什么是数据库
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是数据库相关的知识,希望对你有一定的参考价值。
什么是数据库?数据库是以某种文件结构存储的一系列信息表,这种文件结构使您能够访问这些表、选择表中的列、对表进行排序以及根据各种标准选择行。数据库通常有多个 索引与这些表中的许多列相关联,所以我们能尽可能快地访问这些表。
以员工记录为例,您可以设想一个含有员工姓名、地址、工资、扣税以及津贴等内容的表。让我们考虑一下这些内容可能如何组织在一起。您可以设想一个表包含员工姓名、地址和电话号码。您希望保存的其它信息可能包括工资、工资范围、上次加薪时间、下次加薪时间、员工业绩评定等内容。
这些内容是否应保存在一个表格中?几乎可以肯定不应该如此。不同类别的员工的工资范围可能没有区别;这样,您可以仅将员工类型储存在员工记录表中,而将工资范围储存在另一个表中,通过类型编号与这个表关联。考虑以下情况:
Key Lastname SalaryType SalaryType Min Max
1 Adams 2 1 30000 45000
2 Johnson 1 2 45000 60000
3 Smyth 3 3 60000 75000
4 Tully 1
5 Wolff 2
SalaryType 列中的数据引用第二个表。我们可以想象出许多种这样的表,如用于存储居住城市和每个城市的税值、健康计划扣除金额等的表。每个表都有一个主键列(如上面两个表中最左边的列)和若干数据列。在数据库中建立表格既是一门艺术,也是一门科学。这些表的结构由它们的范式指出。我们通常说表属于1NF、2NF 或 3NF。
第一范式:表中的每个表元应该只有一个值(永远不可能是一个数组)。(1NF)
第二范式:满足 1NF,并且每一个非主键列完全依赖于主键列。这表示主键和该行中的剩余表元之间是 1 对 1 的关系。(2NF)
第三范式:满足 2NF,并且所有非主键列是互相独立的。任何一个数据列中包含的值都不能从其他列的数据计算得到。(3NF)
现在,几乎所有的数据库都是基于“第三范式 (3NF)”创建的。这意味着通常都有相当多的表,每个表中的信息列都相对较少。
从数据库中获取数据
假设我们希望生成一个包含员工及其工资范围的表,在我们设计的一个练习中将使用这个表。这个表格不是直接存在在数据库中,但可以通过向数据库发出一个查询来构建它。我们希望得到如下所示的一个表:
Name Min Max
Tully $30,000.00 $45,000.00
Johnson $30,000.00 $45,000.00
Wolff $45,000.00 $60,000.00
Adams $45,000.00 $60,000.00
Smyth $60,000.00 $75,000.00
我们发现,获得这些表的查询形式如下所示
SELECT DISTINCTROW Employees.Name, SalaryRanges.Min,
SalaryRanges.Max FROM Employees INNER JOIN SalaryRanges ON Employees.SalaryKey = SalaryRanges.SalaryKey
ORDER BY SalaryRanges.Min;
这种语言称为结构化查询语言,即 SQL,而且它是几乎目前所有数据库都可以使用的一种语言。SQL-92 标准被认为是一种基础标准,而且已更新多次。
数据库的种类
PC 上的数据库,如 dBase、Borland Paradox、Microsoft Access 和 FoxBase。
数据库服务器:IBM DB/2、Microsoft SQL Server、 Oracle、Sybase、SQLBase 和 XDB。
所有这些数据库产品都支持多种相对类似的 SQL 方言,因此,所有数据库最初看起来好象可以互换。每种数据库都有不同的性能特征,而且每一种都有不同的用户界面和编程接口。
ODBC
如果我们能够以某种方式编写不依赖于特定厂商的数据库的代码,并且能够不改变自己的调用程序即可从这些数据库中得到相同的结果,那将是一件很好的事。如果我们可以仅为所有这些数据库编写一些封装,使它们具有相似的编程接口,这种对数据库编程独立于供应商的特性将很容易实现。
什么是 JDBC?
JDBC 是对 ODBC API 进行的一种面向对象的封装和重新设计,它易于学习和使用,并且它真正能够使您编写不依赖厂商的代码,用以查询和操纵数据库。尽管它与所有 Java API 一样,都是面向对象的,但它并不是很高级别的对象集.
除 Microsoft 之外,多数厂商都采用了 JDBC,并为其数据库提供了 JDBC 驱动程序;这使您可轻松地真正编写几乎完全不依赖数据库的代码。另外,JavaSoft 和 Intersolv 已开发了一种称为 JDBC-ODBC Bridge 的产品,可使您连接还没有直接的 JDBC 驱动程序的数据库。支持 JDBC 的所有数据库必须至少可以支持 SQL-92 标准。这在很大程度上实现了跨数据库和平台的可移植性。
安装和使用 JDBC
JDBC 的类都被归到 java.sql 包中,在安装 Java JDK 1.4时会自动安装。然而,如果您想使用 JDBC-ODBC 桥。JDBC-ODBC 驱动程序可从 Sun 的 Java 网站 (http://java.sun.com/) 轻松地找到并下载。在您扩充并安装了这个驱动程序后,必须执行下列步骤:
将 \jdbc-odbc\classes; 路径添加到您的 PATH 环境变量中。
将 \jdbc-odbc\classes; 路径添加到您的 CLASSPATH 环境变量中。
JDBC 驱动程序的类型
Java 程序连接数据库的方法实际上有四种:
1. JDBC-ODBC 桥和 ODBC 驱动程序 -- 在这种方式下,这是一个本地解决方案,因为 ODBC 驱动程序和桥代码必须出现在用户的每台机器中。从根本上说这是一个临时解决方案。
2. 本机代码和 Java 驱动程序 -- 它用另一个本地解决方案(该平台上的 Java 可调用的本机代码)取代 ODBC 和 JDBC-ODBC 桥。
3. JDBC 网络的纯 Java 驱动程序 -- 由 Java 驱动程序翻译的 JDBC 形成传送给服务器的独立协议。然后,服务器可连接任何数量的数据库。这种方法使您可能从客户机 Applet 中调用服务器,并将结果返回到您的 Applet。在这种情况下,中间件软件提供商可提供服务器。
4. 本机协议 Java 驱动程序 -- Java 驱动程序直接转换为该数据库的协议并进行调用。这种方法也可以通过网络使用,而且可以在 Web 浏览器的 Applet 中显示结果。在这种情况下,每个数据库厂商将提供驱动程序。
如果您希望编写代码来处理 PC 客户机数据库,如 dBase、Foxbase 或 Access,则您可能会使用第一种方法,并且拥有用户机器上的所有代码。更大的客户机-服务器数据库产品(如 IBM 的 DB2)已提供了第 3 级别的驱动程序。
两层模型和三层模型
当数据库和查询它的应用程序在同一台机器上,而且没有服务器代码的干预时,我们将生成的程序称为两层模型。一层是应用程序,而另一层是数据库。在 JDBC-ODBC 桥系统中通常是这种情况。
当一个应用程序或 applet 调用服务器,服务器再去调用数据库时,我们称其为三层模型。当您调用称为“服务器”的程序时通常是这种情况。
编写 JDBC 代码访问数据库
用 ODBC 注册您的数据库
连接数据库
所有与数据库有关的对象和方法都在 java.sql 包中,因此在使用 JDBC 的程序中必须加入 "import java.sql.* "。 JDBC 要连接 ODBC 数据库,您必须首先加载 JDBC-ODBC 桥驱动程序
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
