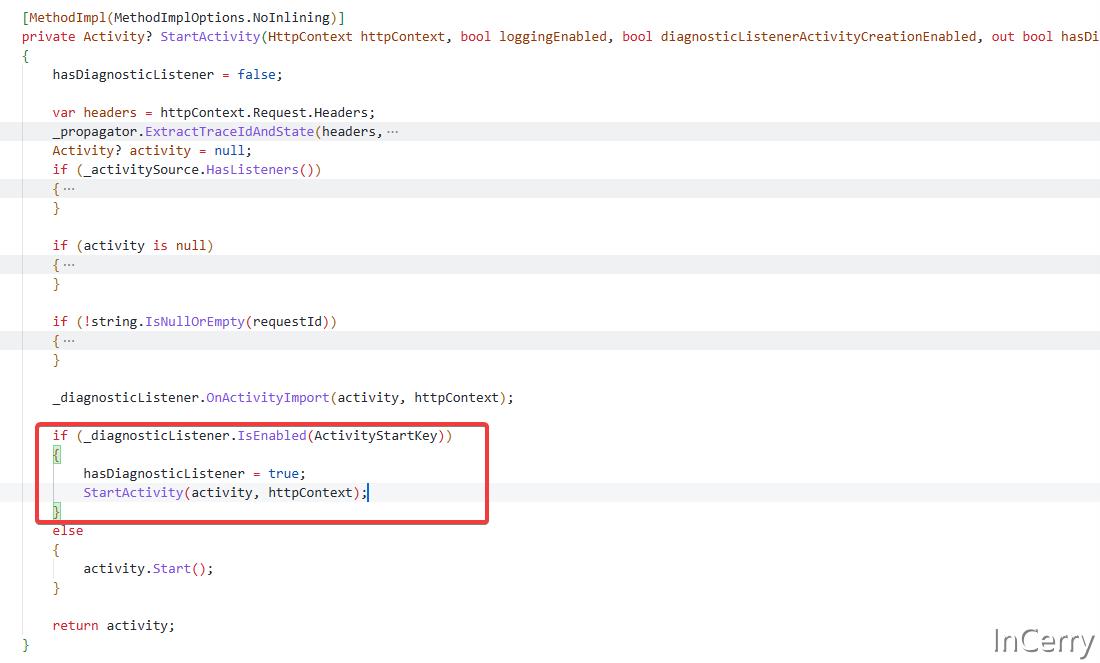
就拿 ASP.NET Core 来举例,组件源码中有[HostingApplicationDiagnostics.cs](https://github.com/dotnet/aspnetcore/blob/main/src/Hosting/Hosting/src/Internal/HostingApplicationDiagnostics.cs)这样一个类,这个类中定义了 Hosting 在请求处理过程中的几个事件。
internal const string ActivityName = "Microsoft.AspNetCore.Hosting.HttpRequestIn";
private const string ActivityStartKey = ActivityName + ".Start";
private const string ActivityStopKey = ActivityName + ".Stop";
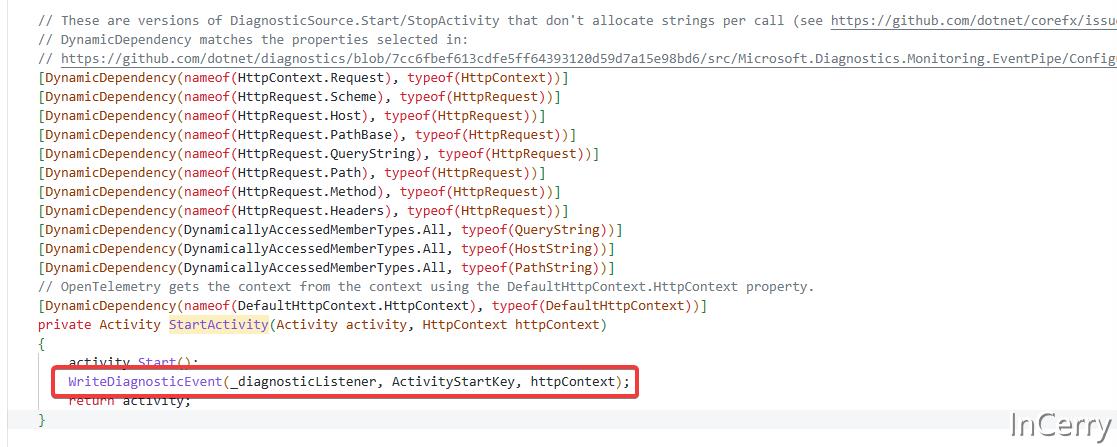
当 Hosting 开始处理请求时,会检测当前是否有监听者监听这些事件,如果有的话就会写入事件,事件也会携带当前的一些上下文信息,代码如下所示:
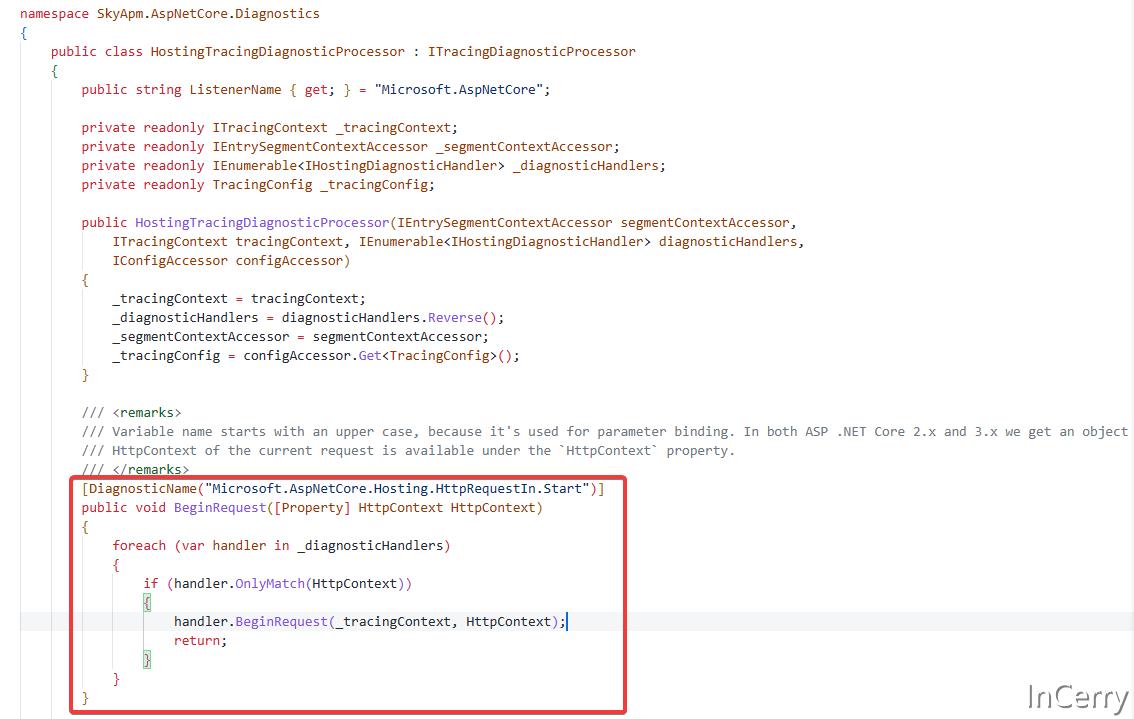
以 SkyAPM-dotnet 举例,有对应的HostingTracingDiagnosticProcessor.cs监听事件,然后获取上下文信息记录 APM 埋点信息,代码如下所示:
这种方式的优点有:
- 高效和高性能:
DiagnosticSource是 .NET 平台自带的框架,使用它硬编码可以享受到编译器和 JIT 相关优化可以避免一些性能开销。组件开发者可以控制事件传递的频率和内容,以达到最佳的性能和资源利用率。 - 灵活:通过使用
DiagnosticSource,组件开发者可以灵活地定义自己的事件模型,并按需发布事件。这意味着可以轻松地定制自己的监测需求,而不必担心过多的日志数据产生过大的开销。 - 可扩展性:使用
DiagnosticSource可以让组件的监测需求随着时间的推移而演变,而不必担心日志系统的限制。开发者可以根据自己的需要添加新的事件类型,以适应不断变化的监测需求。 - 易用性:
DiagnosticSource的 API 简单易用,订阅事件数据也很容易。这使得使用它进行组件监测变得非常容易,并且可以快速地集成到现有的监测系统中。 - 可移植性:
DiagnosticSource可以在多个平台上运行,包括 Windows、Linux 和 macOS 等。这意味着可以使用相同的事件模型来监测不同的应用程序和服务,从而简化了监测系统的设计和管理。
不过这种方式的缺点也很明显,就是必须由组件开发者显式的添加事件代码,探针的开发者也因此束手束脚,这就导致一些没有进行手动埋点的三方组件都无法添加事件监听,所以现阶段 SkyAPM-dotnet 支持的第三方组件还不是很丰富。
那么其实只要解决如何为没有进行手动埋点的组件库加入埋点就能解决 SkyAPM-dotnet 支持第三方组件多样性的问题。
.NET方法注入
从上一节我们可以知道,目前制约APM支持组件不够丰富的原因之一就是很多组件库都没有进行可观测性的适配,没有在关键路径进行埋点。
那么要解决这个问题其实很简单,我们只需要修改组件库关键路径代码给加上一些埋点就可以了,那应该如何给这些第三方库的代码加点料呢?聊到这个问题我们需要知道一个 .NET 程序是怎么从源代码变得可以运行的。
通常情况下,一个 .NET 程序从源码到运行会经过两次编译(忽略 ReadyToRun 、NativeAOT 、分层编译等情况)。如下图所示:
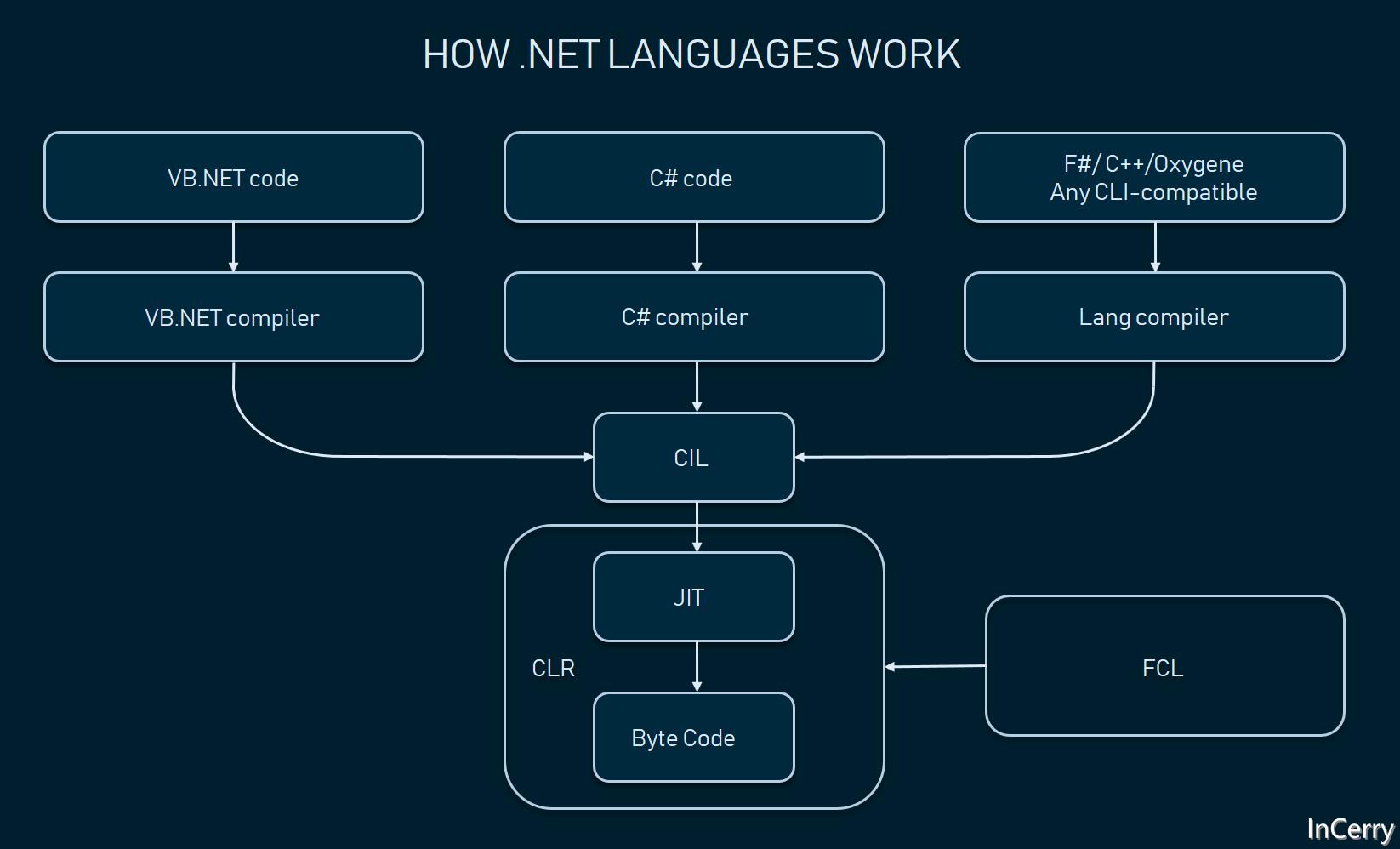
第一次是使用编译器将 C#/F#/VB/Python/PHP 源码使用 Roslyn 等对应语言编译器编译成 CIL(Common Intermediate Language,公共中间语言)。第二次使用 RuyJit 编译器将 CIL 编译为对应平台的机器码,以 C# 语言举了个例子,如下图所示:
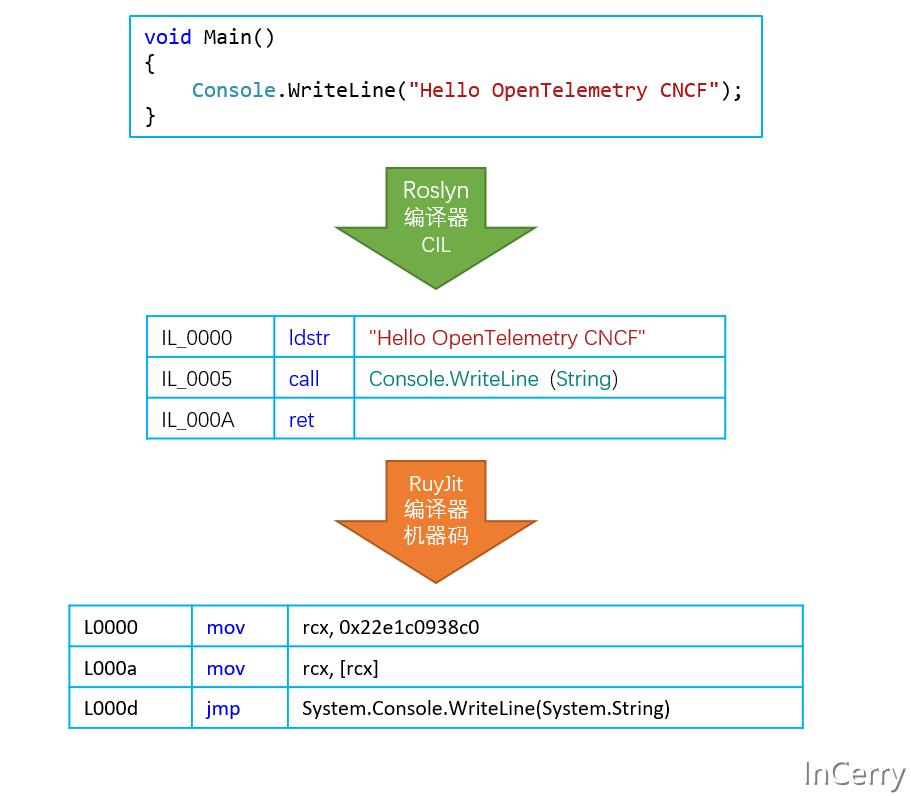
方法注入也一般是发生在这两次编译前后,一个是在 Roslyn 静态编译期间进行方法注入,期间目标 .NET 程序并没有运行,所以这种 .NET 程序未运行的方法注入我们叫它编译时静态注入。而在 RuyJit 期间 .NET程序已经在运行,这时进行方法注入我们叫它运行时动态注入。下表中列出了比较常见方法注入方式:
| 框架 | 类型 | 实现原理 | 优点 | 缺点 |
|---|---|---|---|---|
| metalama | 静态注入 | 重写Roslyn编译器,运行时插入代码 | 源码修改难度低,兼容性好 | 目前该框架不开源,只能修改源码,不能修改已编译好的代码,会增加编译耗时 |
| Mono.Cecil、Postsharp | 静态注入 | 加载编译后的*.dll文件,修改和替换生成后的CIL代码 |
兼容性好 | 使用难度高,需要熟悉 CIL ,会增加编译耗时,会增加程序体积 |
| Harmony | 动态注入 | 创建一个方法签名与原方法一致的方法,修改Jit后原方法汇编,插入jmp跳转到重写后方法 | 高性能,使用难度低 | 泛型、分层编译支持不友好 |
| CLR Profile API | 动态注入 | 调用CLR接口重写方法IL代码 | 功能强大,公开的API支持 | 实现困难,需要熟悉 CIL ,稍有不慎导致程序崩溃 |
综合各种优缺点现阶段APM使用最多的是 CLR Profile API 的方式进行方法注入,比如 Azure AppInsights、DataDog、Elastic等.NET探针都是使用这种方式。
基于CLR Profile API 实现APM探针原理
CLR Profile API 简介
在下面的章节中和大家聊一聊基于 CLR Profile API 是如何实现方法注入,以及 CLR Profile API 是如何使用的。
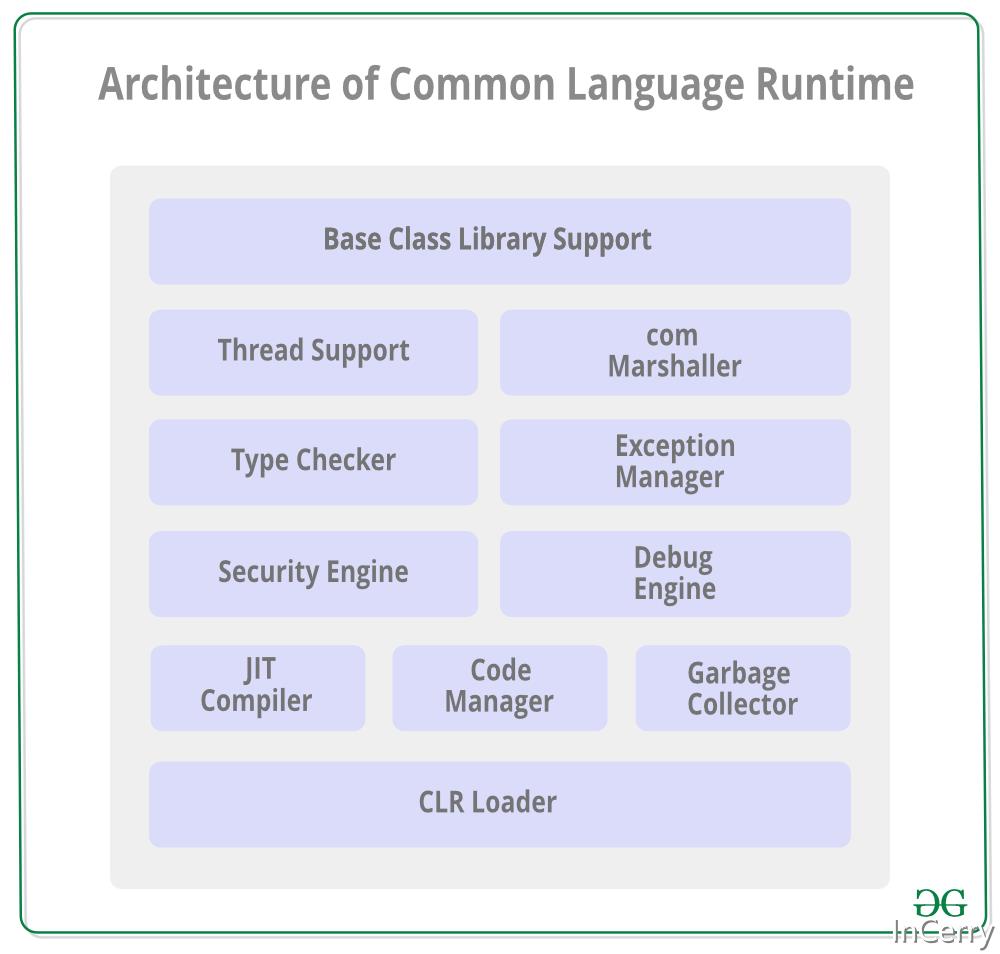
聊到 CLR 探查器,我们首先就得知道 CLR 是什么,CLR(Common Language Runtime,公共语言运行时),可以理解为是托管运行 .NET 程序的平台,它提供了基础类库、线程、JIT 、GC 等语言运行的环境(如下图所示),它功能和 Java 的 JVM 有相似之处,但定位有所不同。
.NET 程序、CLR 和操作系统的关系如下图所示:
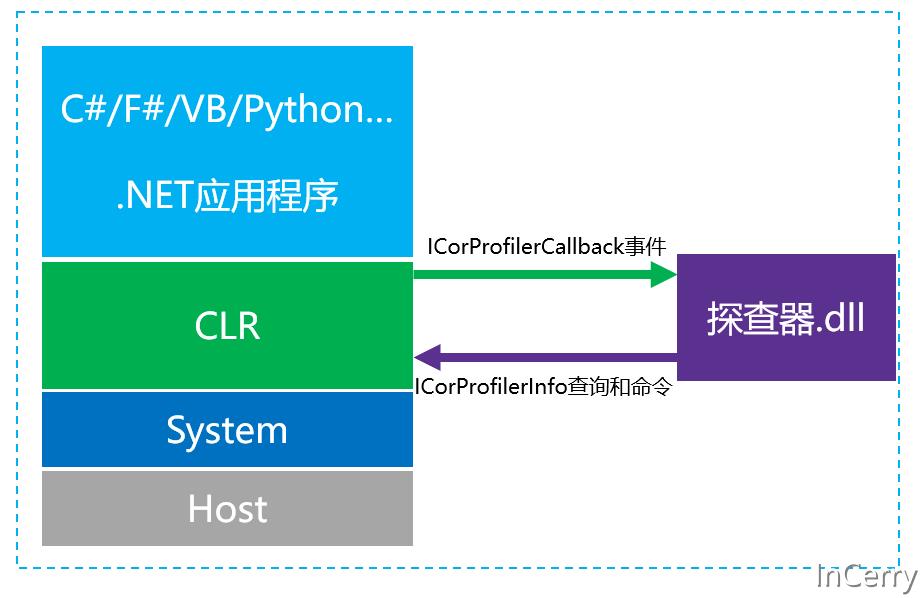
那么 CLR 探查器是什么东西呢?根据官方文档的描述,CLR 探查器和相关API的支持从 .NET Framework 1.0就开始提供,它是一个工具,可以使用它来监视另一个 .NET 应用程序的执行情况,它也是一个( .dll )动态链接库,CLR 在启动运行时加载探查器,CLR 会将一些事件发送给探查器,另外探查器也可以通过 Profile API 向 CLR 发送命令和获取运行时信息。下方是探查器和 CLR 工作的简单交互图:
ICorProfilerCallback提供的事件非常多,常用的主要是下方提到这几类:
- CLR 启动和关闭事件
- 应用程序域创建和关闭事件
- 程序集加载和卸载事件
- 模块加载和卸载事件
- COM vtable 创建和析构事件
- 实时 (JIT) 编译和代码间距调整事件
- 类加载和卸载事件
- 线程创建和析构事件
- 函数入口和退出事件
- 异常
- 托管和非托管代码执行之间的转换
- 不同运行时上下文之间的转换
- 有关运行时挂起的信息
- 有关运行时内存堆和垃圾回收活动的信息
ICorProfilerInfo提供了很多查询和命令的接口,主要是下方提到的这几类:
- 方法信息接口
- 类型信息接口
- 模块信息接口
- 线程信息接口
- CLR 版本信息接口
- Callback 事件设置接口
- 函数 Hook 接口
- 还有 JIT 相关的接口
通过 CLR Profile API 提供的这些事件和信息查询和命令接口,我们就可以使用它来实现一个无需改动原有代码的 .NET 探针。
自动化探针执行过程
APM 使用 .NET Profiler API 对应用程序进行代码插桩方法注入,以监控方法调用和性能指标从而实现自动化探针。下面详细介绍这一过程:
