Python+Selenium笔记(十八):持续集成jenkins
Posted 习惯形成性格,性格决定命运
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python+Selenium笔记(十八):持续集成jenkins相关的知识,希望对你有一定的参考价值。
(一)安装xmlrunner
使用Jenkins执行测试时,测试代码中会用到这个模块。
pip install xmlrunner
下文安装Jenkins环境:Windows 10
Ubuntu安装Jenkins可参考:https://www.cnblogs.com/clemente/p/10642760.html
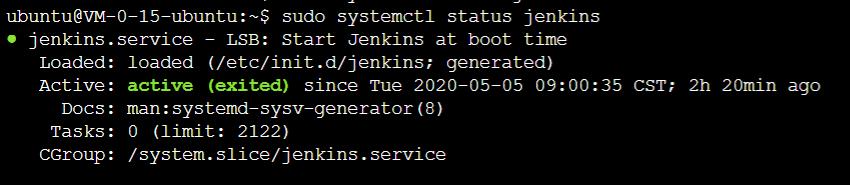
亲测可行。
(二)安装jenkins
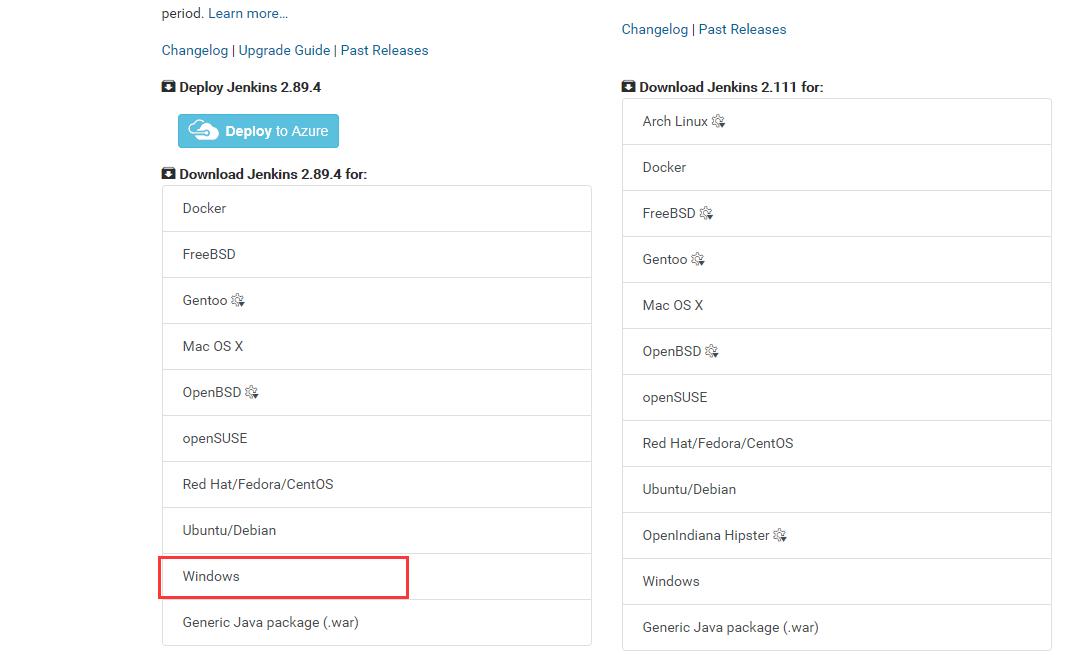
(1) 下载jekins
下载适合自己的,我是下载长期稳定版的。
(2) 解压后运行jenkins.msi这个文件,然后一直下一步就是了。
(3) http://localhost:8080 登录
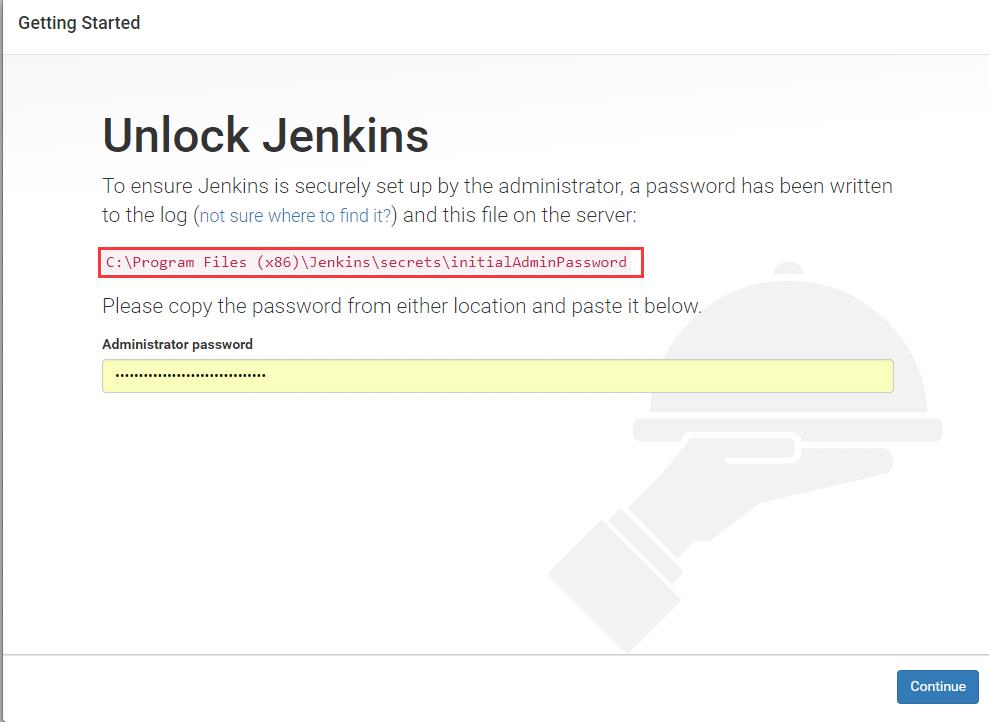
