Python格式化操作符:%
Posted Volcano!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python格式化操作符:%相关的知识,希望对你有一定的参考价值。
在编写程序的过程中,经常需要进行格式化输出,每次用每次查。干脆就在这里整理一下,以便索引。
格式化操作符(%)
"%"是Python风格的字符串格式化操作符,非常类似C语言里的printf()函数的字符串格式化(C语言中也是使用%)。
下面整理了一下Python中字符串格式化符合:
|
格式化符号 |
说明 |
|
%c |
转换成字符(ASCII 码值,或者长度为一的字符串) |
|
%r |
优先用repr()函数进行字符串转换 |
|
%s |
优先用str()函数进行字符串转换 |
|
%d / %i |
转成有符号十进制数 |
|
%u |
转成无符号十进制数 |
|
%o |
转成无符号八进制数 |
|
%x / %X |
转成无符号十六进制数(x / X 代表转换后的十六进制字符的大小写) |
|
%e / %E |
转成科学计数法(e / E控制输出e / E) |
|
%f / %F |
转成浮点数(小数部分自然截断) |
|
%g / %G |
%e和%f / %E和%F 的简写 |
|
%% |
输出% (格式化字符串里面包括百分号,那么必须使用%%) |
这里列出的格式化符合都比较简单,唯一想要强调一下的就是"%s"和"%r"的差别。
看个简单的代码:
string = "Hello\\tWill\\n" print "%s" %string print "%r" %string
代码的输出为:

其实,这里的差异是str()和repr()两个内建函数之间的差异:
- str()得到的字符串是面向用户的,具有较好的可读性
-
repr()得到的字符串是面向机器的
- 通常(不是所有)repr()得到的效果是:obj == eval(repr(obj))
格式化操作符辅助符
通过"%"可以进行字符串格式化,但是"%"经常会结合下面的辅助符一起使用。
|
辅助符号 |
说明 |
|
* |
定义宽度或者小数点精度 |
|
- |
用做左对齐 |
|
+ |
在正数前面显示加号(+) |
|
# |
在八进制数前面显示零(0),在十六进制前面显示"0x"或者"0X"(取决于用的是"x"还是"X") |
|
0 |
显示的数字前面填充"0"而不是默认的空格 |
|
(var) |
映射变量(通常用来处理字段类型的参数) |
|
m.n |
m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
看一些简单的 例子:

num = 100
print "%d to hex is %x" %(num, num)
print "%d to hex is %X" %(num, num)
print "%d to hex is %#x" %(num, num)
print "%d to hex is %#X" %(num, num)
# 浮点数
f = 3.1415926
print "value of f is: %.4f" %f
# 指定宽度和对齐
students = [{"name":"Wilber", "age":27}, {"name":"Will", "age":28}, {"name":"June", "age":27}]
print "name: %10s, age: %10d" %(students[0]["name"], students[0]["age"])
print "name: %-10s, age: %-10d" %(students[1]["name"], students[1]["age"])
print "name: %*s, age: %0*d" %(10, students[2]["name"], 10, students[2]["age"])
# dict参数
for student in students:
print "%(name)s is %(age)d years old" %student
代码输出为:
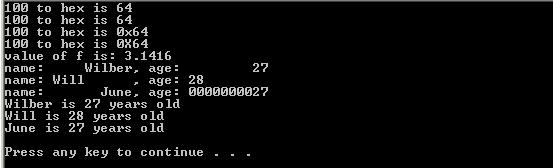
对于Python的格式化操作符,不仅可以接受tuple类型的参数,也可以支持dict,象上面代码的最后一部分,那么格式化字符串中就可以直接使用"%(key)s"(这里的s根据具体类型改变)的方式表示dict中对应的value了。
字符串模板
其实,在Python中进行字符串的格式化,除了格式化操作符,还可以使用string模块中的字符串模板(Template)对象。下面就主要看看Template对象的substitute()方法:
from string import Template
s = Template("Hi, $name! $name is learning $language")
print s.substitute(name="Wilber", language="Python")
d = {"name": "Will", "language": "C#"}
print s.substitute(d)
# 用$$表示$符号
s = Template("This book ($bname) is 17$$")
print s.substitute(bname="TCP/IP")
代码结果为:

