Python之路(第九篇)Python文件操作
Posted Nicholas--Altshuler
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python之路(第九篇)Python文件操作相关的知识,希望对你有一定的参考价值。
文件句柄 = open(\'文件路径+文件名\', \'模式\')
例子
f = open("test.txt","r",encoding = “utf-8”)
分析:这里由于python文件和test.txt文件在同一文件夹里,不需要写test的绝对路径
如果要写绝对路径可以这样写
f = open(file = "d:/python/test.txt","r",encoding = “utf-8”)
文件打开模式有以下几种模式
1、文本文件的打开模式
“r” ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
“w”, 只写模式【不可读;不存在则创建;存在则清空内容】
"a",只追加写模式【不可读;不存在则创建;存在则只追加内容】
就是以二进制的方式打开文件,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
"+" 表示可以同时读写某个文件
"r+",读写【可读,可写】
"w+",写读【可读,可写】
"a+",写读【可读,可写】
2、readable()、writable()
readable()判断文件是否可读,返回True或者False,
writable()判断文件是否可写,返回True或者False,
例子
f.readable()
f.writable()
3、read()、readline() 、readlines()
字符串的形式返回结果,read([size])方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止
f.readline() #读取一行内容,光标移动到第二行首部
以字符串的形式返回结果
f.readlines() #读取每一行内容,存放于列表中
读取文本所有内容,将每一行作为一个列表的元素,并且以列表的格式返回结果,但读取大文件会比较占内存。
4、write()、writelines( )
write()要写入字符串
writelines()既可以传入字符串又可以传入一个字符序列,并将该字符序列写入文件。 注意必须传入的是字符序列,不能是数字序列。
f.write(\'1111\\n222\\n\') #针对文本模式的写,需要自己写换行符 f.write(\'1111\\n222\\n\'.encode(\'utf-8\')) #针对b模式的写,需要自己写换行符 f.writelines([\'333\\n\',\'444\\n\']) #文件模式 f.writelines([bytes(\'333\\n\',encoding=\'utf-8\'),\'444\\n\'.encode(\'utf-8\')]) #b模式
5、f.close() #关闭文件f.closed()#查看文件是否关闭
用open方法打开文件后,必须用f.close()关闭文件
文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的。
f.closed()#查看文件是否关闭,返回True或者False
6、with open as f打开方法
这种打开文件的方式不用写f.closed关闭文件
例子
with open(\'/path/to/file\', \'r\') as f:
with open("test.txt","r",encoding = “utf-8”) as f:
7、 对于非文本文件,我们只能使用b模式
非文本文件的打开模式,只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式,b模式可以跨平台使用)
"rb"
"wb"
"ab"
f = open("test.py","rb")
分析:注意这里不能在加,encoding = “utf-8”,因为这里是以二进制的方式打开,不需要再设置打开的编码方式
例子
f = open("test.py","rb")
data = f.read()
print(data)
test.py文件内容:
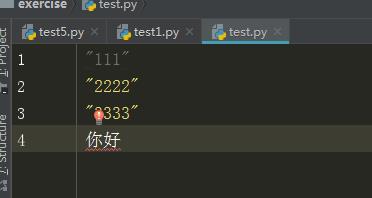
输出
b\'"111"\\r\\n"2222"\\r\\n"3333"\\r\\n\\xe4\\xbd\\xa0\\xe5\\xa5\\xbd\'
分析:这里的\\r\\n是Windows平台的换行,以b开头代表输出的是字节形式
这里的\\xe4\\xbd\\xa0\\xe5\\xa5\\xbd\'代表汉字
f = open("test.py","rb")
data = f.read()
print(data.decode("utf-8"))
输出结果
"111" "2222" "3333" 你好
分析:这里在test.py文件存储时用的是utf-8存储的,在打印输出的时候以"utf-8"进行解码即可输出结果。
以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
例子2
f = open("test11.py","wb")f.write("111\\n")
f.close()
输出结果:出错,提示这里需要字节,而不是字符串形式,这里写入必须以字节形式写入
可改为
f = open("test11.py","wb")
f.write(bytes("111\\n",encoding="utf-8"))
f.close()
分析:这里就可以把字符串“111\\n”写入文件了,这里bytes()一定要指定一个编码。
或者直接对字符串进行编码,不用bytes()方法
f = open("test11.py","wb")
