Cuda架构,调度与编程杂谈
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Cuda架构,调度与编程杂谈相关的知识,希望对你有一定的参考价值。
Cuda架构,调度与编程杂谈
Nvidia GPU——CUDA、底层硬件架构、调度策略
说到GPU估计大家都不陌生,但是提起gpu底层的一些架构以及硬件层一些调度策略的话估计大部分人就很难说的上熟悉了。当然这个不是大家的错,主要是因为Nv gpu的整个生态都是闭源的,所以大家了解起来就会有一些障碍。最近这半年笔者有幸参与了一些gpu的项目,在这个过程当中也花了一些时间去理了一下gpu相关的东西,故借这篇文章给大家简单介绍一下。下面的行文将基于以下三个层面进行阐述:
- CUDA编程模型
- GPU 底层硬件架构
- 硬件层的调度策略
CUDA编程模型
为了让习惯了以cpu为计算主体的广大开发者也能够快速的开发出基于gpu来进行计算的应用程序,英为达在2007年发布了一种新的编程模型框架cuda。简单来讲,cuda里面提供了基于gpu来进行并行计算的编程范式以及大量的api。这里需要强调的是基于cuda的应用程序,它的程序主体仍然运行在cpu上,开发者可以通过其提供的api将相关代码offload到gpu上去执行比如一些矩阵运算等。从大的层面来讲cuda编程主要可以分为下面三大步:
通过cuda api(比如cudaMemcpy)将input data 从host memory copy到device memory通过cuda api将gpu code load到gpu上去执行
device将执行之后的结果dma到host memory注:host-> cpu server device->gpu为了让大家更好地去理解相关的流程,这里给大家先介绍一下cuda编程模型当中的一些核心概念。
kernel
对于操作系统同学来说此kernel非彼kernel,这里的kernel更准确的来说是叫核函数,在概念上跟大家熟悉的c++/c函数差不多,只不过它是在gpu上执行的。
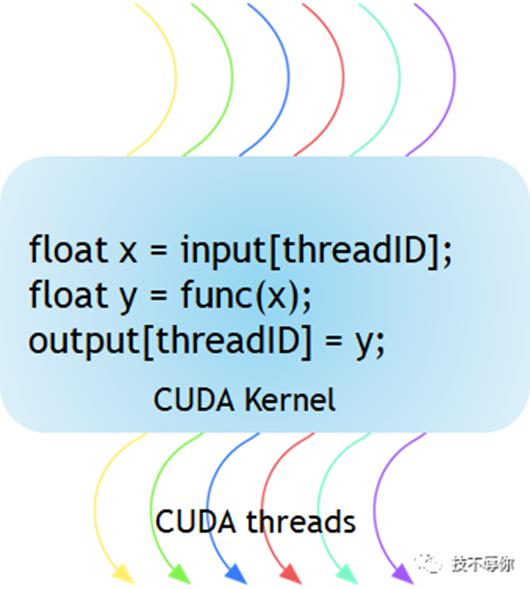
图1 the kernel function execute gpu
每一个cuda 核函数的开始处都有一个__global__的关键字来进行申明。具体例子可以参考一下图1所示,可能大家会对图中的threadID感到有些摸不到头脑。下面我们就来介绍一下thead相关的概念。
thread blocks and Grid
为了能够更好地讲清楚thread blocks和grid的概念,我们先上一个基于gpu进行矩阵计算的代码sample。
// Kernel - Adding two matrices MatA and MatB
___global__ void MatAdd(float MatA[N][N], float MatB[N][N], float MatC[N][N])
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
MatC[i][j] = MatA[i][j] + MatB[i][j];
