mysql 内存表和一般表的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql 内存表和一般表的区别相关的知识,希望对你有一定的参考价值。
我们仍然使用两个会话,一个会话 run,用于运行主 SQL;另一个会话 ps,用于进行 performance_schema 的观察:
主会话线程号为 29,
将 performance_schema 中的统计量重置,
临时表的表大小限制取决于参数 tmp_table_size 和 max_heap_table_size 中较小者,我们实验中以设置 max_heap_table_size 为例。
我们将会话级别的临时表大小设置为 2M(小于上次实验中临时表使用的空间),执行使用临时表的 SQL:
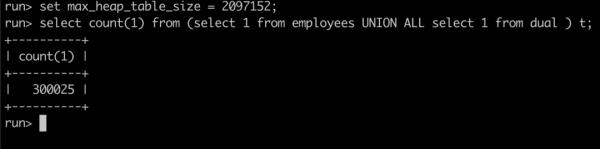
查看内存的分配记录:

会发现内存分配略大于 2M,我们猜测临时表会比配置略多一点消耗,可以忽略。
查看语句的特征值: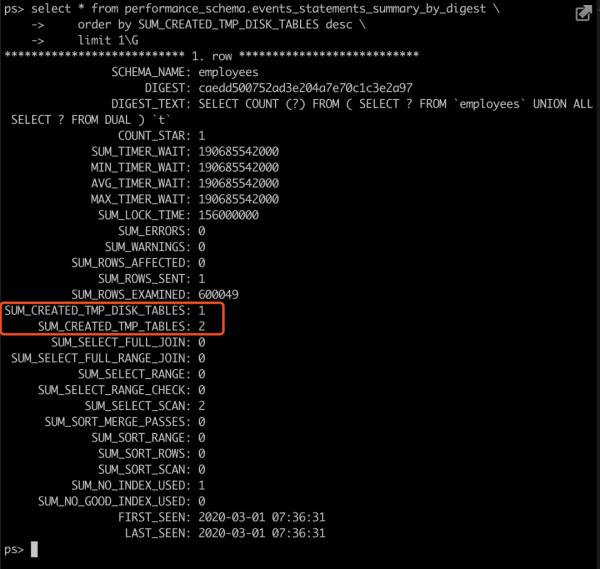
可以看到语句使用了一次需要落磁盘的临时表。
那么这张临时表用了多少的磁盘呢?
我们开启 performance_schema 中 waits 相关的统计项:
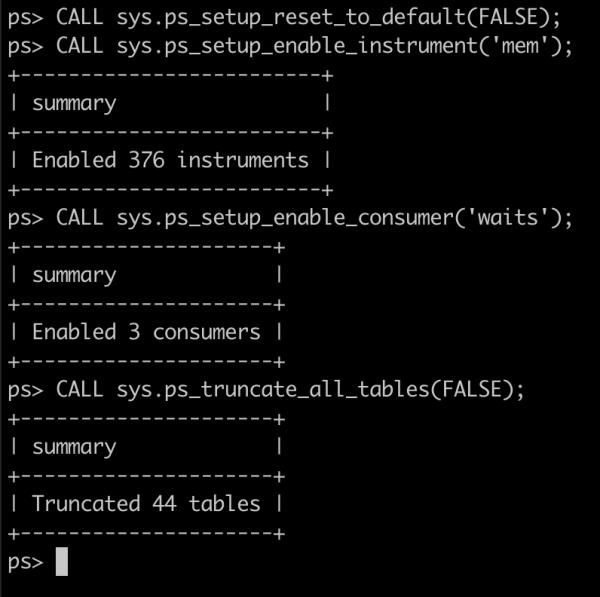
重做实验,略过。
再查看 performance_schema 的统计值:
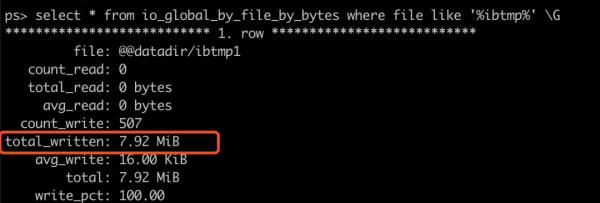
可以看到几个现象:
1. 临时表空间被写入了 7.92MiB 的数据。
2. 这些数据是语句写入后,慢慢逐渐写入的。
来看看这些写入操作的特征,该方法我们在 实验 03 使用过: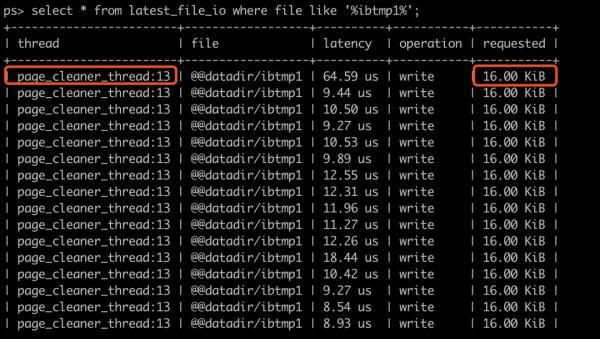
可以看到写入的线程是 page_clean_thread,是一个刷脏操作,这样就能理解数据为什么是慢慢写入的。
也可以看到每个 IO 操作的大小是 16K,也就是刷数据页的操作。
结论:
我们可以看到,
1. MySQL 会基本遵守 max_heap_table_size 的设定,在内存不够用时,直接将表转到磁盘上存储。
2. 由于引擎不同(内存中表引擎为 heap,磁盘中表引擎则跟随 internal_tmp_disk_storage_engine 的配置),本次实验写磁盘的数据量和 实验 05 中使用内存的数据量不同。
3. 如果临时表要使用磁盘,表引擎配置为 InnoDB,那么即使临时表在一个时间很短的 SQL 中使用,且使用后即释放,释放后也会刷脏页到磁盘中,消耗部分 IO。
