Python基础 (下)
Posted 安小
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础 (下)相关的知识,希望对你有一定的参考价值。
参考:菜鸟教程
目录
一、读写文件
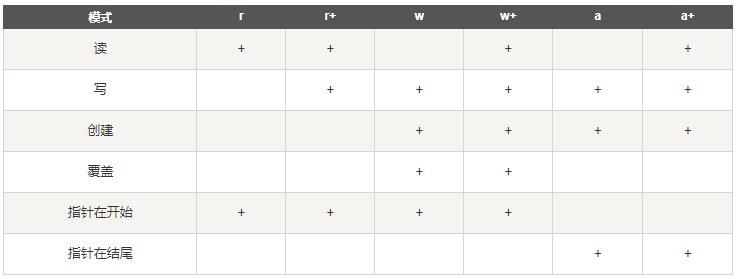
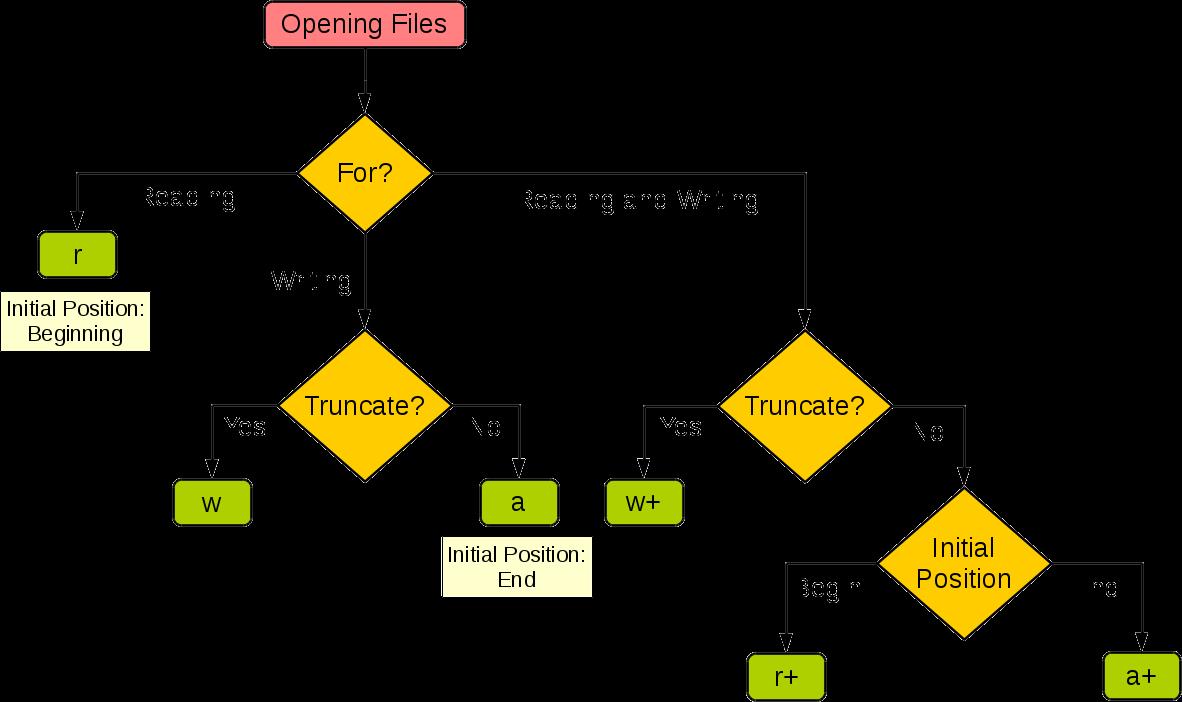
1. 打开文件: open(filename, mode)。 mode有如下几种模式,默认为只读(r)。
2. 写入文件
f = open("/home/test.txt", "w") # write(s) 将s写入到文件中, 然后返回写入的字符数 num = f.write("Come on baby!\\n Let\'s go party") print(num) # 写入非字符串数据, 需要类型转化 value = (\'amy\', 14, \'China\') s = str(value) f.write(s) # writelines(seq) 向文件中写入一个字符串列表 seq = ["Come on baby\\n", "Let\'s go party"] f.writelines(seq) f.close()
3. 读取文件
f = open("/home/test.txt", "r") str = f.read() # f.read(size) 读取指定的字节数, 如果未给定或为负则读取所有内容。 str = f.readline() # f.readline(size) 读取一行,包括\'\\n\'字符。 当返回一个空字符串, 说明已经读取到最后一行。 str = f.readlines() # f.readlines(sizeint) 读取所有行,如果设置可选参数sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。 print(str) # 迭代文件对象然后读取每行 for line in f: print(line, end=\'\') f.close()
4. 移动文件位置
seek(offset, from_what) 改变文件当前的位置 from_what为0表示从文件开头移动, 1表示当前位置, 2表示文件的结尾,默认为0
seek(x,0) : 从起始位置即文件首行首字符开始移动x个字符
seek(x,1) : 表示从当前位置往后移动x个字符
seek(-x,2):表示从文件的结尾往前移动x个字符
f = open(\'/home/test.txt\', \'rb+\') f.write(b\'0123456789abcdef\') f.tell() # 16 返回文件对象当前所处的位置 f.seek(5) # 移动到文件的第六个字节 f.read(1) # b\'5\' f.seek(-3, 2) # 移动到文件的倒数第三字节 f.read(1) # b\'d\' f.close()
5. pickle模块 - 对象序列化
a. 将数据对象保存到文件
import pickle data1 = {\'a\': [1, 2.0, 3, 4+6j], \'b\': (\'string\', u\'Unicode string\'), \'c\': None} list1 = [1, 2, 3] list1.append(list1) f = open(\'data.pkl\', \'wb\') pickle.dump(data1, f) # 使用 protocol 0 pickle.dump(list1, f, -1) # 使用最高的协议 f.close()
b. 从文件中重构python对象
import pprint, pickle f = open(\'data.pkl\', \'rb\') data1 = pickle.load(f) pprint.pprint(data1) f.close()
6. 其他方法
# flush()方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。 # 一般情况下,文件关闭后会自动刷新缓冲区,但有时你需要在关闭前刷新它,这时就可以使用 flush() 方法。 f.flush() # isatty()检测文件是否连接到一个终端设备,如果是返回True,否则返回False ret = f.isatty() # False # fileno()方法返回一个整型的文件描述符,可用于底层操作系统的I/O操作。 fid = f.fileno() # 文件描述符为 3 # next()获取下一行 line = next(f) # truncate(size)从文件头开始截取size个字符,无size表示从截取当前位置到文件末的字符 f = open(\'C:/Users/HuangAm/test.txt\', \'r+\') line = f.readline() # 1.apple 读取一行 f.truncate() line = f.readlines() # [\'2.apple\\n\', \'3.apple\'] 从当前读取到文件结束 f.seek(0) f.truncate(5) line = f.readlines() # [\'1.app\'] 截取5个字符 f.close()
7. OS 文件/目录方法
os 模块提供了非常丰富的方法用来处理文件和目录。参考
二、错误和异常
1. 异常处理
import sys try: f = open(\'myfile.txt\') s = f.readline() i = int(s.strip()) raise NameError(\'Hi there\') # raise语句抛出一个指定的异常, 它必须是一个异常的实例或者是异常的类(即Exception的子类) except OSError as err: print("OS error: {0}".format(err)) except ValueError: print("Could not convert data to an integer.") except: print("Unexpected error:", sys.exc_info()[0]) raise else: # else在try语句没有发生任何异常的时候执行 print("No error!") f.close()