该语句加载驱动程序,并创建该类的一个实例。然后,要连接一个特定的数据库,您必须创建 Connect 类的一个实例,并使用 URL 语法连接数据库。
String url = "jdbc:odbc:Northwind";
Connection con = DriverManager.getConnection(url);
请注意,您使用的数据库名是您在 ODBC 设置面板中输入的“数据源”名称。
URL 语法可能因数据库类型的不同而变化极大。
jdbc:subprotocol:subname
第一组字符代表连接协议,并且始终是 jdbc。还可能有一个子协议,在此处,子协议被指定为 odbc。它规定了一类数据库的连通性机制。如果您要连接其它机器上的数据库服务器,可能也要指定该机器和一个子目录:
jdbc:bark//doggie/elliott
最后,您可能要指定用户名和口令,作为连接字符串的一部分:
jdbc:bark//doggie/elliot;UID=GoodDog;PWD=woof
访问MSSQL Server方法:(驱动程序需要:msutil.jar,msbase.jar,mssqlServer.jar)
DBDriver=com.microsoft.jdbc.sqlserver.SQLServerDriver
URL=jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=demo
username=sa
password=
maxcon=10
mincon=1
poolName=SkyDev
利用我们开发的数据库类,使用方法如下:
DbObject DbO = new DbObject(new SqlServerConnectionFactory("localhost",
1433, "demo", "sa", ""));
Connection con = DbO.getConnection();
//类代码(不含连接工厂实现)
package skydev.modules.data;
public final class SqlServerConnectionFactory
extends ConnectionFactory
private final String dbDriver =
"com.microsoft.jdbc.sqlserver.SQLServerDriver";
private String host;
private int port;
private String databaseName;
public SqlServerConnectionFactory()
super.setDriverName(dbDriver);
/**
*
* @param host 数据库所在的主机名:如"localhost"
* @param port SQL服务器运行的端口号,如果使用缺省值 1433,传入一个负数即可
* @param databaseName 数据库名称
* @param userName 用户名
* @param password 口令
*/
public SqlServerConnectionFactory(String host,
int port,
String databaseName,
String userName,
String password)
this.setHost(host);
this.setPort(port);
this.setDatabaseName(databaseName);
this.setUserName(userName);
this.setPassword(password);
init();
private void init()
super.setDriverName(dbDriver);
super.setUrl("jdbc:microsoft:sqlserver://" + host.trim() + ":" +
new Integer(port).toString() + ";DatabaseName=" +
databaseName.trim());
//super.setUrl("jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=demo");
……
//------------------------------------------------------------------------------------
访问MySQL的方法:
DBDriver=com.mysql.jdbc.Driver
URL=jdbc:mysql://localhost/demo
username=
password=
maxcon=5
mincon=1
poolName=zhengmao
访问数据库
一旦连接到数据库,就可以请求表名以及表列的名称和内容等信息,而且您可以运行 SQL 语句来查询数据库或者添加或修改其内容。可用来从数据库中获取信息的对象有:
DatabaseMetaData 有关整个数据库的信息:表名、表的索引、数据库产品的名称和版本、数据库支持的操作。
ResultSet 关于某个表的信息或一个查询的结果。您必须逐行访问数据行,但是您可以任何顺序访问列。
ResultSetMetaData 有关 ResultSet 中列的名称和类型的信息。
尽管每个对象都有大量的方法让您获得数据库元素的极为详细的信息,但在每个对象中都有几种主要的方法使您可获得数据的最重要信息。然而,如果您希望看到比此处更多的信息,建议您学习文档以获得其余方法的说明。
ResultSet
ResultSet 对象是 JDBC 中最重要的单个对象。从本质上讲,它是对一个一般宽度和未知长度的表的一种抽象。几乎所有的方法和查询都将数据作为 ResultSet 返回。ResultSet 包含任意数量的命名列,您可以按名称访问这些列。它还包含一个或多个行,您可以按顺序自上而下逐一访问。在您使用 ResultSet 之前,必须查询它包含多少个列。此信息存储在 ResultSetMetaData 对象中。
//从元数据中获得列数
ResultSetMetaData rsmd;
rsmd = results.getMetaData();
numCols = rsmd.getColumnCount();
当您获得一个 ResultSet 时,它正好指向第一行之前的位置。您可以使用 next() 方法得到其他每一行,当没有更多行时,该方法会返回 false。由于从数据库中获取数据可能会导致错误,您必须始终将结果集处理语句包括在一个 try 块中。
您可以多种形式获取 ResultSet 中的数据,这取决于每个列中存储的数据类型。另外,您可以按列序号或列名获取列的内容。请注意,列序号从 1 开始,而不是从 0 开始。ResultSet 对象的一些最常用方法如下所示。
getInt(int); 将序号为 int 的列的内容作为整数返回。
getInt(String); 将名称为 String 的列的内容作为整数返回。
getFloat(int); 将序号为 int 的列的内容作为一个 float 型数返回。
getFloat(String); 将名称为 String 的列的内容作为 float 型数返回。
getDate(int); 将序号为 int 的列的内容作为日期返回。
getDate(String); 将名称为 String 的列的内容作为日期返回。
next(); 将行指针移到下一行。如果没有剩余行,则返回 false。
Close(); 关闭结果集。
getMetaData(); 返回 ResultSetMetaData 对象。
ResultSetMetaData
您使用 getMetaData() 方法从 ResultSet 中获取 ResultSetMetaData 对象。您可以使用此对象获得列的数目和类型以及每一列的名称。