参考技术A 内存表,就是放在内存中的表,所使用内存的大小可通过My.cnf中的max_heap_table_size指定,如max_heap_table_size=1024M,内存表与临时表并不相同,临时表也是存放在内存中,临时表最大所需内存需要通过tmp_table_size =128M设定。当数据超过临时表的最大值设定时,自动转为磁盘表,此时因需要进行IO操作,性能会大大下降,而内存表不会,内存表满后,会提示数据满错误。临时表和内存表都可以人工创建,但临时表更多的作用是系统自己创建后,组织数据以提升性能,如子查询,临时表在多个连接之间不能共享。本回答被提问者和网友采纳
链表和顺序表的一些区别
顺序表与链表是非常基本的数据结构,它们可以被统称为线性表。
线性表(Linear List)是由 n(n≥0)个数据元素(结点)a[0],a[1],a[2]…,a[n-1] 组成的有限序列。
顺序表和链表,是线性表的不同存储结构。它们各自有不同的特点和适用范围。针对它们各自的缺点,也有很多改进的措施。
一、顺序表
顺序表一般表现为数组,使用一组地址连续的存储单元依次存储数据元素,如图 1 所示。它具有如下特点:
- 长度固定,必须在分配内存之前确定数组的长度。
- 存储空间连续,即允许元素的随机访问。
- 存储密度大,内存中存储的全部是数据元素。
- 要访问特定元素,可以使用索引访问,时间复杂度为 。
- 要想在顺序表中插入或删除一个元素,都涉及到之后所有元素的移动,因此时间复杂度为 。
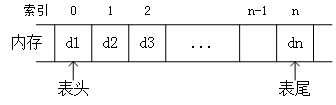
图 1 顺序表
顺序表最主要的问题就是要求长度是固定的,可以使用倍增-复制的办法来支持动态扩容,将顺序表变成“可变长度”的。
具体做法是初始情况使用一个初始容量(可以指定)的数组,当元素个数超过数组的长度时,就重新申请一个长度为原先二倍的数组,并将旧的数据复制过去,这样就可以有新的空间来存放元素了。这样,列表看起来就是可变长度的。
一个简单的实现如下所示,初始的容量为 4。
#include <string.h>
struct sqlist {
int *items, size, capacity;
sqlist():size(0), capacity(4) {
// initial capacity = 4
items = new int[capacity];
}
void doubleCapacity() {
capacity *= 2;
int* newItems = new int[capacity];
memcpy(newItems, items, sizeof(int)*size);
delete[] items;
items = newItems;
}
void add(int value) {
if (size >= capacity) {
doubleCapacity();
}
items[size++] = value;
}
};这个办法不可避免的会浪费一些内存,因为数组的容量总是倍增的。而且每次扩容的时候,都需要将旧的数据全部复制一份,肯定会影响效率。不过实际上,这样做还是直接使用链表的效率要高,具体原因会在下一节进行分析。
二、链表
链表,类似它的名字,表中的每个节点都保存有指向下一个节点的指针,所有节点串成一条链。根据指针的不同,还有单链表、双链表和循环链表的区分,如图 2 所示。