2. 用户自定义异常
可以通过创建一个新的exception类来拥有自己的异常,异常应该继承自 Exception 类。当创建一个模块有可能抛出多种不同的异常时,一种通常的做法是为这个包建立一个基础异常类,然后基于这个基础类为不同的错误情况创建不同的子类。
class Error(Exception): # 异常的基类 pass class InputError(Error): def __init__(self, expression, message): self.expression = expression self.message = message class TransitionError(Error): def __init__(self, previous, next, message): self.previous = previous self.next = next self.message = message try: raise InputError(2*2, "InputError") except MyError as e: print(\'My exception occurred:\', e)
3. 定义清理行为
try 子句里面有没有发生异常,finally 子句都会执行。如果一个异常在 try 子句里(或者在 except 和 else 子句里)被抛出,而又没有任何的 except 把它截住,那么这个异常会在 finally 子句执行后再次被抛出。
def divide(x, y): try: result = x / y except ZeroDivisionError: print("division by zero!") else: print("result is", result) finally: print("executing finally clause") >>> divide(2, 1) result is 2.0 executing finally clause >>> divide(2, 0) division by zero! executing finally clause >>> divide("2", "1") executing finally clause # 出现异常,else没有执行 Traceback (most recent call last): ... TypeError: unsupported operand type(s) for /: \'str\' and \'str\'
预定义的清理行为
一些对象定义了标准的清理行为,无论系统是否成功的使用了它,一旦不需要它了,那么这个标准的清理行为就会执行。
# 当执行完以下代码后,文件会保持打开状态,并没有被关闭。 for line in open("myfile.txt"): print(line, end="") # 使用关键词 with 语句就可以保证诸如文件之类的对象在使用完之后,一定会正确的执行他的清理方法 with open("myfile.txt") as f: for line in f: print(line, end="")
三、XML和JSON解析
1. XML解析
常见的XML编程接口有DOM和SAX,而python有三种XML解析方法:SAX,DOM,以及ElementTree。
(1) SAX (simple API for XML )
python 标准库包含SAX解析器,SAX是一种基于事件驱动的API。利用SAX解析XML文档牵涉到两个部分:解析器和事件处理器。解析器负责读取XML文档,并向事件处理器发送事件,如元素开始跟元素结束事件;而事件处理器则负责对事件作出相应,对传递的XML数据进行处理。SAX适于处理下面的问题:
- 对大型文件进行处理;
- 只需要文件的部分内容,或者只需从文件中得到特定信息。
- 想建立自己的对象模型的时候。
students.xml文件及其解析结果:


<students> <student id="1"> <name>Amy</name> <age>16</age> </student> <student id="2"> <name>Daniel</name> <age>17</age> </student> </students> 输出结果: Student - 1 name: Amy age: 16 Student - 2 name: Daniel age: 17
SAX解析代码:
import xml.sax class StudentHandler( xml.sax.ContentHandler ): def _init_(self): self.currentTag = "" self.name = "" self.age = "" def startElement(self, tag, attributes): self.currentTag = tag if tag == "student": print("Student -", attributes["id"]) def endElement(self, tag): if self.currentTag == "name": print("name:", self.name) elif self.currentTag == "age": print("age:", self.age) self.currentTag = "" # 读取字符时调用 def characters(self, content): if self.currentTag == "name": self.name = content elif self.currentTag == "age": self.age = content if(__name__ == "__main__"): parser = xml.sax.make_parser() # 创建一个 XMLReader parser.setFeature(xml.sax.handler.feature_namespaces, 0) Handler = StudentHandler() parser.setContentHandler(Handler) parser.parse("C:/students.xml")
