利用CRNN来识别图片中的文字(二)tensorflow中ctc有关函数详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用CRNN来识别图片中的文字(二)tensorflow中ctc有关函数详解相关的知识,希望对你有一定的参考价值。
参考技术A 定义一个稀疏tensor。将一个稀疏tensor转换成稠密tensor。
计算ctc_loss。
主要参数1:labels: int32 SparseTensor 是数据的真实标签,一般是先用sparse_placeholder(),然后在session中feed训练数据batch_y。batch_y为 SparseTensor 利用sparse_tuple_from(y)函数计算得到。
sparse_tuple_from(y)函数的输入是在train_y中随机选择大小为 batch_size 的数据,输出是一个(indices, values, shape)形式的三元组。
主要参数2:inputs:是三维 float Tensor .logits是网络向前传播inference计算的结果。形状为[max_time_step, batch_size, num_classes]这里的num_classes是中文字典的大小,及992个汉字加1个空白,所以num_classes=993。输入图像经过卷积之后的大小为[batch_size, 11, 1, 512],max_time_step=512,是通道数,可以看作是512个图片特征序列。
主要参数3:sequence_length:一维 int32 向量【注意是向量,不是 Tensor !!!】长度为batch_size(批处理大小),值为max_len(ctc的最大输出长度,这个长度是自己定义的!合理即可!)的可以按照下面的方式定义。
占位符。在session中feed训练数据。
OCR-CRNN (CNN+CTC)文字识别,实践上手
前言
提示:这里可以添加本文要记录的大概内容:
文字识别可根据待识别的文字特点采用不同的识别方法,一般分为定长文字、不定长文字两大类别。
- 定长文字(例如验证码),由于字符数量固定,采用的网络结构相对简单,识别也比较容易;
- 不定长文字(例如印刷文字、广告牌文字等),由于字符数量是不固定的,因此需要采用比较复杂的网络结构和后处理环节,识别也具有一定的难度。
提示:以下是本篇文章正文内容,下面案例可供参考
环境
- ubuntu 18.05
- pytorch 最新版
- CUDA 11.2
- 其他基本环境配置 (pandas、numpy、opencv、PILLow)
一、数据集
我们需要的数据集是这样的,他是一个txt文本,里面是以image,str(图片内容文本)
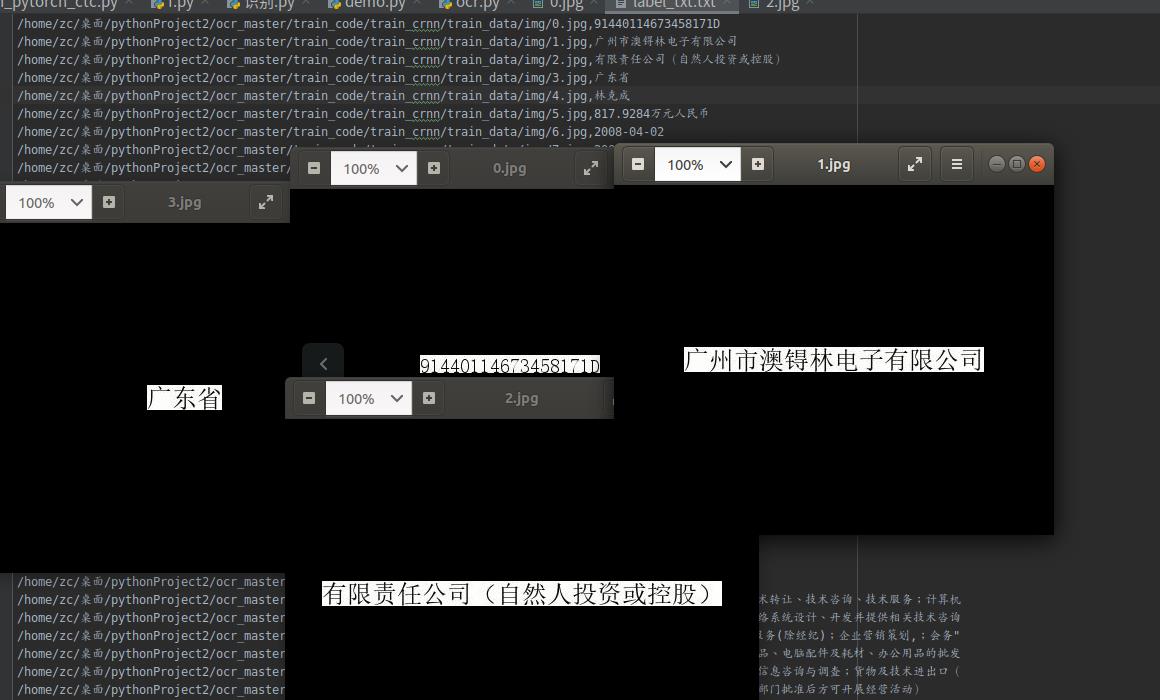

二、数据集构造
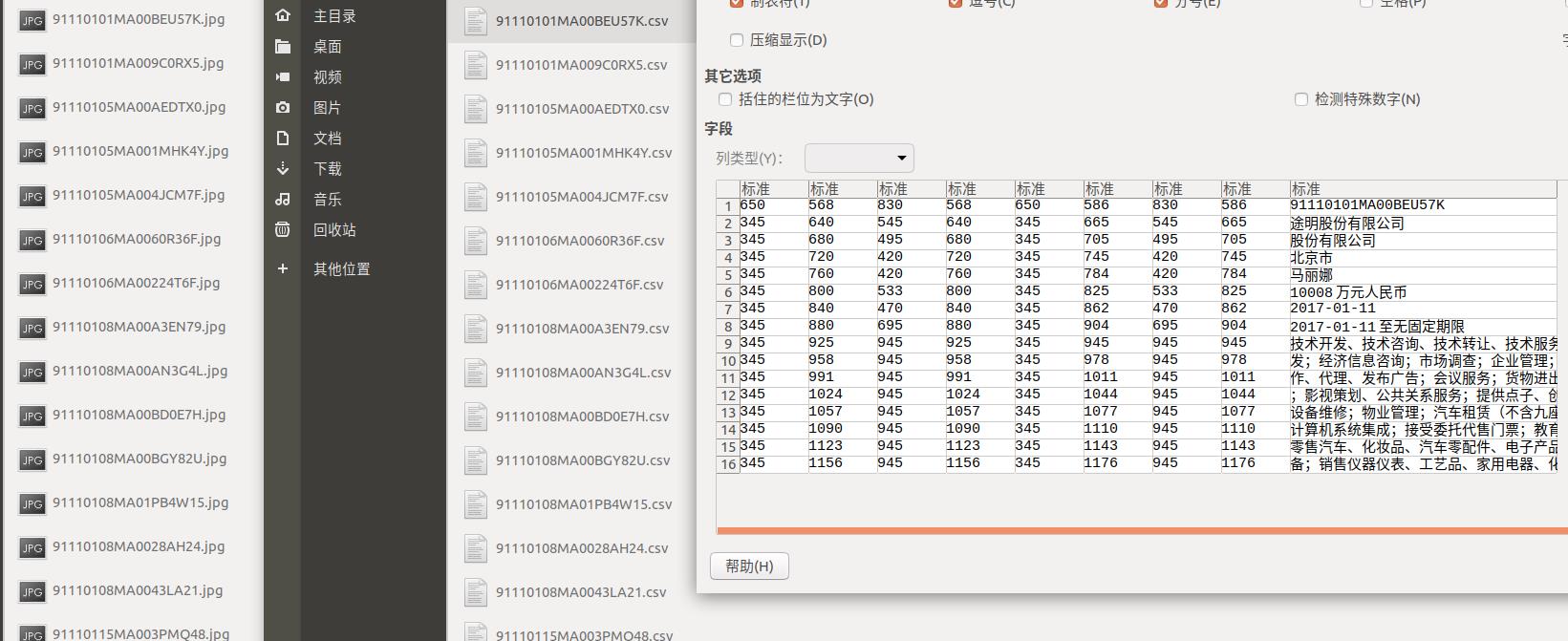
对于数据构造的话,就需要在原始的图片上面去截取,保存
在这里我们需要创建两个数据集训练集和验证集
代码如下(示例):
import os
import cv2
import pandas as pd
import csv
img_list= os.listdir('imgs')#图片路径
"""
这里可能就有些不一样了,本人是一张图片对应一个坐标文件
"""
txt_list = os.listdir('/home/zc/桌面/pythonProject2/坐标')
f = open('/home/zc/桌面/pythonProject2/ocr_master/train_code/train_crnn/train_data/val_txt/label_txt.txt','a',newline='')
wi = csv.writer(f)
num = 0