(4) 根据提示输入密码后,下一步。
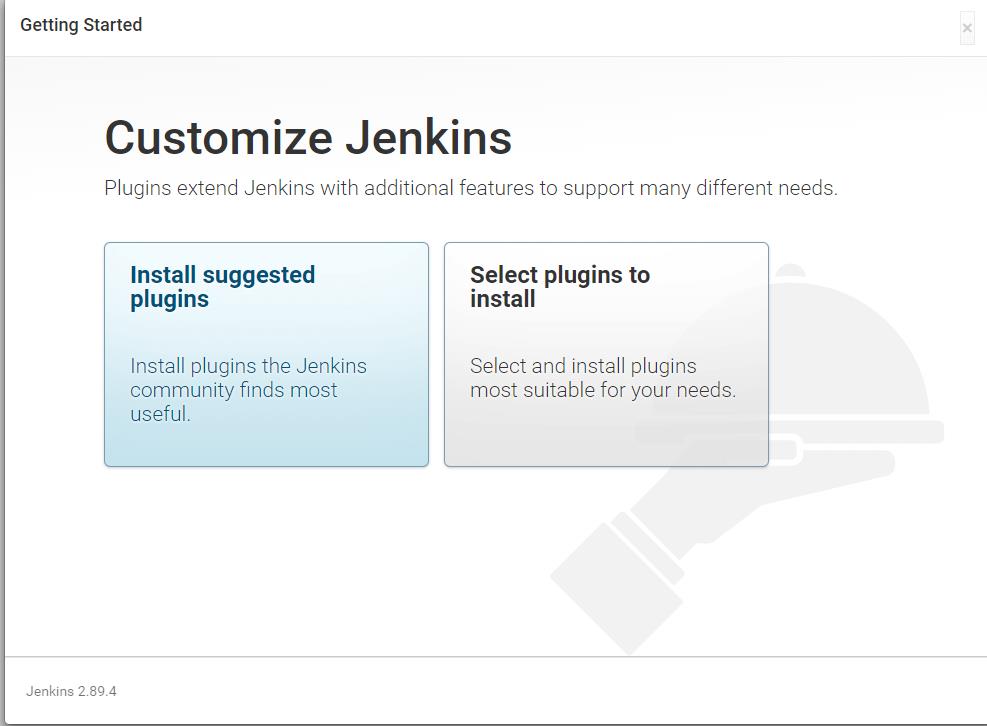
(6) 这里第一个应该是默认安装jenkins community的常用插件,第二个应该是选择需要安装的插件。不熟悉的时候选第一个就是了。
(7) 插件安装成功后如下图所示。(如果这步有部分插件安装失败的话,就重新下载,实在安装不了就重启Jenkins服务(Windows的服务里重启),然后重新登陆后跳过这步,安装失败的插件以后再在Jenkins的插件管理中去安装)
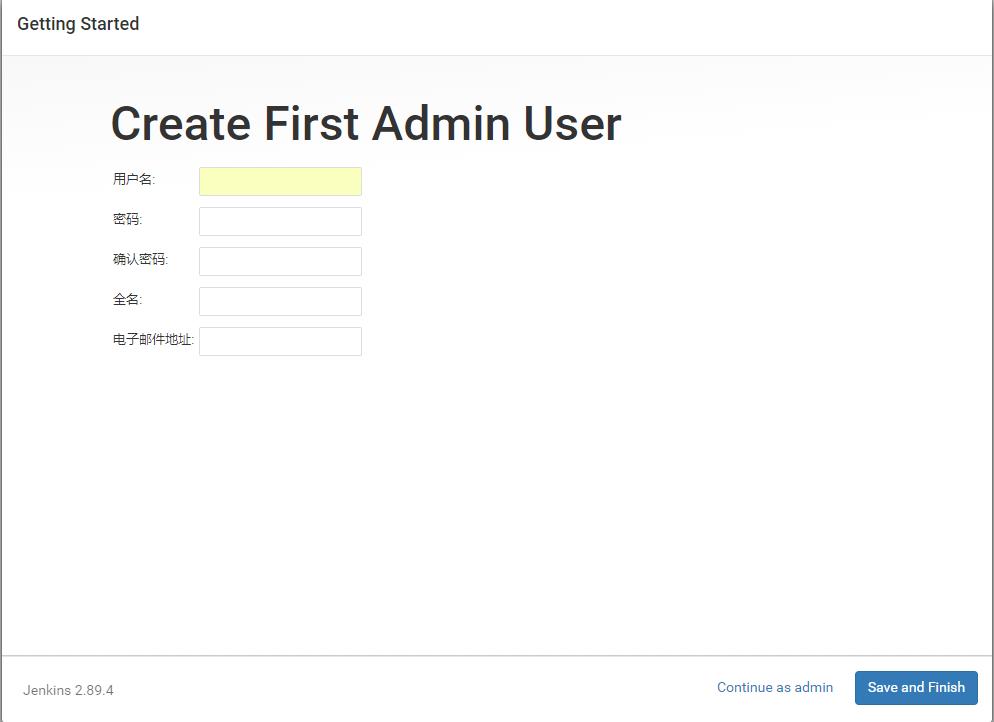
