python 简单图像识别--验证码Ⅲ
Posted Oran9e
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 简单图像识别--验证码Ⅲ相关的知识,希望对你有一定的参考价值。
python 简单图像识别--验证码
记录下,准备工作安装过程很是麻烦。
首先库:pytesseract,image,tesseract,PIL
windows安装PIL,直接exe进行安装更方便(https://files.cnblogs.com/files/Oran9e/PILwin64.zip)(https://files.cnblogs.com/files/Oran9e/PILwin32.zip)
安装 image:pip install image
安装 pytesseract:pip install pytesseract
安装 tesseract:pip install tesseract (安装 tesseracr,这里是个坑,需要安装到C盘里C:\\Program Files (x86)\\Tesseract-OCR,也就是默认路径 ,不然运行 python 代码的时候调用不了 tesseract.exe )
修改 tesseract.py 代码:\\python\\Lib\\site-packages\\pytesseract\\tesseract.py
tesseract_cmd 改成 tesseract.exe的路径,进行调用。
tesseract_cmd = \'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe\'
准备完上面的工作,基本上就可以进行简单的验证码识别了。
代码:
#coding=utf-8 from PIL import Image import pytesseract image = Image.open(\'2.jpg\') orange = pytesseract.image_to_string(image) print orange


下篇文章将会写个自动识别验证码,实现自动登陆的小脚本。
python 简单图像识别--验证码Ⅱ
在实现自动登陆的时候,我们首先需要做到识别验证码,上篇文章讲到如何识别验证码(http://www.cnblogs.com/Oran9e/p/8799194.html)。
一般情况下,我们见到的验证码是服务器动态生成的,这个时候我们要做的就是把验证码下载到本地,然后就可以像上篇文章一样进行识别,为自动登陆打下坚实的基础。
下面就记下困扰我两天的问题,把坑说明一下。
本来是想把 cnvd 的验证码进行下载识别(http://www.cnvd.org.cn/jcaptcha/jpeg/imageCaptcha?id=1523686908)
但是 cnvd 的网站是有反爬虫机制的,打印下 get 到的内容,是<script>***</script> js 代码,因此我认为是不能直接下载的,当然也存在右键另存为了哈。
对比下两个链接打印出来的内容(http://lab1.xseclab.com/vcode7_f7947d56f22133dbc85dda4f28530268/vcode.php)

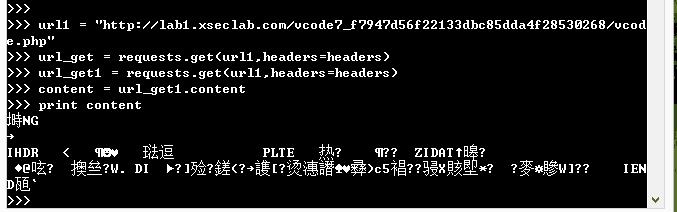
上图可以看到,直接打印的内容是验证码图片的内容,因此这个时候我们可以进行下载,下载的时候是以二进制的方式展现,先保存到本地。
代码如下:
#coding=utf-8
from PIL import Image
import pytesseract
import requests
url = \'http://lab1.xseclab.com/vcode7_f7947d56f22133dbc85dda4f28530268/vcode.php\' #验证码URL
headers = {\'User-Agent\':"Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0"} #headers
url_get = requests.request("GET",url,headers=headers,verify=False) #发送请求
当然,下载验证码也不止上面的一种方式,也可以通过截图保存验证码进行识别。有兴趣可以试试。
先记录到这里,争取晚上写出识别验证码自动登陆的脚本。
python 简单图像识别--验证码Ⅲ
实现自动登陆网站
登录学校图书馆管理系统为例,做一个简单的例子。python识别简单的没有干扰的纯数字验证码还是可以的,但是识别字母数字再加上干扰因素,误报率很高,因此这个我是采用”人工识别“,人工输入。
首先得明白cookie的作用,cookie是某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据。因此我们需要用Cookielib模块来保持网站的cookie。
登录学校图书馆管理系统登陆(http://122.207.221.227:8080/opac/login),验证码(http://122.207.221.227:8080/kaptcha/goldlib)
可以发现这个验证码是动态更新的每次打开都不一样,一般这种验证码和cookie是同步的。想识别验证码肯定是吃力不讨好的事,因此我们的思路是首先访问验证码页面,保存验证码、获取cookie用于登录,然后再直接向登录地址post数据。
先分析登录页面需要post的request和header信息
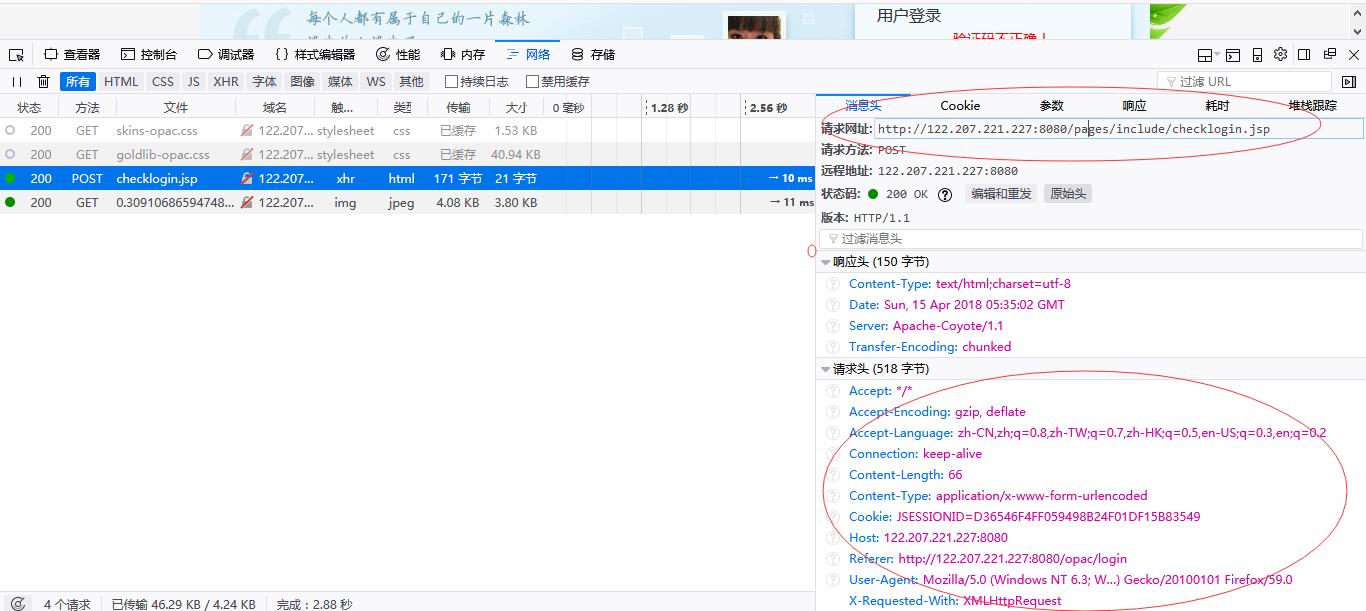