int main()
...
// Matrix addition kernel launch from host code
dim3 threadsPerBlock(16, 16);
dim3 numBlocks((N + threadsPerBlock.x -1) / threadsPerBlock.x, (N+threadsPerBlock.y -1) / threadsPerBlock.y);
//核心函数launch
MatAdd<<<numBlocks, threadsPerBlock>>>(MatA, MatB, MatC);
...
从上面的示例当中MatAdd是一个核函数,可以看到其具体实现里面有blockId和threadId的代码段,也就是说核函数会被拆分为多个thread去gpu上执行。接下来我们看一下block和thread 的声明:
dim3 threadsPerBlock(16, 16);
dim3 numBlocks((N + threadsPerBlock.x -1) / threadsPerBlock.x, (N+threadsPerBlock.y -1) / threadsPerBlock.y);
cuda里面用关键字dim3 来定义block和thread的数量,以上面来为例先是定义了一个16*16 的2维threads也即总共有256个thread,接着定义了一个2维的blocks。因此在在计算的时候,需要先定位到具体的block,再从这个bock当中定位到具体的thread,具体的实现逻辑见MatAdd函数。再来看一下grid的概念,其实也很简单它是多个block组成的一个集合。thread、block 和grid的关系具体见下图:
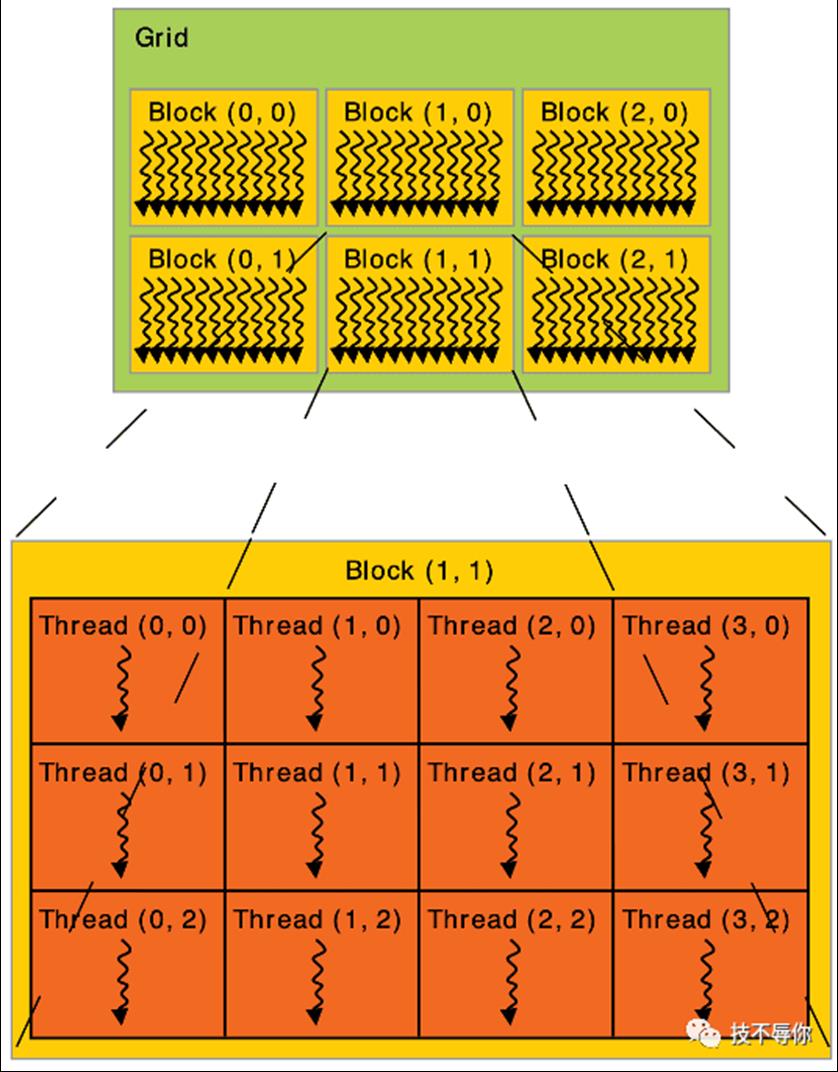
图2 grid、block and thread
stream
中文翻译为"流",它主要是通过提升kernel函数的并发性来提升整个计算的运行效率。下面我们来看一下在cuda编程模型当中具体是如何使用stream的。
cudaStream_t stream[nStreams];
for(int i = 0; i < nStreams; i ++)
checkCuda(cudaStreamCreate(&stream[i]));
for(int i = 0; i < nStreams; i ++)
checkCuda(cudaStreamDestroy(stream[i]));
上面所展示的是stream的创建和销毁,接下来我们来看一下如何使用stream
for(int i = 0; i < nStreams; i ++)
int offset = i * streamSize;
checkCuda(cudaMemcpyAsync(&d_a[offset], &a[offset], streamBytes, cudaMemcpyHostToDevice, stream[i]));
kernel_function<<<streamSize/blockSize, blockSize, 0, stream[i]>>>(d_a, offset);
