Python 全栈开发:python文件处理
Posted 人生何必久睡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 全栈开发:python文件处理相关的知识,希望对你有一定的参考价值。
python文件处理
打开文件的模式
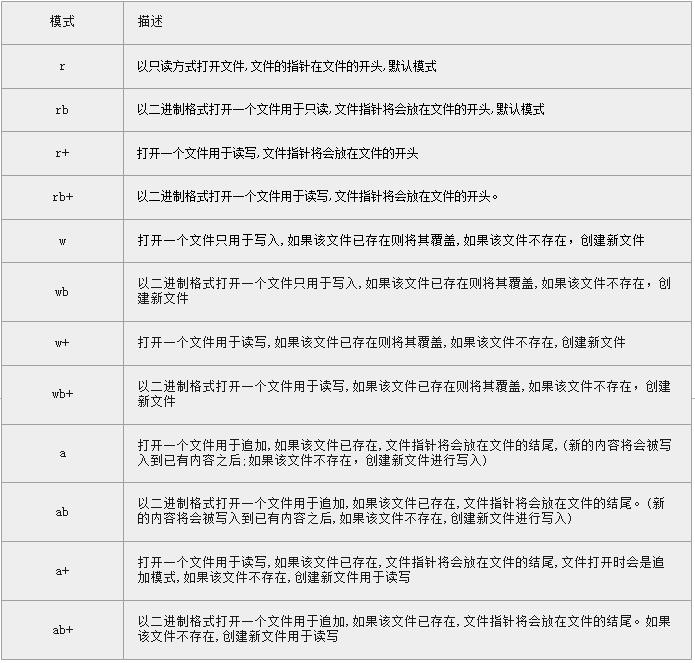
file常用函数
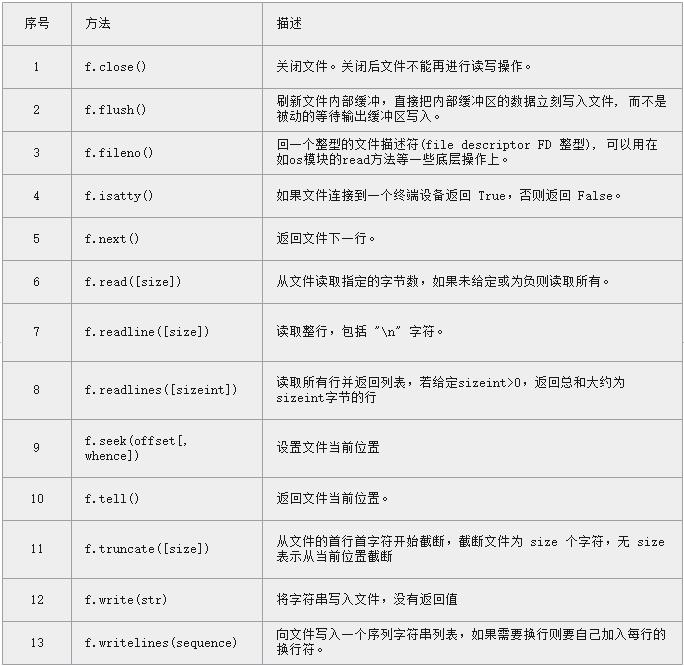
一、打开文件,关闭文件
操作文件的流程:
#1. 打开文件,得到文件句柄并赋值给一个变量 #2. 通过句柄对文件进行操作 #3. 关闭文件
获取文件句柄open()方法:返回一个file对象
语法格式:
#file = open(filename,mode,encoding) #打开文件 #文件操作 文件的读和写 #file.close() #关闭文件
常用参数
filename: 要打开的文件路径
mode: 打开文件的模式(见上图)
encoding:打开文件的编码格式
注意点:
filename是文件的路径,当我们使用绝对路径的时候
eg:
f = open(\'C:\\Users\\Fixdq\\1.txt\',mode=\'r\',encoding=\'utf-8\'): data = f.read() print(data)
报错:SyntaxError: (unicode error) \'unicodeescape\' codec can\'t decode bytes in position 2-3: truncated \\UXXXXXXXX escape
报错原因:pyrhon中使用反斜杠(\\)进行字符串的转义操作,这就可能导致路径被转义成其他字符,导致路径无法被解析
解决方法:在路径字符串前加一个 r (rawstring 原生字符串)
eg:
f = open(r\'C:\\Users\\Fixdq\\1.txt\',mode=\'r\',encoding=\'utf-8\'): data = f.read() print(data)
#这样就不会出现路径错误的信息了
二、mode打开文件的模式
1.默认文本模式(t模式)
- r, 只读 (默认模式,文件必须存在,不存在报错)
- w,只写 (不可读,不存在创建,存在清空内容)
- a,追加 (不可读,不存在创建,存在末尾追加)
2.字节模式(b模式)
图片,视频,音乐等非文本文件,都是以字节的模式存储的,需要用字节模式(b模式)进行读写
同样在计算机中所有的文件都是以字节模式存储的,使用(b模式)无需考虑文件类型
注:以b模式打开时,读取到的内容是字节类型,写入时也必须是字节类型(不能设置encoding 编码类型)
- rb, 只读 (文件必须存在,不存在报错)
- wb,只写 (不可读,不存在创建,存在清空内容)
- ab,追加 (不可读,不存在创建,存在末尾追加)
3.可读写模式(+模式)
- r+,r+b 读写 (可读,可写) (文件必须存在,不存在报错)
- w+,w+b 写读 (可写,可读)(文件不存在创建,存在清空内容)
- a+,a+b 写读 (可写,可读)(文件不存在创建,存在清空内容)
三、常用的方法
大前提,被读取的文件 a.txt 已存在(不存在会报错)
a.txt 文件内容
这一个可读的文件11
这一个可读的文件22
这一个可读的文件33
f.read() 读取文件的所有字符
#打开文件(前提 a.txt 存在) f = open(\'a.txt\',mode=\'r\',encoding=\'utf-8\') print(f.read())
f.close()