- Profiler注册:在启动应用程序时,.NET Tracer 作为一个分析器(profiler)向 CLR(Common Language Runtime)注册。这样可以让它在整个应用程序生命周期内监听和操纵执行流程。
- JIT编译拦截:当方法被即时编译(JIT)时,Profiler API 发送事件通知。.NET Tracer 捕获这些事件,如JITCompilationStarted,从而有机会在方法被编译之前修改其 IL(Intermediate Language)代码。
- 代码修改插桩:通过操纵IL代码,.NET Tracer 在关键方法的入口和退出点插入跟踪逻辑。这种操作对原始应用程序是透明的,不需要修改源代码。跟踪逻辑通常包括记录方法调用数据、计时、捕获异常等。
- 上下文传播:为了连接跨服务或异步调用的请求链,.NET Tracer 会将 Trace ID 和 Span ID在分布式系统中进行传递。这使得在复杂的微服务架构中追踪请求变得更加容易。
- 数据收集:插桩后的代码在运行期间会产生跟踪数据,包括方法调用时间、执行路径、异常信息等。这些数据会被封装成跟踪和跨度(spans),并且通过 APM Agent 发送到 APM 平台进行后续分析和可视化。
通过使用 .NET Profiler API 对应用程序进行方法注入插桩,APM 可以实现对 .NET 程序的详细性能监控,帮助开发者和运维人员发现并解决潜在问题。
第一步,向 CLR 注册分析器的步骤是很简单的,CLR 要求分析器需要实现COM组件接口标准,微软的 COM(Component Object Model)接口是一种跨编程语言的二进制接口,用于实现在操作系统中不同软件组件之间的通信和互操作。通过 COM 接口,组件可以在运行时动态地创建对象、调用方法和访问属性,实现模块化和封装。COM 接口使得开发人员能够以独立、可复用的方式构建软件应用,同时还有助于降低维护成本和提高开发效率。COM 一般需要实现以下接口:
- 接口(Interfaces):COM 组件使用接口提供一套预定义的函数,这样其他组件就可以调用这些函数。每个接口都有一个唯一的接口标识(IID)。
- 对象(Objects):COM 对象是实现了一个或多个接口的具体实例。客户端代码通过对象暴露的接口与其进行交互。
- 引用计数(Reference Counting):COM 使用引用计数管理对象的生命周期。当一个客户端获取到对象的接口指针时,对象的引用计数加一;当客户端不再需要该接口时,引用计数减一。当引用计数减至零时,COM 对象会被销毁。
- 查询接口(QueryInterface):客户端可以通过 QueryInterface 函数获取 COM 对象所实现的特定接口。这个函数接收一个请求的接口 IID,并返回包含该接口指针的 HRESULT。
- 类工厂(Class Factories):为了创建对象实例,COM 使用类工厂。类工厂是实现了 IClassFactory 接口的对象,允许客户端创建新的对象实例。
比如 OpenTelemetry 中的class_factory.cpp就是声明了COM组件,其中包括了查询接口、引用计数以及创建实例对象等功能。

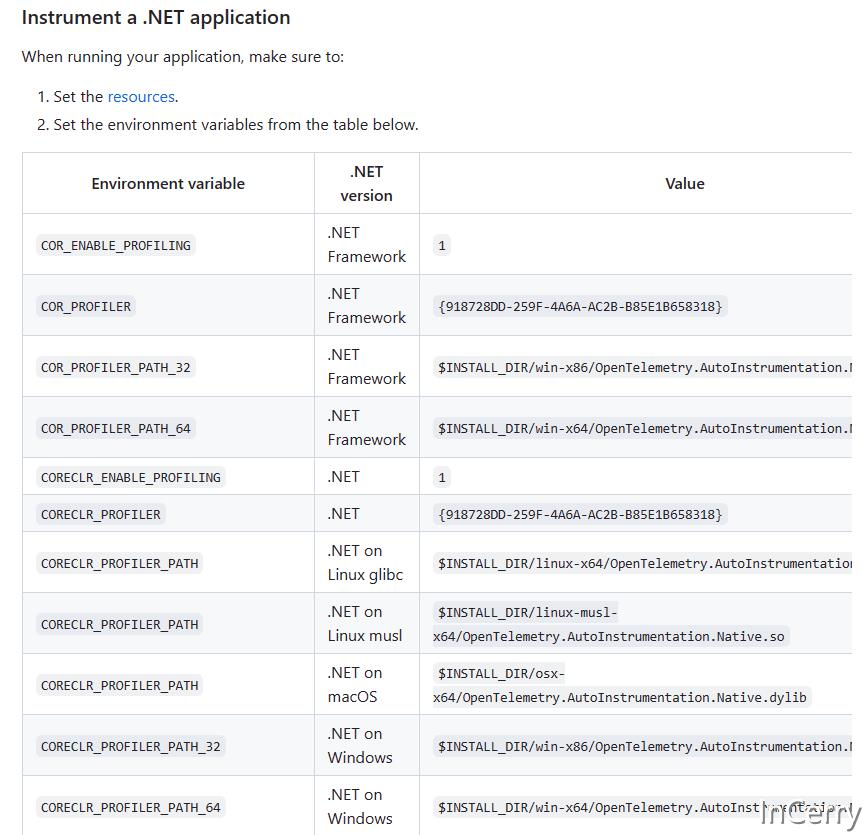
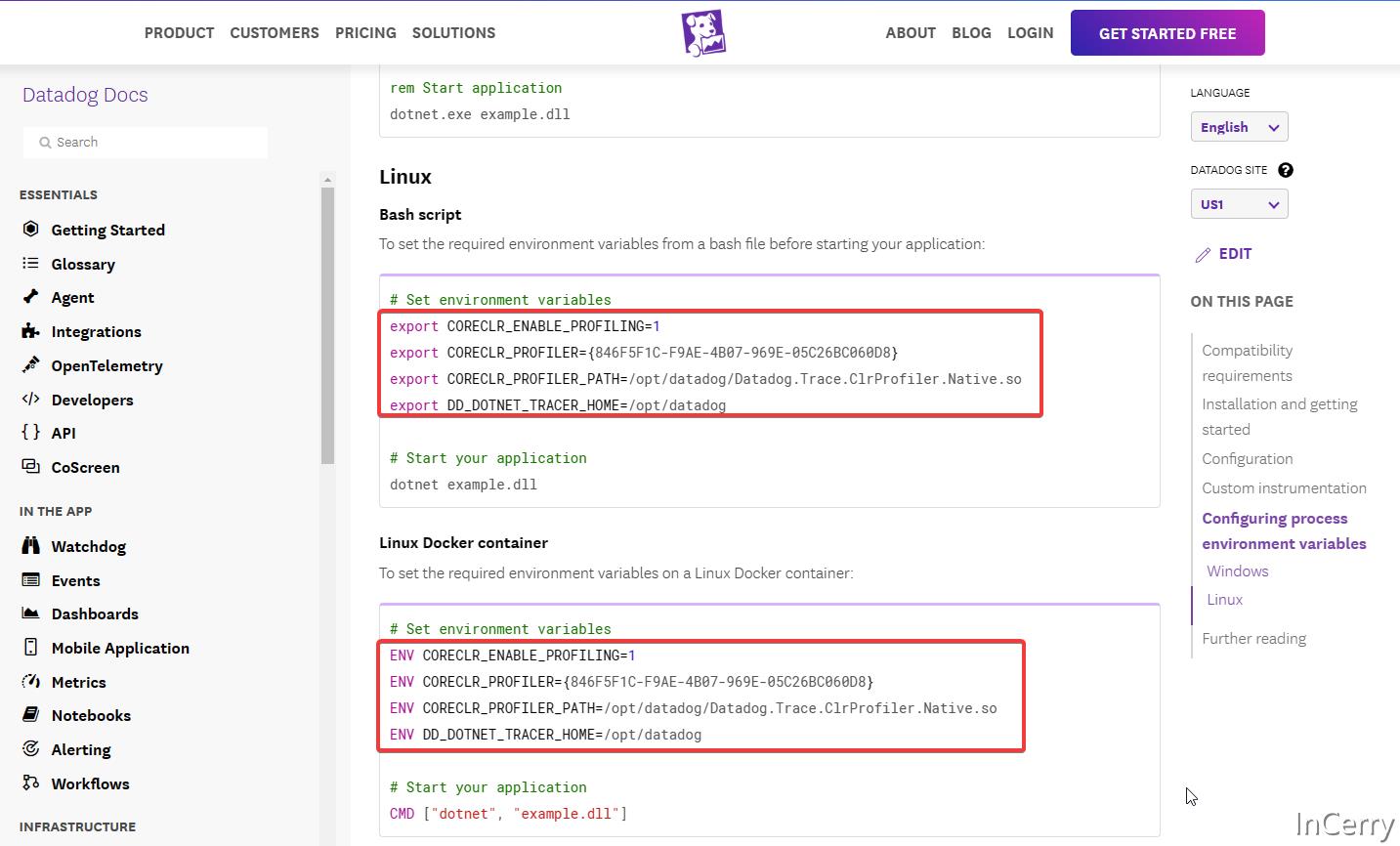
然后我们只需要设置三个环境变量,如下所示:
COR_ENABLE_PROFILING:将其设置为1,表示启用 CLR 分析器。COR_PROFILER: 设置分析器的COM组件ID,使 CLR 能正确的加载分析器。COR_PROFILER_PATH_32/64: 设置分析器的路径,32位或者是64位应用程序。
通过以上设置,CLR 就可以在启动时通过 COM 组件来调用分析器实现的函数,此时也代表着分析器加载完成。在 OpenTelemetry 和 data-dog 等 APM 中都有这样的设置。
那后面的JIT编译拦截以及其它功能如何实现呢?我们举一个现实存在的例子,如果我们需要跟踪每一次 Reids 操作的时间和执行命令的内容,那么我们在应该修改StackExchange.Redis ExecuteAsyncImpl方法,从message中读取执行命令的内容并记录整个方法耗时。

那么APM如何实现对Redis ExecuteAsyncImpl进行注入的?可以打开dd-trace-dotnet仓库也可以打开opentelemetry-dotnet-instrumentation仓库,这两者的方法注入实现原理都是一样的,只是代码实现上有一些细微的差别。这里我们还是以 dd-trace-dotnet 仓库代码为例。
打开tracer/src/Datadog.Trace/ClrProfiler/AutoInstrumentation目录,里面所有的源码都是通过方法注入的方式来实现APM埋点,有非常多的组件埋点的实现,比如 MQ 、Redis 、 CosmosDb 、Couchbase 等等。
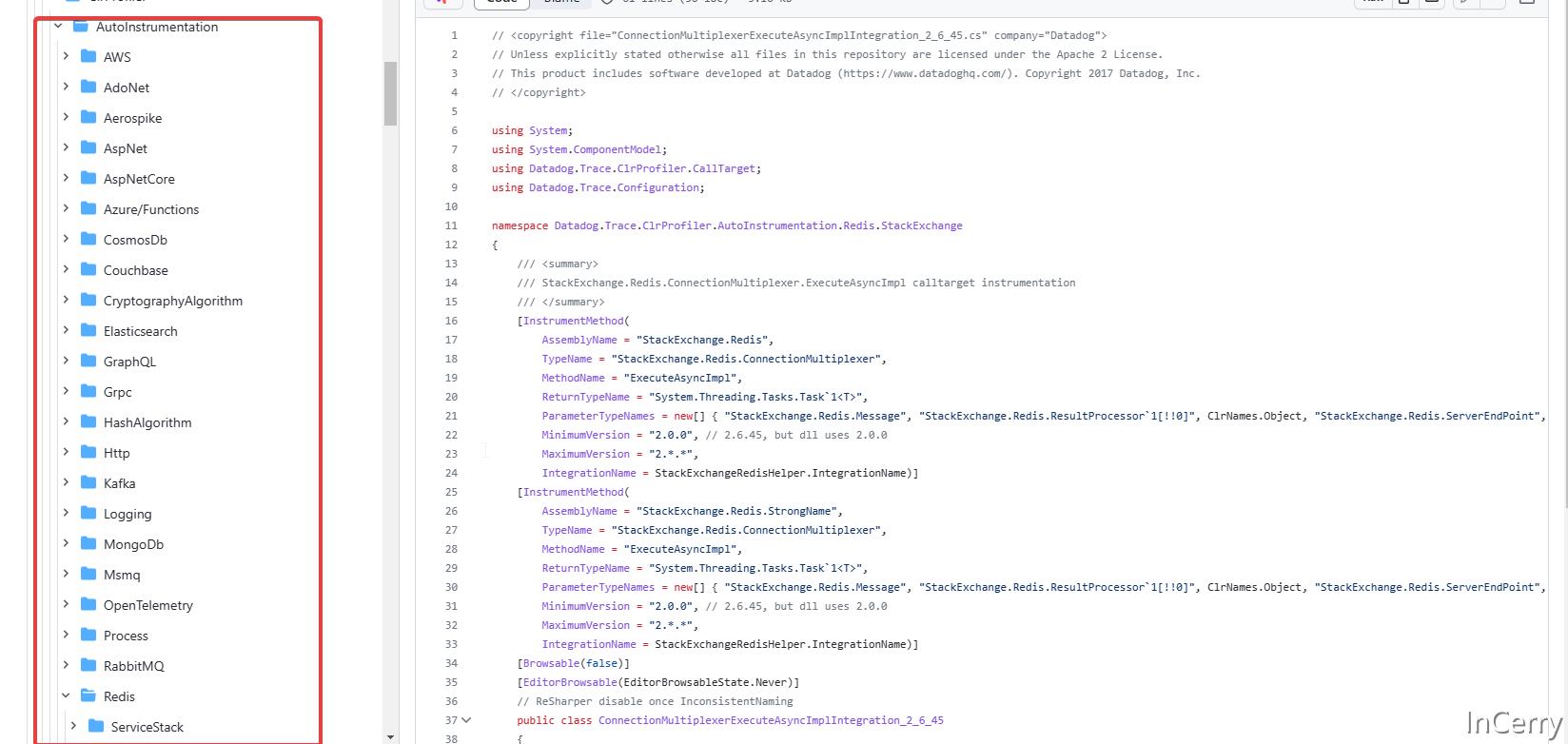
打开 Redis 的文件夹,可以很容易找到 Redis 进行方法注入的源码,这相当于是一个 AOP 切面实现方法:
[InstrumentMethod(
AssemblyName = "StackExchange.Redis",
TypeName = "StackExchange.Redis.ConnectionMultiplexer",
MethodName = "ExecuteAsyncImpl",
ReturnTypeName = "System.Threading.Tasks.Task`1<T>",
ParameterTypeNames = new[] "StackExchange.Redis.Message", "StackExchange.Redis.ResultProcessor`1[!!0]", ClrNames.Object, "StackExchange.Redis.ServerEndPoint" ,
MinimumVersion = "1.0.0",
MaximumVersion = "2.*.*",
IntegrationName = StackExchangeRedisHelper.IntegrationName)]
[InstrumentMethod(
AssemblyName = "StackExchange.Redis.StrongName",
TypeName = "StackExchange.Redis.ConnectionMultiplexer",
MethodName = "ExecuteAsyncImpl",
ReturnTypeName = "System.Threading.Tasks.Task`1<T>",
ParameterTypeNames = new[] "StackExchange.Redis.Message", "StackExchange.Redis.ResultProcessor`1[!!0]", ClrNames.Object, "StackExchange.Redis.ServerEndPoint" ,
MinimumVersion = "1.0.0",
MaximumVersion = "2.*.*",
IntegrationName = StackExchangeRedisHelper.IntegrationName)]
[Browsable(false)]
[EditorBrowsable(EditorBrowsableState.Never)]
public class ConnectionMultiplexerExecuteAsyncImplIntegration
/// <summary>
/// OnMethodBegin callback
/// </summary>
/// <typeparam name="TTarget">Type of the target</typeparam>
/// <typeparam name="TMessage">Type of the message</typeparam>
/// <typeparam name="TProcessor">Type of the result processor</typeparam>
/// <typeparam name="TServerEndPoint">Type of the server end point</typeparam>
/// <param name="instance">Instance value, aka `this` of the instrumented method.</param>