getColumnCount(); 返回 ResultSet 中的列数。
getColumnName(int); 返回列序号为 int 的列名。
getColumnLabel(int); 返回此列暗含的标签。
isCurrency(int); 如果此列包含带有货币单位的一个数字,则返回 true。
isReadOnly(int); 如果此列为只读,则返回 true。
isAutoIncrement(int); 如果此列自动递增,则返回 true。这类列通常为键,而且始终是只读的。
getColumnType(int); 返回此列的 SQL 数据类型。这些数据类型包括
BIGINT
BINARY
BIT
CHAR
DATE
DECIMAL
DOUBLE
FLOAT
INTEGER
LONGVARBINARY
LONGVARCHAR
NULL
NUMERIC
OTHER
REAL
SMALLINT
TIME
TIMESTAMP
TINYINT
VARBINARY
VARCHAR
DatabaseMetaData
DatabaseMetaData 对象可为您提供整个数据库的信息。您主要用它获取数据库中表的名称,以及表中列的名称。由于不同的数据库支持不同的 SQL 变体,因此,也有多种方法查询数据库支持哪些 SQL 方法。
getCatalogs() 返回该数据库中的信息目录列表。使用 JDBC-ODBC Bridge 驱动程序,您可以获得用 ODBC 注册的数据库列表。这很少用于 JDBC-ODBC 数据库。
getTables(catalog, schema,tableNames, columnNames) 返回表名与 tableNames 相符而且列名与 columnNames 相符的所有表的说明。
getColumns(catalog, schema,tableNames, columnNames) 返回表名与 tableNames 相符而且列名与 columnNames 相符的所有表列说明。
getURL(); 获得您所连接的 URL 名称。
getDriverName(); 获得您所连接的数据库驱动程序的名称。
获取有关表的信息
您可以使用 DataBaseMetaData 的 getTables() 方法来获取数据库中表的信息。这个方法有如下4个 String 参数:
results =dma.getTables(catalog, schema, tablemask, types[]);
其中参数的意义是:
Catalog 要在其中查找表名的目录名。对于 JDBC-ODBC 数据库以及许多其他数据库而言,可将其设置为 null。这些数据库的目录项实际上是它在文件系统中的绝对路径名称。
Schema 要包括的数据库“方案”。许多数据库不支持方案,而对另一些数据库而言,它代表数据库所有者的用户名。一般将它设置为 null。
Tablemask 一个掩码,用来描述您要检索的表的名称。如果您希望检索所有表名,则将其设为通配符 %。请注意,SQL 中的通配符是 % 符号,而不是一般 PC 用户的 * 符号。
types[] 这是描述您要检索的表的类型的 String 数组。数据库中通常包括许多用于内部处理的表,而对作为用户的您没什么价值。如果它是空值,则您会得到所有这些表。如果您将其设为包含字符串“TABLES”的单元素数组,您将仅获得对用户有用的表格。
一个简单的 JDBC 程序
我们已经学习了 JDBC 的所有基本功能,现在我们可以编写一个简单的程序,该程序打开数据库,打印它的表名以及某一表列的内容,然后对该数据库执行查询。此程序如下所示:
package skydevkit;
import java.sql.*;
public class JdbcOdbc_test
ResultSet results;
ResultSetMetaData rsmd;
DatabaseMetaData dma;
Connection con;
public JdbcOdbc_test() throws SQLException
String url = "jdbc:odbc:Northwind";
try
//加载 JDBC-ODBC 桥驱动程序
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
con = DriverManager.getConnection(url);//连接数据库
dma = con.getMetaData();//获取数据库的元数据
System.out.println("Connected to:" + dma.getURL());
System.out.println("Driver " + dma.getDriverName());
catch (Exception e)
System.out.println(e);
try
Statement stmt = con.createStatement();
results = stmt.executeQuery("select * from 客户;");
ResultSetMetaData resultMetaData = results.getMetaData();
int cols = resultMetaData.getColumnCount();
String resultRow = "";
for (int i = 1; i < cols; i++)
resultRow += resultMetaData.getColumnName(i) + ";";
System.out.println(resultRow);
while (results.next())
resultRow = "";
for (int i = 1; i < cols; i++)
try
resultRow += results.getString(i) + ";";
catch (NullPointerException e)
System.out.println(e.getMessage());
System.out.println(resultRow);
catch (Exception e)
System.out.println("query exception");
finally
results.close();
补充高级内容
关于调用SQLServer存储过程的例子:(用到了我们开发的数据库连接类)
CREATE PROCEDURE [dbo].[sp_getStudentByName](@name char(10))
AS
Select * from Students where [Name]=@name
GO
DbObject DbO = new DbObject(new SqlServerConnectionFactory("localhost",
1433, "demo", "sa", ""));
Connection con = DbO.getConnection();
CallableStatement pstmt = null;
System.out.println("TestDB1()............");
/* try
pstmt = con.prepareCall("call sp_getStudentById(?)");
pstmt.setInt(1, 1);
*/
try
pstmt = con.prepareCall("call sp_getStudentByName(?)"); //注意参数如何传递
pstmt.setString(1, "Tom");
……
使用输出参数:
CREATE PROCEDURE [dbo].[sp_insertStudent](@name char(10),@age int,@id int OUTPUT) AS