(2) DOM (Document Object Model)
DOM解析器在解析一个XML文档时,一次性读取整个文档,将XML数据在内存中解析成一个树,通过对树的操作来解析XML。可以利用DOM 提供的不同的函数来读取或修改文档的内容和结构,也可以把修改过的内容写入xml文件。
from xml.dom.minidom import parse import xml.dom.minidom DOMTree = xml.dom.minidom.parse("C:/students.xml") root = DOMTree.documentElement stuList = root.getElementsByTagName("student") for stu in stuList: print("Student -", stu.getAttribute("id")) name = stu.getElementsByTagName("name")[0] print("name:", name.childNodes[0].data) age = stu.getElementsByTagName("age")[0] print("age:", age.childNodes[0].data)
2. JSON解析
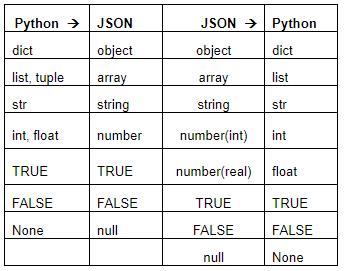
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。python 的原始类型与json类型的转化对应表如下:
(1) 使用json.dumps 与 json.loads 解析JSON对象
import json data = { \'no\' : 1, \'name\' : \'Runoob\', \'url\' : \'http://www.runoob.com\' } json_str = json.dumps(data) # json.dumps()将Python字典转换为JSON对象 print ("Python 原始数据:", repr(data)) print ("JSON 对象:", json_str) data2 = json.loads(json_str) # json.loads()将JSON对象转换为Python字典 print ("data2[\'name\']: ", data2[\'name\']) print ("data2[\'url\']: ", data2[\'url\'])
(2) 使用 json.dump() 和 json.load() 解析JSON文件
with open(\'data.json\', \'w\') as f: json.dump(data, f) # 写入 JSON 数据 with open(\'data.json\', \'r\') as f: data = json.load(f) # 读取数据
四、类
1. 类定义
class people: name = \'\' #定义基本属性 age = 0 __weight = 0 #定义私有属性,两个下划线开头,声明该属性为私有, 类外部无法直接进行访问 def __init__(self,n,a,w): #定义构造方法 self.name = n self.age = a self.__weight = w def speak(self): print("My name is %s and I\'m %d years old." %(self.name,self.age)) def printInfo(self): # 类方法的第一个参数必须是self, 表示当前对象的地址,self.class 则指向类。 print(self) print(self.__class__) class student(people): # 多继承时,若基类中有相同的方法名,而在子类使用时未指定,python会从左到右查找基类中是否包含方法。 grade = \'\' def __init__(self,n,a,w,g): people.__init__(self,n,a,w) #调用父类的构函 self.grade = g def speak(self): #覆写父类的方法 print("My name is %s and I\'m in grade %s."%(self.name,self.grade)) s = student(\'Amy\',16,80,\'one\') # 实例化类 s.speak()
2. 类的专有方法
""" 类的专有方法: __init__ : 构造函数,在生成对象时调用 __del__ : 析构函数,释放对象时使用 __repr__ : 打印,转换 __setitem__ : 按照索引赋值 __getitem__ : 按照索引获取值 __len__: 获得长度 __cmp__: 比较运算 __call__: 函数调用 __add__: 加运算 __sub__: 减运算 __mul__: 乘运算 __div__: 除运算 __mod__: 求余运算 __pow__: 乘方 """ class Vector: def __init__(self, a, b): self.a = a self.b = b def __str__(self): return \'Vector (%d, %d)\' % (self.a, self.b) # Python同样支持运算符重载,我们可以对类的专有方法进行重载 def __add__(self,other): # 重载加法运算方法 return Vector(self.a + other.a, self.b + other.b) v1 = Vector(2,10) v2 = Vector(5,-2) print (v1 + v2) # Vector(7,8) 这里用到两个重载方法
五、Python高级教程
1. MySQL数据库操作