/// <param name="message">Message instance</param>
/// <param name="resultProcessor">Result processor instance</param>
/// <param name="state">State instance</param>
/// <param name="serverEndPoint">Server endpoint instance</param>
/// <returns>Calltarget state value</returns>
internal static CallTargetState OnMethodBegin<TTarget, TMessage, TProcessor, TServerEndPoint>(TTarget instance, TMessage message, TProcessor resultProcessor, object state, TServerEndPoint serverEndPoint)
where TTarget : IConnectionMultiplexer
where TMessage : IMessageData
string rawCommand = message.CommandAndKey ?? "COMMAND";
StackExchangeRedisHelper.HostAndPort hostAndPort = StackExchangeRedisHelper.GetHostAndPort(instance.Configuration);
Scope scope = RedisHelper.CreateScope(Tracer.Instance, StackExchangeRedisHelper.IntegrationId, StackExchangeRedisHelper.IntegrationName, hostAndPort.Host, hostAndPort.Port, rawCommand);
if (scope is not null)
return new CallTargetState(scope);
return CallTargetState.GetDefault();
/// <summary>
/// OnAsyncMethodEnd callback
/// </summary>
/// <typeparam name="TTarget">Type of the target</typeparam>
/// <typeparam name="TResponse">Type of the response, in an async scenario will be T of Task of T</typeparam>
/// <param name="instance">Instance value, aka `this` of the instrumented method.</param>
/// <param name="response">Response instance</param>
/// <param name="exception">Exception instance in case the original code threw an exception.</param>
/// <param name="state">Calltarget state value</param>
/// <returns>A response value, in an async scenario will be T of Task of T</returns>
internal static TResponse OnAsyncMethodEnd<TTarget, TResponse>(TTarget instance, TResponse response, Exception exception, in CallTargetState state)
state.Scope.DisposeWithException(exception);
return response;
这段代码是一个用于监控和跟踪 StackExchange.Redis 库的 APM(应用性能监控)工具集成。它针对 StackExchange.Redis.ConnectionMultiplexer 类的 ExecuteAsyncImpl 方法进行了注入以收集执行过程中的信息。
- 使用了两个
InstrumentMethod属性,分别指定StackExchange.Redis和StackExchange.Redis.StrongName两个程序集。属性包括程序集名称、类型名、方法名、返回类型名等信息以及版本范围和集成名称。 ConnectionMultiplexerExecuteAsyncImplIntegration类定义了OnMethodBegin和OnAsyncMethodEnd方法。这些方法在目标方法开始和结束时被调用。OnMethodBegin方法创建一个新的Tracing Scope,其中包含了与执行的 Redis 命令相关的信息(如hostname,port,command等)。OnAsyncMethodEnd方法在命令执行结束后处理Scope,在此过程中捕获可能的异常,并返回结果。- 而这个
CallTargetState state中其实包含了上下文信息,有 Span Id 和 Trace Id ,就可以将其收集发送到 APM 后端进行处理。
但是,仅仅只有声明了一个 AOP 切面类不够,我们还需将这个 AOP 切面类应用到 Redis SDK 原有的方法中,这又是如何做到的呢?那么我们就需要了解一下 CLR Profiler API 实现方法注入的原理了。
方法注入底层实现原理
在不考虑 AOT 编译和分层编译特性,一个 .NET 方法一开始的目标地址都会指向 JIT 编译器,当方法开始执行时,先调用 JIT 编译器将 CIL 代码转换为本机代码,然后缓存起来,运行本机代码,后面再次访问这个方法时,都会走缓存以后得本机代码,流程如下所示:

拦截JIT编译
由于方法一般情况下只会被编译一次,一种方法注入的方案就是在 JIT 编译前替换掉对应方法的 MethodBody ,这个在 CLR Profile API 中提供的一个关键的回调。
JITCompilationStarted:通知探查器,即时编译器已经开始编译方法。
我们只需要订阅这个事件,就可以在方法编译开始时将对应的 MethodBody 修改成我们想要的样子,在里面进行 AOP 埋点即可。在JITCompilationStarted事件中重写方法IL的流程大致如下:
- 捕获
JITCompilationStarted事件:当一个方法被即时编译(JIT)时,CLR(Common Language Runtime)会触发JITCompilationStarted事件。通过使用 Profiler API ,分析器可以订阅这个事件并得到一个回调。 - 确定要修改的方法:在收到
JITCompilationStarted事件回调时,分析器需要检查目标方法元数据,例如方法名称、参数类型和返回值类型等,来确定是否需要对该方法进行修改。 - 获取方法的原始 IL 代码:如果确定要对目标方法进行修改,分析器需要首先获取该方法的原始 IL 代码。这可以通过使用Profiler API 提供的
GetILFunctionBody方法来实现。 - 分析和修改 IL 代码:接下来,分析器需要解析原始 IL 代码,找到适当的位置以插入新的跟踪逻辑。这通常包括方法的入口点(开始执行时)和退出点(返回或抛出异常)。分析器会生成一段新的 IL 代码,用于记录性能指标、捕获异常等。
- 替换方法的 IL 代码:将新生成的 IL 代码插入到原始 IL 代码中,并使用
SetILFunctionBody方法替换目标方法的IL代码。这样,在方法被JIT编译成本地代码时,新的跟踪逻辑也会被包含进去。 - 继续JIT编译:完成IL代码重写后,分析器需要通知CLR继续JIT编译过程。编译后的本地代码将包含插入的跟踪逻辑,并在应用程序运行期间执行。
我们来看看源码是如何实现的,打开 dd-trace-dotnet 开源仓库,回退到较早的发布版本,有一个 integrations.json 文件,在 dd-trace-dotnet 编译时会自动生成这个文件,当然也可以手动维护,在这个文件里配置了需要 AOP 切面的程序集名称、类和方法,在分析器启动时,就会加载 json 配置,告诉分析器应该注入那些方法。