insert into Students([Name],[Age]) values (@name,@age)
select @id=@@IDENTITY
GO
try
pstmt = con.prepareCall("call sp_insertStudent(?,?,?)");
pstmt.setString(1, "zengqingsong");
pstmt.setInt(2, 22);
pstmt.registerOutParameter(3, Types.INTEGER);
pstmt.executeUpdate();
int id = pstmt.getInt(3);
System.out.println(id);
使用返回参数的例子:
CREATE PROCEDURE [dbo].[sp_insertStudent](@name char(10),@age int,@id int OUTPUT) AS
insert into Students([Name],[Age]) values (@name,@age)
select @id=@@IDENTITY –测试输出参数
return 30 –测试返回30
GO
try
pstmt = con.prepareCall("?=call sp_insertStudent(?,?,?)");
pstmt.setString(2, "zengqingsong");
pstmt.setInt(3, 22);
pstmt.registerOutParameter(4, Types.INTEGER);
pstmt.registerOutParameter(1, Types.INTEGER);
int ret = pstmt.executeUpdate(); //执行影响的行数
int ret2 = pstmt.getInt(1); //返回参数(输出参数)
int id = pstmt.getInt(4); //输出参数
System.out.println(ret);
System.out.println(ret2);
System.out.println(id);
参考资料:百度知道
参考技术A 什么是数据库?数据库是以某种文件结构存储的一系列信息表,这种文件结构使您能够访问这些表、选择表中的列、对表进行排序以及根据各种标准选择行。数据库通常有多个 索引与这些表中的许多列相关联,所以我们能尽可能快地访问这些表。
以员工记录为例,您可以设想一个含有员工姓名、地址、工资、扣税以及津贴等内容的表。让我们考虑一下这些内容可能如何组织在一起。您可以设想一个表包含员工姓名、地址和电话号码。您希望保存的其它信息可能包括工资、工资范围、上次加薪时间、下次加薪时间、员工业绩评定等内容。
这些内容是否应保存在一个表格中?几乎可以肯定不应该如此。不同类别的员工的工资范围可能没有区别;这样,您可以仅将员工类型储存在员工记录表中,而将工资范围储存在另一个表中,通过类型编号与这个表关联。考虑以下情况:
Key Lastname SalaryType SalaryType Min Max
1 Adams 2 1 30000 45000
2 Johnson 1 2 45000 60000
3 Smyth 3 3 60000 75000
4 Tully 1
5 Wolff 2
SalaryType 列中的数据引用第二个表。我们可以想象出许多种这样的表,如用于存储居住城市和每个城市的税值、健康计划扣除金额等的表。每个表都有一个主键列(如上面两个表中最左边的列)和若干数据列。在数据库中建立表格既是一门艺术,也是一门科学。这些表的结构由它们的范式指出。我们通常说表属于1NF、2NF 或 3NF。
第一范式:表中的每个表元应该只有一个值(永远不可能是一个数组)。(1NF)
第二范式:满足 1NF,并且每一个非主键列完全依赖于主键列。这表示主键和该行中的剩余表元之间是 1 对 1 的关系。(2NF)
第三范式:满足 2NF,并且所有非主键列是互相独立的。任何一个数据列中包含的值都不能从其他列的数据计算得到。(3NF)
现在,几乎所有的数据库都是基于“第三范式 (3NF)”创建的。这意味着通常都有相当多的表,每个表中的信息列都相对较少。
从数据库中获取数据
假设我们希望生成一个包含员工及其工资范围的表,在我们设计的一个练习中将使用这个表。这个表格不是直接存在在数据库中,但可以通过向数据库发出一个查询来构建它。我们希望得到如下所示的一个表:
Name Min Max
Tully $30,000.00 $45,000.00
Johnson $30,000.00 $45,000.00
Wolff $45,000.00 $60,000.00
Adams $45,000.00 $60,000.00
Smyth $60,000.00 $75,000.00
我们发现,获得这些表的查询形式如下所示
SELECT DISTINCTROW Employees.Name, SalaryRanges.Min,
SalaryRanges.Max FROM Employees INNER JOIN SalaryRanges ON Employees.SalaryKey = SalaryRanges.SalaryKey
ORDER BY SalaryRanges.Min;
这种语言称为结构化查询语言,即 SQL,而且它是几乎目前所有数据库都可以使用的一种语言。SQL-92 标准被认为是一种基础标准,而且已更新多次。
数据库的种类
PC 上的数据库,如 dBase、Borland Paradox、Microsoft Access 和 FoxBase。
数据库服务器:IBM DB/2、Microsoft SQL Server、 Oracle、Sybase、SQLBase 和 XDB。
所有这些数据库产品都支持多种相对类似的 SQL 方言,因此,所有数据库最初看起来好象可以互换。每种数据库都有不同的性能特征,而且每一种都有不同的用户界面和编程接口。
ODBC
如果我们能够以某种方式编写不依赖于特定厂商的数据库的代码,并且能够不改变自己的调用程序即可从这些数据库中得到相同的结果,那将是一件很好的事。如果我们可以仅为所有这些数据库编写一些封装,使它们具有相似的编程接口,这种对数据库编程独立于供应商的特性将很容易实现。
什么是 JDBC?
JDBC 是对 ODBC API 进行的一种面向对象的封装和重新设计,它易于学习和使用,并且它真正能够使您编写不依赖厂商的代码,用以查询和操纵数据库。尽管它与所有 Java API 一样,都是面向对象的,但它并不是很高级别的对象集.
除 Microsoft 之外,多数厂商都采用了 JDBC,并为其数据库提供了 JDBC 驱动程序;这使您可轻松地真正编写几乎完全不依赖数据库的代码。另外,JavaSoft 和 Intersolv 已开发了一种称为 JDBC-ODBC Bridge 的产品,可使您连接还没有直接的 JDBC 驱动程序的数据库。支持 JDBC 的所有数据库必须至少可以支持 SQL-92 标准。这在很大程度上实现了跨数据库和平台的可移植性。
安装和使用 JDBC
JDBC 的类都被归到 java.sql 包中,在安装 Java JDK 1.4时会自动安装。然而,如果您想使用 JDBC-ODBC 桥。JDBC-ODBC 驱动程序可从 Sun 的 Java 网站 (http://java.sun.com/) 轻松地找到并下载。在您扩充并安装了这个驱动程序后,必须执行下列步骤:
将 \jdbc-odbc\classes; 路径添加到您的 PATH 环境变量中。
将 \jdbc-odbc\classes; 路径添加到您的 CLASSPATH 环境变量中。
JDBC 驱动程序的类型
Java 程序连接数据库的方法实际上有四种:
1. JDBC-ODBC 桥和 ODBC 驱动程序 -- 在这种方式下,这是一个本地解决方案,因为 ODBC 驱动程序和桥代码必须出现在用户的每台机器中。从根本上说这是一个临时解决方案。
