用python拉钩网的完整版
Posted lin1318
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用python拉钩网的完整版相关的知识,希望对你有一定的参考价值。
这是在爬取伯乐在线的基础之上的,所以就没重复代码。
在lagou.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ArticleSpider.utils.common import get_md5
from selenium import webdriver
import time
import pickle
from ArticleSpider.items import LagouJobItemLoader, LagouJobItem
from datetime import datetime
class LagouSpider(CrawlSpider):
name = ‘lagou‘
allowed_domains = [‘www.lagou.com‘]
start_urls = [‘https://www.lagou.com/‘]
# headers = {
# "HOST": "www.lagou.com",
# "Referer": ‘https://www.lagou.com‘,
#
# ‘User-Agent‘:"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36"
# }
rules = (
Rule(LinkExtractor(allow=r‘gongsi/j/\\d+.html‘), follow=True),
Rule(LinkExtractor(allow=r‘zhaopin/.*‘), follow=True),
Rule(LinkExtractor(allow=r‘jobs/\\d+.html‘), callback=‘parse_job‘, follow=True),
)
def parse_job(self, response):
#解析拉勾网的职位
item_loader = LagouJobItemLoader(item=LagouJobItem(), response=response)
item_loader.add_css("title", ".job-name::attr(title)")
item_loader.add_value("url", response.url)
item_loader.add_value("url_object_id", get_md5(response.url))
item_loader.add_css("salary", ".job_request .salary::text")
item_loader.add_xpath("job_city", "//*[@class=‘job_request‘]/p/span[2]/text()")
item_loader.add_xpath("work_years", "//*[@class=‘job_request‘]/p/span[3]/text()")
item_loader.add_xpath("degree_need", "//*[@class=‘job_request‘]/p/span[4]/text()")
item_loader.add_xpath("job_type", "//*[@class=‘job_request‘]/p/span[5]/text()")
item_loader.add_css("tags", ‘.position-label li::text‘)
item_loader.add_css("publish_time", ".publish_time::text")
item_loader.add_css("job_advantage", ".job-advantage p::text")
item_loader.add_css("job_desc", ".job_bt div")
item_loader.add_css("job_addr", ".work_addr")
item_loader.add_css("company_name", "#job_company dt a img::attr(alt)")
item_loader.add_css("company_url", "#job_company dt a::attr(href)")
item_loader.add_value("crawl_time", datetime.now())
job_item = item_loader.load_item()
return job_item
def start_requests(self):
browser = webdriver.Chrome(executable_path="D:/Temp/chromedriver.exe")
browser.get("https://passport.lagou.com/login/login.html?service=https%3a%2f%2fwww.lagou.com%2f")
browser.find_element_by_xpath("/html/body/section/div[1]/div[2]/form/div[1]/input").send_keys("account")#需要输入正确的拉钩网账号
browser.find_element_by_xpath("/html/body/section/div[1]/div[2]/form/div[2]/input").send_keys("password")#需要输入拉钩网密码
print(browser.page_source)
browser.find_element_by_xpath("/html/body/section/div[1]/div[2]/form/div[5]").click()