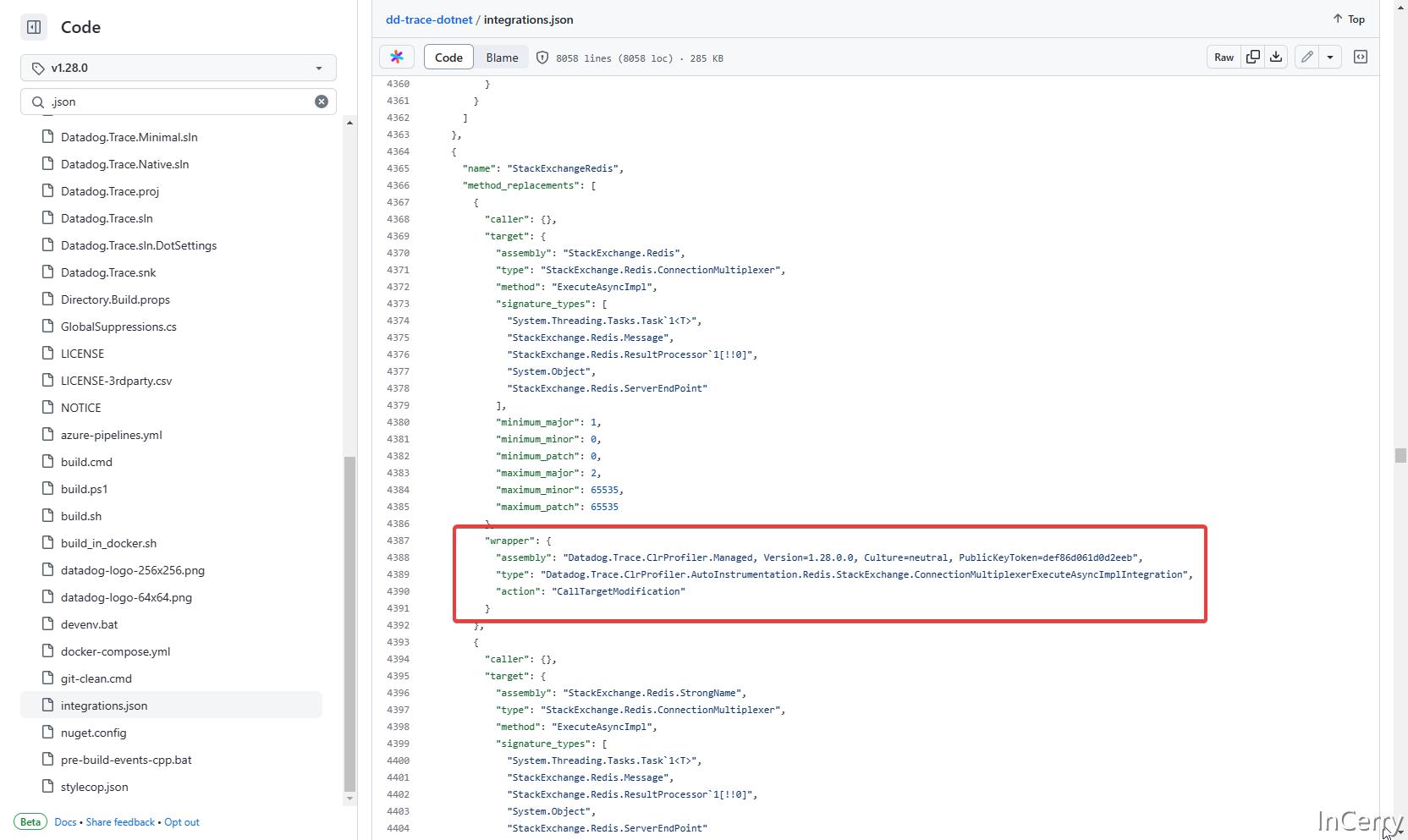
接下来,我们找到cor_profiler.cpp文件并打开,这是实现 CLR 事件回调的代码,转到关于JITCompilationStarted事件的通知的处理的源码。
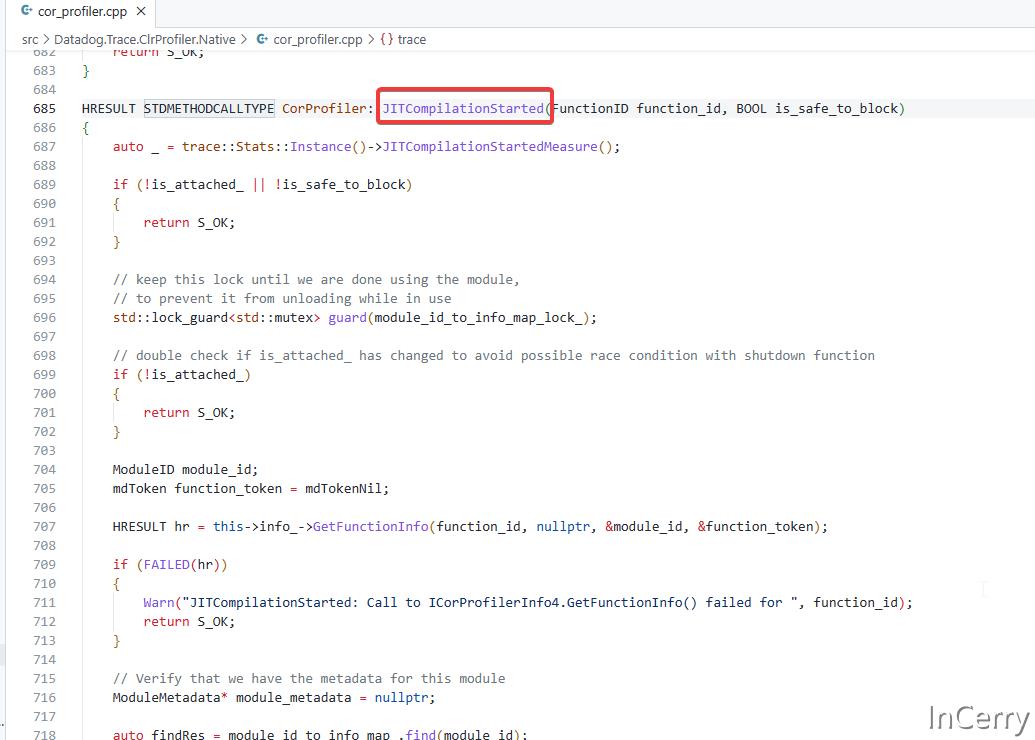
由于代码较长,简单的说一下这个函数它做了什么,函数主要用于在 .NET JIT(Just-In-Time)编译过程中执行一系列操作,例如插入启动钩子、修改 IL(中间语言)代码以及替换方法等,以下是它的功能:
- 函数检查
is_attached_和is_safe_to_block变量,如果不满足条件,则直接返回。 - 使用互斥锁保护模块信息,防止在使用过程中卸载模块。
- 通过给定的
function_id获取模块 ID 和函数 token。 - 根据模块 ID 查找模块元数据。
- 检查是否已在
CallTarget模式下注入加载器。 - 如果符合条件且加载器尚未注入,则在
AppDomain中的第一个 JIT 编译方法中插入启动钩子。在最低程度上,必须添加AssemblyResolve事件,以便从磁盘找到Datadog.Trace.ClrProfiler.Managed.dll及其依赖项,因为它不再被提供为 NuGet 包。 - 在桌面版 IIS 环境下,调用
AddIISPreStartInitFlags()方法来设置预启动初始化标志。 - 如果未启用
CallTarget模式,将对integrations.json配置的方法进行插入和替换,并处理插入和替换调用。 - 返回
S_OK表示成功完成操作。
其中有两个关键函数,可以对 .NET 方法进行插入和替换,分别是ProcessInsertionCalls和ProcessReplacementCalls。
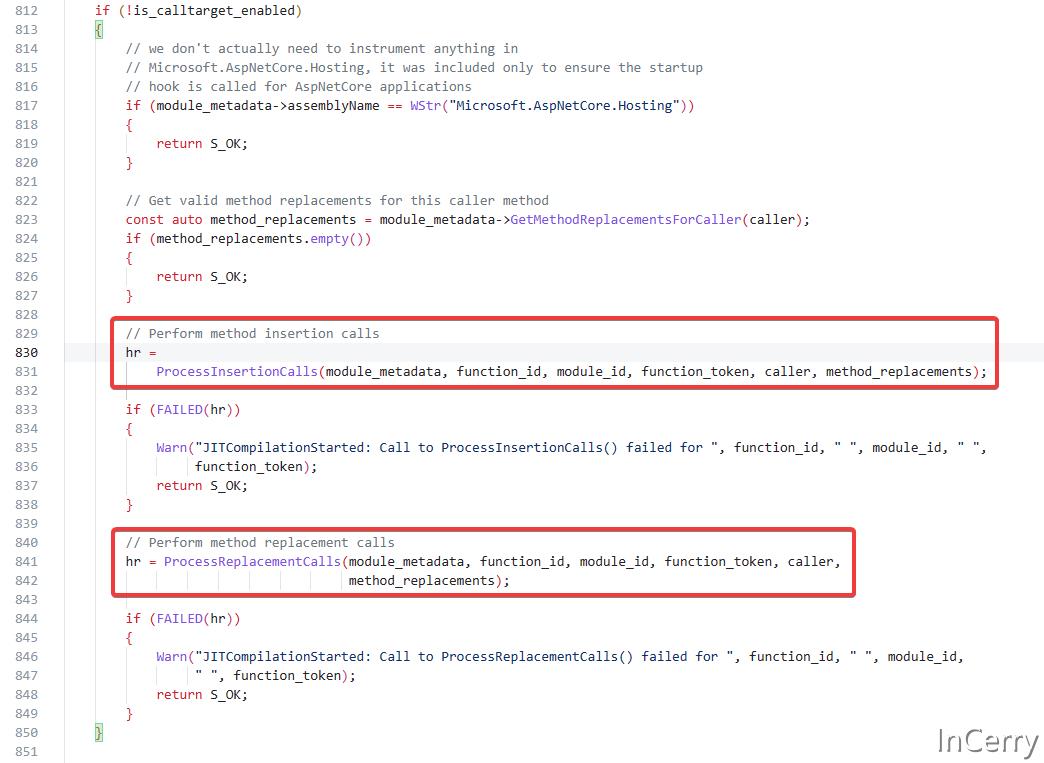
其中ProcessInsertionCalls用于那些只需要在方法前部插入埋点的场景,假设我们有以下原始 C# 类:
public class TargetClass
public void TargetMethod()
Console.WriteLine("This is the original method.");
现在,我们希望在TargetMethod的开头插入一个新的方法调用。让我们创建一个示例方法,并在WrapperClass中定义它:
修改后,插入InsertedMethod调用的TargetMethod将如下所示:
public class TargetClass
public void TargetMethod()
WrapperClass.InsertedMethod(); // 这是新插入的方法调用
Console.WriteLine("This is the original method.");
public class WrapperClass
public static void InsertedMethod()
Console.WriteLine("This is the inserted method.");
请注意,上述示例是为了解释目的而手动修改的,实际上这种修改是通过操作IL代码来完成的。在CorProfiler::ProcessInsertionCalls方法中,这些更改是在IL指令级别上进行的,不会直接影响源代码。
修改方法的 IL 代码.NET官方提供了一个帮助类 ILRewriter ,ILRewriter 是一个用于操作C#程序中方法的中间语言(Intermediate Language,IL)代码的工具类。它会将方法的IL代码以链表的形式组织,让我们可以方便的修改IL代码,它通常用于以下场景:
- 代码注入:在方法体中插入、删除或修改 IL 指令。
- 代码优化:优化 IL 代码以提高性能。
- 执行 AOP(面向切面编程):通过动态操纵字节码实现横切关注点(如日志记录、性能度量等)。
ILRewriter 类提供了一系列方法用于读取、修改和写回IL指令序列。例如,在上述CorProfiler::ProcessInsertionCalls方法中,我们使用 ILRewriter 对象导入IL代码,执行所需的更改(如插入新方法调用),然后将修改后的 IL 代码导出并应用到目标方法上。这样可以实现对程序行为的运行时修改,而无需直接更改源代码。
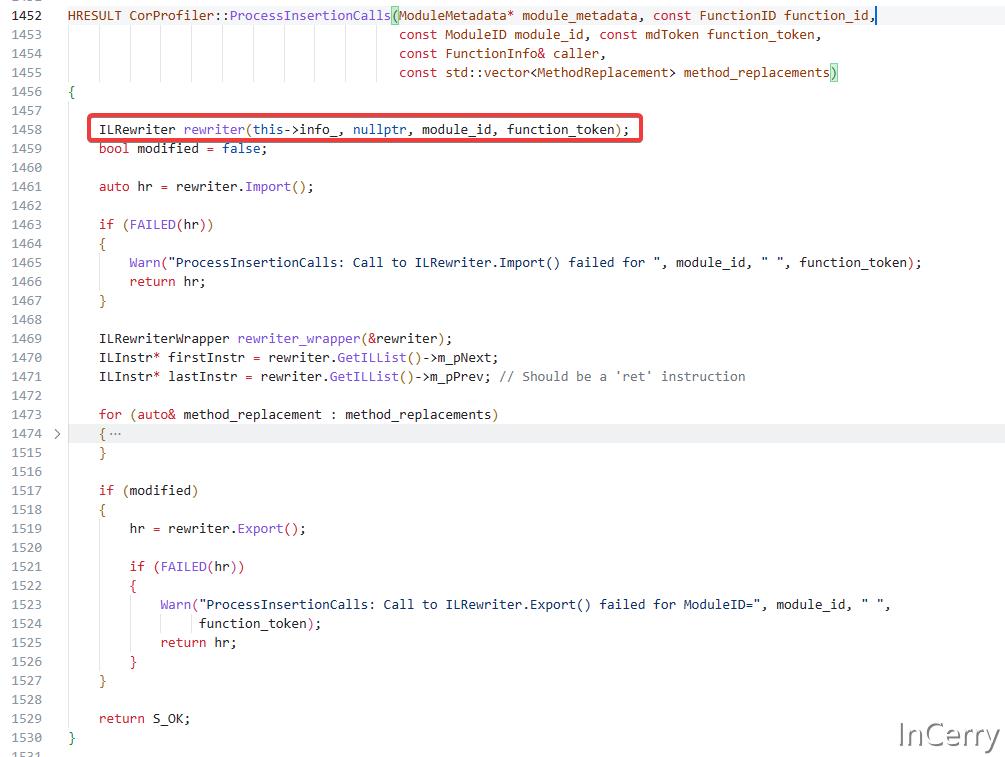
另一个ProcessReplacementCalls方法就是将原有的方法调用实现一个 Proxy ,适用于那些需要捕获异常获取方法返回值的场景,这块代码比较复杂,假设我们有以下 C# 代码,其中我们想要替换OriginalMethod()的调用:
public class TargetClass
public int OriginalMethod(int a, int b)
return a * b;
public class CallerClass
public void CallerMethod()
TargetClass target = new TargetClass();
int result = target.OriginalMethod(3, 4);
Console.WriteLine(result);
在应用方法调用替换后,CallerMethod()将调用自定义的替换方法WrapperMethod()而不是OriginalMethod()。例如,我们可以使用以下替换方法:
public class WrapperClass
public static int WrapperMethod(TargetClass instance, int opCode, int mdToken, long moduleVersionId, int a, int b)
Console.WriteLine("Method call replaced.");
return instance.OriginalMethod(a, b);
经过IL修改后,CallerMethod()看起来大致如下:
public void CallerMethod()
TargetClass target = new TargetClass();
int opCode = /* Original CALL or CALLVIRT OpCode */;
int mdToken = /* Metadata token for OriginalMethod */;
long moduleVersionId = /* Module version ID pointer */;
// Call the wrapper method instead of the original method
int result = WrapperClass.WrapperMethod(target, opCode, mdToken, moduleVersionId, 3, 4);
Console.WriteLine(result);
现在CallerMethod()将调用WrapperMethod(),在这个例子中,我们记录了一条替换消息,然后继续调用OriginalMethod()。
正如所述,通过捕获JITCompilationStarted事件并对中间语言(IL)进行改写,我们修改方法行为的基本原理。在 .NET Framework 4.5 之前的版本中,这种方式广泛应用于方法改写和植入埋点,从而实现 APM 的自动化探针。然而,此方法也存在以下一些不足之处:
- 不支持动态更新:
JITCompilationStarted在方法被 JIT 编译之前触发,这意味着它只能在初次编译过程中修改 IL。 - 更大的性能影响:由于
JITCompilationStarted是一个全局事件,它会在每个需要 JIT 编译的方法被调用时触发。因此,如果在此事件中进行 IL 修改,可能会对整个应用程序产生更大的性能影响。 - 无法控制执行时机:在
JITCompilationStarted中重写 IL 时,您不能精确控制何时对某个方法应用更改。 - 某些情况下,运行时可能选择跳过JIT编译过程,例如对于 NGEN(Native Image Generator,俗称AOT编译)生成的本地映像,此时无法捕获到
JITCompilationStarted事件。 - 在多线程环境下,可能会出现竞争条件,导致一些方法执行的是未更新的代码。