checkCuda(cudaMemcpyAsync(&a[offset], &d_a[offset], streamBytes, cudaMemcpyDeviceToHost, stream[i]));
stream具体用法如上面sample所示,如果你不显示的申请stream的话系统也会有一个default的stream0。大家可以从下面的这张图比较直观地看到两者在执行效率上的区别:
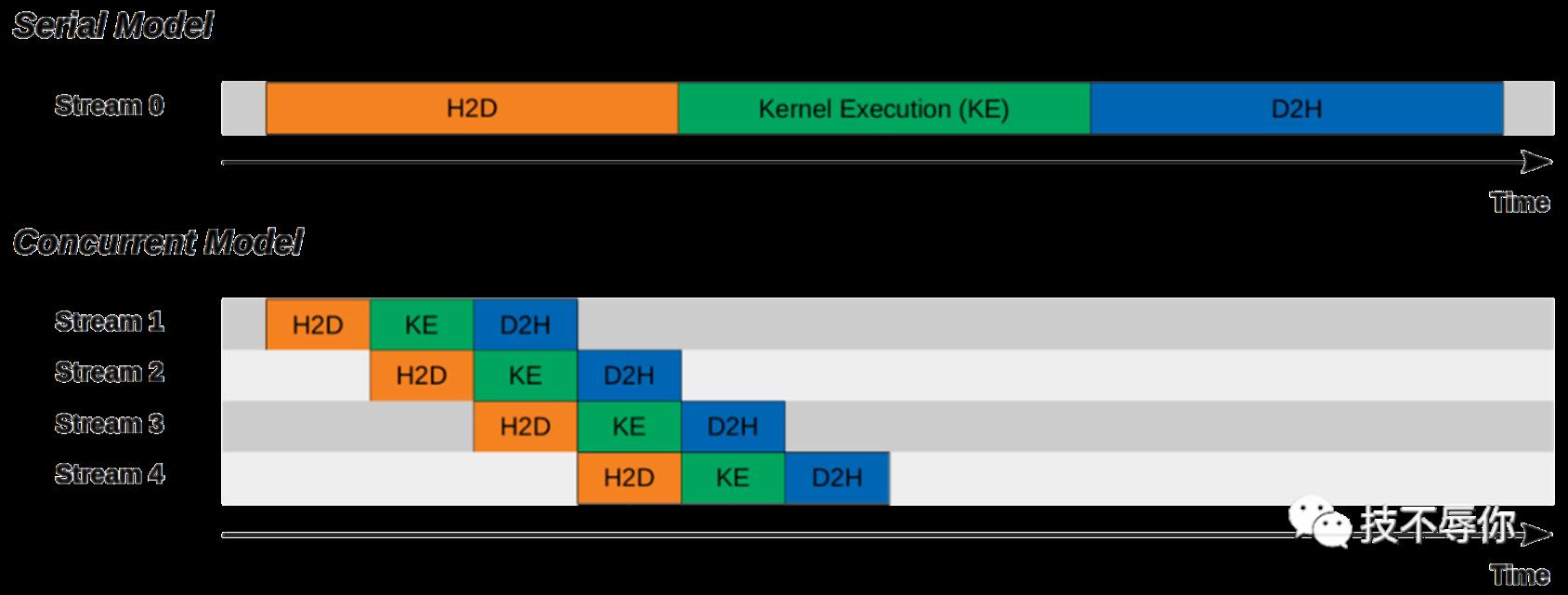
图3 cuda stream 串行和并行执行
GPU底层硬件架构
上面所讲的都是cuda层面的概念,下面我们来讲一下GPU的底层硬件架构。GPU最核心的东西就是SM(stream multiprocessor),上面所讲的thread最终的执行体就是SM。因为nv每一代gpu的SM都有一些小的差别,所以这里我们从nv最近5代的gpu来简单讲一下。
Pascal架构之P100
Nvidia 在2016年发布了他的第一代数据中心专用gpu P100,也是在p100这代gpu当中首次引入了float16的支持。下面我们来看p100的sm的底层微架构,具体如下图所示:

图4 P100 SM
每张p100 gpu卡总共有56个SM,每个SM包含了两个SP(stream processor),下面我们来详细介绍一下每个SP的相关组成。
core也称之为cuda core,主要用来进行FP和INT的计算DP Unit主要是在HPC场景用来进行double precison 计算,而机器学习场景基本上不会用到
SFU也是一个计算单元,它主要负责 sine, cosine, log and exponential等函数的计算
LD/ST即load uint和store unit即内存控制器的常用组件
Register File即寄存器组
Tex即图形渲染时需要用到的内存
上面还有一些组件比如warp scheduler、dispatch unit,这些都会在后面的调度章节进行详细介绍。
Volta架构之V100
2018年NV推出了v100 gpu卡,每张卡拥有80个SM,每个SM包含了4个SP。v100 SM底层微架构如下图所示:

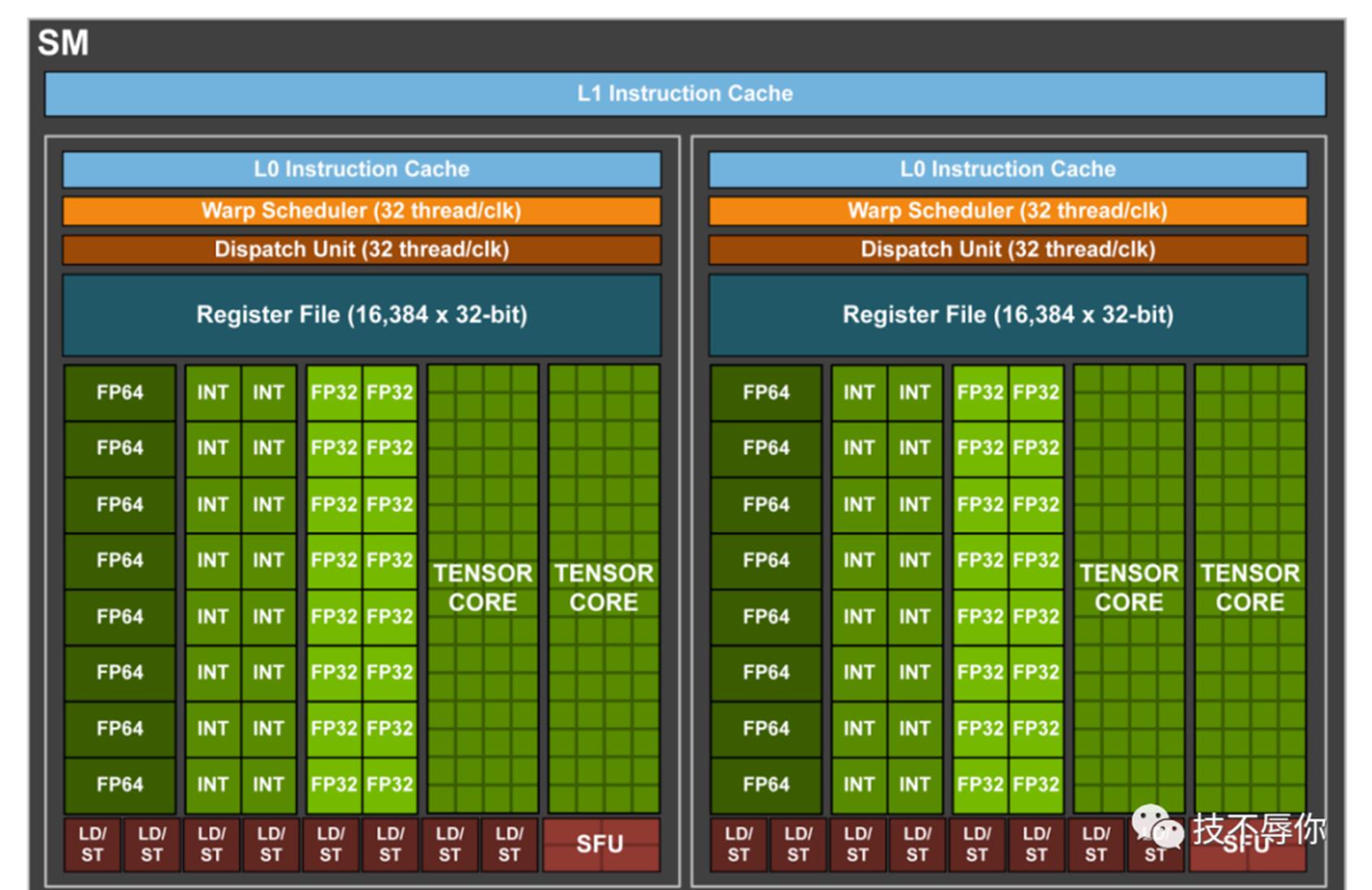
图5 v100 SM
相关的组件这里就不详细介绍了,从图中可以看到v100 sp跟p100 sp的区别主要有1)去掉了DP Unit从而为增加更多的FP、INT unit腾出位置。2)SFU 数量减少,多增加了TENSOR CORE。 因为是首次引入tensor core,这里我们来详细介绍一下tensor core的作用。它主要用来做矩阵的MAC运算即两个矩阵的乘积与另外一个矩阵的和。
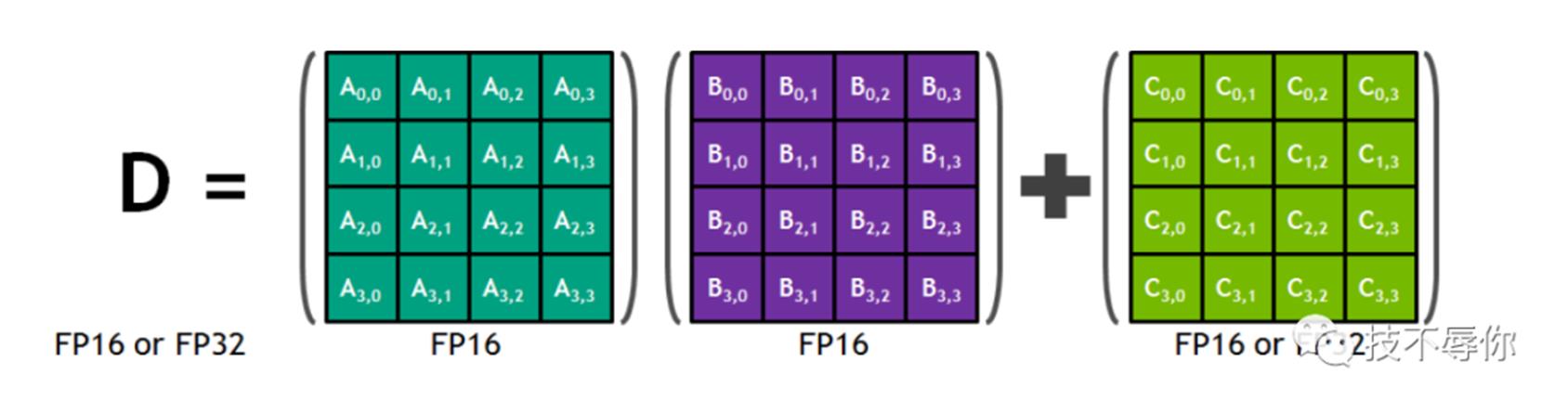
图6 tensor core 4x4 Matrix Multiply and Accumulate
从图6可以看到tensor core MAC运算是支持混合精度运算的,这里需要强调的是MAC操作是在一个cycle里面完成的。具体来说gpu主要是通过FMA(Fused multiply-add)指令在一个运算周期内完成一次先乘再加的浮点运算。