2. 本机代码和 Java 驱动程序 -- 它用另一个本地解决方案(该平台上的 Java 可调用的本机代码)取代 ODBC 和 JDBC-ODBC 桥。
3. JDBC 网络的纯 Java 驱动程序 -- 由 Java 驱动程序翻译的 JDBC 形成传送给服务器的独立协议。然后,服务器可连接任何数量的数据库。这种方法使您可能从客户机 Applet 中调用服务器,并将结果返回到您的 Applet。在这种情况下,中间件软件提供商可提供服务器。
4. 本机协议 Java 驱动程序 -- Java 驱动程序直接转换为该数据库的协议并进行调用。这种方法也可以通过网络使用,而且可以在 Web 浏览器的 Applet 中显示结果。在这种情况下,每个数据库厂商将提供驱动程序。
如果您希望编写代码来处理 PC 客户机数据库,如 dBase、Foxbase 或 Access,则您可能会使用第一种方法,并且拥有用户机器上的所有代码。更大的客户机-服务器数据库产品(如 IBM 的 DB2)已提供了第 3 级别的驱动程序。
两层模型和三层模型
当数据库和查询它的应用程序在同一台机器上,而且没有服务器代码的干预时,我们将生成的程序称为两层模型。一层是应用程序,而另一层是数据库。在 JDBC-ODBC 桥系统中通常是这种情况。
当一个应用程序或 applet 调用服务器,服务器再去调用数据库时,我们称其为三层模型。当您调用称为“服务器”的程序时通常是这种情况。
编写 JDBC 代码访问数据库
用 ODBC 注册您的数据库
连接数据库
所有与数据库有关的对象和方法都在 java.sql 包中,因此在使用 JDBC 的程序中必须加入 "import java.sql.* "。 JDBC 要连接 ODBC 数据库,您必须首先加载 JDBC-ODBC 桥驱动程序
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
该语句加载驱动程序,并创建该类的一个实例。然后,要连接一个特定的数据库,您必须创建 Connect 类的一个实例,并使用 URL 语法连接数据库。
String url = "jdbc:odbc:Northwind";
Connection con = DriverManager.getConnection(url);
请注意,您使用的数据库名是您在 ODBC 设置面板中输入的“数据源”名称。
URL 语法可能因数据库类型的不同而变化极大。
jdbc:subprotocol:subname
第一组字符代表连接协议,并且始终是 jdbc。还可能有一个子协议,在此处,子协议被指定为 odbc。它规定了一类数据库的连通性机制。如果您要连接其它机器上的数据库服务器,可能也要指定该机器和一个子目录:
jdbc:bark//doggie/elliott
最后,您可能要指定用户名和口令,作为连接字符串的一部分:
jdbc:bark//doggie/elliot;UID=GoodDog;PWD=woof
访问MSSQL Server方法:(驱动程序需要:msutil.jar,msbase.jar,mssqlServer.jar)
DBDriver=com.microsoft.jdbc.sqlserver.SQLServerDriver
URL=jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=demo
username=sa
password=
maxcon=10
mincon=1
poolName=SkyDev
利用我们开发的数据库类,使用方法如下:
DbObject DbO = new DbObject(new SqlServerConnectionFactory("localhost",
1433, "demo", "sa", ""));
Connection con = DbO.getConnection();
//类代码(不含连接工厂实现)
package skydev.modules.data;
public final class SqlServerConnectionFactory
extends ConnectionFactory
private final String dbDriver =
"com.microsoft.jdbc.sqlserver.SQLServerDriver";
private String host;
private int port;
private String databaseName;
public SqlServerConnectionFactory()
super.setDriverName(dbDriver);
/**
*
* @param host 数据库所在的主机名:如"localhost"
* @param port SQL服务器运行的端口号,如果使用缺省值 1433,传入一个负数即可
* @param databaseName 数据库名称
* @param userName 用户名
* @param password 口令
*/
public SqlServerConnectionFactory(String host,
int port,
String databaseName,
String userName,
String password)
this.setHost(host);
this.setPort(port);
this.setDatabaseName(databaseName);
this.setUserName(userName);
this.setPassword(password);
init();
private void init()
super.setDriverName(dbDriver);
super.setUrl("jdbc:microsoft:sqlserver://" + host.trim() + ":" +
new Integer(port).toString() + ";DatabaseName=" +
databaseName.trim());
//super.setUrl("jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=demo");
……
//------------------------------------------------------------------------------------
访问MySQL的方法:
DBDriver=com.mysql.jdbc.Driver
URL=jdbc:mysql://localhost/demo
username=
password=
maxcon=5
mincon=1
poolName=zhengmao
访问数据库
一旦连接到数据库,就可以请求表名以及表列的名称和内容等信息,而且您可以运行 SQL 语句来查询数据库或者添加或修改其内容。可用来从数据库中获取信息的对象有:
DatabaseMetaData 有关整个数据库的信息:表名、表的索引、数据库产品的名称和版本、数据库支持的操作。
ResultSet 关于某个表的信息或一个查询的结果。您必须逐行访问数据行,但是您可以任何顺序访问列。
ResultSetMetaData 有关 ResultSet 中列的名称和类型的信息。
尽管每个对象都有大量的方法让您获得数据库元素的极为详细的信息,但在每个对象中都有几种主要的方法使您可获得数据的最重要信息。然而,如果您希望看到比此处更多的信息,建议您学习文档以获得其余方法的说明。
ResultSet