但是我们也无法再其它时间进行重写,因为JIT一般情况下只会编译一次,JIT 已经完成编译以后修改方法 IL 不会再次 JIT ,修改也不会生效。在 .NET Framework 4.5 诞生之前,我们并未拥有更为优美的途径来实现 APM 自动化探测。然而,随着 .NET Framework 4.5 的降临,一条全新的路径终于展现在我们面前。
重新JIT编译
上文中提到了捕获JITCompilationStarted事件时进行方法重写的种种缺点,于是在.NET 4.5中,新增了一个名为RequestReJIT的方法,它允许运行时动态地重新编译方法。RequestReJIT主要用于性能分析和诊断工具,在程序运行过程中,可以为指定的方法替换新的即时编译(JIT)代码,以便优化性能或修复bug。
RequestReJIT提供了一种强大的机制,使开发人员能够在不重启应用程序的情况下热更新代码逻辑。这在分析、监视及优化应用程序性能方面非常有用。它可以在程序运行时动态地替换指定方法的 JIT 代码,而无需关心方法是否已经被编译过。RequestReJIT减轻了多线程环境下的竞争风险,并且可以处理 NGEN 映像中的方法。通过提供这个强大的机制,RequestReJIT使得性能分析和诊断工具能够更有效地优化应用程序性能及修复bug。
使用RequestReJIT重写方法IL的流程如下:
- Profiler 初始化:当.NET应用程序启动时,分析器(profiler)会利用Profiler API向CLR(Common Language Runtime)注册。这允许分析器在整个应用程序生命周期内监听和操纵代码执行流程。
- 确定要修改的方法:分析器需要识别哪些方法需要进行修改。这通常是通过分析方法元数据(如方法名称、参数类型和返回值类型等)来判断的。
- 为目标方法替换 IL 代码:首先,分析器获取目标方法的原始 IL 代码,并在适当位置插入新的跟踪逻辑。接着,使用 SetILFunctionBody 方法将修改后的 IL 代码设置为目标方法的新 IL 代码。
- 请求重新 JIT 编译:使用
RequestReJIT方法通知 CLR 重新编译目标方法。此时,CLR 会触发ReJITCompilationStarted事件。 - 捕获
ReJITCompilationStarted事件:分析器订阅ReJITCompilationStarted事件,在事件回调中获取到修改后的 IL 代码,订阅结束事件,分析器可以获取本次重新编译是否成功。 - 生成新的本地代码:CLR 会根据修改后的 IL 代码重新进行 JIT 编译,生成新的本地代码。这样,新的 JIT 代码便包含了插入的跟踪逻辑。
- 执行新的本地代码:之后,当目标方法被调用时,将执行新生成的本地代码。这意味着插入的跟踪逻辑会在应用程序运行期间起作用,从而收集性能数据和诊断信息。
有了RequestJIT方法,我们可以在任何时间修改方法 IL 然后进行重新编译,无需拦截JIT执行事件,在新版的 dd-trace 触发方法注入放到了托管代码中,托管的 C# 代码直接调用非托管的分析器 C++ 代码进行方法注入,所以不需要单独在 json 文件中配置。
取而代之的是InstrumentationDefinitions.g.cs文件,在编译时会扫描所有标记了InstrumentMethod特性的方法,然后自动生成这个类。

当分析器启动时,会调用Instrumentation.cs类中Initialize()方法,在这个方法内部就会和分析器通讯,将需要进行方法注入的方法传递给分析器。

因为需要和分析器进行通讯,所以需要在分析器中导出可供 C# 代码调用的函数,源码中是interop.cpp导出了 C# 和 C++ 代码互操作的几个函数,同样在 C# 中也要使用P/Invoke技术来定义一个调用类。
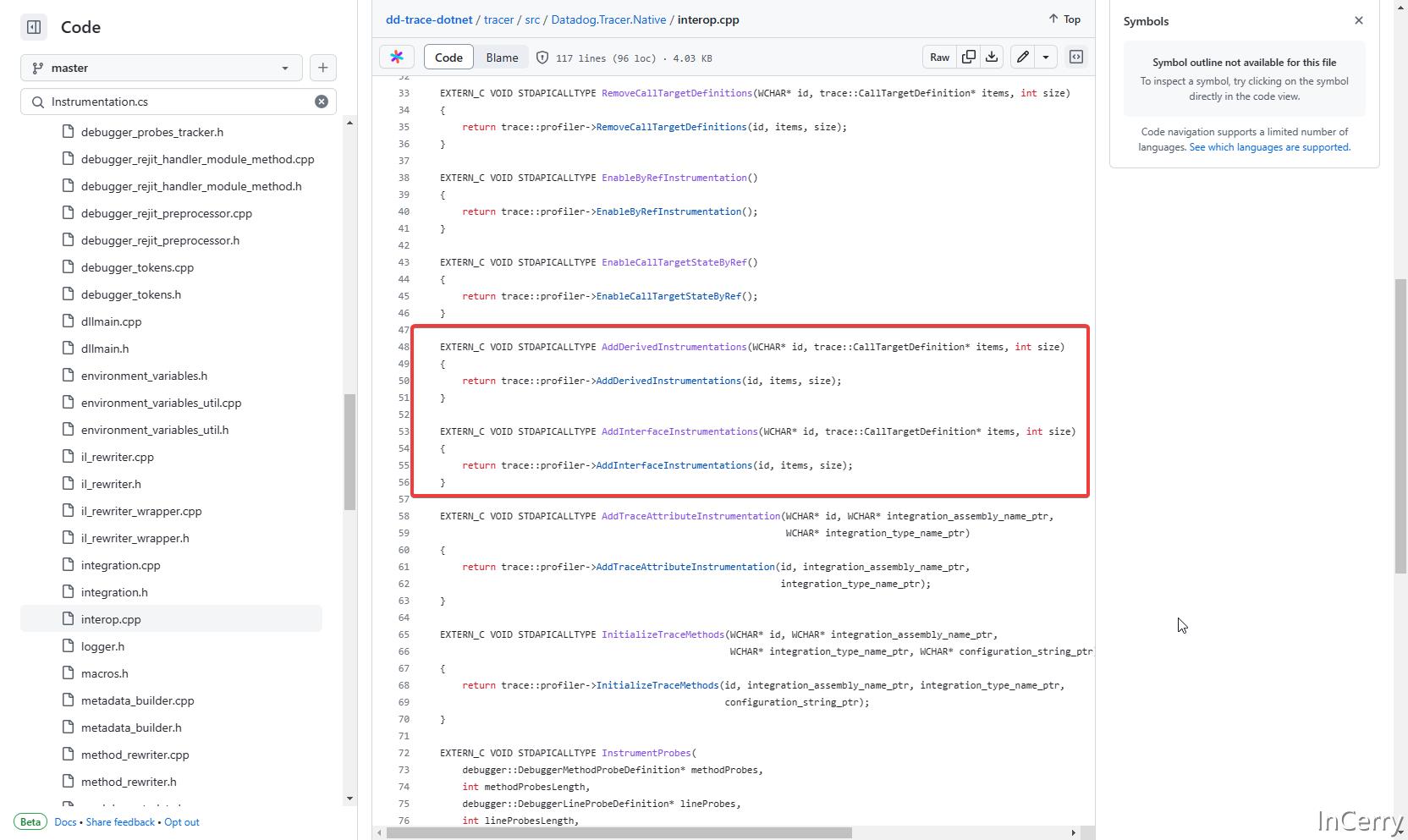

分析器接受到需要注入的方法信息以后,会将其加入到方法注入的队列中,然后会重写对应方法至下方这种形式:
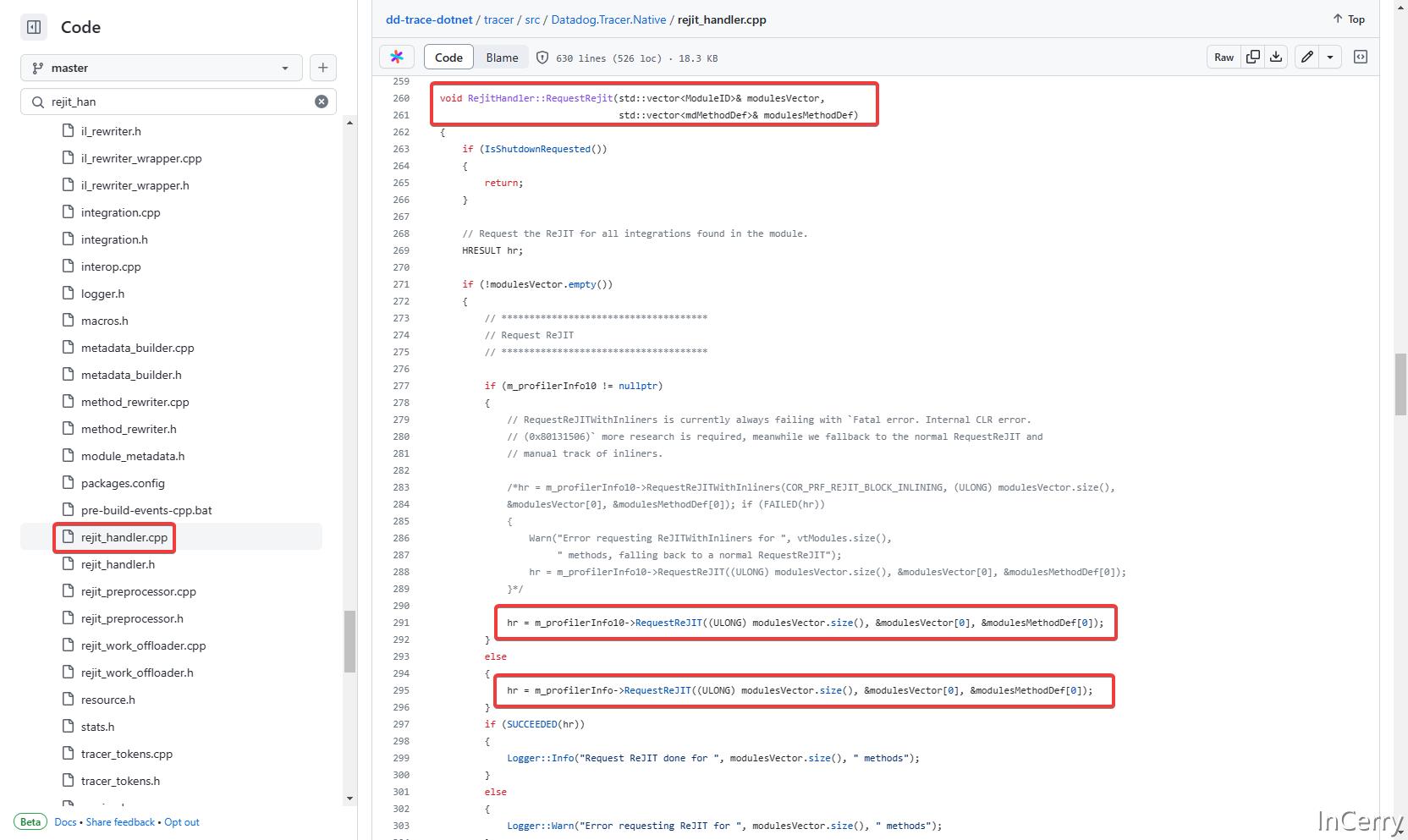
/// <摘要>
/// 用calltarget实现重写目标方法体。(这个函数是由ReJIT处理程序触发的)生成的代码结构:
///
/// - 为 TReturn(如果非 void 方法)、CallTargetState、CallTargetReturn/CallTargetReturn<TReturn> 和 Exception 添加局部变量
/// - 初始化局部变量
try
try
try
- 使用对象实例(对于静态方法则为 null)和原始方法参数调用 BeginMethod
- 将结果存储到 CallTargetState 局部变量中
catch 当异常不是 Datadog.Trace.ClrProfiler.CallTarget.CallTargetBubbleUpException 时
- 调用 LogException(Exception)
- 执行原始方法指令
* 所有RET指令都替换为 LEAVE_S。对于非void方法,堆栈上的值首先存储在 TReturn 局部变量中。
catch (Exception)
- 将异常存储到 Exception 局部变量中
- 抛出异常
finally
try
- 使用对象实例(对于静态方法则为null),TReturn局部变量(如果非 void 方法),CallTargetState局部变量和 Exception 局部变量调用 EndMethod
- 将结果存储到 CallTargetReturn/CallTargetReturn<TReturn> 局部变量中
- 如果是非void方法,将 CallTargetReturn<TReturn>.GetReturnValue() 存储到 TReturn 局部变量中
catch 当异常不是 Datadog.Trace.ClrProfiler.CallTarget.CallTargetBubbleUpException 时
- 调用 LogException(Exception)
- 如果非 void 方法,则加载 TReturn 局部变量
- RET
最后请求RequestReJIT来重新编译进行 JIT 编译,完成了整个方法的注入。
总结
以上就是目前 .NET 上 APM 主流的无侵入自动化探针的实现原理的简单科普,总体实现是很复杂的,里面还有诸多细节在本文中并未提到。然而,通过了解这些基本概念和技术原理,希望能为您提供一个较为清晰的认识,让您更好地理解 APM 无侵入式探针是如何在 .NET 平台工作的。
如果大家对此话题有兴趣,并希望建立更深入、全面的了解,那么后续可以更新下一篇文章,在接下来的内容中,我们可以实现一个简单版本的 .NET 无侵入探针,并将深入探讨相关实现细节以及如何在实际场景中应用这些方法。
参考文献
作者介绍
InCerry,微软最有价值专家,现就职于同程旅行
.NET性能优化交流群
相信大家在开发中经常会遇到一些性能问题,苦于没有有效的工具去发现性能瓶颈,或者是发现瓶颈以后不知道该如何优化。之前一直有读者朋友询问有没有技术交流群,但是由于各种原因一直都没创建,现在很高兴的在这里宣布,我创建了一个专门交流.NET性能优化经验的群组,主题包括但不限于:
- 如何找到.NET性能瓶颈,如使用APM、dotnet tools等工具
- .NET框架底层原理的实现,如垃圾回收器、JIT等等
- 如何编写高性能的.NET代码,哪些地方存在性能陷阱
希望能有更多志同道合朋友加入,分享一些工作中遇到的.NET性能问题和宝贵的性能分析优化经验。目前一群已满,现在开放二群。
如果提示已经达到200人,可以加我微信,我拉你进群: ls1075
另外也创建了QQ群,群号: 687779078,欢迎大家加入。
深入学习JVM探针与字节码技术
JVM探针是自jdk1.5以来,由虚拟机提供的一套监控类加载器和符合虚拟机规范的代理接口,结合字节码指令能够让开发者实现无侵入的监控功能。如:监控生产环境中的函数调用情况或动态增加日志输出等等。虽然在常规的业务中不会有太多用武之地,但是作为一项高级的技术手段也应该是资深开发人员的必备技能之一。同时,它也是企业级开发和生产环境部署不可或缺的技术方案,是对当下流行的APM的一种补充,因为使用探针技术能够实现比常规APM平台更细粒度的监控。
哪些方面适合使用探针技术:
-
(1) 如果你发现生产环境上有些问题无法在测试或开发环境中复现
-
(2) 如果你希望在不修改源码的情况下为你的应用添加一些输出日志
-
(3) 如果在刚发布的生产包中发现了一个bug,而你又不希望被它阻断,希望有一个临时的补救措施
一、JVM探针:Instrumentation