import pymysql # 打开数据库连接 db = pymysql.connect("localhost","testuser","test123","TESTDB" ) # 使用 cursor() 方法创建一个游标对象 cursor cursor = db.cursor() # 建表 cursor.execute("DROP TABLE IF EXISTS EMPLOYEE") sql = """CREATE TABLE EMPLOYEE ( NAME CHAR(20) NOT NULL, AGE INT, SEX CHAR(1))""" cursor.execute(sql) # 插入、更新、删除语句 sql = """INSERT INTO EMPLOYEE(NAME, AGE, SEX) VALUES (\'Mac\', 20, \'M\')""" sql = "INSERT INTO EMPLOYEE(NAME, \\ AGE, SEX) \\ VALUES (\'%s\', \'%d\', \'%c\')" % \\ (\'Mac\', 20, \'M\') sql = "UPDATE EMPLOYEE SET AGE = AGE + 1 WHERE SEX = \'%c\'" % (\'M\') sql = "DELETE FROM EMPLOYEE WHERE AGE > \'%d\'" % (20) try: cursor.execute(sql) db.commit() except: db.rollback() # 回滚 # 查询语句 fetchone(),rowcount() sql = "SELECT * FROM EMPLOYEE WHERE AGE > \'%d\'" % (18) try: cursor.execute(sql) results = cursor.fetchall() for row in results: print ("name=%s,age=%d,sex=%s" % \\ (row[0], row[1], row[2])) except: print ("Error: unable to fetch data") # 关闭数据库连接 db.close()
2. Socket网络编程
Socket又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯。
# 服务器端 # -*- coding: utf-8 -*- import socket import sys serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 创建 socket 对象 host = socket.gethostname() # 获取本地主机名 port = 9876 serversocket.bind((host, port)) # 绑定地址 serversocket.listen(5) # 设置最大连接数,超过后排队 while True: clientsocket, addr = serversocket.accept() # (阻塞式)等待客户端连接 print("Client Address: %s" % str(addr)) msg = \'Hello World!\'+ "\\r\\n" clientsocket.send(msg.encode(\'utf-8\')) clientsocket.close() # 客户端 # -*- coding: utf-8 -*- import socket import sys s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 创建 socket 对象 host = socket.gethostname() # 获取本地主机名 port = 9876 # 设置端口号 s.connect((host, port)) # TCP连接服务,指定主机和端口 msg = s.recv(1024) # 接收小于 1024 字节的数据 s.close() print (msg.decode(\'utf-8\'))
3. SMTP发送邮件
# -*- conding:utf-8 -*- import smtplib from email.mime.image import MIMEImage from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText from email.header import Header sender = \'12345678@qq.com\' receivers = [\'779858277@qq.com\'] # 收件人 # 1.普通文本邮件 message = MIMEText(\'Email Content...\', \'plain\', \'utf-8\') 发送普通文本 # 2.HTML格式的邮件 mail_msg = """<p>Email Content...</p> <p><a href="http://www.abc.com">this is abc.</a></p>""" message = MIMEText(mail_msg, \'html\', \'utf-8\') # 三个参数分别为:邮件正文,文本格式,编码方式 # 3.有图片的HTML格式的邮件 message = MIMEMultipart(\'related\') mail_msg = """<p>Email Content...</p> <p><a href="http://www.abc.com">this is abc.</a></p> <p>image:</p><p><img src="cid:image1"></p>""" msgAlternative.attach(MIMEText(mail_msg, \'html\', \'utf-8\')) fp = open(\'test.png\', \'rb\') img = MIMEImage(fp.read()) fp.close() img.add_header(\'Content-ID\', \'<image1>\') # 定义图片 ID,在 HTML 文本中引用 message.attach(img) 以上是关于Python基础 (下)的主要内容,如果未能解决你的问题,请参考以下文章