python简单爬取静态网页
Posted 韩非囚秦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python简单爬取静态网页相关的知识,希望对你有一定的参考价值。
一、简单爬虫框架
简单爬虫框架由四个部分组成:URL管理器、网页下载器、网页解析器、调度器,还有应用这一部分,应用主要是NLP配合相关业务。
它的基本逻辑是这样的:给定一个要访问的URL,获取这个html及内容(也可以获取head和cookie等其它信息),获取html中的某一类链接,如a标签的href属性。从这些链接中继续访问相应的html页面,然后获取这些html的固定标签的内容,并把这些内容保存下来。
一些前提:;所有要爬取的页面,它们的标签格式都是相同的,可以写一个网页解析器去获取相应的内容;给定的URL(要访问的资源)所获得的html,它包含的标签链接是可以筛选的,筛选后的标签链接(新的URL)会被继续请求其html文档。调度器是一个循环体,循环处理这些URL、请求以及html、网页解析。
1.运行流程
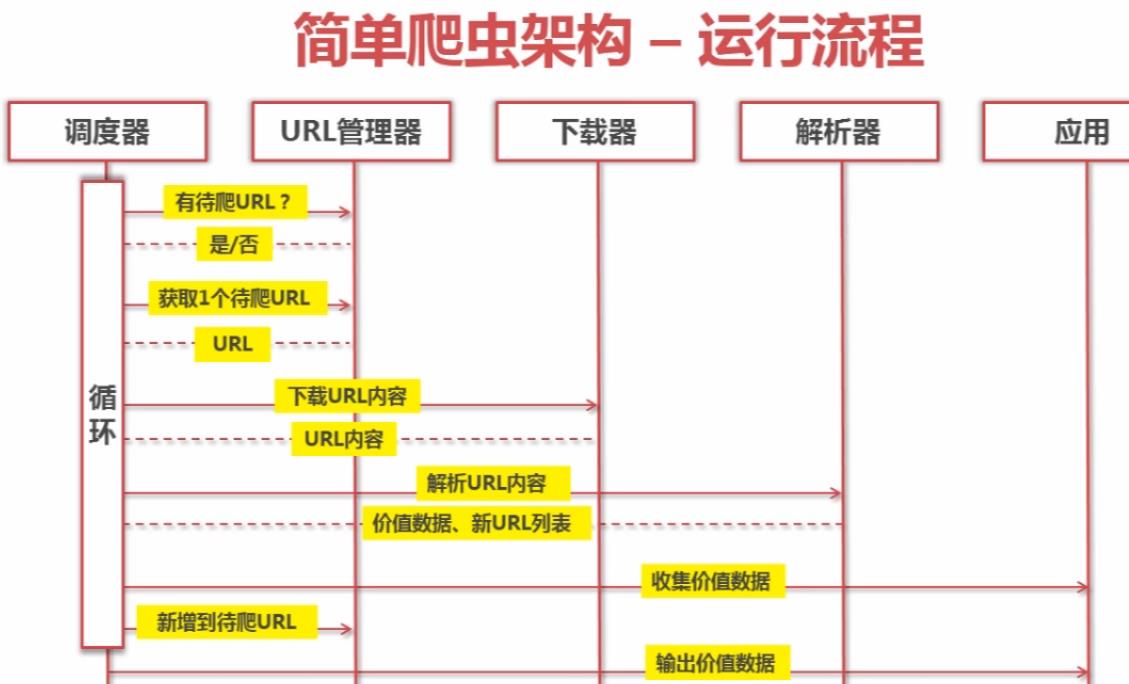
调度器是一个主循环体,负责不断重复执行URL管理器、下载器、解析器。URL是管理新的URL的添加、旧的URL的去除,以及URL的去重和记录。下载器顾名思义,就是根据URL,发送http请求,获取utf-8编码的字节流的html文件数据。解析器负责将html还原成DOM对象,并提供一套类似js的DOM操作的方法,从html中获取节点、属性、文本、甚至是样式等内容。
2.URL管理器
URL管理器有两个功能,获取待添加的URL--判断它是否在已被读取的URL集合里--[No]判断它是否在待读取的URL集合里--[No]添加到待读取的URL集合里。否则就直接抛弃。
URL管理器一般放在内存、关系型数据库和缓存数据库里。python里可以使用set()集合去重。
3.网页下载器
向给定的URL发送请求,获取html。python的两个模块。内置urllib模块和第三方模块request。python3将urllib2封装成了urllib.request模块。
1 # 网页下载器代码示例 2 import urllib 3 4 url = "http://www.baidu.com" 5 6 print("第一种方法: 直接访问url") 7 response1 = urllib.request.urlopen(url) 8 print(response1.getcode()) # 状态码 9 print(len(response1.read())) # read读取utf-8编码的字节流数据 10 11 print("第二种方法: 设置请求头,访问Url") 12 request = urllib.request.Request(url) # 请求地址 13 request.add_header("user-agent", "mozilla/5.0") # 修改请求头 14 response2 = urllib.request.urlopen(request) 15 print(response2.getcode()) 16 print(len(response2.read())) 17 18 import http.cookiejar # 不知道这是啥 19 20 print("第三种方法: 设置coockie,返回的cookie") 21 # 第三种方法的目的是为了获取浏览器的cookie内容 22 cj = http.cookiejar.CookieJar() 23 opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) 24 urllib.request.install_opener(opener) 25 response3 = urllib.request.urlopen(url) 26 print(response3.getcode()) 27 print(len(response3.read())) 28 print(cj) # 查看cookie的内容
4.网页解析器
将utf-8编码的字节码重新重新解析为html。因为数据传输是字节数据,所以网页下载器下载的内容需要重新解析。
提供DOM对象[html文档解构]的操作方法。和js类似。包括节点、标签元素、属性[包括name、class、style、value等等]、样式、内容等的操作。从而能够获取特定的内容。
python的BeautifulSoup模块(bs4)。以下代码可直接在bs4模块官方文档中获取和运行。
1 from bs4 import BeautifulSoup 2 from re import compile 3 html_doc = """ 4 <html><head><title>The Dormouse\'s story</title></head> 5 <body> 6 <p class="title"><b>The Dormouse\'s story</b></p> 7 8 <p class="story">Once upon a time there were three little sisters; and their names were 9 <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, 10 <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and 11 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; 12 and they lived at the bottom of a well.