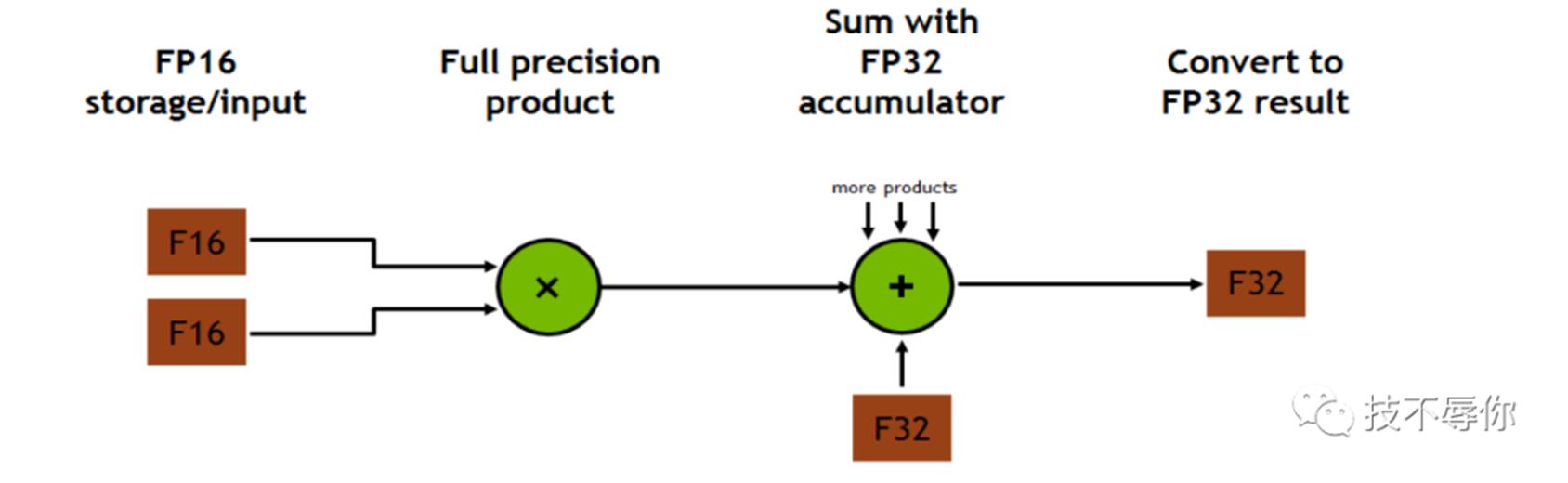
图7 Multiplication and addition happen in one clock cycle also known as FMA
Turing架构之TU102/TU104/TU106
Turing系列的gpu卡也是在2018年发布的,与Volta系列不同的是Turing主打的是游戏加速场景。当然它也可以用在AI场景,比如T系列的tensor core除了支持FP16之外还支持INT8和INT4。

图8 turing SM
从图8可以看到T系列SM跟V系列SM不同之处在于引入了RT CORE,从turing spec里面可以知道它主要是用来加速3D场景ray tracing。
Ampere 架构之A100
Nvidia 在2020发布了Ampere系列gpu卡,从功能上来说它是V系列的继承者。A100 GPU拥有108 颗SM。
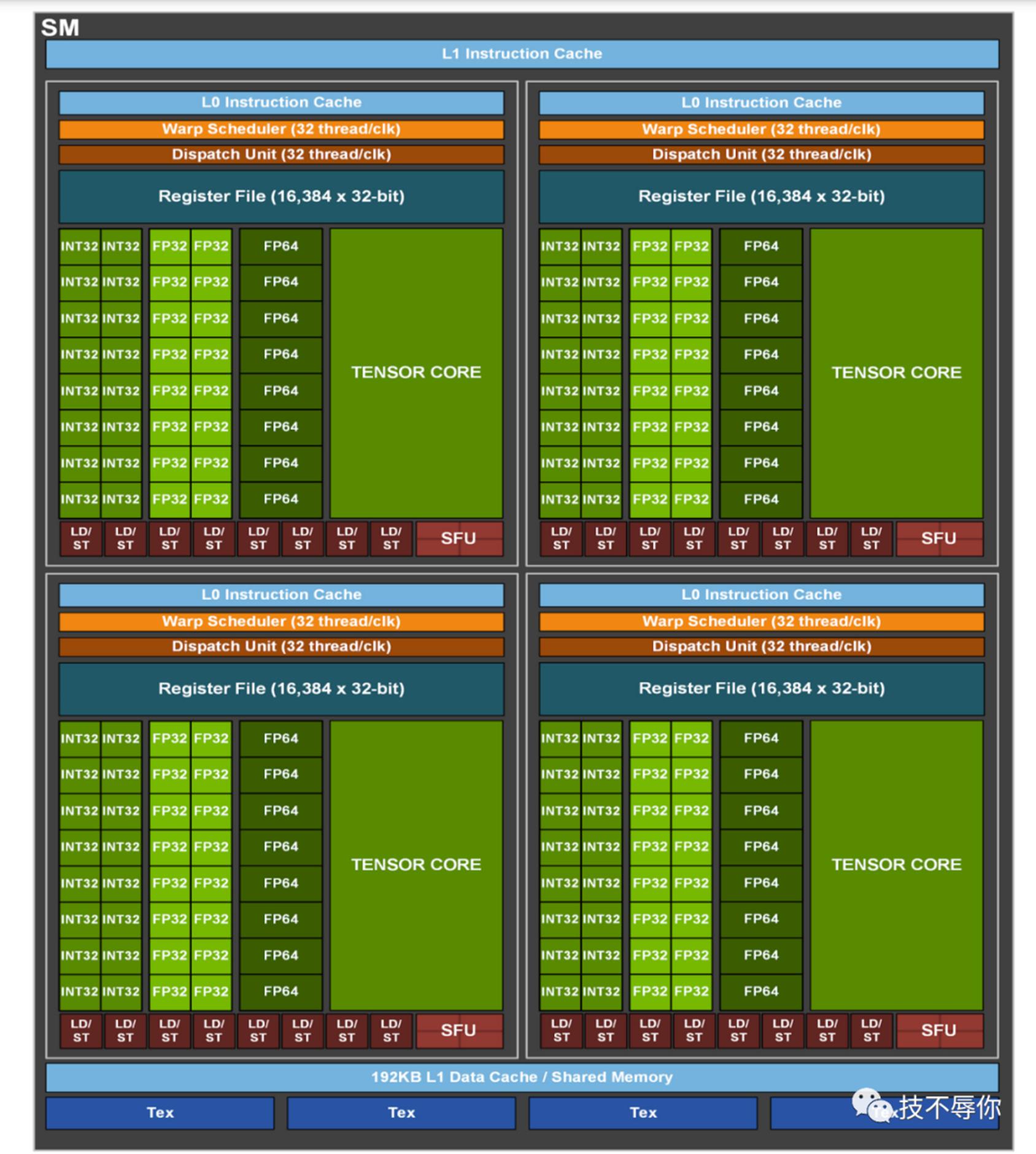
图9 a100 sm
A100 GPU上引入了第三代tensor core,新的TC支持了从INT4、INT8、FP16、TF32到FP64所有类型的数据运算。同时在性能上也要比V100 TC增加了很多,具体如下图所示:
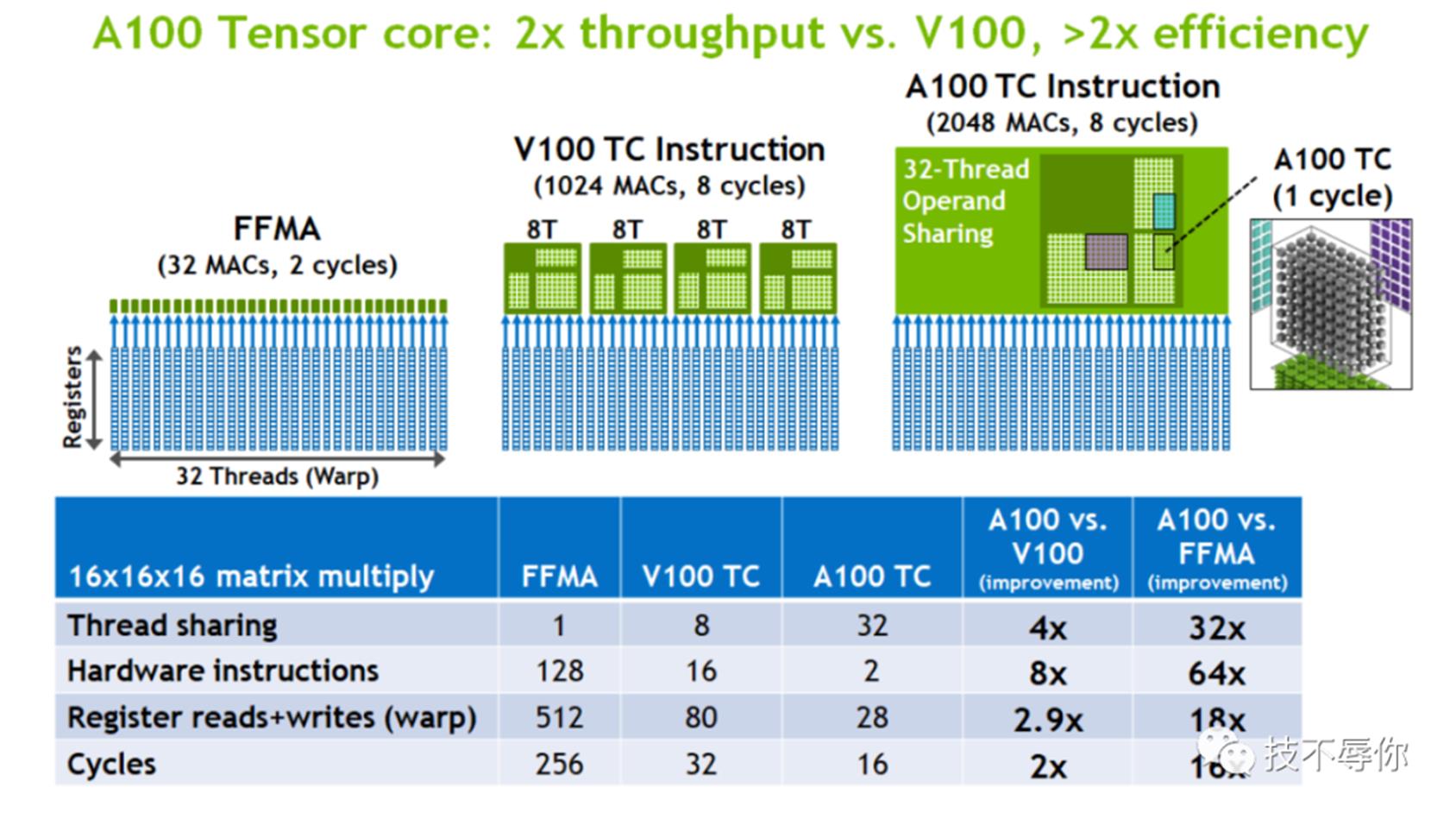
图10 A100 tc throughput and Efficiency
Hopper 架构之H100
Nvidia在2022年3月发布了Hopper系列gpu也即H100,每张H100 gpu 卡拥有144 颗SM,其中每个SM包含4颗SP。
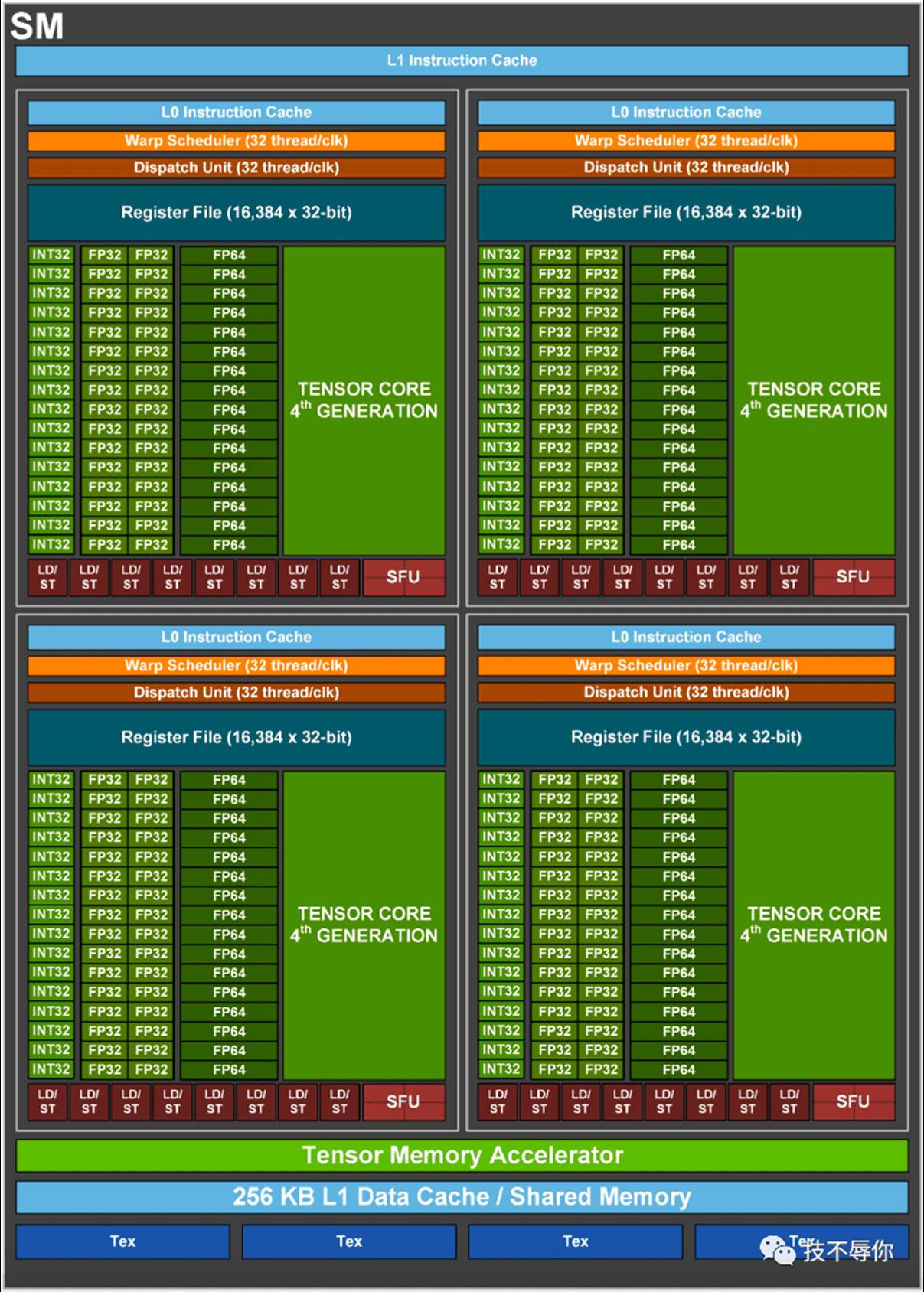
图11 H100 SM
如上图所示H100 的 SM当中引入了第四代的TENSOR CORE,与A100 的第三代tensor core相比H100的第四代tensor core在性能上又有了新的增强,具体如下:
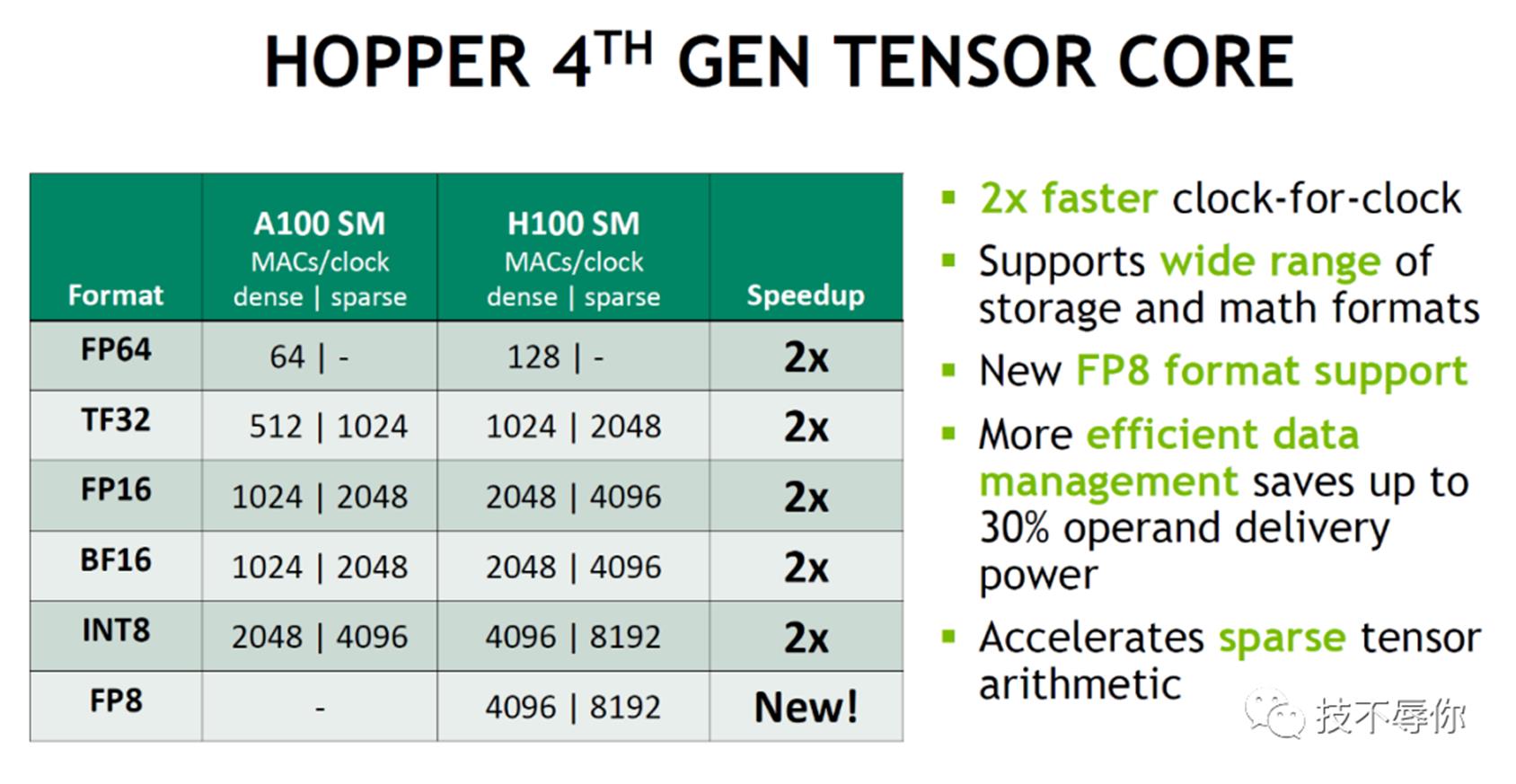
图12
GPU 底层调度
再聊调度之前,我们还是先来重点介绍几个相关的概念:channel、tsg、runlist、pbdma。
channel这是nv driver层的才有的概念,每一个gpu应用程序会创建一个或者多个channel。而channel也是gpu硬件(在gpu context 层面来说)操作的最小单位。
tsg全称为timeslice group,通常情况下一个tsg含有一个或者多个channel,这些channel 共享这个tsg的timeslice。
runlist多个tsg或者channel的集合,gpu硬件就是从runlist上选取channel来进行任务执行。
pbdma 全称为pushbuffer dma。push buffer可以简单的理解为一段主机内存,这段内存主要有cpu写然后gpu来读。gpu通过从pushbuffer 里面拿到的数据生成相应的command(也叫methods) 和data(address) 。而上面讲到的channel里面包含有指向pushbuffer的指针。
