Python Pandas Merge, join and concatenate
Posted Jesse_Li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python Pandas Merge, join and concatenate相关的知识,希望对你有一定的参考价值。
Pandas提供了基于 series, DataFrame 和panel对象集合的连接/合并操作。
Concatenating objects
先来看例子:
from pandas import Series, DataFrame import pandas as pd import numpy as np df1 = pd.DataFrame({\'A\': [\'A0\', \'A1\', \'A2\', \'A3\'], \'B\': [\'B0\', \'B1\', \'B2\', \'B3\'], \'C\': [\'C0\', \'C1\', \'C2\', \'C3\'], \'D\': [\'D0\', \'D1\', \'D2\', \'D3\']}, index=[0, 1, 2, 3]) df2 = pd.DataFrame({\'A\': [\'A4\', \'A5\', \'A6\', \'A7\'], \'B\': [\'B4\', \'B5\', \'B6\', \'B7\'], \'C\': [\'C4\', \'C5\', \'C6\', \'C7\'], \'D\': [\'D4\', \'D5\', \'D6\', \'D7\']}, index=[4, 5, 6, 7]) df3 = pd.DataFrame({\'A\': [\'A8\', \'A9\', \'A10\', \'A11\'], \'B\': [\'B8\', \'B9\', \'B10\', \'B11\'], \'C\': [\'C8\', \'C9\', \'C10\', \'C11\'], \'D\': [\'D8\', \'D9\', \'D10\', \'D11\']}, index=[8, 9, 10, 11]) frames = [df1, df2, df3] result = pd.concat(frames) print(frames)
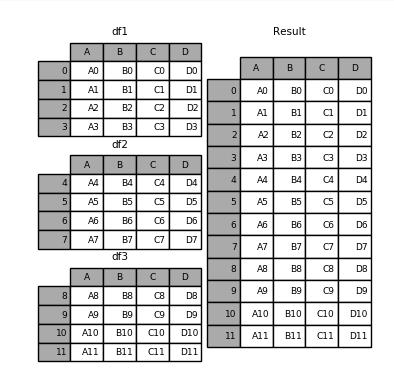
上面效果类似sql中的union操作
pd.concat(objs, axis=0, join=\'outer\', join_axes=None, ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False,copy=True)
objs: a sequence or mapping of Series, DataFrame, or Panel objects. If a dict is passed, the sorted keys will be used as the keys argument, unless it is passed, in which case the values will be selected (see below). Any None objects will be dropped silently unless they are all None in which case a ValueError will be raised.axis: {0, 1, ...}, default 0. The axis to concatenate along.join: {‘inner’, ‘outer’}, default ‘outer’. How to handle indexes on other axis(es). Outer for union and inner for intersection.ignore_index: boolean, default False. If True, do not use the index values on the concatenation axis. The resulting axis will be labeled 0, ..., n - 1. This is useful if you are concatenating objects where the concatenation axis does not have meaningful indexing information. Note the index values on the other axes are still respected in the join.join_axes: list of Index objects. Specific indexes to use for the other n - 1 axes instead of performing inner/outer set logic.keys: sequence, default None. Construct hierarchical index using the passed keys as the outermost level. If multiple levels passed, should contain tuples.levels: list of sequences, default None. Specific levels (unique values) to use for constructing a MultiIndex. Otherwise they will be inferred from the keys.names: list, default None. Names for the levels in the resulting hierarchical index.verify_integrity: boolean, default False. Check whether the new concatenated axis contains duplicates. This can be very expensive relative to the actual data concatenation.copy: boolean, default True. If False, do not copy data unnecessarily.
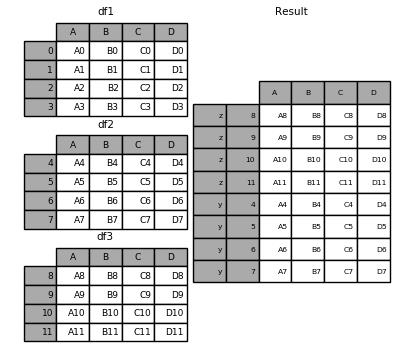
result = pd.concat(frames, keys=[\'x\', \'y\', \'z\']) print(result)

