ebpf的简单学习
Posted 济南小老虎
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ebpf的简单学习相关的知识,希望对你有一定的参考价值。
ebpf的简单学习-万事开头难
前言
bpf 值得是巴克利包过滤器
他的核心思想是在内核态增加一个可编程的虚拟机.
可以在用户态定义很多规则, 然后直接在内核态进行过滤和使用.
他的效率极高. 因为避免了上下文切换,中断等导致的cycle损失.
很多先进的工具,比如XDP以及K8S的cilium等网络组件.都是基于ebpf而来.
因为bpf最初的寄存器太少,并且仅是实现了包过滤,
ebpf增加了寄存器的数量,实现了更多的功能.
类似于Intel的DPDK工具也是类似的原理,直接用户态操作硬件资源.
工具
ebpf有很多工具. 学习起来也是很痛苦(从春节鸽到现在)
最近实在忍受不了自己的拖沓了, 晚上学习了下简单的bpftrace以及perf-tools.
想着能够简单总结一下, 避免一直不作为.
很多需要写c 代码的地方我不是很熟. 计划今年要进行这一块的深入学习.
安装
bpftrace 需要内核比较新, 建议是 4.15 以上, 越新越好.
perf-tools 是性能大神 Brendan Gregg 编写的一套工具.
yum install bpftrace -y 可以安装对应的一套工具, 在线安装
默认仓库是: AppStream
git clone --depth 1 https://github.com/brendangregg/perf-tools
可以用来安装perf-tools工具
里面有很多类似的工具可以使用. 比如cachetop, cachestat等.
bpftrace的简单用法
bpftrace -e \'uretprobe:/bin/bash:readline printf("%s\\n", str(retval)); \'
如上命令可以跟踪所有的shell脚本读取执行的命令.
效果为:
[root@PG15 bin]# bpftrace -e \'uretprobe:/bin/bash:readline printf("%s\\n", str(retval)); \'
Attaching 1 probe...
ping 8.8.8.8
ifconfig
bpftrace的说明
bpftrace 其实是一种调试分析程序的方法
不同于测试环境可以debug. 生产环境基本上没有debug的条件:
1. 现在很多镜像部署, 都是最小化打包,一方面提高性能,减少内存占用, 另一方面减少磁盘文件大小,减少镜像大小.
2. debug的断点会导致生产环境卡顿, 只要不是有受虐倾向的客户(或者是喝茶看报纸的客户)都会大为光火
所以bpftrace可能就是一个很好的解决方案了.
但是bpftrace需要对产生异常的代码非常熟悉,要了解到具体产生异常的系统调用.
有时需要使用 readelf等方式获取具体的调用才可以.
方法比较复杂, 我这边还没入门, 也没法详细解释了.
perf-tools
Brendan Gregg 大神的工具集.
注意perf-tools不区分架构, arm和x86都可以使用. 主要是脚本为主.
cachestat cachetop 是几个比较基本的命令
注意部分工具需要安装 yum install perf 才可以使用
需要说明, x86都可以进行使用, 但是arm的很多命令存在异常, 需要修复.
举例
./syscount
control + c 会出现如下的信息.
[ perf record: Captured and wrote 3.537 MB perf.data (27102 samples) ]
COMM COUNT
rpcbind 1
lsmd 4
gmain 12
sssd_be 12
sshd 18
perf 25
NetworkManager 55
in:imjournal 56
sssd_nss 264
tuned 1167
redis-server 1255
aliyun-service 1621
AliYunDunUpdate 1721
AliYunDun 20891
可以参考火焰图进行生成.
Linux内核 eBPF基础:BCC (BPF Compiler Collection)