使用探针只需要一条附加选项:-javaagent:<jar 路径>[=<选项>],作为探针(代理)的jar包必须满足两个条件:1. MANIFEST.MF文件需要增加Premain-Class项,说明启动类。2. 启动类必须声明一个静态函数,它的入参是: String和Instrumentation。因此,一个常见的启动类可能像这样:
package aa.bb.cc;
public class PremainAgent
public static void premain(String agentArgs, Instrumentation inst)
// TODO
MANIFEST.MF
premain-class: aa.bb.cc.PremainAgent
如果使用maven作为构建工具,需要在pom文件中添加构建插件
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<archive>
<manifestEntries>
<premain-class>aa.bb.cc.PremainAgent</premain-class>
</manifestEntries>
</archive>
</configuration>
</plugin>
如果你还引入了其它依赖希望同时打包,那么你应该使用assembly插件替代
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifestEntries>
<Premain-Class><package>.PremainAgent</Premain-Class>
<Can-Redefine-Classes>true</Can-Redefine-Classes>
<Can-Retransform-Classes>true</Can-Retransform-Classes>
</manifestEntries>
</archive>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions></plugin>
两个重要的类
Instrumentation: 由JDK提供的一个探针类,它会负责加载用户自定义的ClassFileTransformer
ClassFileTransformer: 字节码转换类,jvm在加载class文件前会先调用它,对所有类加载器有效
具体用法稍后会做详细介绍。
总结:JVM探针只是提供了一种让开发人员能够在类加载加载class文件前主动介入的一种方法,具体如何操作需要开发人员了解Java虚拟机规范以及字节码的相关知识。
二、栈帧与指令集
栈帧(Stack Frame)是用于支持虚拟机进行方法调用和方法执行的数据结构。它是虚拟机运行时数据区中的虚拟机栈的栈元素。栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。每一个方法从调用开始至执行完成的过程,都对应着一个栈帧在虚拟机里面从入栈到出栈的过程。
在编译程序代码的时候,栈帧中需要多大的局部变量表,多深的操作数栈都已经完全确定了。因此一个栈帧需要分配多少内存,不会受到程序运行期变量数据的影响,而仅仅取决于具体的虚拟机实现。
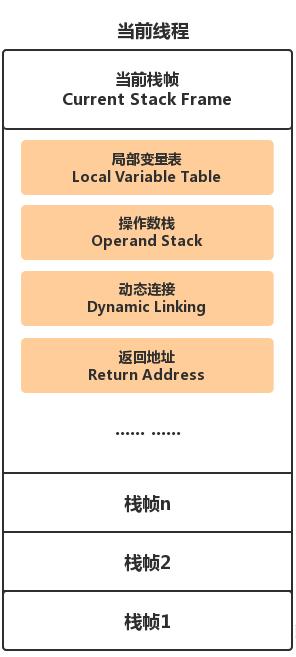
局部变量表(Local Variable Table)是一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量。并且在Java编译为Class文件时,就已经确定了该方法所需要分配的局部变量表的最大容量。局部变量表类似一个数组结构,虚拟机在访问局部变量表的时候会使用下标作为引用,普通方法的局部变量表中第0位索引默认是用于传递方法所属对象实例的引用this。
操作数栈(Operand Stack)和局部变量表一样,在编译时期就已经确定了该方法所需要分配的局部变量表的最大容量。当一个方法刚刚开始执行的时候,这个方法的操作数栈是空的,在方法执行的过程中,会有各种字节码指令往操作数栈中写入和提取内容,也就是出栈/入栈操作。例如,在做算术运算的时候是通过操作数栈来进行的,又或者在调用其它方法的时候是通过操作数栈来进行参数传递的。
动态链接(Dynamic Linking)每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支付方法调用过程中的动态连接。在类加载阶段中的解析阶段会将符号引用转为直接引用,这种转化也称为静态解析。另外的一部分将在每一次运行时期转化为直接引用,这部分称为动态连接。
返回地址:当一个方法开始执行后,只有2种方式可以退出这个方法,方法返回指令和异常退出。无论采用任何退出方式,在方法退出之后,都需要返回到方法被调用的位置,程序才能继续执行,方法返回时可能需要在栈帧中保存一些信息。一般来说,方法正常退出时,调用者的PC计数器的值可以作为返回地址,栈帧中会保存这个计数器值。而方法异常退出时,返回地址是要通过异常处理器表来确定的,栈帧中一般不会保存这部分信息。
JVM指令集并非是对Java语句的直接翻译,由于指令只使用1个字节表示,所以指令集最多只能包含256种指令。因此,一条Java语句一般会对应多条底层指令。每一条指令都有与之对应的助记符,我们可以通过官方资料查看它们对应关系:https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-6.html。为了帮助大家更加直观的理解字节码指令,我将通过三个用例分别解释。
从一个简单的加法函数开始,我们可以使用javac将.java文件编译成.class,再通过javap -c查看它的字节码文件
public int add(int x, int y)
return x + y;
public add(II)I
ILOAD 1 // 将局部变量表中#1变量入栈
ILOAD 2 // 将局部变量表中#2变量入栈
IADD // 调用整型数相加(两个数出栈,再将结果入栈)
IRETURN // 返回栈顶的结果
MAXSTACK = 2 // 最大栈数2
MAXLOCALS = 3 // 最大本地变量数3
第一行是它的函数签名,2~7行的注释分别是对指令的解释。ILOAD,IADD,IRETURN分别是整型数的入栈,加法和返回操作。大家可以将add方法修改为静态函数后重新编译,看看MAXLOCALS是否有变化。
接下来我们把函数变得复杂一些,尝试对函数的执行时间做一个计算并输出
public int add(int x, int y)
long t = System.nanoTime();
int ret = x + y;
t = System.nanoTime() - t;
System.out.println(t);
return ret;
public add(II)I
INVOKESTATIC java/lang/System.nanoTime ()J // 调用静态函数,结果long入栈
LSTORE 3 // 将栈顶的long保存到局部变量#3
ILOAD 1
ILOAD 2
IADD
ISTORE 5 // 将栈顶的int保存到局部变量#5
INVOKESTATIC java/lang/System.nanoTime ()J
LLOAD 3 // 局部变量#3入栈
LSUB // 从栈顶弹出两个long相减
LSTORE 3 // 结果保存到变量#3
GETSTATIC java/lang/System.out : Ljava/io/PrintStream; // 获取静态引用
LLOAD 3 // 局部变量#3入栈
INVOKEVIRTUAL java/io/PrintStream.println (J)V // 调用函数
ILOAD 5 // 局部变量#5入栈
IRETURN
MAXSTACK = 4
MAXLOCALS = 6
第2行结尾的J表示函数返回值是long类型。第14行结尾的V表示println函数的返回值是void。第12行到第14行的指令对应代码的System.out.println(t),特别需要注意的是INVOKEVIRTUAL指令实际上需要从操作数栈获取两个数,第一个数是在执行了GETSTATIC后入栈的对象引用。
我们再次修改函数,这一次我们引入比较和循环语句,尽管代码的逻辑不太正常,但这并不妨碍我们理解
public int add(int x, int y)
if(x > 1)
return x + y;
for(int i = 0; i < y; i++)
x ++;
return x - y;
public add(II)I
ILOAD 1
ICONST_1 // 将一个常整型数1入栈