f.readline() 读取文件中的一行
f = open(\'a.txt\',mode=\'r\',encoding=\'utf-8\') print(f.readline())
f.close()

f.readlines() 读取文件中的所有行,并以 行 为单元素返回一个列表
f = open(\'a.txt\',mode=\'r\',encoding=\'utf-8\') print(f.readlines())
f.close()

循环读取
f = open(\'a.txt\',mode=\'r\',encoding=\'utf-8\') for i in f: print(i) f.close()
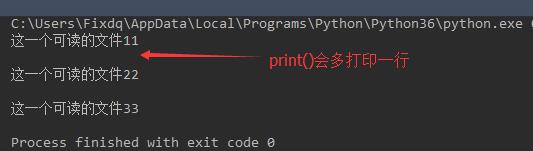
f.write()
f.writelines()
f=open(r\'a1.txt\',mode=\'w\',encoding=\'utf-8\') #默认是wt f.write(\'第一行\\n\') f.write(\'第二行\\n\') f.writelines([\'1111\\n\',\'2222\\n\',\'3333\\n\']) # 向文件写入字符串列表 f.write(\'aaaaa\\nbbbb\\nccccc\\n\')
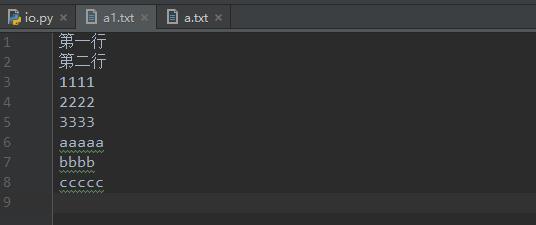
追加模式(a)
#a:只追加写模式 #注意: #在文件不存在时,创建空文件 #在文件存在时,光标直接跑到文件末尾 f=open(\'access.log\',mode=\'a\',encoding=\'utf-8\') # print(f.writable()) # f.readlines() #报错 f.write(\'5555555555555\\n\') f.close()
指针(光标)
f = open(\'a.txt\',mode=\'r\',encoding=\'utf-8\')
print(f.readline(),end=\'\')
print(f.readline(),end=\'\')
print(f.readline(),end=\'\')
print(f.readline(),end=\'\')
print(f.readline(),end=\'\')
f.close()

从上面的结果中我们可以看到 ,我们一共读取了 5 行 ,只显示了三行 。因为在文件读取过程中有个指针,文件读到了哪里,指针就会指到哪里,读取三行以后,指针已经在文件的末尾了,此时在进行文件的读操作将不会有任何内容。
结论:读到哪里,指针就指到哪里,指针在末尾,将读取不到内容
四、上下文管理
为什么要有上下文管理呢?
实际的代码编写过程中,经常会有人忘记 f.close(),这导致系统打开的文件一直占用资源,这是很可耻的浪费行为。
怎么办?
使用with 关键字,将管理权,交给解释器,这样就不需要关注文件的关闭了
eg:
with open(\'sh\',mode=\'rb\') as f: data = f.read()#以bytes读取文件 dedata=data.decode(\'utf-8\')#解码操作 print(dedata)
以上是关于Python 全栈开发:python文件处理的主要内容,如果未能解决你的问题,请参考以下文章