目录
BPF Compiler Collection (BCC)是基于eBPF的Linux内核分析、跟踪、网络监控工具。其源码存放于iovisor/bcc。
BCC包括的一些工具
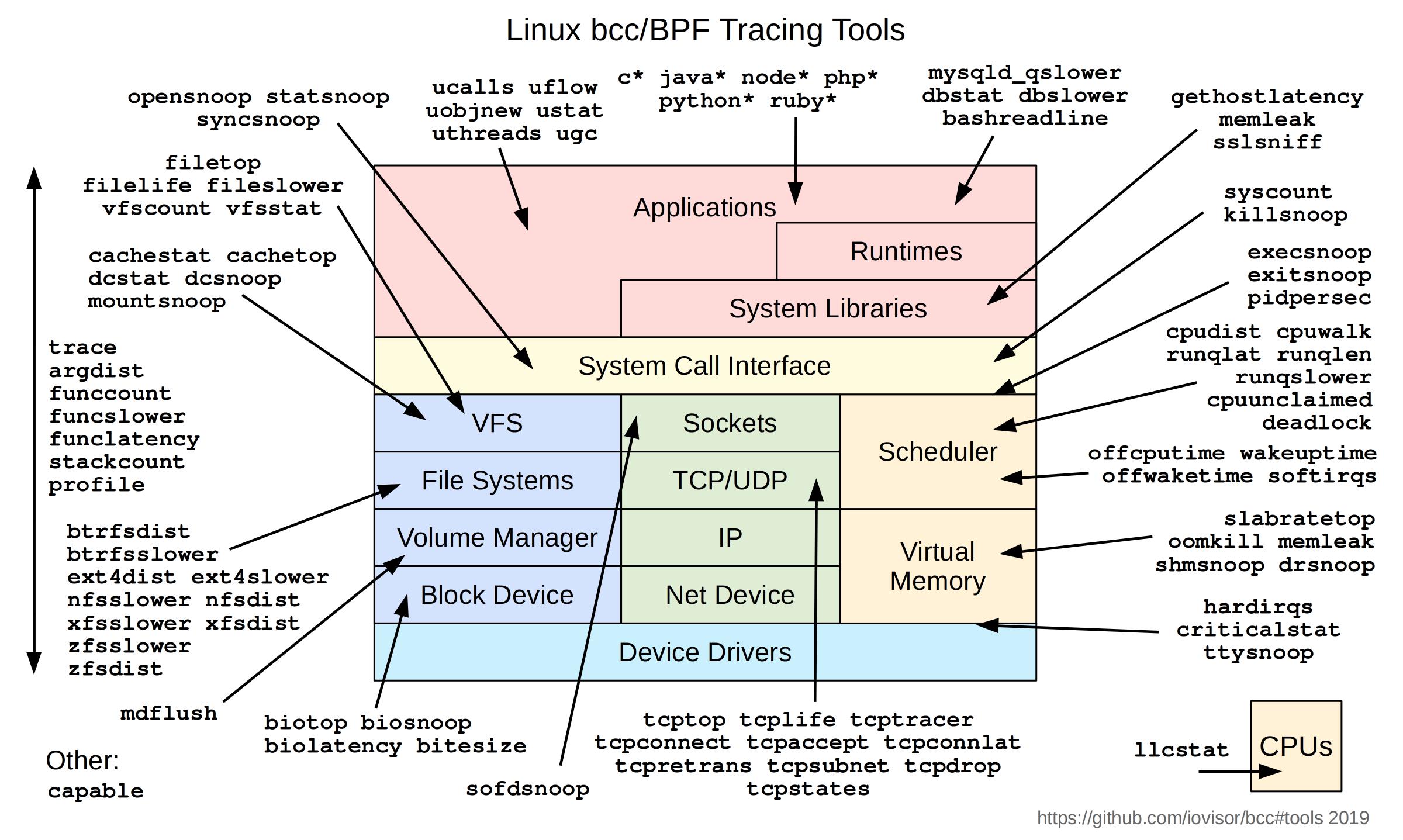
http://www.brendangregg.com/ebpf.html
安装BCC
Ubuntu:
echo "deb [trusted=yes] https://repo.iovisor.org/apt/xenial xenial-nightly main" | sudo tee /etc/apt/sources.list.d/iovisor.list
sudo apt-get update
sudo apt-get install -y bcc-tools libbcc-examples python-bcc
CentOS:
echo -e '[iovisor]\\nbaseurl=https://repo.iovisor.org/yum/nightly/f23/$basearch\\nenabled=1\\ngpgcheck=0' | sudo tee /etc/yum.repos.d/iovisor.repo
yum install -y bcc-tools
安装完成后,bcc工具会放到/usr/share/bcc/tools目录中
$ ls /usr/share/bcc/tools
argdist cachestat ext4dist hardirqs offwaketime softirqs tcpconnect vfscount
bashreadline cachetop ext4slower killsnoop old solisten tcpconnlat vfsstat
biolatency capable filelife llcstat oomkill sslsniff tcplife wakeuptime
biosnoop cpudist fileslower mdflush opensnoop stackcount tcpretrans xfsdist
biotop dcsnoop filetop memleak pidpersec stacksnoop tcptop xfsslower
bitesize dcstat funccount mountsnoop profile statsnoop tplist zfsdist
btrfsdist doc funclatency mysqld_qslower runqlat syncsnoop trace zfsslower
btrfsslower execsnoop gethostlatency offcputime slabratetop tcpaccept ttysnoop
常用工具示例
capable
capable检查Linux进程的security capabilities:
$ capable
TIME UID PID COMM CAP NAME AUDIT
22:11:23 114 2676 snmpd 12 CAP_NET_ADMIN 1
22:11:23 0 6990 run 24 CAP_SYS_RESOURCE 1
22:11:23 0 7003 chmod 3 CAP_FOWNER 1
22:11:23 0 7003 chmod 4 CAP_FSETID 1
22:11:23 0 7005 chmod 4 CAP_FSETID 1
22:11:23 0 7005 chmod 4 CAP_FSETID 1
22:11:23 0 7006 chown 4 CAP_FSETID 1
22:11:23 0 7006 chown 4 CAP_FSETID 1
22:11:23 0 6990 setuidgid 6 CAP_SETGID 1
22:11:23 0 6990 setuidgid 6 CAP_SETGID 1
22:11:23 0 6990 setuidgid 7 CAP_SETUID 1
22:11:24 0 7013 run 24 CAP_SYS_RESOURCE 1
22:11:24 0 7026 chmod 3 CAP_FOWNER 1
[...]