(8) 安装完成。
 (三)新建任务
(三)新建任务
(1) 首页点击【新建】。
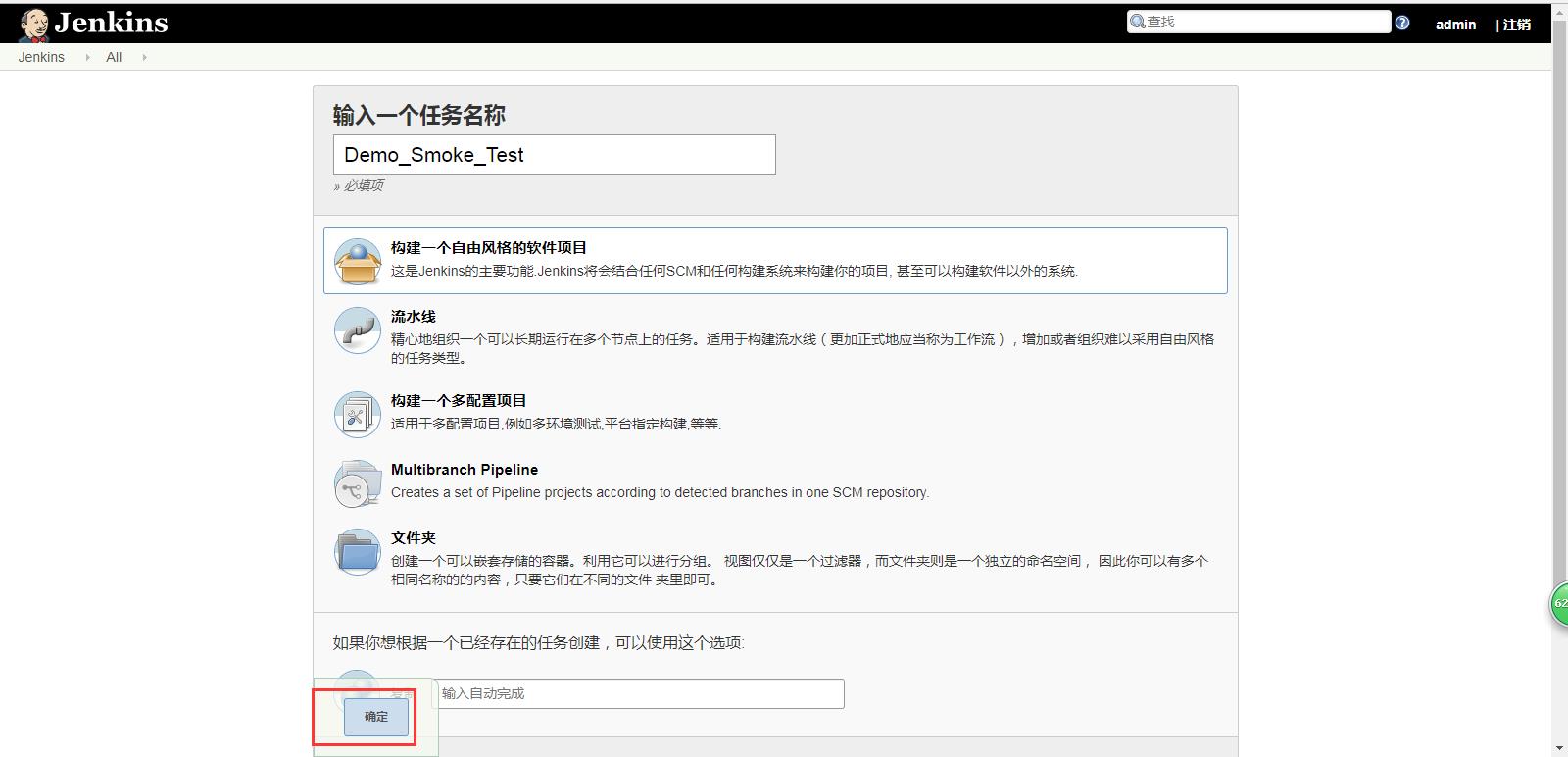
(2) 填写相关信息后,点击【确定】。
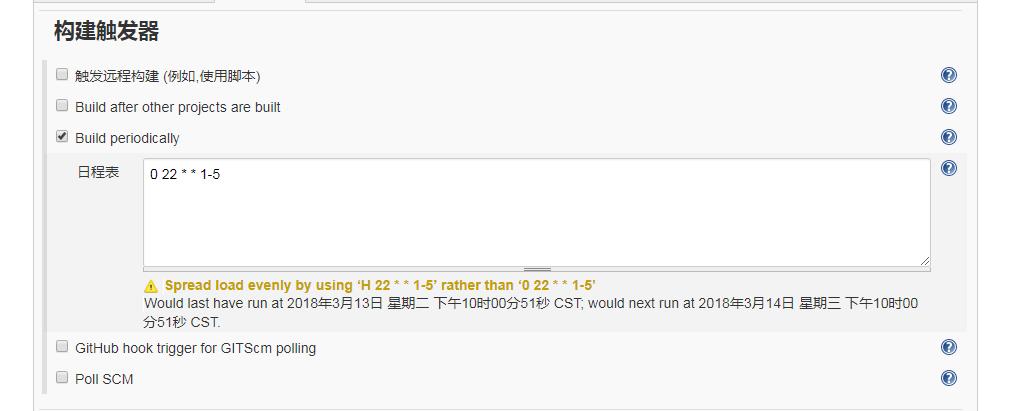
(3) 构建触发器设置自动构建的时间。下面的是工作日每晚10点自动执行,这样第二天早上上班就能看到测试结果了。
这里有5个参数:可以点击后面?查看说明文档,*代表任意时间
第一个:分钟(0-59)
第二个:小时(0-23)
第三个:日(1-31)