字符串内建函数format()
Python2.6开始,新增了一种格式化字符串的函数str.format(),通过这个函数同样可以对字符串进行格式化处理。在format()函数中,使用“{}”符号来当作格式化操作符。
下面直接通过一些简单的例子演示format()函数的基本使用:
# 位置参数
print "{0} is {1} years old".format("Wilber", 28)
print "{} is {} years old".format("Wilber", 28)
print "Hi, {0}! {0} is {1} years old".format("Wilber", 28)
# 关键字参数
print "{name} is {age} years old".format(name = "Wilber", age = 28)
# 下标参数
li = ["Wilber", 28]
print "{0[0]} is {0[1]} years old".format(li)
# 填充与对齐
# ^、<、>分别是居中、左对齐、右对齐,后面带宽度
# :号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充
print \'{:>8}\'.format(\'3.14\')
print \'{:<8}\'.format(\'3.14\')
print \'{:^8}\'.format(\'3.14\')
print \'{:0>8}\'.format(\'3.14\')
print \'{:a>8}\'.format(\'3.14\')
# 浮点数精度
print \'{:.4f}\'.format(3.1415926)
print \'{:0>10.4f}\'.format(3.1415926)
# 进制
# b、d、o、x分别是二进制、十进制、八进制、十六进制
print \'{:b}\'.format(11)
print \'{:d}\'.format(11)
print \'{:o}\'.format(11)
print \'{:x}\'.format(11)
print \'{:#x}\'.format(11)
print \'{:#X}\'.format(11)
# 千位分隔符
print \'{:,}\'.format(15700000000)
str的内建函数
在最开始的时候,Python有一个专门的string模块,要使用string的方法要先import这个模块。从Python2.0开始, 为了方便使用,str类型添加了很多内建函数,这些函数可以实现跟string模块中函数相同的功能,也就是说,只要S是一个字符串对象就可以直接使用内建函数,而不用import。
对于字符串的格式化处理,也可以考虑使用str的其他内建函数:
>>> dir(str) [\'__add__\', \'__class__\', \'__contains__\', \'__delattr__\', \'__doc__\', \'__eq__\', \'__ format__\', \'__ge__\', \'__getattribute__\', \'__getitem__\', \'__getnewargs__\', \'__get slice__\', \'__gt__\', \'__hash__\', \'__init__\', \'__le__\', \'__len__\', \'__lt__\', \'__mo d__\', \'__mul__\', \'__ne__\', \'__new__\', \'__reduce__\', \'__reduce_ex__\', \'__repr__\', \'__rmod__\', \'__rmul__\', \'__setattr__\', \'__sizeof__\', \'__str__\', \'__subclasshook __\', \'_formatter_field_name_split\', \'_formatter_parser\', \'capitalize\', \'center\', \'count\', \'decode\', \'encode\', \'endswith\', \'expandtabs\', \'find\', \'format\', \'index \', \'isalnum\', \'isalpha\', \'isdigit\', \'islower\', \'isspace\', \'istitle\', \'isupper\', \'join\', \'ljust\', \'lower\', \'lstrip\', \'partition\', \'replace\', \'rfind\', \'rindex\', \' rjust\', \'rpartition\', \'rsplit\', \'rstrip\', \'split\', \'splitlines\', \'startswith\', \' strip\', \'swapcase\', \'title\', \'translate\', \'upper\', \'zfill\']
下面整理出来了一些常用的str类型的内建函数:
# 小写 S.lower() # 大写 S.upper() #大小写互换 S.swapcase() # 首字母大写 S.capitalize() # 输出width个字符,S左对齐,不足部分用fillchar填充,默认的为空格。 S.ljust(width,[fillchar]) # 右对齐 S.rjust(width,[fillchar]) # 中间对齐 S.center(width, [fillchar]) # 返回S中出现substr的第一个字母的标号,如果S中没有substr则返回-1。start和end作用就相当于在S[start:end]中搜索 S.find(substr, [start, [end]]) # 返回S中最后出现的substr的第一个字母的标号,如果S中没有substr则返回-1,也就是说从右边算起的第一次出现的substr的首字母标号 S.rfind(substr, [start, [end]]) # 计算substr在S中出现的次数 S.count(substr, [start, [end]]) #把S中的oldstar替换为newstr,count为替换次数 S.replace(oldstr, newstr, [count]) # 把S中前后chars中有的字符全部去掉,可以理解为把S前后chars替换为None S.strip([chars]) S.lstrip([chars]) S.rstrip([chars]) # 以sep为分隔符,把S分成一个list。maxsplit表示分割的次数。默认的分割符为空白字符 S.split([sep, [maxsplit]]) # 把seq代表的字符串序列,用S连接起来 S.join(seq)
总结
本文整理了一些格式化字符,以及一些辅助指令,结合格式化操作符(%),就可以生成特定格式的字符串了。也可以使用字符串模板来进行字符串格式化。
以上是关于Python格式化操作符:%的主要内容,如果未能解决你的问题,请参考以下文章
如何在 Javadoc 中使用 @ 和 符号格式化代码片段?
[未解决问题记录]python asyncio+aiohttp出现Exception ignored:RuntimeError('Event loop is closed')(代码片段