tcpconnect
tcpconnect检查活跃的TCP连接,并输出源和目的地址:
$ ./tcpconnect
PID COMM IP SADDR DADDR DPORT
2462 curl 4 192.168.1.99 74.125.23.138 80
tcptop
tcptop统计TCP发送和接受流量:
$ ./tcptop -C 1 3
Tracing... Output every 1 secs. Hit Ctrl-C to end
08:06:45 loadavg: 0.04 0.01 0.00 2/174 3099
PID COMM LADDR RADDR RX_KB TX_KB
1740 sshd 192.168.1.99:22 192.168.0.29:60315 0 0
08:06:46 loadavg: 0.04 0.01 0.00 2/174 3099
PID COMM LADDR RADDR RX_KB TX_KB
1740 sshd 192.168.1.99:22 192.168.0.29:60315 0 0
08:06:47 loadavg: 0.04 0.01 0.00 2/174 3099
PID COMM LADDR RADDR RX_KB TX_KB
1740 sshd 192.168.1.99:22 192.168.0.29:60315 0 0
扩展工具
基于eBPF和bcc,可以很方便的扩展功能。bcc目前支持以下事件
kprobe__kernel_function_name(BPF.attach_kprobe())kretprobe__kernel_function_name(BPF.attach_kretprobe())TRACEPOINT_PROBE(category, event),支持的event列表参见/sys/kernel/debug/tracing/events/category/event/formatBPF.attach_uprobe()和BPF.attach_uretprobe()- 用户自定义探针(USDT)
USDT.enable_probe()
简单示例
#!/usr/bin/env python
from __future__ import print_function
from bcc import BPF
text='int kprobe__sys_sync(void *ctx) { bpf_trace_printk("Hello, World!\\\\n"); return 0; }'
prog="""
int hello(void *ctx) {
bpf_trace_printk("Hello, World!\\\\n");
return 0;
}
"""
b = BPF(text=prog)
b.attach_kprobe(event="sys_clone", fn_name="hello")
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMM", "PID", "MESSAGE"))
while True:
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
except ValueError:
continue
print("%-18.9f %-16s %-6d %s" % (ts, task, pid, msg))
使用BPF_PERF_OUTPUT
from __future__ import print_function
from bcc import BPF
import ctypes as ct
# load BPF program
b = BPF(text="""
struct data_t {
u64 ts;
};
BPF_PERF_OUTPUT(events);
void kprobe__sys_sync(void *ctx) {
struct data_t data = {};
data.ts = bpf_ktime_get_ns() / 1000;
events.perf_submit(ctx, &data, sizeof(data));
};
""")
class Data(ct.Structure):
_fields_ = [
("ts", ct.c_ulonglong)
]
# header
print("%-18s %s" % ("TIME(s)", "CALL"))
# process event
def print_event(cpu, data, size):
event = ct.cast(data, ct.POINTER(Data)).contents
print("%-18.9f sync()" % (float(event.ts) / 1000000))
# loop with callback to print_event
b["events"].open_perf_buffer(print_event)
while True:
b.kprobe_poll()
更多的示例参考bbc/docs/tutorial_bcc_python_developer.md。
用户自定义探针示例
from __future__ import print_function
from bcc import BPF
from time import strftime
import ctypes as ct
# load BPF program
bpf_text = """
#include <uapi/linux/ptrace.h>
struct str_t {
u64 pid;
char str[80];
};
BPF_PERF_OUTPUT(events);
int printret(struct pt_regs *ctx) {
struct str_t data = {};
u32 pid;
if (!PT_REGS_RC(ctx))
return 0;
pid = bpf_get_current_pid_tgid();
data.pid = pid;
bpf_probe_read(&data.str, sizeof(data.str), (void *)PT_REGS_RC(ctx));
events.perf_submit(ctx,&data,sizeof(data));
return 0;
};
"""
STR_DATA = 80
class Data(ct.Structure):
_fields_ = [
("pid", ct.c_ulonglong),
("str", ct.c_char * STR_DATA)
]
b = BPF(text=bpf_text)
b.attach_uretprobe(name="/bin/bash", sym="readline", fn_name="printret")
# header
print("%-9s %-6s %s" % ("TIME", "PID", "COMMAND"))
def print_event(cpu, data, size):
event = ct.cast(data, ct.POINTER(Data)).contents
print("%-9s %-6d %s" % (strftime("%H:%M:%S"), event.pid, event.str))
b["events"].open_perf_buffer(print_event)
while 1:
b.kprobe_poll()
# ./bashreadline
TIME PID COMMAND
08:22:44 2070 ls /
08:22:56 2070 ping -c3 google.com
# ./gethostlatency
TIME PID COMM LATms HOST
08:23:26 3370 ping 2.00 google.com
08:23:37 3372 ping 56.00 baidu.com
参考
- iovisor.org
- iovisor.org - ebpf
- iovisor.org - xdp
- iovisor/bpf-docs
- kernel.org - filter
- iovisor-lc-bof-2016
- BPF Internals – II
- Dive into BPF: a list of reading material
- cilium/cilium
以上是关于ebpf的简单学习的主要内容,如果未能解决你的问题,请参考以下文章