第四个:月份(1-12)
第五个:星期几(0-7,0和7都代表星期日)
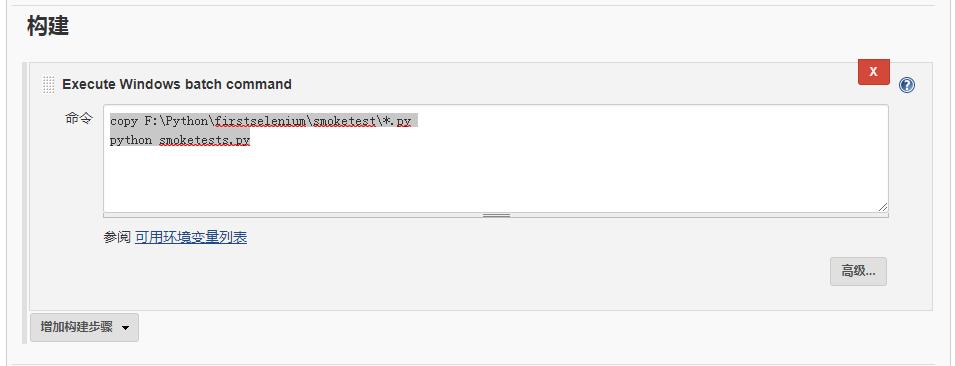
(4) 构建部分增加构建步骤,这里选择Windows批处理命令。
copy F:\\Python\\firstselenium\\smoketest\\*.py
python smoketests.py
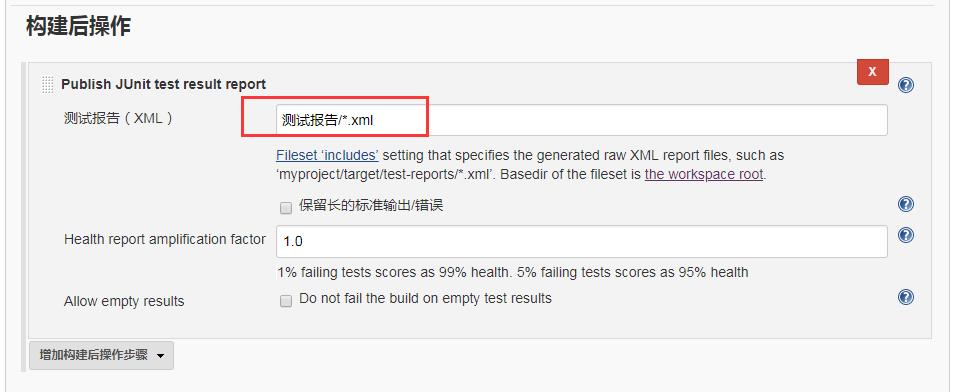
(5) 构建后操作,增加操作步骤,选择Publish JUnit test result report,然后在测试报告字段填写 测试报告/*.xml。