1、数据类型
int :如1、2、4等, 用于计算
bool: True , False ,用户判断
str: 储存少量数据,进行操作。
如:‘fdasklfjfladfl‘,‘而而噩噩‘,‘1234‘
list:储存大量数据。用中括号引起来。[‘哈哈‘,1324,34455,[1,2,3]],可以储存的数据很多。
tupe元组:只读列表。
(1,2,3,‘第三方‘)
dict:字典:储存大量关系型、成对的数据。
{‘云姐‘:[],‘二哥‘:[2000,200........]}
{‘name‘:‘云姐‘,‘age‘:16}
集合:{1,2,34,‘asdf‘}
2、int
bit_length:转换成二进制最小位数
i=5 print (i.bit_length())
3、bool
True False
数字与字符串转换
#int ------->str
i = 1 s = str(i)
#str ----> int
i = int (s)
# int ----->bool.
只要是0------>False, 非0 就是 True
i =3 b = bool(i) print(b)
#bool ------>int
True------->1
False------>0
ps:
while True: #效率低
pass
while 1 : #效率高
pass
# str ----->bool:字符串转换成布尔值
s =""(空字符串)------->False
s ="0"----------->True
if s: print (‘你输入的为空‘) else : pass
4、str
#字符串的索引与切片
s =‘ADCDLSRSRF‘
#索引
1 s1 = s[0] 2 print (s1)
对字符串进行操作会形成一个新的字符串,与原字符串无关。
s2 = s [2] print(s2)
#字符串的切片:顾头不顾尾
s=‘ABCD‘
s3 = s[0:3] print(s3) #ABC
s =‘ABCDLSRSRF‘#取最后一位 s3 = s[-1] #F s4 = s[-2] #R print(s3) print(s4)
#全取
s5 = s[0:]
s6 =[:]
#怎么跳着取
s =‘ADCDLSRSRF‘ s7 = s[0:5:2] # s[首:尾:步长] #ACL
#倒着取
s =‘ADCDLSRSRF‘ s11 = s[4:0:-1] #LDCB s12 = s[3::-1] #DCBA s12 = s[3::-2] #DB s13 =s[-1::-1] #RFSRSLDCBA s14= [::-1] #RFSRSLDCBA
5、字符串的操作
(1)#capitalize首字母大写
s =‘alexwusir‘ s1 =‘s.capitalize‘ print(s1) #Alexwusir
(2)#全部变成大写
s2 = s.upper() print(s2) ALEXWUSIR
#全部小写:
s21 = s. lower() print(s2,s21) #alexwusir
示例:验证码不区分大小写
(3)大小写反转
s3 = s.swapcase() print(s3)
# 每个用特殊字符和数字隔开的首字母大写
s = ‘alex*egon wusir‘ s4 = s.title() print(s4) #Alex*Egon Wusir
(4)#居中,空白填充
s =‘alexWUsir‘ s5 = s.center(20,#) print(s5) #####alexWUsir#####
(5)#\\t加上前面,不满八位的补充八位。
s = alex\\tWUsir s6 = s.expandtabs print(s6) #alex WUsir
(6)#公共方法(list,str,dict,tupe,通用):测量字符长度:len()
s =’alexwusir‘ l =len(s) print(l)
(7)判断字符串以什么为开头
#s.startswith() s = ‘alexWUsir‘ s7 = s.startswith(‘alex‘) if s7: pass elif s.startswith(‘bl‘): pass print(s7) #s7 = s.startswith(‘alex‘)----->True #s71 =s.startswith(‘e‘,2,5)-------->True
自己试 endswith 以什么为结尾?
#s.endswith() s = ‘alexWUsir‘ s7 = s.endswith(‘ex‘,0,5) if s7: pass(加内容) elif s.endswith(‘bl‘): pass(加内容) print(s7) #s7 = s.endwith(‘alex‘)----->False #s71 =s.endwith(‘e‘,2,5)-------->False
(8)#通过元素找索引,找不到返回-1
s =‘alexwusir‘ s8 =s. find(‘w‘) print (s8)
#4(返回对应下标)
找到返回下标数字,找不到返回-1
index通过元素找索引,找不到报错。
s =‘alexwusir‘ s8 =s. index(‘w‘) print (s8) #4(返回对应下标)
(9)#strip默认删除前后空格
s =‘ alexwusir ‘ s9 =s.strip() print(s9) ‘‘‘ username = input(‘请输入名字‘).strip()#删除用户输入时不小心加入的空格 if username == ‘春哥‘ print(‘.....‘) ‘‘‘
#strip还可删除特殊符号
s =‘alexWUsir%‘ s9 = s.strip(‘%‘) print(s9) #alexWUsir s=‘ *alexWUsir%‘ s91 = s.strip(‘ %*‘) print(s91) #strip rstrip lstrip
(10)count
s =‘alexaa wusirl‘ s10 =s.count(‘a‘) print (s10) #---->3 .若没有则返回0
#结合字符串切片
s =‘alexaa wusirl‘ s1 = s[0:3]#讲字符串s,切片。从[0,3),则s1=‘al‘ s2 =s1.count(‘a‘)#计算字符串s1中包含有多少个‘a’ print (s2) #-------->1
(11)split分割文本 (将str------>list)
s=‘alex:wusir:taibai‘ l = s.split(:)#以:为分隔符,分割字符串s print (l) ------>[alex:wusir:taibai]
(12)format 格式化输出
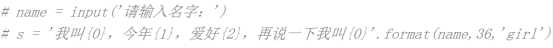
#第一种
s =‘我叫{},今天{},爱好{},再说一下我叫{}‘.format(‘太白‘,36,‘girl‘,‘太白‘)
print(s)
#第二种
s =‘我叫{0},今天{1},爱好{2},再说一下我叫{0}‘.format(‘太白‘,36,‘girl‘)
print(s)
#第三种
s =‘我叫{name},今天{age},爱好{hobby},再说一下我叫{name }‘.format(name =‘太白‘,age =36,hobby =‘girl‘)
print(s)
name = input(‘名字‘)
s =‘我叫{name},今天{age},爱好{hobby},再说一下我叫{name }‘.format(name =name,age =36,hobby =‘girl‘)
(13)replace 替换
##默认全部都替换

(14)、for 循环
‘‘‘s =‘fhajldfjl‘ for i in s : ‘‘‘ s =‘adSBadf‘ if ‘SB‘ in s: print(‘您的评论有敏感词..‘) #-------->您的评论有敏感词..