IF_ICMPLE L0 // 比较如果操两个操作数是小于等于的关系则成立,否则跳转到L0的位置继续
ILOAD 1
ILOAD 2
IADD
IRETURN
L0
ICONST_0 // 将常整型数0入栈
ISTORE 3 // 栈顶数保存到局部变量#3
L1
ILOAD 3
ILOAD 2
IF_ICMPGE L2 // 比较栈顶的两个操作数是否是大于等于的关系,如果不成立则跳转到L2
IINC 1 1 // 局部变量#1 自增1
IINC 3 1 // 局部变量#3 自增1
GOTO L1 // 跳转到L1执行
L2
ILOAD 1
ILOAD 2
ISUB
IRETURN
MAXSTACK = 2
MAXLOCALS = 4
当我们使用字节码直接操作虚拟机中的底层代码的时候,基本上就是通过改变局部变量表和操作数栈来改变程序的逻辑。还记得根据Java虚拟机规范,MAXSTACK和MAXLOCALS是在.java文件被编译成.class就被确定下来的吗,如果我们要对方法做出修改势必会引入新的局部变量,这时就难免需要对MAXSTACK和MAXLOCALS做重新计算。好在目前流行的字节码框架已经可以自动帮助我们完成这项任务。
三、ASM框架
ASM是一个比较硬核的字节码框架,也是转换效率最高的工具。下面是常用类的介绍:
1. ClassReader
按照Java虚拟机规范(JVMS)中定义的方式来解析class文件中的内容,在遇到合适的字段时调用ClassVisitor中相对应的方法。
ClassReader(final byte[] classFile)
构造方法,通过class字节码数据加载
ClassReader(final String className) throws IOException
通过class全路径名从ClassLoader加载
2. ClassVisitor
java中类的访问者,提供一系列方法由ClassReader调用。调用的顺序如下:visit -> visitSource -> visitModule -> visitNestHost -> visitOuterClass -> visitAnnotation -> visitTypeAnnotation -> visitAttribute -> visitNestMember -> visitPermittedSubclass -> visitInnerClass -> visitRecordComponent -> visitField -> visitMethod -> visitEnd
3. ClassWriter
ClassVisitor的子类,通过它生成最后的字节码。并且它可以帮助重新计算MAXSTACK和MAXLOCALS
4. ModuleVisitor
Java中模块的访问者,作为ClassVisitor.visitModule方法的返回值
5. AnnotationVisitor
Java中注解的访问者,作为ClassVisito中visitTypeAnnotation和visitTypeAnnotation的返回值
6. FieldVisitor
Java中字段的访问者,作为ClassVisito.visitField的返回值
7. MethodVisitor
Java中方法的访问者,作为ClassVisito.visitMethod的返回值
- visitMethodInsn 方法调用指令
- visitVarInsn 局部变量调用指令
- visitInsn(int) 访问一个零参数要求的字节码指令,如LSUB
- visitLdcInsn 把一个常量放到栈顶
- visitInvokeDynamicInsn 动态方法调用
- visitFieldInsn 调用/访问某个字段
8. AnalyzerAdapter
MethodVisitor的子类,使用它重新计算最大操作数栈(MAXSTACK)
9. LocalVariablesSorter
MethodVisitor的子类,使用它重新计算局部变量表(MAXLOCALS)的索引
- newLocal 创建局部变量
通过IDEA的Plugins安装ASM Bytecode Viewer Support Kotlin,我们可以借助这个插件来帮助我们生成大部分代码,具体用法这里就赘述了。
总结:有了以上知识基础,我们可以完成一个简单的demo来感受探针和字节码技术的强大。
一个计算函数执行时间的完整用例
1. 在IDEA中创建一个典型的maven工程
2. 编写pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<groupId>com.learnhow.study</groupId>
<version>1.0</version>
<packaging>jar</packaging>
<artifactId>agent</artifactId>
<dependencies>
<dependency>
<groupId>org.ow2.asm</groupId>
<artifactId>asm</artifactId>
<version>9.2</version>
</dependency>
<dependency>
<groupId>org.ow2.asm</groupId>
<artifactId>asm-commons</artifactId>
<version>9.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>[your jdk version]</source>
<target>[your jdk version]</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifestEntries>
<Premain-Class>[your package].PremainAgent</Premain-Class>
<Can-Redefine-Classes>true</Can-Redefine-Classes>
<Can-Retransform-Classes>true</Can-Retransform-Classes>
</manifestEntries>
</archive>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
带[]的部分请换成你的本地环境。
3.PremainAgent类
public class PremainAgent
public static void premain(String agentArgs, Instrumentation inst)
inst.addTransformer(new XClassFileTransformer());
4.XClassFileTransformer类
public class XClassFileTransformer implements ClassFileTransformer
@Override
public byte[] transform(ClassLoader loader,
String className,
Class<?> classBeingRedefined,
ProtectionDomain protectionDomain,
byte[] classfileBuffer) throws IllegalClassFormatException
try
ClassReader cr = new ClassReader(classfileBuffer);
ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_MAXS);
cr.accept(new NanoTimerClassVisitor(cw), ClassReader.SKIP_DEBUG);
byte[] cc = cw.toByteArray();
return cc;
catch (IOException e)
return null;
transform方法返回null或者new byte[0]表示对当前字节码文件不进行修改。ClassWriter.COMPUTE_MAXS表示框架会自动计算MAXSTACK和MAXLOCALS,ClassReader.SKIP_DEBUG表示当字节码中包含调试信息的时候,会忽略不会触发回调。
5.NanoTimerClassVisitor类
public class NanoTimerClassVisitor extends ClassVisitor
private String className;
