Python 如何将长度不同的字符串尽量均匀地分配到N个文件中?每一行的字符串作为整体,不能打散。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 如何将长度不同的字符串尽量均匀地分配到N个文件中?每一行的字符串作为整体,不能打散。相关的知识,希望对你有一定的参考价值。
如:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
bbbbbb
ccccccccccccccccc
ddddddddd
ee
ffffff
gggggggggggggggggggggggggggggggggggggg
分配到三个文件。三个文件尽量大小接近。
背包问题的一个变种。或者说是一维装箱算法。
你将每一行字符串想象为一个物品,字符串的长度就是这个物品的大小。每个文件相当于不同的箱子,箱子的大小是固定的,装入的物品体积之和不能超过箱子的总容量。
问题就是:如何使用尽可能少的箱子来装入所有的物品,或者:如果使尽可能多的箱子空间利用率更高,以及类似的相关问题。
这类问题的答案不是一个简单的数字,它需要给出一个策略:物品1...n分别装入箱子1...m(m<=n).
对于二维装箱或三维等,区别主要在于解法的复杂度,但一个解法一般来说其思路是可以从一维扩展到二维或者三维的。
这类问题目前来说,没有全局最优解(即,没有一个算法能确保在所有情况下均能得到最好的结果),但可以得到局部最优解。算法有多种,如最常见的贪心算法,或动态规划。
贪心算法的思路比较简单:把所有的物品从大到小排好序,拿一个箱子,尝试装入最大的物品,如果不能装入,就尝试装入小一些的物品,如此循环,直到所有物品装入所有箱子。
算法很简单,但很多时候得到的结果并不理想。

贪心算法
动态规划的思路是,每装入一个物品到箱子里,就提出一个新的问题:【以所有未装入的物品和这个箱子剩余空间作为条件,怎么装?】而这样的问题随着装入的物品不同,会有许多个,选择其中最终剩余空间最小的方式,就是局部最优的解。一般来说,这比较适合用递归来处理,但它的复杂度是远远高于贪心算法的。

动态规划
当然,还有其它的算法,不同的算法有不同的思路,复杂度也不同,适用范围也有一些区别。所以,没必要纠结于【最好】,只要【尽可能好】。
否则的话,关于装箱问题,都可以出许多篇博士论文了。
针对题主这一问题,贪心算法的解决思路就是读入每一行,然后排序,从大到小装入剩余空间最大的箱子(即装入内容最少的箱子)。
可以参考以下处理方式:

题主你好,
代码及相应测试截图如下:
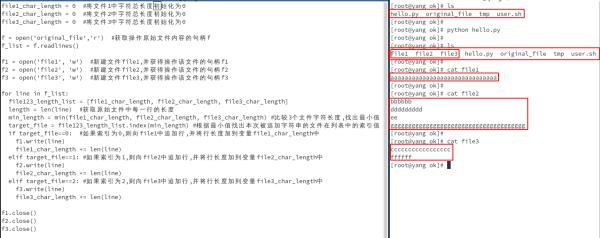
上面代码大致思路:
1.将题主那几行字符串放在文件original_file中;
2.定义3个变量file1|file2|file3-char-length,表示被写入的3个目标文件的字符长度,初始值为0;
3.一行一行的读取original_file中的内容,然后对比2中定义的3个变量长度,谁小,就将当前行追加到那个文件中,然后将该字符串的长度加到相应的变量上,如此循环.
希望可以帮到题主, 欢迎追问
files=["a.txt","b.txt","c.txt"]
strs=[str[0:len(str)//3],[str[len(str)//3:len(str)//3*2]],[str[len(str)//3*2:len(str)]]]
for a in range(3):
--with open(files[a],"w")as f:f.write(strs[a])
print("finished.\n--the end--")
如何在节点上平均分配 slurm 任务?
【中文标题】如何在节点上平均分配 slurm 任务?【英文标题】:How to distribute slurm tasks evenly over the nodes? 【发布时间】:2018-12-12 17:20:33 【问题描述】:我想在一个 sbatch 脚本中使用 srun 命令在集群上运行大约 200 次脚本。由于执行脚本需要一些时间,因此最好将任务均匀地分布在集群中的节点上。可悲的是,我对此有疑问。
现在,我创建了一个示例脚本(“hostname.sh”)来测试 sbatch 脚本中的不同参数:
echo `date +%s` `hostname`
sleep 10
这是我的 sbatch 脚本:
#SBATCH --ntasks=15
#SBATCH --cpus-per-task=16
for i in `seq 200`; do
srun -n1 -N1 bash hostname.sh &
done
wait
我希望 hostname.sh 被执行 200 次(for 循环),但只有 15 个任务同时运行(--ntasks=15)。由于我最大的节点有 56 个内核,因此只有三个作业应该能够同时在该节点上运行(--cpus-per-task=16)。
从脚本的输出中,我可以看到前九个任务分布在集群的九个节点上,但所有其他任务(191 个!)同时在一个节点上执行。整个 sbatch 脚本执行只用了大约 15 秒。
我想我误解了 slurm 的一些参数,但查看官方文档并没有帮助我。
【问题讨论】:
【参考方案1】:您需要在该上下文中使用srun 的--exclusive 选项:
srun -n1 -N1 --exclusive bash hostname.sh &
来自srun manpage:
默认情况下,作业步骤可以访问分配给作业的每个 CPU。 要确保为每个作业步骤分配不同的 CPU,请使用 --exclusive 选项。
另请参阅上述文档中的最后一个示例。
【讨论】:
srun 的 --exclusive 选项不仅用于在节点上专门运行作业,这对我来说是新的。这对于其他 slurm 初学者来说可能非常重要......谢谢!以上是关于Python 如何将长度不同的字符串尽量均匀地分配到N个文件中?每一行的字符串作为整体,不能打散。的主要内容,如果未能解决你的问题,请参考以下文章