ResultSet 对象是 JDBC 中最重要的单个对象。从本质上讲,它是对一个一般宽度和未知长度的表的一种抽象。几乎所有的方法和查询都将数据作为 ResultSet 返回。ResultSet 包含任意数量的命名列,您可以按名称访问这些列。它还包含一个或多个行,您可以按顺序自上而下逐一访问。在您使用 ResultSet 之前,必须查询它包含多少个列。此信息存储在 ResultSetMetaData 对象中。
//从元数据中获得列数
ResultSetMetaData rsmd;
rsmd = results.getMetaData();
numCols = rsmd.getColumnCount();
当您获得一个 ResultSet 时,它正好指向第一行之前的位置。您可以使用 next() 方法得到其他每一行,当没有更多行时,该方法会返回 false。由于从数据库中获取数据可能会导致错误,您必须始终将结果集处理语句包括在一个 try 块中。
您可以多种形式获取 ResultSet 中的数据,这取决于每个列中存储的数据类型。另外,您可以按列序号或列名获取列的内容。请注意,列序号从 1 开始,而不是从 0 开始。ResultSet 对象的一些最常用方法如下所示。
getInt(int); 将序号为 int 的列的内容作为整数返回。
getInt(String); 将名称为 String 的列的内容作为整数返回。
getFloat(int); 将序号为 int 的列的内容作为一个 float 型数返回。
getFloat(String); 将名称为 String 的列的内容作为 float 型数返回。
getDate(int); 将序号为 int 的列的内容作为日期返回。
getDate(String); 将名称为 String 的列的内容作为日期返回。
next(); 将行指针移到下一行。如果没有剩余行,则返回 false。
Close(); 关闭结果集。
getMetaData(); 返回 ResultSetMetaData 对象。
ResultSetMetaData
您使用 getMetaData() 方法从 ResultSet 中获取 ResultSetMetaData 对象。您可以使用此对象获得列的数目和类型以及每一列的名称。
getColumnCount(); 返回 ResultSet 中的列数。
getColumnName(int); 返回列序号为 int 的列名。
getColumnLabel(int); 返回此列暗含的标签。
isCurrency(int); 如果此列包含带有货币单位的一个数字,则返回 true。
isReadOnly(int); 如果此列为只读,则返回 true。
isAutoIncrement(int); 如果此列自动递增,则返回 true。这类列通常为键,而且始终是只读的。
getColumnType(int); 返回此列的 SQL 数据类型。这些数据类型包括
BIGINT
BINARY
BIT
CHAR
DATE
DECIMAL
DOUBLE
FLOAT
INTEGER
LONGVARBINARY
LONGVARCHAR
NULL
NUMERIC
OTHER
REAL
SMALLINT
TIME
TIMESTAMP
TINYINT
VARBINARY
VARCHAR
DatabaseMetaData
DatabaseMetaData 对象可为您提供整个数据库的信息。您主要用它获取数据库中表的名称,以及表中列的名称。由于不同的数据库支持不同的 SQL 变体,因此,也有多种方法查询数据库支持哪些 SQL 方法。
getCatalogs() 返回该数据库中的信息目录列表。使用 JDBC-ODBC Bridge 驱动程序,您可以获得用 ODBC 注册的数据库列表。这很少用于 JDBC-ODBC 数据库。
getTables(catalog, schema,tableNames, columnNames) 返回表名与 tableNames 相符而且列名与 columnNames 相符的所有表的说明。
getColumns(catalog, schema,tableNames, columnNames) 返回表名与 tableNames 相符而且列名与 columnNames 相符的所有表列说明。
getURL(); 获得您所连接的 URL 名称。
getDriverName(); 获得您所连接的数据库驱动程序的名称。
获取有关表的信息
您可以使用 DataBaseMetaData 的 getTables() 方法来获取数据库中表的信息。这个方法有如下4个 String 参数:
results =dma.getTables(catalog, schema, tablemask, types[]);
其中参数的意义是:
Catalog 要在其中查找表名的目录名。对于 JDBC-ODBC 数据库以及许多其他数据库而言,可将其设置为 null。这些数据库的目录项实际上是它在文件系统中的绝对路径名称。
Schema 要包括的数据库“方案”。许多数据库不支持方案,而对另一些数据库而言,它代表数据库所有者的用户名。一般将它设置为 null。
Tablemask 一个掩码,用来描述您要检索的表的名称。如果您希望检索所有表名,则将其设为通配符 %。请注意,SQL 中的通配符是 % 符号,而不是一般 PC 用户的 * 符号。
types[] 这是描述您要检索的表的类型的 String 数组。数据库中通常包括许多用于内部处理的表,而对作为用户的您没什么价值。如果它是空值,则您会得到所有这些表。如果您将其设为包含字符串“TABLES”的单元素数组,您将仅获得对用户有用的表格。
一个简单的 JDBC 程序
我们已经学习了 JDBC 的所有基本功能,现在我们可以编写一个简单的程序,该程序打开数据库,打印它的表名以及某一表列的内容,然后对该数据库执行查询。此程序如下所示:
package skydevkit;
import java.sql.*;
public class JdbcOdbc_test
ResultSet results;
ResultSetMetaData rsmd;
DatabaseMetaData dma;
Connection con;
public JdbcOdbc_test() throws SQLException
String url = "jdbc:odbc:Northwind";
try
//加载 JDBC-ODBC 桥驱动程序
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
con = DriverManager.getConnection(url);//连接数据库
dma = con.getMetaData();//获取数据库的元数据
System.out.println("Connected to:" + dma.getURL());
System.out.println("Driver " + dma.getDriverName());
catch (Exception e)
System.out.println(e);
try
Statement stmt = con.createStatement();
results = stmt.executeQuery("select * from 客户;");
ResultSetMetaData resultMetaData = results.getMetaData();
int cols = resultMetaData.getColumnCount();
String resultRow = "";
for (int i = 1; i < cols; i++)
resultRow += resultMetaData.getColumnName(i) + ";";
System.out.println(resultRow);
while (results.next())
resultRow = "";
for (int i = 1; i < cols; i++)
try