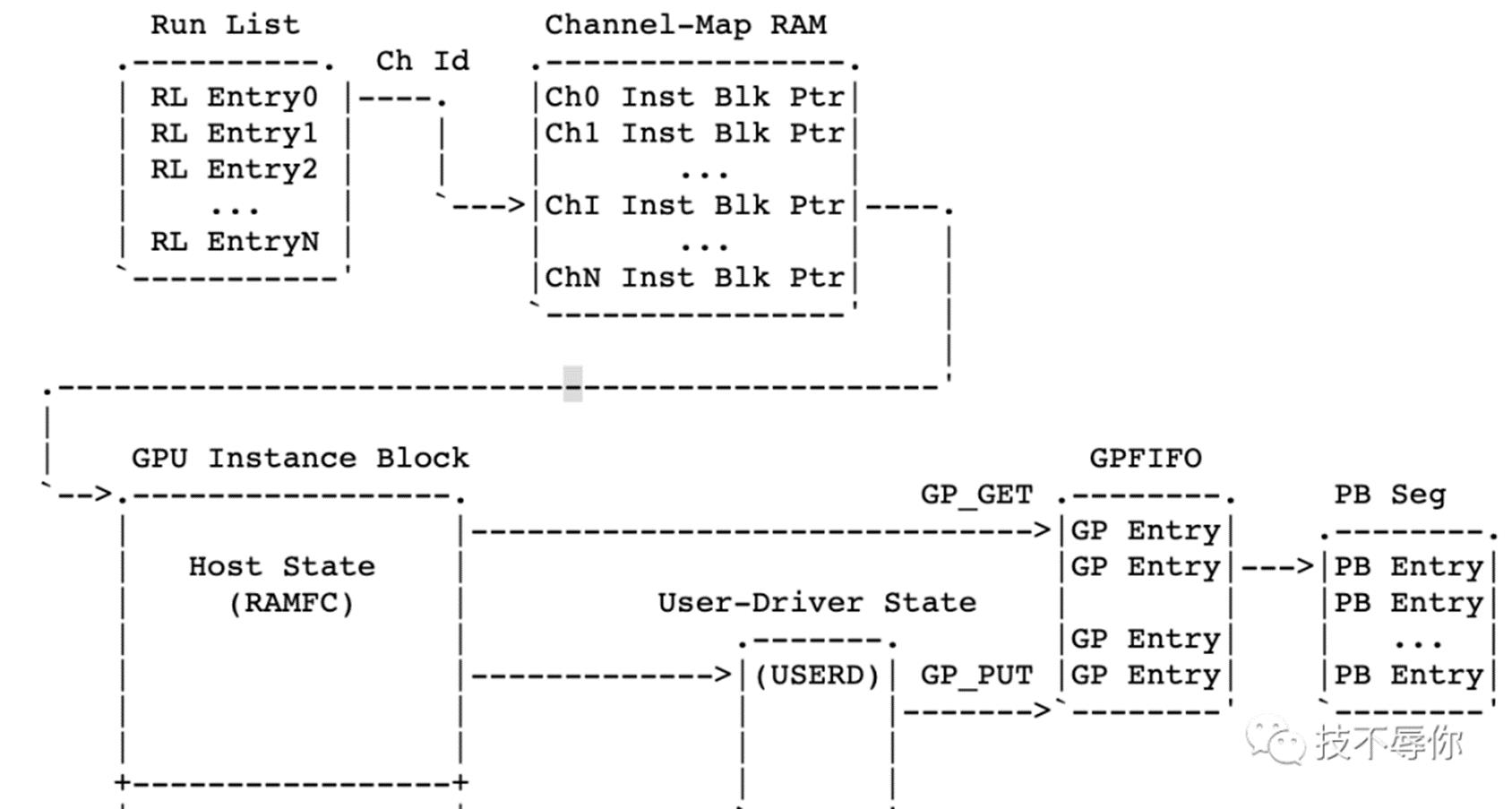
图13
结合图13再给大家理一下上面几个概念之前的一些关联。首先,runlist里面的每个entry就是一个channel,每个channel里面有Inst Blk Ptr 也即instance块指针,这些指针分别指向保存gpu上下文的内存和push buffer也即上图当中的PB seg。
接着我们先来简单的描述一下gpu应用是如何通过channel来提交任务的,具体流程如下:
Submitting new work to a channel involves the following steps:
1. Write methods to a pushbuffer segment
2. Construct a new GP entry pointing to that pushbuffer segment
3. Update GP_PUT in USERD( User-Driver Accessible RAM) to indicate the
new GP entry is ready
4. Request the doorbell handle from RM, given the channel ID
5. Write the channel\'s handle to the NOTIFY_CHANNEL_PENDING register
相信大家结合上面的一些讲述应该比较容易看懂上面的提交流程这里就不再赘述了,接下来我们回到调度正题上来。上面说到了应用提交work的相关流程,那这个work提交之后呢?这就涉及到如何将这些任务进行调度和执行了,下面我们先上一个整体调度架构图
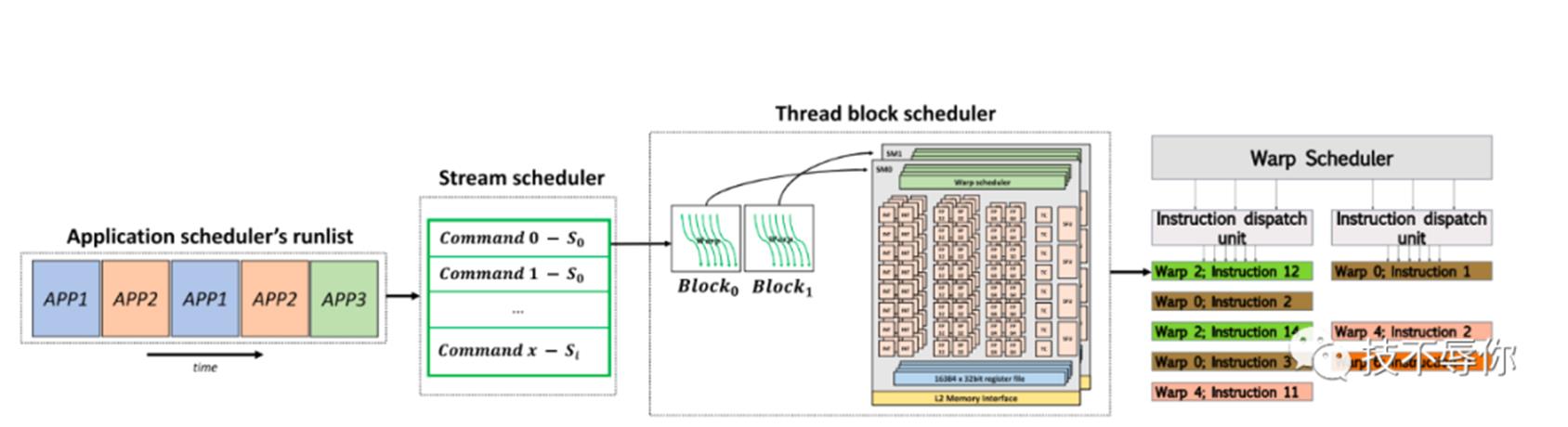
图14 gpu scheduler
gpu的整个调度结构如图14所示,从左到右依次为Application scheduler、stream scheduler、thread block scheduler和warp scheduler。下面我们来一一对他们进行介绍。
Application scheduler
通常情况下两个不同的gpu应用是不能同时占用gpu的计算单元的,他们只能通过时分复用的方法来使用gpu。具体来讲就是gpu按照FIFO的策略依次从runlist上拿取channel进行执行,每一个channel只能运行一定的时间,等时间片用完之后就会进行切换来运行其他的channel。但是这种时分复用的调度算法有一个缺陷就是如果App每次提交的任务都比较小就无法占满gpu SM从而导致了gpu 整体使用率比较低。为了解决这个问题,nvidia 又提出了一另外一种调试算法叫Multi-Process Service,我们也叫空分。在MPS的场景下它允许两个不同的应用能够在同一时刻去占用不同的gpu sm,从而来提高gpu的使用率。
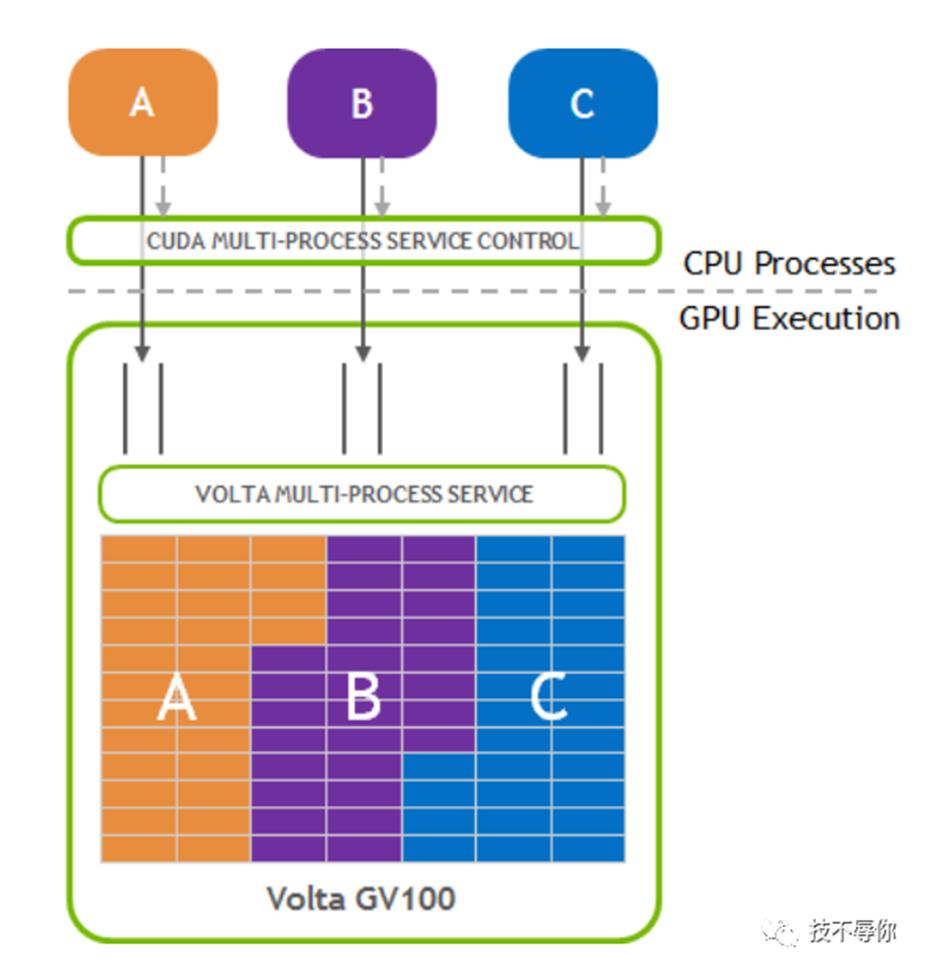