for i in txt_list[:50]:
a = i[:-4]
data = pd.read_csv('/home/zc/桌面/pythonProject2/坐标/{}'.format(i),header=None)
img = cv2.imread('imgs/{}.jpg'.format(a))
for j in range(len(data)):
x1,y1 = data.loc[j][0],data.loc[j][1]
x2,y2 = data.loc[j][6],data.loc[j][7]
txt_str = data.loc[j][8]
im = img[y1:y2,x1:x2]
if num==750:
print(im.shape)
if im.shape==(0, 0, 3):
continue
cv2.imwrite('/home/zc/桌面/pythonProject2/ocr_master/train_code/train_crnn/train_data/val_img/{}.jpg'.format(num),im)
wi.writerow(['/home/zc/桌面/pythonProject2/ocr_master/train_code/train_crnn/train_data/val_img/{}.jpg'.format(num),txt_str])
num += 1
模型训练
代码
链接: https://pan.baidu.com/s/1kZlGueOmcGNicoBgRwzoLQ
提取码: h6en
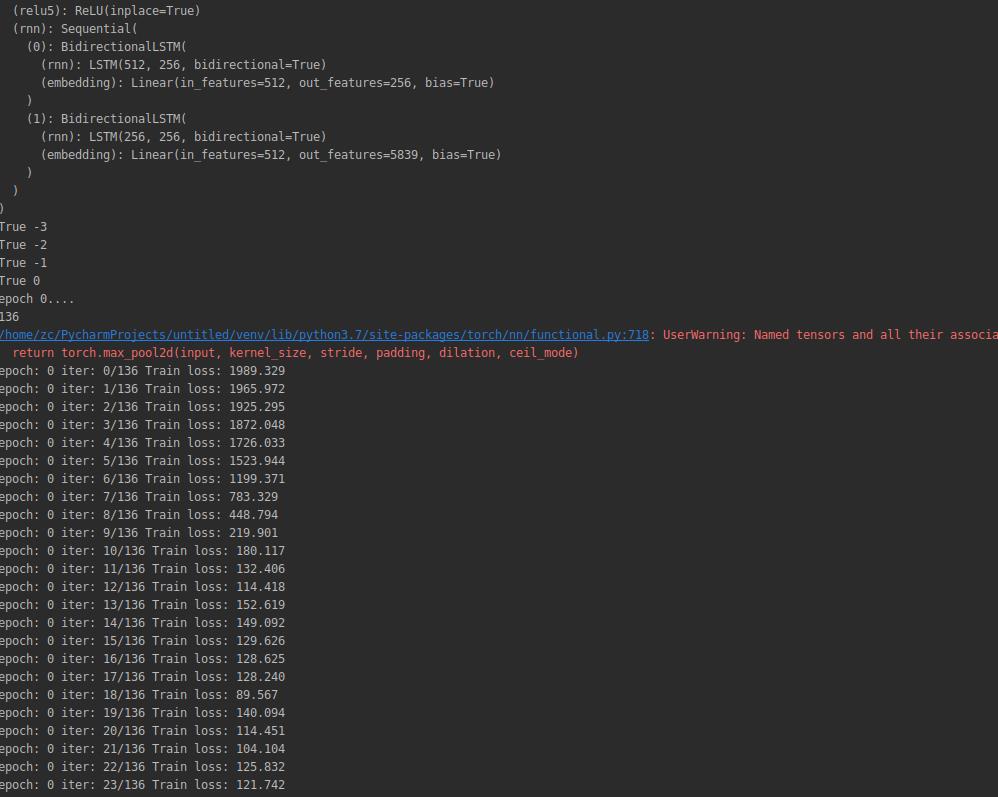
感兴趣的同学可以下载下来训练一下,只需要修改train_pytorch_ctc.py里面的训练文本路径和验证文本路径
 训练过程:
训练过程:
加载模型,识别图片
import torch.nn as nn
# import torchvision.models as models
import torch, os
from PIL import Image
import cv2
import torchvision.transforms as transforms
from torch.autograd import Variable
import numpy as np
import random
from ocr_master.recognize.crnn import CRNN
from ocr_master.recognize import config
# copy from mydataset
class resizeNormalize(object):
def __init__(self, size, interpolation=Image.LANCZOS, is_test=True):
self.size = size
self.interpolation = interpolation
self.toTensor = transforms.ToTensor()
self.is_test = is_test
def __call__(self, img):
w, h = self.size
w0 = img.size[0]
h0 = img.size[1]
if w <= (w0 / h0 * h):
img = img.resize(self.size, self.interpolation)
img = self.toTensor(img)
img.sub_(0.5).div_(0.5)
else:
w_real = int(w0 / h0 * h)
img = img.resize((w_real, h), self.interpolation)
img = self.toTensor(img)
img.sub_(0.5).div_(0.5)