resultRow += results.getString(i) + ";";
catch (NullPointerException e)
System.out.println(e.getMessage());
System.out.println(resultRow);
catch (Exception e)
System.out.println("query exception");
finally
results.close();
补充高级内容
关于调用SQLServer存储过程的例子:(用到了我们开发的数据库连接类)
CREATE PROCEDURE [dbo].[sp_getStudentByName](@name char(10))
AS
Select * from Students where [Name]=@name
GO
DbObject DbO = new DbObject(new SqlServerConnectionFactory("localhost",
1433, "demo", "sa", ""));
Connection con = DbO.getConnection();
CallableStatement pstmt = null;
System.out.println("TestDB1()............");
/* try
pstmt = con.prepareCall("call sp_getStudentById(?)");
pstmt.setInt(1, 1);
*/
try
pstmt = con.prepareCall("call sp_getStudentByName(?)"); //注意参数如何传递
pstmt.setString(1, "Tom");
……
使用输出参数:
CREATE PROCEDURE [dbo].[sp_insertStudent](@name char(10),@age int,@id int OUTPUT) AS
insert into Students([Name],[Age]) values (@name,@age)
select @id=@@IDENTITY
GO
try
pstmt = con.prepareCall("call sp_insertStudent(?,?,?)");
pstmt.setString(1, "zengqingsong");
pstmt.setInt(2, 22);
pstmt.registerOutParameter(3, Types.INTEGER);
pstmt.executeUpdate();
int id = pstmt.getInt(3);
System.out.println(id);
使用返回参数的例子:
CREATE PROCEDURE [dbo].[sp_insertStudent](@name char(10),@age int,@id int OUTPUT) AS
insert into Students([Name],[Age]) values (@name,@age)
select @id=@@IDENTITY –测试输出参数
return 30 –测试返回30
GO
try
pstmt = con.prepareCall("?=call sp_insertStudent(?,?,?)");
pstmt.setString(2, "zengqingsong");
pstmt.setInt(3, 22);
pstmt.registerOutParameter(4, Types.INTEGER);
pstmt.registerOutParameter(1, Types.INTEGER);
int ret = pstmt.executeUpdate(); //执行影响的行数
int ret2 = pstmt.getInt(1); //返回参数(输出参数)
int id = pstmt.getInt(4); //输出参数
System.out.println(ret);
System.out.println(ret2);
System.out.println(id);
http://zhidao.baidu.com/question/2050414.html 参考技术B 回答
你好,你想咨询数据库,那方面的问题
提问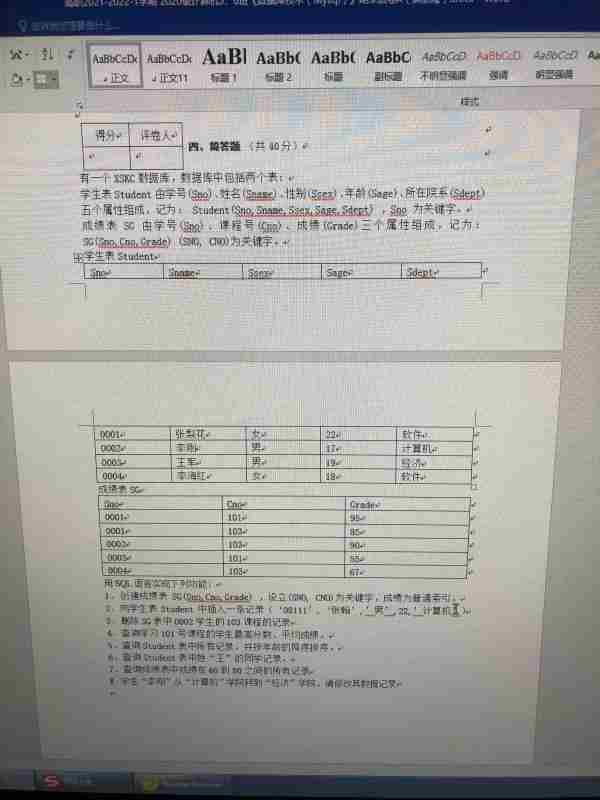
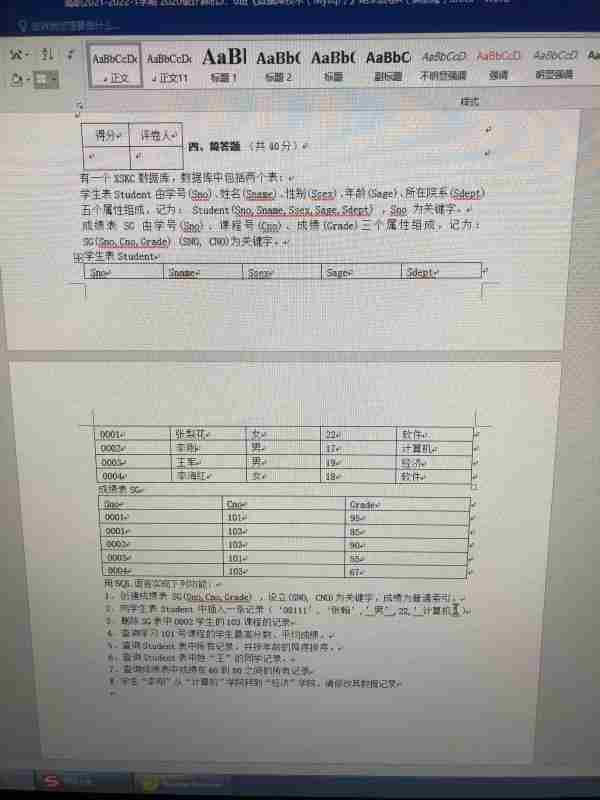
用sql语句创建学生表的方法:首先打开sql的新建查询,新建表;然后输入学号和姓名,类型用字符来表示;接着输入性别,年龄,专业;最后点击执行即可。本文操作环境:Windows7系统,SQL Server 2016版本,Dell G3电脑。用sql语句创建学生表的方法:1、我们打开sql的新建查询2、我们建一个表,叫student3、我们输入学号和姓名,类型用字符来表示4、我们输入性别,年龄,专业,分别用适合的类型定义。5、这时候我们按执行6、我们救可以看到系统显示成功建表。
参考技术C 数据库是依照某种数据模型组织起来并存放二级存储器中的数据集合。这种数据集合具有如下特点:尽可能不重复,以最优方式为某个特定组织的多种应用服务,其数据结构独立于使用它的应用程序,对数据的增、删、改和检索由统一软件进行管理和控制。从发展的历史看,数据库是数据管理的高级阶段,它是由文件管理系统发展起来的。数据库的基本结构分三个层次,反映了观察数据库的三种不同角度。
(1)物理数据层。它是数据库的最内层,是物理存贮设备上实际存储的数据的集合。这些数据是原始数据,是用户加工的对象,由内部模式描述的指令操作处理的位串、字符和字组成。
(2)概念数据层。它是数据库的中间一层,是数据库的整体逻辑表示。指出了每个数据的逻辑定义及数据间的逻辑联系,是存贮记录的集合。它所涉及的是数据库所有对象的逻辑关系,而不是它们的物理情况,是数据库管理员概念下的数据库。
(3)逻辑数据层。它是用户所看到和使用的数据库,表示了一个或一些特定用户使用的数据集合,即逻辑记录的集合。
数据库不同层次之间的联系是通过映射进行转换的。数据库具有以下主要特点:
(1)实现数据共享。数据共享包含所有用户可同时存取数据库中的数据,也包括用户可以用各种方式通过接口使用数据库,并提供数据共享。
(2)减少数据的冗余度。同文件系统相比,由于数据库实现了数据共享,从而避免了用户各自建立应用文件。减少了大量重复数据,减少了数据冗余,维护了数据的一致性。
(3)数据的独立性。数据的独立性包括数据库中数据库的逻辑结构和应用程序相互独立,也包括数据物理结构的变化不影响数据的逻辑结构。
(4)数据实现集中控制。文件管理方式中,数据处于一种分散的状态,不同的用户或同一用户在不同处理中其文件之间毫无关系。利用数据库可对数据进行集中控制和管理,并通过数据模型表示各种数据的组织以及数据间的联系。
(5)数据一致性和可维护性,以确保数据的安全性和可靠性。主要包括:①安全性控制:以防止数据丢失、错误更新和越权使用;②完整性控制:保证数据的正确性、有效性和相容性;③并发控制:使在同一时间周期内,允许对数据实现多路存取,又能防止用户之间的不正常交互作用;④故障的发现和恢复:由数据库管理系统提供一套方法,可及时发现故障和修复故障,从而防止数据被破坏 参考技术D 中毒表现:登陆服务器发现,服务器所有文件后缀名统一变为.ETH文件,无法正常打开文件
病毒种类:*.ETH
数据类型: MDF
应用软件: 二羊软件
数据大小: 3GB
文件数量: 1
数据检测 : 通过WINHEX检测文件底层,发现文件头部底层数据错乱被加密,文件尾部有异常代码.
恢复方案:通过参考空库结构,修复数据库结构,提取表数据,存储过程,合并为新的数据库 .
具体描述:通过和客户沟通,使用客户提供的远程登录口令,登录客户服务器进行数据提取、传回地分析加密结构、对比底层数据、进行人工数据修复.