图15 MPS
stream scheduler
当gpu从runlist里面取出channel之后会生成相应的command和数据,而每个stream里面包含了一系列的commands。由于不同的应用的stream是可以设置不同的优先级的,所以stream scheduler主要负责不同应用的stream的调度和抢占。
Thread Block scheduler
它主要负责将thread block assign给gpu的sm,完成thread block跟gpu sm之间的一一映射。通常能不能将一个 kernel的thread block assign给某个sm主要看SM上的计算能力。举个例子,假如说一个sm支持 2048 threads和32 blocks,那么如果某个kernel有64个threads和64个blocks则scheduler也只能选这个kernel一半的blocks去运行。
warp scheduler
通常情况下一个warp包含了32个thread,warp scheduler的主要作用就是从wrap中获取准备好的待执行的instruction,并把这些instruction分配给sm上的Disaptch Unit。接着Dispatch Unit会把这些指令发送到SM的SIMD core上执行。
英伟达CUDA GPU编程原理介绍
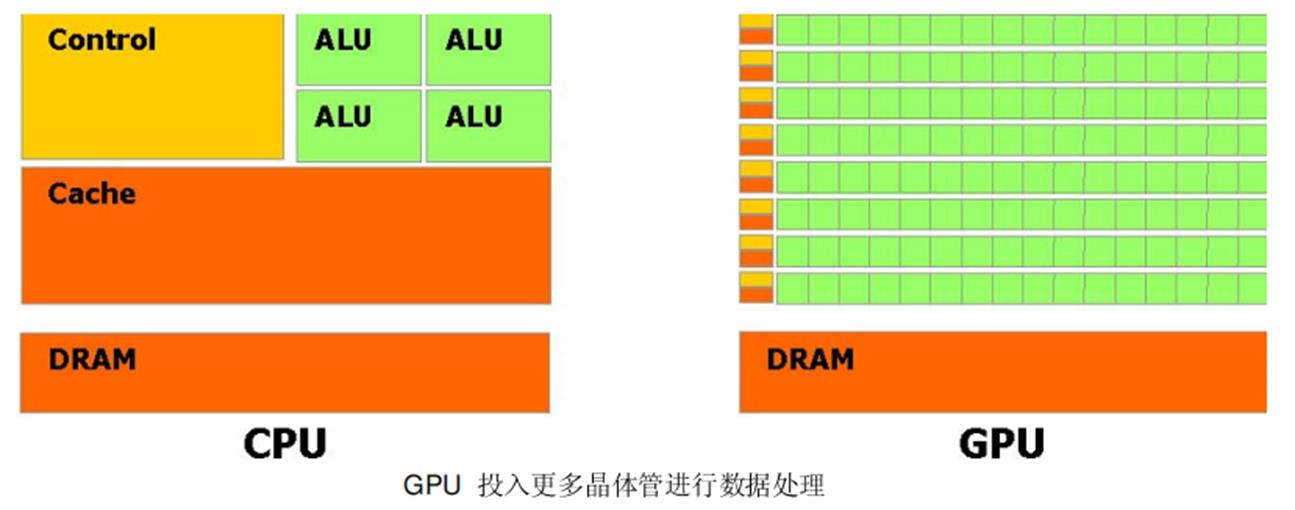
这个演变背后的主要原因是由于GPU 被设计用于高密度和并行计算,更确切地说是用于图形渲染。因此更多的晶体管被投入到数据处理而不是数据缓存和流量控制。
GPU 是特别适合于并行数据运算的问题-同一个程序在许多并行数据元素,并带有高运算密度(算术运算与内存操作的比例)。由于同一个程序要执行每个数据元素,降低了对复杂的流量控制要求; 并且,因为它执行许多数据元素并且据有高运算密度,内存访问的延迟可以被忽略。
并行数据处理,意味着数据元素以并行线程处理。许多处理大量数据集,例如数组的应用程序可以使用一个并行数据的编程模型来加速计算。在3D 渲染上,大的像素集和顶点被映射到并行线程。同样,图像和媒体处理的应用程序例如着色的图像后处理,录像编码和解码,图像缩放比例,立体视觉,以及图像识别也可以映射图像块和像素到并行处理线程。实际上,在图像着色和处理领域外的许多算法同样可以通过并行数据处理得到加速,从一般信号处理或物理模拟到金融计算或者生物计算。
然而直到今天,尽管强大的计算能力包装进了GPU,而它对非图形应用的有效支持依然有限:
- GPU 只能通过图型API 来编程,导致新手很难学习和非图形API 上很不充分的应用。
- GPU DRAM 可以用一般方式下读取,GPU 程序可以从任何DRAM 部分收集数据元素。但不可写,在一般方式下的GPU 程序不能写入信息到DRAM 的任何部分,相比CPU 丧失了很多编程的灵活性。
- 有些应用是由于DRAM 内存带宽而形成的瓶颈,未能充分利用GPU 的计算能力。
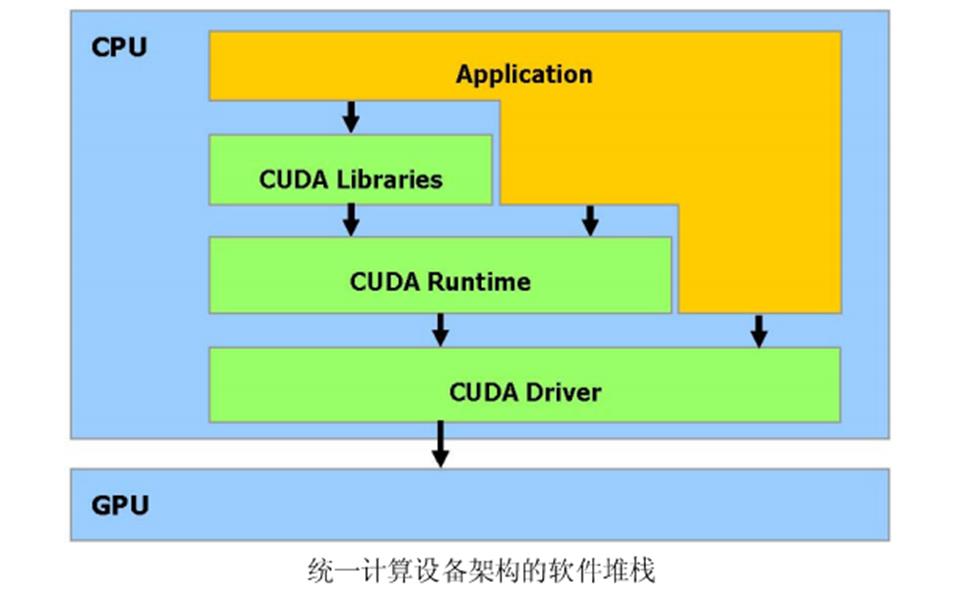
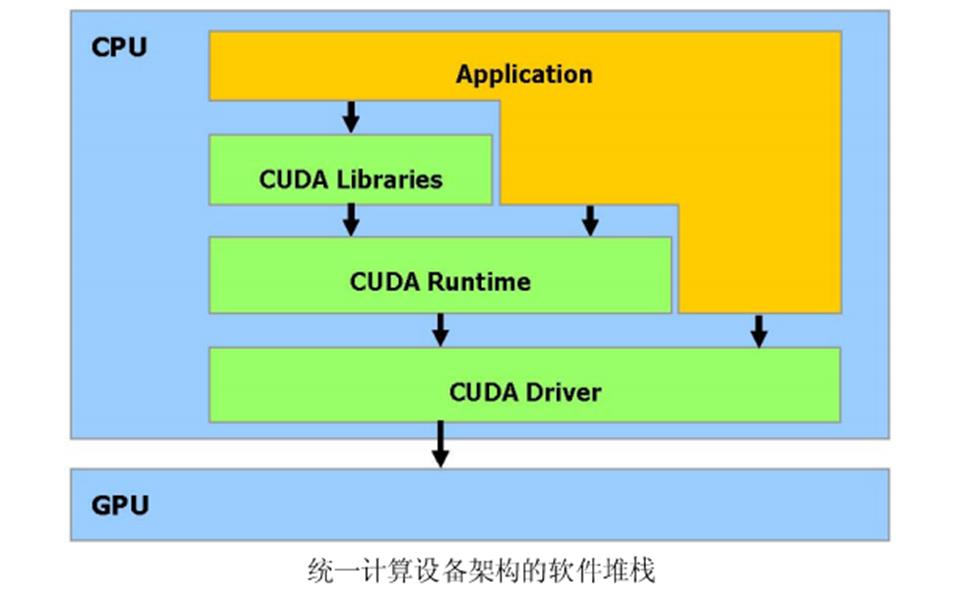