从中可以看出需要 post 的url并不是访问的页面,而是(http://122.207.221.227:8080/pages/include/checklogin.jsp)
其中需要提交的表单数据中 username 和 password 分别用户名和密码。
分析了上面的因素,下面就直接贴出代码。
#coding=utf-8
from PIL import Image
import pytesseract
import urllib2
import urllib
import PIL.ImageOps
import requests
import cookielib
import re
import sys
\'\'\'图书馆登陆\'\'\'
reload(sys)
sys.setdefaultencoding("utf-8") #防止中文报错
url = \'http://122.207.221.227:8080/pages/include/checklogin.jsp\'
capchaurl = \'http://122.207.221.227:8080/kaptcha/0.5458022691509324\'
cookie = cookielib.CookieJar() # 将cookies绑定到一个opener cookie由cookielib自动管理
handler = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(handler)
username=\'xxxxx\'
password=\'xxxxx\' #用户名,密码
callNo = \'callNo\'
picture = opener.open(capchaurl).read() # 用openr访问验证码地址,获取cookie
local = open(\'C:\\Users\\ww\\Desktop\\goldlib.jpg\',"wb") # 保存验证码到本地
local.write(picture)
local.close()
secrecode = raw_input(\'yanzhengma: \') # 输入验证码
postData = {
\'username\': username,
\'password\': password,
\'loginType\': callNo,
\'kaptcha\': secrecode,
} # 抓包信息 构造表单
headers = {
\'Accept\': \'*/*\',
\'Accept-Encoding\': \'gzip, deflate\',
\'Accept-Language\': \'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2\',
\'Connection\': \'keep-alive\',
\'Content-Length\': \'64\',
\'Content-Type\': \'application/x-www-form-urlencoded\',
\'Host\': \'122.207.221.227:8080\',
\'Referer\': \'http://122.207.221.227:8080/opac/login\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0\',
\'X-Requested-With\': \'XMLHttpRequest\',
} # 根据抓包信息 构造headers
data = urllib.urlencode(postData) # 生成post数据 ?key1=value1&key2=value2的形式
request = urllib2.Request(url,data,headers) #构造request请求
try:
response = opener.open(request)
result = response.read().decode(\'utf-8\')
print result
except urllib2.HTTPError, e:
print e.code
演示结果

任重而道远!
转载请注明链接(http://www.cnblogs.com/Oran9e/p/8847313.html)。
以上是关于python 简单图像识别--验证码Ⅲ的主要内容,如果未能解决你的问题,请参考以下文章