tmp = torch.zeros([img.shape[0], h, w])
start = random.randint(0, w - w_real - 1)
if self.is_test:
start = 0
tmp[:, :, start:start + w_real] = img
img = tmp
return img
# copy from utils
class strLabelConverter(object):
def __init__(self, alphabet, ignore_case=False):
self._ignore_case = ignore_case
if self._ignore_case:
alphabet = alphabet.lower()
self.alphabet = alphabet + '_' # for `-1` index
self.dict = {}
for i, char in enumerate(alphabet):
# NOTE: 0 is reserved for 'blank' required by wrap_ctc
self.dict[char] = i + 1
# print(self.dict)
def encode(self, text):
length = []
result = []
for item in text:
item = item.decode('utf-8', 'strict')
length.append(len(item))
for char in item:
if char not in self.dict.keys():
index = 0
else:
index = self.dict[char]
result.append(index)
text = result
return (torch.IntTensor(text), torch.IntTensor(length))
def decode(self, t, length, raw=False):
if length.numel() == 1:
length = length[0]
assert t.numel() == length, "text with length: {} does not match declared length: {}".format(t.numel(),
length)
if raw:
return ''.join([self.alphabet[i - 1] for i in t])
else:
char_list = []
for i in range(length):
if t[i] != 0 and (not (i > 0 and t[i - 1] == t[i])):
char_list.append(self.alphabet[t[i] - 1])
return ''.join(char_list)
else:
# batch mode
assert t.numel() == length.sum(), "texts with length: {} does not match declared length: {}".format(
t.numel(), length.sum())
texts = []
index = 0
for i in range(length.numel()):
l = length[i]
texts.append(
self.decode(
t[index:index + l], torch.IntTensor([l]), raw=raw))
index += l
return texts
# recognize api
class PytorchOcr():
def __init__(self, model_path='checkpoints/CRNN-1010.pth'):