CUDA是一个在GPU 上计算的新架构CUDA(Compute Unified Device Architecture) 统一计算设备架构,在GPU 上发布的一个新的硬件和软件架构,它不需要映射到一个图型API 便可在GPU 上管理和进行并行数据计算。从G80 系列和以后的型号都可以支持。操作系统的多任务机制通过几个CUDA 和图型应用程序协调运行来管理访问GPU。
CUDA 软件堆栈由几层组成,如图所示:一个硬件驱动程序,一个应用程序编程接口(API)和它的Runtime, 还有二个高级的通用数学库,CUFFT 和CUBLAS。硬件被设计成支持轻量级的驱动和Runtime 层面,因而提高性能。
CUDA
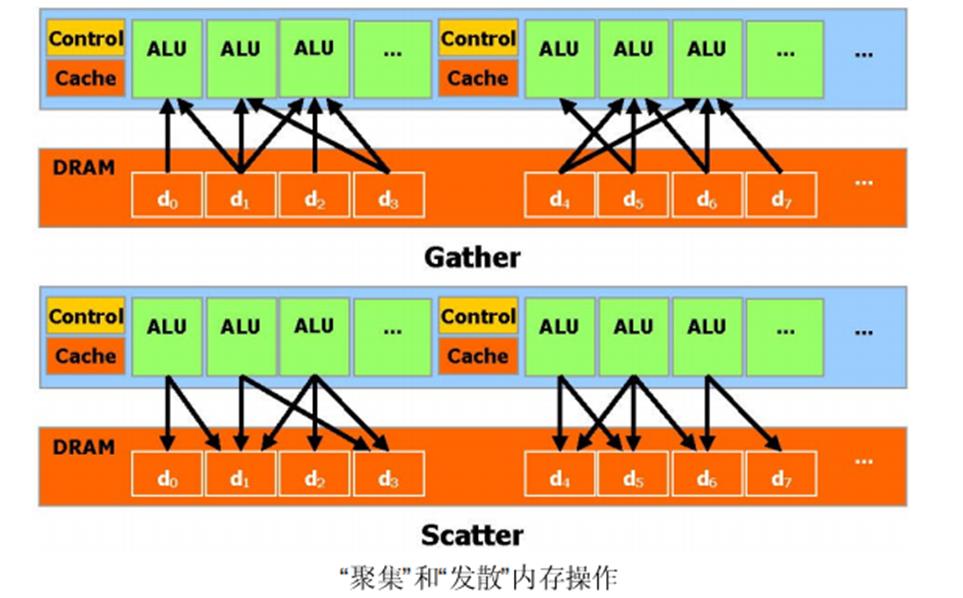
API 更像是C 语言的扩展,以便最小化学习的时间。CUDA 提供一般DRAM 内存寻址方式:“发散” 和“聚集”内存操作,如图所示。从而提供最大的编程灵活性。从编程的观点来看,它可以在DRAM的任何区域进行读写数据的操作,就像在CPU 上一样。
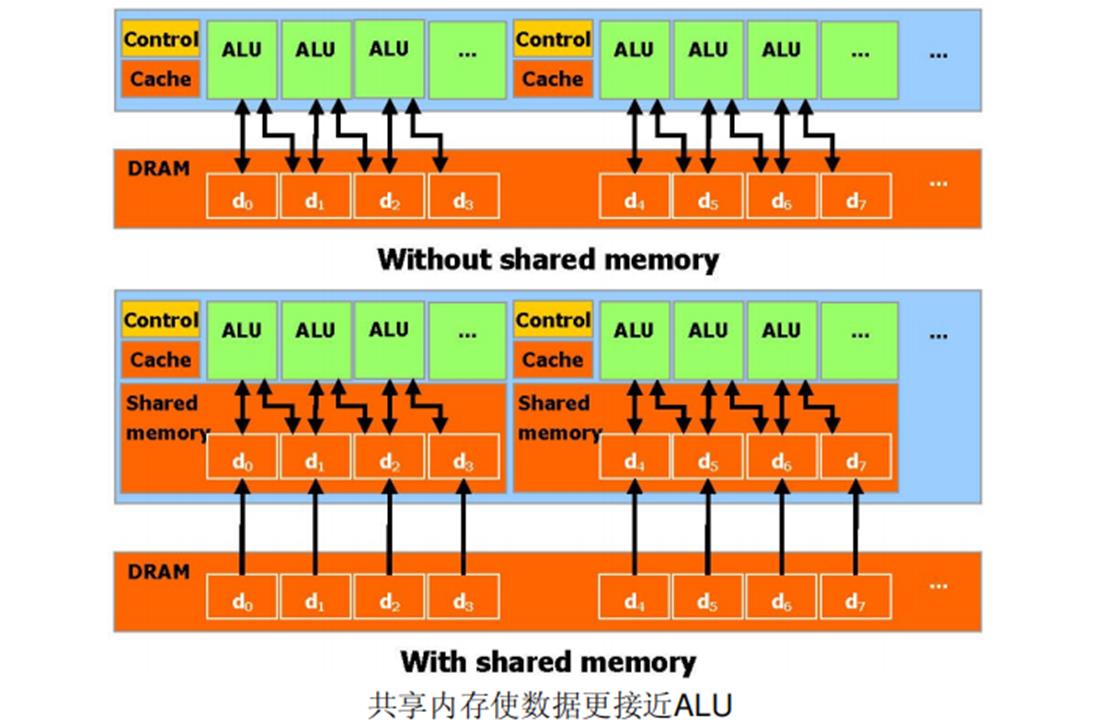
CUDA 允许并行数据缓冲或者在On-chip 内存共享,可以进行快速的常规读写存取,在线程之间共享数据。如图所示,应用程序可以最小化数据到DRAM 的overfetch 和round-trips ,从而减少对DRAM 内存带宽的依赖。
当通过CUDA 编译时,GPU 可以被视为能执行非常高数量并行线程的计算设备。它作为主CPU 的一个协处理器。换句话说,运行在主机上的并行数据和高密度计算应用程序部分,被卸载到这个设备上。
更准确地讲,一个被执行许多次不同数据的应用程序部分,可以被分离成为一个有很多不同线程在设备上执行的函数。达到这个效果,这个函数被编译成设备的指令集(kernel 程序),被下载到设备上。
主机和设备使用它们自己的DRAM,主机内存和设备内存。并可以通过利用设备高性能直接内存存取(DMA)的引擎(API)从一个DRAM 复制数据到其他DRAM。
线程批处理就是执行一个被组织成许多线程块的kernel,如图所示。
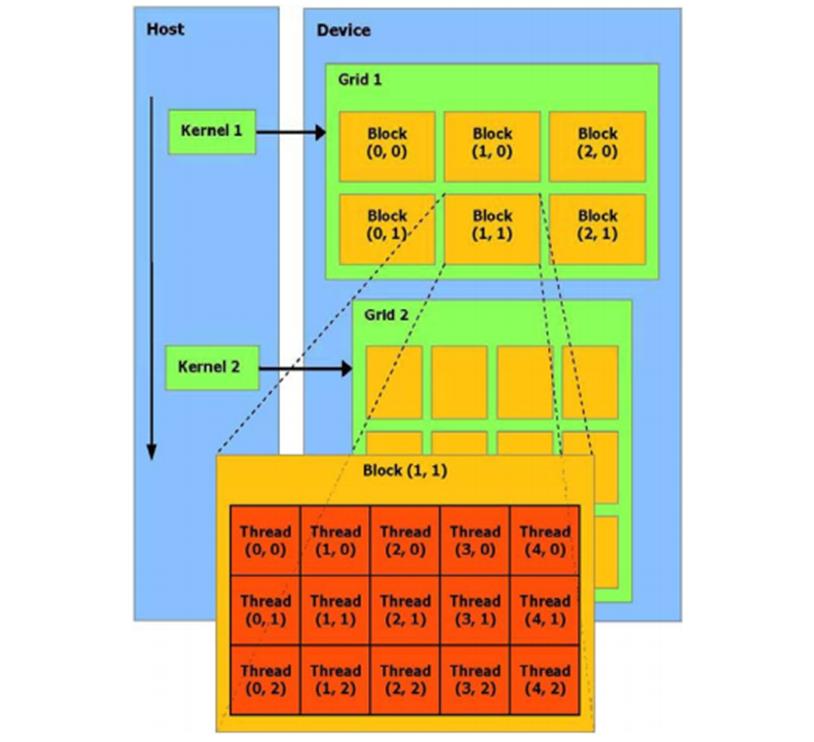
主机发送一个连续的kernel 调用到设备。每个kernel 作为一个由线程块组成的批处理线程来执行。一个线程块是一个线程的批处理,它通过一些快速的共享内存有效地分享数据并且在制定的内存访问中同步它们的执行。更准确地说,它可以在Kernel 中指定同步点,一个块里的线程被挂起直到它们所有都到达同步点。
为一个应用程序使用多GPU 作为CUDA 设备,必须保证这些GPU 是一样的类型。如果系统工作在SLI 模式下,那么只有一个GPU 可以作为CUDA 设备,由于所有的GPU 在驱动堆栈中被底层的融合了。SLI 模式需要在控制面板中关闭,这样才能事多个GPU 作为CUDA设备。
参考文献链接
https://mp.weixin.qq.com/s/u_lhA5Kg_8MLhneXEdJ_NQ
https://mp.weixin.qq.com/s/Kt4TQlg7N84fJi2R1PLluw