f.write("222\\n".encode("utf-8"))
f.close()
8、f.encoding
取文件打开的编码
例子
f = open("test11.py","w",encoding="gbk")
f.write("222\\n")
f.close()
print(f.encoding)
输出
gbk
分析:这里取的是文件打开的编码,即open语句里的编码,与源文件实际的编码无关。
9、f.flush() 、f.tell()
f.flush() 立刻将文件内容从内存刷到硬盘,这里需要用命令提示行操作,在pycharm里会直接将写入内容写入硬盘,不需要flush()
f.tell()获取当前光标所在的位置
10、文件内光标移动
read(3):
a、文件打开方式为文本模式时,代表读取3个字符
b、文件打开方式为b模式时,代表读取3个字节
read()默认读取整个文件
其余的文件内光标移动都是以字节为单位如seek,tell,truncate
例子
test.txt文件内容
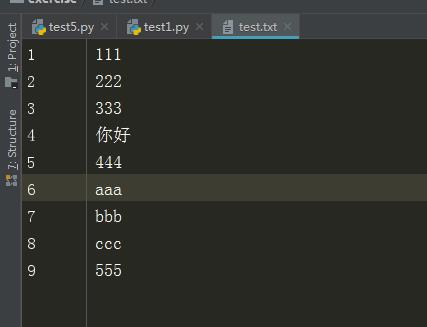
f = open("test.txt","rb")
data = f.read(6)
f.close()
print(data)
输出结果
b\'111\\r\\n2\'
分析:这里的111算3个字节,\\r\\n算2个字节,2算1个字节,这里是b模式,以字节进行计算,这里不能指定编码即不能写encoding = "xx",否则会报错
例子2
文件内容与上面相同
f = open("test.txt","r+",encoding="utf-8")
data = f.read(6)
f.close()
print(data)
输出结果
111 22
分析:这是文本模式,这里的111算3个字符,换行符\\r\\n算一个字符,22算2个字符,共计6个字符。
11、seek()
seek()移动文件光标到到指定位置。
seek()语法
f.seek(offset[, whence])
offset即移动多少个字节数,whence有0,1,2三种模式,0 代表文件开始算, 1 代表当前位置开始算, 2 代表文件末尾开始算,默认是0。其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的,Widnows 系统下的换行代表2个字节大小(\\r\\n)。
例子
test.txt文件内容
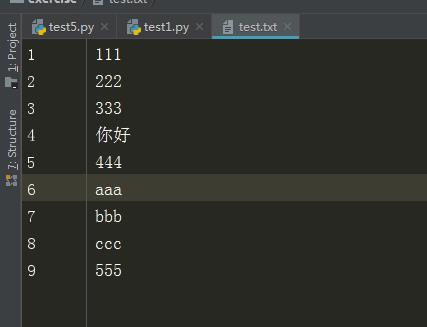
f = open("test.txt","r+",encoding="utf-8")
f.seek(3,0)
data = f.read()
f.close()
print(data)
输出结果
222 333 你好 444 aaa bbb ccc 555
例子2
文件内容与上面相同
f = open("test.txt","rb")
f.seek(5)
f.seek(11,1)
print(f.tell())
data = f.read()
f.close()
print(data)
输出结果
16 b\'\\xbd\\xa0\\xe5\\xa5\\xbd\\r\\n444\\r\\naaa\\r\\nbbb\\r\\nccc\\r\\n555\'
分析
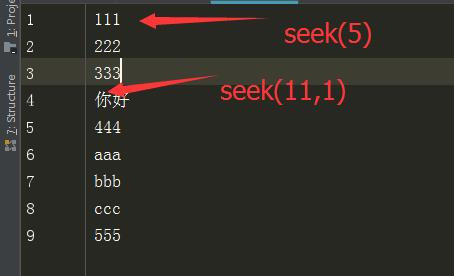
这里是以二进制打开的,111算3个字节,后面有个看不见的\\r\\n换行符,因此,seek(5)的位置就是第一行的最后
seek(11,1)是从当前位置继续移动光标,即222\\r\\n算5个字节,同理333\\r\\n算5个字节,“你好”(文本文件是utf-8编码的)算6个字节,因此这时只取“你”这个字的3个字节的第一个字节,光标移动到你的第一个字节之后,所以最后输出了\\xbd\\xa0\\xe5\\xa5\\xbd共5个字节。
注意这里的光标操作要用seek()方法,直接用鼠标移动光标是无效的。
例子3
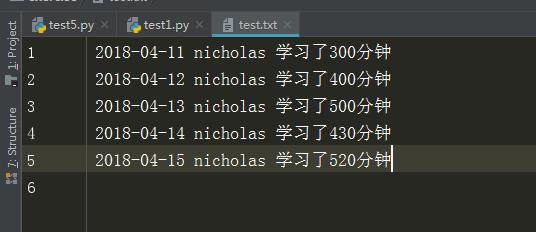
文件内容
f = open("test.txt","rb")
offs = -20
while True:
f.seek(offs,2)
data = f.readlines()
if len(data) > 1:
print("文件的最后一行是%s"%data[-1].decode("utf-8"))
breakf = open("test.txt","rb")
offs = -20
while True:
f.seek(offs,2)
data = f.readlines()
if len(data) > 1:
print("文件的最后一行是%s"%data[-1].decode("utf-8"))
break
这里目的是在不知道一行是多少字节的情况下输入最后一行
输出结果
文件的最后一行是2018-04-15 nicholas 学习了520分钟
分析:seek(-20,2)是从文件的最后开始计算的,必须以b模式进行。
12、 truncate()
truncate() 方法用于从文件的首行首字节开始截断,截断文件为 size 个字节,无 size 表示从当前位置截断;截断后面的所有字节被删除,其中 Widnows 系统下的换行代表2个字节大小。
例子
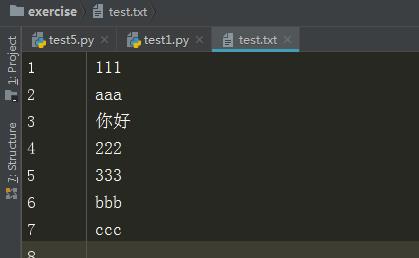
文件内容
f = open("test.txt","r+")
f.truncate(10)
data = f.read()
print(data)
输出结果
111 aaa
分析:这里是以字节进行计算的,111算3个字节,后面的换行符算2个字节,所以这里截取了111aaa和之后的2个换行符,共计10个字节。
以上是关于Python之路(第九篇)Python文件操作的主要内容,如果未能解决你的问题,请参考以下文章