public NanoTimerClassVisitor(ClassVisitor classVisitor)
super(ASM9, classVisitor);
@Override
public void visit(int version, int access, String name, String signature, String superName, String[] interfaces)
this.className = name;
super.visit(version, access, name, signature, superName, interfaces);
@Override
public MethodVisitor visitMethod(int access, String name, String descriptor, String signature, String[] exceptions)
MethodVisitor mv = super.visitMethod(access, name, descriptor, signature, exceptions);
if (Objects.nonNull(mv) && !name.equals("<init>") && !name.equals("<clinit>"))
NanoTimerMethodVisitor methodVisitor = new NanoTimerMethodVisitor(mv, className, access, name, descriptor);
return methodVisitor.refactor();
return mv;
class NanoTimerMethodVisitor extends MethodVisitor
private AnalyzerAdapter analyzerAdapter;
private LocalVariablesSorter localVariablesSorter;
private int timeOpcode;
private int outOpcode;
private String className;
private int methodAccess;
private String methodName;
private String methodDescriptor;
public NanoTimerMethodVisitor(MethodVisitor methodVisitor, String className, int methodAccess,
String methodName, String methodDescriptor)
super(ASM9, methodVisitor);
this.className = className;
this.methodAccess = methodAccess;
this.methodName = methodName;
this.methodDescriptor = methodDescriptor;
// 使用AnalyzerAdapter计算最大操作数栈
analyzerAdapter = new AnalyzerAdapter(className, methodAccess, methodName, methodDescriptor, this);
// LocalVariablesSorter重新计算局部变量的索引并自动更新字节码中的索引引用
localVariablesSorter = new LocalVariablesSorter(methodAccess, methodDescriptor, analyzerAdapter);
public MethodVisitor refactor()
return localVariablesSorter;
@Override
public void visitCode()
super.visitCode();
mv.visitMethodInsn(INVOKESTATIC, "java/lang/System", "nanoTime", "()J", false);
timeOpcode = localVariablesSorter.newLocal(Type.LONG_TYPE);
mv.visitVarInsn(LSTORE, timeOpcode);
@Override
public void visitInsn(int opcode)
if ((opcode >= IRETURN && opcode <= RETURN) || opcode == ATHROW)
mv.visitMethodInsn(INVOKESTATIC, "java/lang/System", "nanoTime", "()J", false);
mv.visitVarInsn(LLOAD, timeOpcode);
mv.visitInsn(LSUB);
mv.visitVarInsn(LSTORE, timeOpcode);
mv.visitLdcInsn(className + "." + methodName + "(ns):");
outOpcode = localVariablesSorter.newLocal(Type.getType(String.class));
mv.visitVarInsn(ASTORE, outOpcode);
mv.visitVarInsn(ALOAD, outOpcode);
mv.visitVarInsn(LLOAD, timeOpcode);
mv.visitInvokeDynamicInsn("makeConcatWithConstants", "(Ljava/lang/String;J)Ljava/lang/String;", new Handle(Opcodes.H_INVOKESTATIC, "java/lang/invoke/StringConcatFactory", "makeConcatWithConstants", "(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/String;[Ljava/lang/Object;)Ljava/lang/invoke/CallSite;", false), new Object[]"\\u0001\\u0001");
mv.visitVarInsn(ASTORE, outOpcode);
mv.visitFieldInsn(GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");
mv.visitVarInsn(ALOAD, outOpcode);
mv.visitMethodInsn(INVOKEVIRTUAL, "java/io/PrintStream", "println", "(Ljava/lang/String;)V", false);
super.visitInsn(opcode);
6. 通过assembly插件对项目进行打包生成:agent-1.0-jar-with-dependencies.jar
7. 运行一个目标项目,并添加虚拟机指令-javaagent,就可以看到执行效果
如何查看生成后的代码
计算函数执行时间是一个非常简单的功能,我们很容易一次性写正确。但是如果需要代理的逻辑比较复杂,而探针程序又不像普通程序一样方便做断点调试。我们如何才能够很方便知道生成的代码是否正确呢?这里告诉大家一个诀窍。回到我们XClassFileTransformer类,增加两行代码:
public class XClassFileTransformer implements ClassFileTransformer
@Override
public byte[] transform(ClassLoader loader,
String className,
Class<?> classBeingRedefined,
ProtectionDomain protectionDomain,
byte[] classfileBuffer) throws IllegalClassFormatException
try
ClassReader cr = new ClassReader(classfileBuffer);
ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_MAXS);
cr.accept(new NanoTimerClassVisitor(cw优雅地实现Android主流图片加载框架封装,可无侵入切换框架