alphabet_unicode = config.alphabet_v2
self.alphabet = ''.join([chr(uni) for uni in alphabet_unicode])
# print(len(self.alphabet))
self.nclass = len(self.alphabet) + 1
self.model = CRNN(config.imgH, 1, self.nclass, 256)
self.cuda = False
if torch.cuda.is_available():
self.cuda = True
self.model.cuda()
self.model.load_state_dict({k.replace('module.', ''): v for k, v in torch.load(model_path).items()})
else:
# self.model = nn.DataParallel(self.model)
self.model.load_state_dict(torch.load(model_path, map_location='cpu'))
self.model.eval()
self.converter = strLabelConverter(self.alphabet)
def recognize(self, img):
h,w = img.shape[:2]
if len(img.shape) == 3:
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
image = Image.fromarray(img)
transformer = resizeNormalize((int(w/h*32), 32))
image = transformer(image)
image = image.view(1, *image.size())
image = Variable(image)
if self.cuda:
image = image.cuda()
preds = self.model(image)
_, preds = preds.max(2)
preds = preds.transpose(1, 0).contiguous().view(-1)
preds_size = Variable(torch.IntTensor([preds.size(0)]))
txt = self.converter.decode(preds.data, preds_size.data, raw=False).strip()
return txt
if __name__ == '__main__':
model_path = '/home/zc/桌面/pythonProject2/ocr_master/checkpoints/CRNN-1010.pth'
recognizer = PytorchOcr(model_path)
img_name = '2.jpg'
img = cv2.imread(img_name)
# h, w = img.shape[:2]
res = recognizer.recognize(img)
print(res)
cv2.imshow('1',img)
cv2.waitKey(-1)
cv2.destroyAllWindows()
检测结果


完整代码下载
链接: https://pan.baidu.com/s/1kZlGueOmcGNicoBgRwzoLQ
提取码: h6en
结果展示
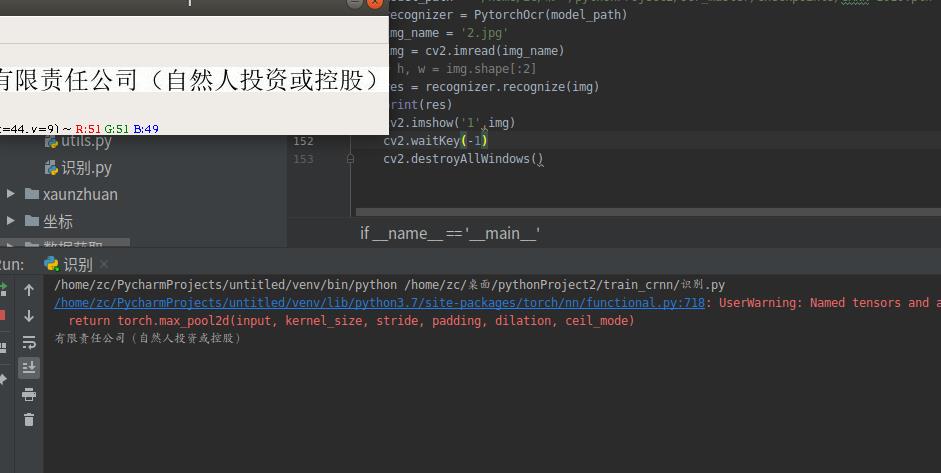
希望这篇文章对你有用!
谢谢点赞评论!
以上是关于利用CRNN来识别图片中的文字(二)tensorflow中ctc有关函数详解的主要内容,如果未能解决你的问题,请参考以下文章