验收结果: 通过验收
数据中台是什么,它能解决什么问题
前言:
近几年来数据中台概念大火,市面上掀起了一波建业务中台、数据中台热潮,那么数据中台到底是什么?它的出现能解决什么问题呢?首先数据中台的概念最早由阿里提出,自从阿里提出了“大中台,小前台”概念之后,数据中台这个概念火了起来,不少企业,无论是互联网企业还是传统企业纷纷搭建起了自家的数据中台,究竟数据中台有什么魅力,能让企业如此重视?本文主要从数据中台是什么、怎么做数据中台和为什么要做数据中台三个方面对这个问题进行了分析。
什么是数据中台:
广义的数据中台包括了数据技术,比如对海量数据进行采集、计算、存储、加工的一系列技术集合,数据中台包括数据模型,算法服务,数据产品,数据管理等等,和企业的业务有较强的关联性,是企业独有的且能复用的,比如企业自建的1000个基础模型,500个融合模型,1万个标签。它是企业业务和数据的沉淀,其不仅能降低重复建设,减少烟囱式协作的成本,也是差异化竞争优势所在。
如何构建数据中台:
(1)数据汇集
数据汇集是数据中台数据接入的入口。数据中台本身不产生数据,所有数据来自于业务系统、日志、文件、网络等,这些数据分散在不同的业务系统中,难以利用,很难产生业务价值。数据汇集是数据中台必须提供的核心工具,把各种异构网络、异构数据源的数据能够方便地采集到数据中台进行集中存储,为后续的加工建模做准备。数据汇集方式一般分为离线批量汇聚和实时采集。
(2)数据资产管理
数据资产管理包括对数据资产目录、元数据、数据质量、数据血缘、数据生命周期等进行管理和展示,以一种更直观的方式展现企业的数据资产,提升企业的数据意识。
(3)数据服务
数据服务体系就是把数据变为一种服务能力,通过数据服务让数据参与到业务,激活整个数据中台,数据服务体系是数据中台存在的价值所在。企业的数据服务是千变万化的,中台产品可以带有一些标准服务,但是很难满足企业的服务诉求,大部分服务还是需要通过中台的能力快速定制。数据中台的服务模块并没有自带很多服务,而是提供快速的服务生成能力以及服务的管控等功能。
(4)数据应用开发
数据开发是一整套数据加工以及加工过程管控的工具,数据开发模块主要是面向开发、分析人员,提供离线、实时、算法开发工具以及任务的管理、代码发布、运维、监控、告警等一些列集成工具,方便使用,提升效率,根据企业需要,在这一层可以通过一系列数据工具集快速构建各种数据应用,及时有效的提供给企业各部分使用。
(5)数据安全
建立健全的高效灵敏预警体系,通过对系统各模块完善监测机制,得到量化的数据,分析发现并预测潜在危机,及时上报,预警风险;提供数据访问黑/白名单设计,例如设可访问数据的IP段,若不在此IP段中将无法接触到数据资产;同时基于可视化操作灵活控制接口的停用和启用等操作,实现调用过程的自主可控;
建设中台的好处:
中台的目标是提升效能、数据化运营、更好支持业务发展和创新,是多领域、多部门、多系统的负责协同。中台是平台化的自然演进,这种演进带来“去中心化“的组织模式,突出对能力复用、协调控制的能力,以及业务创新的差异化构建能力。
是不是所有企业都应该去构建自己的中台:
关于是不是所有企业都应该是构建自己的数据中台呢?在我看来并不是,我们不能为了中台而中台,需要结合企业自身发展需要和基础信息化建设情况来定,我认为建设中台的几个必要条件:
(1)企业信息化基础建设良好;
(2)多年的数据资产沉淀,但数据相对分散,难以共用;
(3)前端业务需求多变,对数据依赖需求比较强烈,但数据和指标具有重叠性,从技术的视角更多的工作是需要类似积木式的自由组合和搭建;
(4)技术部门无法及时满足多变的业务需求。
工具支撑:
NBI数据分析平台(http://nbi.easydatavis.com:8033)的初衷就是致力于提供简单、易用、低成本、快速上线的大数据可视化分析产品和服务,帮助企业提升数 据化运营能力
(1)数据准备:
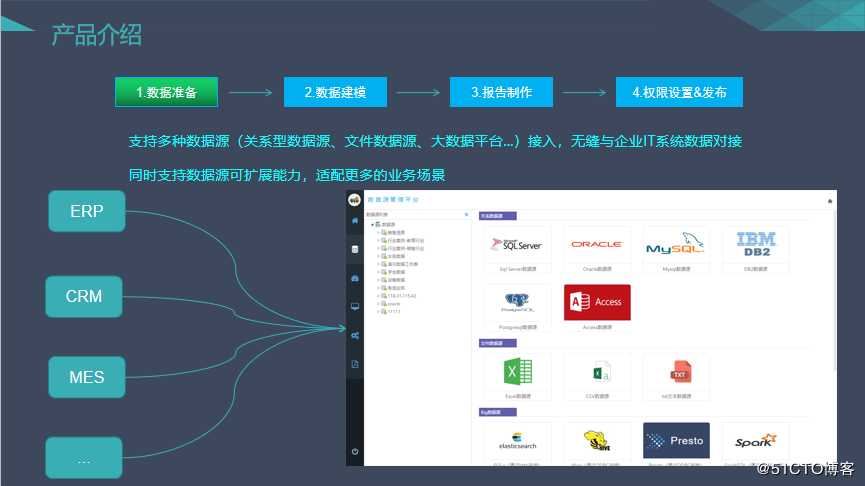
(2)数据建模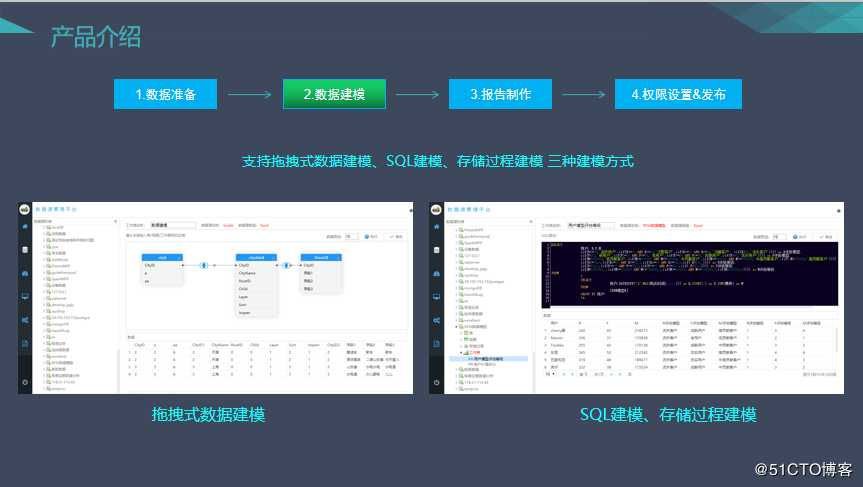
(3)数据分析与数据报告制作
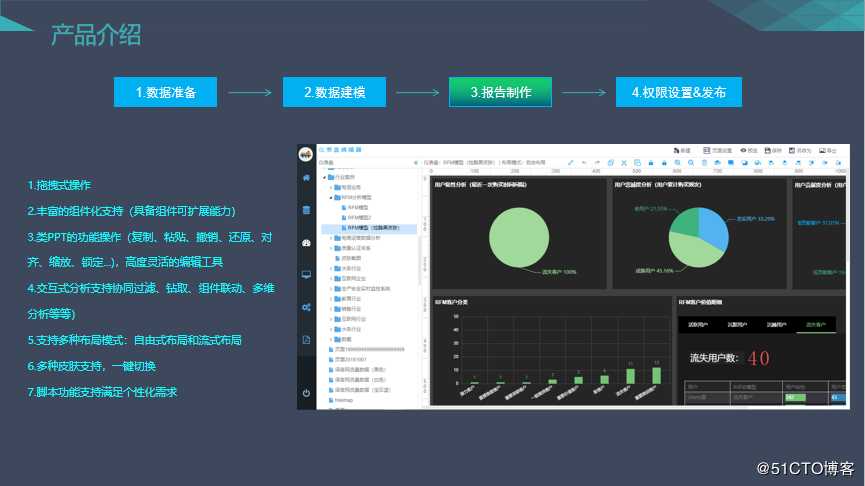
(4)发布

NBI数据分析平台效果展示
大数据分析软件,数据分析平台,开源数据分析平台,echarts,d3.js,数据可视化分析软件,大屏数据分析展示
更多信息请参考(http://nbi.easydatavis.com:8033)
以上是关于什么是数据库的主要内容,如果未能解决你的问题,请参考以下文章