</p> 13 14 <p class="story">...</p> 15 """ 16 17 soup = BeautifulSoup(html_doc, "html.parser") 18 print(soup.prettify()) 19 print(soup.title) 20 print(soup.title.name) 21 print(soup.title.string) 22 print(soup.title.parent.name) 23 print(soup.p) 24 print(soup.p[\'class\']) 25 print(soup.a) 26 print(soup.find_all(href=compile(r"/example.com/\\S*"))) 27 print(soup.find_all(\'a\')) 28 print(soup.find(id="link3")) 29 print(soup.get_text()) 30 print(soup.find("p", attrs={"class": "story"}).get_text()) 31 32 for link in soup.find_all(\'a\'): 33 print(link.get(\'href\'))
二、简单示例
爬取百度百科上词条为python的以href=\'/tem/\'开头的所有相关网页的词条简介。
1 from re import compile 2 from html.parser import HTMLParser 3 from bs4 import 4 5 # url管理器 6 class UrlManager(object): 7 """ 8 url管理器主要有三个功能:add_new_url添加新的待爬取的页面;get_new_url删除已爬取的页面;标记待爬取的和已爬取的页面。 9 """ 10 def __init__(self): 11 self.new_urls = set() 12 self.old_urls = set() 13 def add_new_url(self, url): 14 if url is None: 15 return 16 # 如果传入的url既不在待爬取的url里又不在爬过的url里,说明它是待爬取的url 17 if url not in self.new_urls and url not in self.old_urls: 18 self.new_urls.add(url) 19 20 def add_new_urls(self, urls): 21 if urls is None or len(urls) == 0: 22 return 23 for url in urls: 24 self.add_new_url(url) 25 26 def has_new_url(self): 27 return len(self.new_urls) != 0 28 29 def get_new_url(self): 30 new_url = self.new_urls.pop() # 从待爬去的url中剔除要爬取的目标 31 self.old_urls.add(new_url) # 添加到 32 return new_url 33 34 # 简单的下载器 35 class HtmlDownloader(object): 36 def download(self, url): 37 if url is None: 38 return None 39 response = urllib.request.urlopen(url) 40 if response.getcode() != 200: 41 return None 42 return response.read() 43 44 # 解析器 45 class HtmlParser(object): 46 def _get_new_urls(self, page_url, soup): 47 # 这里要提一下,百度百科python词汇的url是https://baike.baidu.com/item/Python/407313 48 # 页面中的a标签的href属性都类似href="/item/%E6%95%99%E5%AD%A6"这种属性 49 # 在处理时,需要加上baike.baidu.com保证url资源定位符的完整性。后面只需匹配"/item/" 50 new_urls = set() 51 links = soup.find_all(\'a\', href=compile(r"/item/\\S*")) 52 for link in links: 53 new_url = link["href"] 54 new_full_url = urllib.parse.urljoin(page_url, new_url) 55 new_urls.add(new_full_url) 56 return new_urls 57 58 def _get_new_data(self, page_url, soup): 59 res_data = {} 60 res_data["url"] = page_url 61 # 爬取标题 62 # <dd class="lemmaWgt-lemmaTitle-title"></dd><h1>Python</h1> 63 title_node = soup.find("dd", attrs={"class": "lemmaWgt-lemmaTitle-title"}).find("h1") 64 res_data["title"] = title_node.get_text() 65 # 爬取简介内容 66 # <div class="lemma-summary" label-module="lemmaSummary"></div> 67 # 这个div下的所有div里的text 68 summary_node = soup.find(\'div\', attrs={"class": "lemma-summary", "label-module":"lemmaSummary"}) 69 res_data["summary"] = summary_node.get_text() 70 return res_data 71 72 def parse(self, page_url, html_doc): 73 if page_url is None or html_doc is None: 74 return 75 # 解析成了一个整个的DOM对象,也就是纯html格式的文件 76 soup = BeautifulSoup(html_doc, "html.parser", from_encoding="utf-8") 77 new_urls = self._get_new_urls(page_url, soup) 78 new_data = self._get_new_data(page_url, soup) 79 # print("page_url: %r, new_urls: %r, new_data: %r" % (page_url, new_urls, new_data)) 80 return new_urls, new_data 81 82 # 输出器 83 class HtmlOutputer(object): 84 def __init__(self): 85 self.datas = [] 86 def collect_data(self, data): 87 if data is None: 88 return 89 self.datas.append(data) 90 def output_html(self): 91 fout = open("output.html", \'w\', encoding="UTF-8") 92 fout.write("<html>") 93 fout.write("<meta http-equiv=\'content-type\' content=\'text/html;charset=utf-8\'>") 94 fout.write("<body>") 95 fout.write("<table>") 96 for data in self.datas: 97 fout.write("<tr>") 98 fout.write("<td>%s</td>" %data[\'url\']) 99 fout.write("<td>%s</td>" %data[\'title\']) 100 fout.write("<td>%s</td>" %data[\'summary\']) 101 fout.write("</tr>") 102 fout.write("</table>") 103 fout.write("</body>") 104 fout.write("</html>") 105 106 class SpiderMain(object): 107 def __init__(self): 108 self.urls = UrlManager() 109 self.downloader = HtmlDownloader() 110 self.parser = HtmlParser() 111 self.outputer = HtmlOutputer() 112 113 def craw(self, root_url): 114 count = 1 115 self.urls.add_new_url(root_url) 116 while self.urls.has_new_url(): 117 try: 118 new_url = self.urls.get_new_url() 119 html_cont = self.downloader.download(new_url) 120 # print("\\033[1;36m %r \\033[0m" % html_cont.decode("utf-8")) 121 new_urls, new_data = self.parser.parse(new_url, html_cont) 122 self.urls.add_new_urls(new_urls) 123 self.outputer.collect_data(new_data) 124 if count == 11:break 125 print("\\033[1;36m [CRAW]\\033[0m : %d %r" %(count, new_url)) 126 count += 1 127 except Exception as e: 128 print("craw failed") 129 print(e) 130 self.outputer.output_html()
运行结果如下:
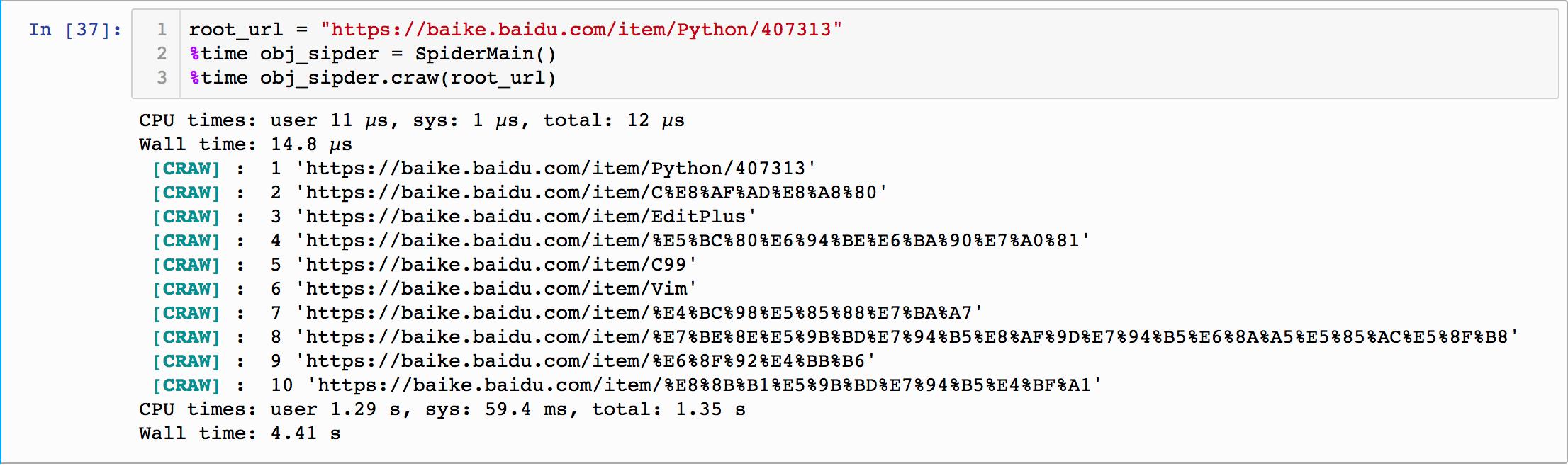
打开保存的out.html,内容如下:

以上是关于python简单爬取静态网页的主要内容,如果未能解决你的问题,请参考以下文章