time.sleep(10)
Cookies=browser.get_cookies()
# print(Cookies)
cookie_dict={}
for cookie in Cookies:
f=open(‘C:/Users/Dell/scrapytest/Scripts/ArticleSpider‘+cookie[‘name‘]+‘.lagou‘,‘wb‘)
pickle.dump(cookie,f)
f.close()
cookie_dict[cookie[‘name‘]]=cookie[‘value‘]
browser.close()
return[scrapy.Request(url=self.start_urls[0], dont_filter=True,cookies=cookie_dict)]
# return[scrapy.Request(url=self.start_urls[0], headers=self.headers,dont_filter=True,cookies=cookie_dict)]
在main中
from scrapy.cmdline import execute import sys import os sys.path.append(os.path.dirname(os.path.abspath(__file__))) # execute(["scrapy", "crawl", "jobbole"]) # execute(["scrapy", "crawl", "zhihu"]) execute(["scrapy", "crawl", "lagou"])
在items中
def remove_splash(value):
#去掉工作城市的斜线
return value.replace("/","")
def handle_jobaddr(value):
addr_list = value.split("\\n")
addr_list = [item.strip() for item in addr_list if item.strip()!="查看地图"]
return "".join(addr_list)
class LagouJobItemLoader(ItemLoader):
#自定义itemloader
default_output_processor = TakeFirst()
class LagouJobItem(scrapy.Item):
#拉勾网职位信息
title = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
salary = scrapy.Field()
job_city = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
work_years = scrapy.Field(
input_processor = MapCompose(remove_splash),
)
degree_need = scrapy.Field(
input_processor = MapCompose(remove_splash),
)
job_type = scrapy.Field()
publish_time = scrapy.Field()
job_advantage = scrapy.Field()
job_desc = scrapy.Field()
job_addr = scrapy.Field(
input_processor=MapCompose(remove_tags, handle_jobaddr),
)
company_name = scrapy.Field()
company_url = scrapy.Field()
tags = scrapy.Field(
input_processor = Join(",")
)
crawl_time = scrapy.Field()
def get_insert_sql(self):
insert_sql = """
insert into lagou_job(title, url, url_object_id, salary, job_city, work_years, degree_need,
job_type, publish_time, job_advantage, job_desc, job_addr, company_name, company_url,
tags, crawl_time) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE salary=VALUES(salary), job_desc=VALUES(job_desc)
"""
params = (
self["title"], self["url"], self["url_object_id"], self["salary"], self["job_city"],
self["work_years"], self["degree_need"], self["job_type"],
self["publish_time"], self["job_advantage"], self["job_desc"],
self["job_addr"], self["company_name"], self["company_url"],
self["job_addr"], self["crawl_time"].strftime(SQL_DATETIME_FORMAT),
)
return insert_sql, params
在数据库的设计
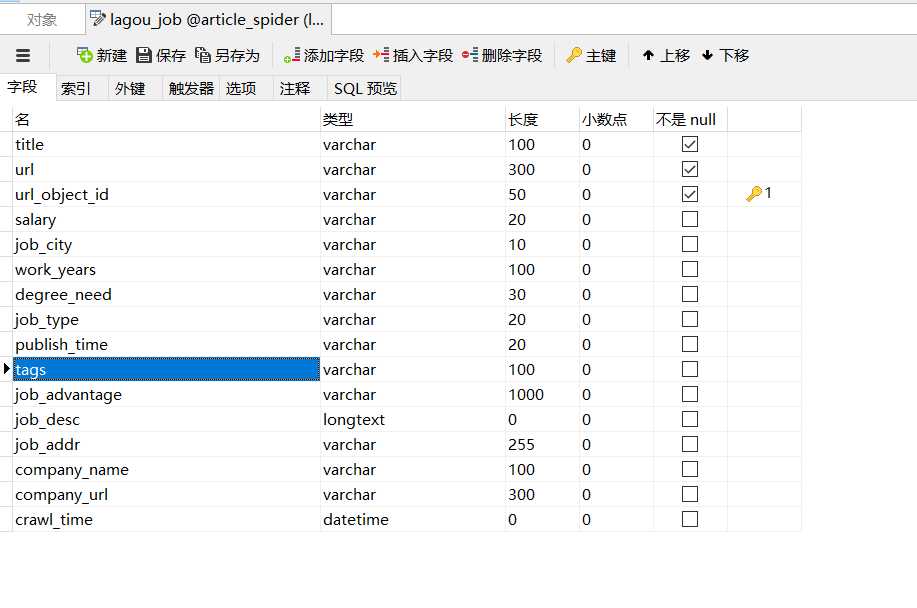
以上是关于用python拉钩网的完整版的主要内容,如果未能解决你的问题,请参考以下文章