上面的结果集有一个hierachical index, 所以我们可以根据这个key找到相应的元素
print(result.loc[\'y\']) # A B C D #4 A4 B4 C4 D4 #5 A5 B5 C5 D5 #6 A6 B6 C6 D6 #7 A7 B7 C7 D7
Set logic on the other axes
When gluing together multiple DataFrames (or Panels or...), for example, you have a choice of how to handle the other axes (other than the one being concatenated). This can be done in three ways:
- Take the (sorted) union of them all,
join=\'outer\'. This is the default option as it results in zero information loss. - Take the intersection,
join=\'inner\'. - Use a specific index (in the case of DataFrame) or indexes (in the case of Panel or future higher dimensional objects), i.e. the
join_axesargument
Here is a example of each of these methods. First, the default join=\'outer\' behavior:
下面有点类似full join的效果
df1 = pd.DataFrame({\'A\': [\'A0\', \'A1\', \'A2\', \'A3\'],
\'B\': [\'B0\', \'B1\', \'B2\', \'B3\'],
\'C\': [\'C0\', \'C1\', \'C2\', \'C3\'],
\'D\': [\'D0\', \'D1\', \'D2\', \'D3\']},
index=[0, 1, 2, 3])
index=[8, 9, 10, 11])
df4 = pd.DataFrame({\'B\': [\'B2\', \'B3\', \'B6\', \'B7\'],
\'D\': [\'D2\', \'D3\', \'D6\', \'D7\'],
\'F\': [\'F2\', \'F3\', \'F6\', \'F7\']},
index=[2, 3, 6, 7])
result = pd.concat([df1, df4], axis=1)
print(result)

下面看下inner的效果
df1 = pd.DataFrame({\'A\': [\'A0\', \'A1\', \'A2\', \'A3\'],
\'B\': [\'B0\', \'B1\', \'B2\', \'B3\'],
\'C\': [\'C0\', \'C1\', \'C2\', \'C3\'],
\'D\': [\'D0\', \'D1\', \'D2\', \'D3\']},
index=[0, 1, 2, 3])
df4 = pd.DataFrame({\'B\': [\'B2\', \'B3\', \'B6\', \'B7\'],
\'D\': [\'D2\', \'D3\', \'D6\', \'D7\'],
\'F\': [\'F2\', \'F3\', \'F6\', \'F7\']},
index=[2, 3, 6, 7])
result = pd.concat([df1, df4], axis=1,join=\'inner\')
print(result)

Left join
df1 = pd.DataFrame({\'A\': [\'A0\', \'A1\', \'A2\', \'A3\'],
\'B\': [\'B0\', \'B1\', \'B2\', \'B3\'],
\'C\': [\'C0\', \'C1\', \'C2\', \'C3\'],
\'D\': [\'D0\', \'D1\', \'D2\', \'D3\']},
index=[0, 1, 2, 3])
df4 = pd.DataFrame({\'B\': [\'B2\', \'B3\', \'B6\', \'B7\'],
\'D\': [\'D2\', \'D3\', \'D6\', \'D7\'],
\'F\': [\'F2\', \'F3\', \'F6\', \'F7\']},
index=[2, 3, 6, 7])
result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
print(result)

Concatenating using append
A useful shortcut to concat are the append instance methods on Series and DataFrame. These methods actually predated concat. They concatenate along axis=0, namely the index:类似union
df1 = pd.DataFrame({\'A\': [\'A0\', \'A1\', \'A2\', \'A3\'],
\'B\': [\'B0\', \'B1\', \'B2\', \'B3\'],
\'C\': [\'C0\', \'C1\', \'C2\', \'C3\'],
\'D\': [\'D0\', \'D1\', \'D2\', \'D3\']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({\'A\': [\'A4\', \'A5\', \'A6\', \'A7\'],
\'B\': [\'B4\', \'B5\', \'B6\', \'B7\'],
\'C\': [\'C4\', \'C5\', \'C6\', \'C7\'],
\'D\': [\'D4\', \'D5\', \'D6\', \'D7\']},
index=[4, 5, 6, 7])
result = result = df1.append(df2)
print(result)

df1 = pd.DataFrame({\'A\': [\'A0\', \'A1\', \'A2\', \'A3\'],
\'B\': [\'B0\', \'B1\', \'B2\', \'B3\'],
\'C\': [\'C0\', \'C1\', \'C2\', \'C3\'],
\'D\': [\'D0\', \'D1\', \'D2\', \'D3\']},
index=[0, 1, 2, 3])
df4 = pd.DataFrame({\'B\': [\'B2\', \'B3\', \'B6\', \'B7\'],
\'D\': [\'D2\', \'D3\', \'D6\', \'D7\'],
\'F\': [\'F2\', \'F3\', \'F6\', \'F7\']},
index=[2, 3, 6, 7])
result = result = df1.append(df4)
print(result)