笔记CUDA - (异步)SIMT 架构
(异步)SIMT 架构
在 CUDA 编程模型中,线程是进行计算或内存操作的最低抽象级别。 从基于 NVIDIA Ampere GPU 架构的设备开始,CUDA 编程模型通过异步编程模型为内存操作提供加速。 异步编程模型定义了与 CUDA 线程相关的异步操作的行为。
异步编程模型为 CUDA 线程之间的同步定义了 异步屏障 的行为。 该模型还解释并定义了如何使用 cuda::memcpy_async 在 GPU计算时从全局内存中异步移动数据。
异步操作
异步操作定义为由CUDA线程发起的操作,并且与其他线程一样异步执行。在结构良好的程序中,一个或多个CUDA线程与异步操作同步。发起异步操作的CUDA线程不需要在同步线程中.
这样的异步线程(as-if 线程)总是与发起异步操作的 CUDA 线程相关联。异步操作使用同步对象来同步操作的完成。这样的同步对象可以由用户显式管理(例如,cuda::memcpy_async)或在库中隐式管理(例如,cooperative_groups::memcpy_async)。
同步对象可以是 cuda::barrier 或 cuda::pipeline。这些对象在 Asynchronous Barrier 和 Asynchronous Data Copies using cuda::pipeline 中进行了详细说明。这些同步对象可以在不同的线程范围内使用。作用域定义了一组线程,这些线程可以使用同步对象与异步操作进行同步。
下表定义了CUDA c++中可用的线程作用域,以及可以与每个线程同步的线程。
| Thread Scope | Description |
|---|---|
| cuda::thread_scope::thread_scope_thread | Only the CUDA thread which initiated asynchronous operations synchronizes. |
| cuda::thread_scope::thread_scope_block | All or any CUDA threads within the same thread block as the initiating thread synchronizes. |
| cuda::thread_scope::thread_scope_device | All or any CUDA threads in the same GPU device as the initiating thread synchronizes. |
| cuda::thread_scope::thread_scope_system | All or any CUDA or CPU threads in the same system as the initiating thread synchronizes. |
这些线程作用域是在CUDA 标准c++库 中作为标准c++的扩展实现的。
以上是关于Cuda架构,调度与编程杂谈的主要内容,如果未能解决你的问题,请参考以下文章