python搜索引擎和框架
Posted C-C
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python搜索引擎和框架相关的知识,希望对你有一定的参考价值。
1.安装全文检索包
# 全文检索框架
pip install django-haystack
# 全文检索引擎
pip install whoosh
# 中文分词框架
pip install jiebaheystack一些配置都是固定写好的,需要注意下
2.配置全文检索
-
1.安装haystack应用
INSTALLED_APPS = ( ... \'haystack\', ) -
2.在settings.py文件中配置搜索引擎
# 配置搜索引擎后端 HAYSTACK_CONNECTIONS = { \'default\': { # 使用whoosh引擎:提示,如果不需要使用jieba框架实现分词,就使用whoosh_backend \'ENGINE\': \'haystack.backends.whoosh_cn_backend.WhooshEngine\', # 索引文件路径 \'PATH\': os.path.join(BASE_DIR, \'whoosh_index\'), # 在项目目录下创建文件夹 whoosh_index } } # 当添加、修改、删除数据时,自动生成索引 HAYSTACK_SIGNAL_PROCESSOR = \'haystack.signals.RealtimeSignalProcessor\' - 3.在要建立索引的表对应的应用下,创建
search_indexes.py文件 -
-
-
定义商品索引类
GoodsSKUIndex(),继承自indexes.SearchIndex和indexes.Indexable -
from haystack import indexes
from .models import GoodsSKU
class GoodsSKUIndex(indexes.SearchIndex, indexes.Indexable):
# 定义字符类型的属性,名称固定为text
# document=True表示建立的索引数据存储到文件中
# use_template=True表示通过模板指定表中的字段,用于查询
text = indexes.CharField(document=True, use_template=True)# 针对哪张表进行查询
def get_model(self):
return GoodsSKU# 针对哪些行进行查询
def index_queryset(self, using=None):
return self.get_model().objects.filter(isDelete=False)
-
-
-
4.指定要建立索引的字段
-
在
templates下面新建目录search/indexes/应用名- 比如
goods应用中的GoodsSKU模型类中的字段要建立索引文件夹:search/indexes/goods -
在新建目录下,创建
goodssku_text.txt,并编辑要建立索引的字段,如下图 -
templates/search/indexes/goods/goodssku_text_txt
- 比如
-
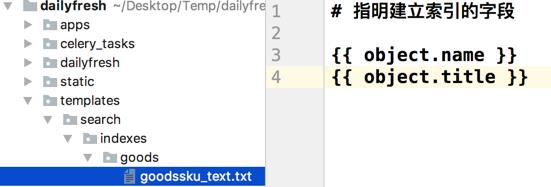
-
5.生成索引文件
- # 在终端运行, 提示是否要删除原有信息, 输入y
-
python manage.py rebuild_index -
-
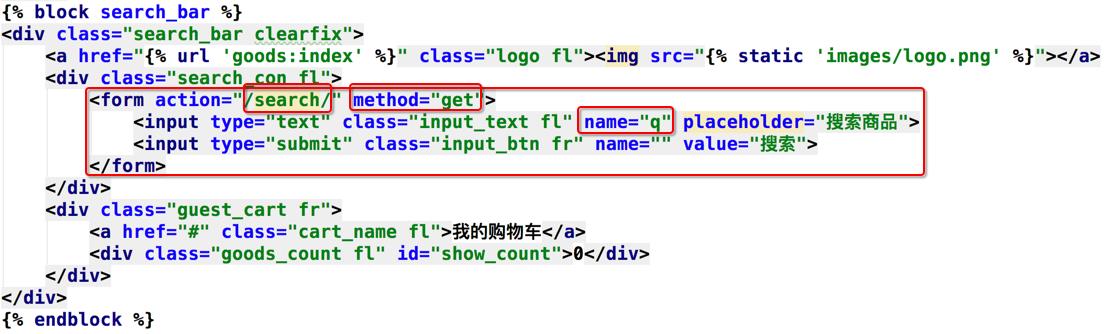
搜索表单处理
- 搜索地址:
/search/ - 搜索方法:
get 接收关键字:q- action="/search/" method="get" 文本框的name= "q" 为固定写法
- 搜索地址:
配置搜索地址正则
import haystack.urls
url(r\'^search/\', include(haystack.urls)),
测试搜索效果,接收结果
-
全文检索结果:
- 搜索出结果后,haystack会把搜索出的结果传递给
templates/search目录下的search.html - 对于
search.html,我们需要自己建立该html文件,并定义自己的搜索结果页面
- 搜索出结果后,haystack会把搜索出的结果传递给
-
传递的上下文包括:
- query:搜索关键字
- page:当前页的page对象
- paginator:分页paginator对象
- 提示:
settings.py文件中设置HAYSTACK_SEARCH_RESULTS_PER_PAGE- 通过
HAYSTACK_SEARCH_RESULTS_PER_PAGE可以控制每页显示数量 - 每页显示一条数据:
HAYSTACK_SEARCH_RESULTS_PER_PAGE = 1
-
search.html编写,类似商品列表页面
以上是关于python搜索引擎和框架的主要内容,如果未能解决你的问题,请参考以下文章