df1 = pd.DataFrame({\'A\': [\'A0\', \'A1\', \'A2\', \'A3\'],
\'B\': [\'B0\', \'B1\', \'B2\', \'B3\'],
\'C\': [\'C0\', \'C1\', \'C2\', \'C3\'],
\'D\': [\'D0\', \'D1\', \'D2\', \'D3\']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({\'A\': [\'A4\', \'A5\', \'A6\', \'A7\'],
\'B\': [\'B4\', \'B5\', \'B6\', \'B7\'],
\'C\': [\'C4\', \'C5\', \'C6\', \'C7\'],
\'D\': [\'D4\', \'D5\', \'D6\', \'D7\']},
index=[4, 5, 6, 7])
df3 = pd.DataFrame({\'A\': [\'A8\', \'A9\', \'A10\', \'A11\'],
\'B\': [\'B8\', \'B9\', \'B10\', \'B11\'],
\'C\': [\'C8\', \'C9\', \'C10\', \'C11\'],
\'D\': [\'D8\', \'D9\', \'D10\', \'D11\']},
index=[8, 9, 10, 11])
df4 = pd.DataFrame({\'B\': [\'B2\', \'B3\', \'B6\', \'B7\'],
\'D\': [\'D2\', \'D3\', \'D6\', \'D7\'],
\'F\': [\'F2\', \'F3\', \'F6\', \'F7\']},
index=[2, 3, 6, 7])
result = df1.append([df2,df3])
print(result)

Ignoring indexes on the concatenation axis
结果集中不出现重复的索引序号
result = pd.concat([df1, df4], ignore_index=True) print(result)

DataFrame.append:效果一样
result = df1.append(df4, ignore_index=True) print(result)
Concatenating with mixed ndims
可以对series 和data frames 进行concatenate
s1 = pd.Series([\'X0\', \'X1\', \'X2\', \'X3\'], name=\'X\') result = pd.concat([df1, s1], axis=1) print(result)

如果series没有命名,结果如下
s2 = pd.Series([\'_0\', \'_1\', \'_2\', \'_3\']) result = pd.concat([df1, s2,s2,s2], axis=1) print(result)

when ignore_index=True 所有的命名都会drop
result = pd.concat([df1, s1], axis=1, ignore_index=True) print(result)

More concatenating with group keys
A fairly common use of the keys argument is to override the column names when creating a new DataFrame based on existing Series. Notice how the default behaviour consists on letting the resulting DataFrame inherits the parent Series’ name, when these existed.
s3 = pd.Series([0, 1, 2, 3], name=\'foo\') s4 = pd.Series([0, 1, 2, 3]) s5 = pd.Series([0, 1, 4, 5]) result = pd.concat([s3, s4, s5], axis=1) print(result)
# foo 0 1 #0 0 0 0 #1 1 1 1 #2 2 2 4 #3 3 3 5
可以在concat的时候声明名字
result = pd.concat([s3, s4, s5], axis=1, keys=[\'red\',\'blue\',\'yellow\']) print(result) # red blue yellow #0 0 0 0 #1 1 1 1 #2 2 2 4 #3 3 3 5
frames= [df1,df2,df3] result = pd.concat(frames, keys=[\'x\', \'y\', \'z\']) print(result)

我们可以通过指定dict
result = {\'x\': df1, \'y\': df2, \'z\': df3}
print(result)

pieces = {\'x\': df1, \'y\': df2, \'z\': df3}
result = pd.concat(pieces, keys=[\'z\', \'y\'])
print(result)
Database-style DataFrame joining/merging
pandas has full-featured, high performance in-memory join operations idiomatically very similar to relational databases like SQL. These methods perform significantly better (in some cases well over an order of magnitude better) than other open source implementations (like base::merge.data.frame in R). The reason for this is careful algorithmic design and internal layout of the data in DataFrame.
See the cookbook for some advanced strategies.
Users who are familiar with SQL but new to pandas might be interested in a comparison with SQL.
pandas provides a single function,