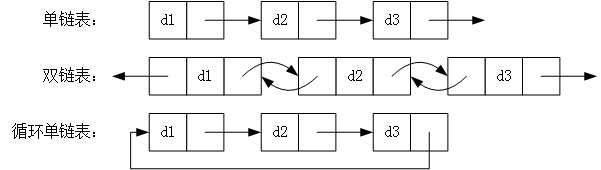
单链表是只包含指向下一个节点的指针,只能单向遍历。
双链表即包含指向下一个节点的指针,也包含指向前一个节点的指针,因此可以双向遍历。
循环单链表则是将尾节点与首节点链接起来,形成了一个环状结构,在某些情况下会非常有用。
还有循环双链表,与循环单链表类似,这里就不再赘述。
由于链表是使用指针将节点连起来,因此无需使用连续的空间,它具有以下特点:
- 长度不固定,可以任意增删。
- 存储空间不连续,数据元素之间使用指针相连,每个数据元素只能访问周围的一个元素(根据单链表还是双链表有所不同)。
- 存储密度小,因为每个数据元素,都需要额外存储一个指向下一元素的指针(双链表则需要两个指针)。
- 要访问特定元素,只能从链表头开始,遍历到该元素,时间复杂度为 。
- 在特定的数据元素之后插入或删除元素,不涉及到其他元素的移动,因此时间复杂度为 。双链表还允许在特定的数据元素之前插入或删除元素。
在上一节说到,利用倍增-复制的办法,同样可以让顺序表长度可变,而且效率比链表还要好,下面就简单的实现一个单链表来验证这一点,至于元素插入的顺序就不要在意了。
#include <stdio.h>
#include <time.h>
struct node {
int value;
node *next;
};
struct llist {
node *head;
void add(int value) {
node *newNode = new node();
newNode->value = value;
newNode->next = head;
head = newNode;
}
};
int main() {
int size = 100000;
sqlist list1;
llist list2;
long start = clock();
for (int i = 0;i < size;i++) {
list1.add(i);
}
long end = clock();
printf("sequence list: %d
", end - start);
start = clock();
for (int i = 0;i < size;i++) {
list2.add(i);
}
end = clock();
printf("linked list: %d
", end - start);
return 0;
}在我的电脑上,链表的耗时大约是顺序表的 4~8 倍。会这样,是因为数组只需要很少的几次大块内存分配,而链表则需要很多次小块内存分配,内存分配操作相对是比较慢的,因而大大拖慢了链表的速度。这也是为什么会出现内存池。
因此,链表并不像理论分析的那样美好,在实际应用中要受很多条件制约,一般情况下还是安心用顺序表的好。
以上是关于mysql 内存表和一般表的区别的主要内容,如果未能解决你的问题,请参考以下文章