(测试报告是测试套件中配置的output参数的值,看下面的smoketests.py的代码就知道了)这样Jenkins每次运行测试的时候都会从这个文件夹读取测试结果。
(6) 配置完成后点击【保存】。
(7) 点击下图的【立即构建】,蓝色就代表成功了。
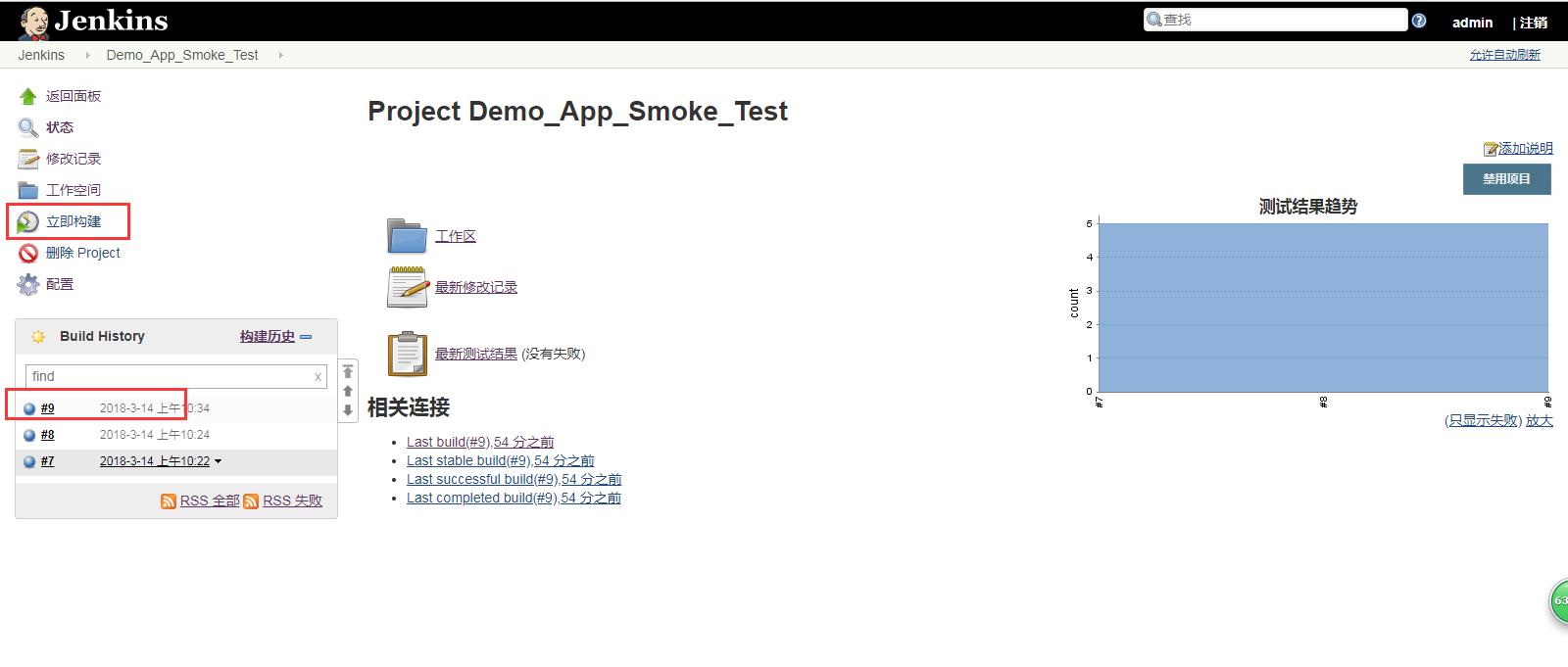
(8) 点击上图的最新测试结果可以查看最新的测试结果。(也可以点击具体Build History下面的时间,查看具体哪一次构建的测试结果,点击蓝色的球形图标的话,可以查看控制台输出)
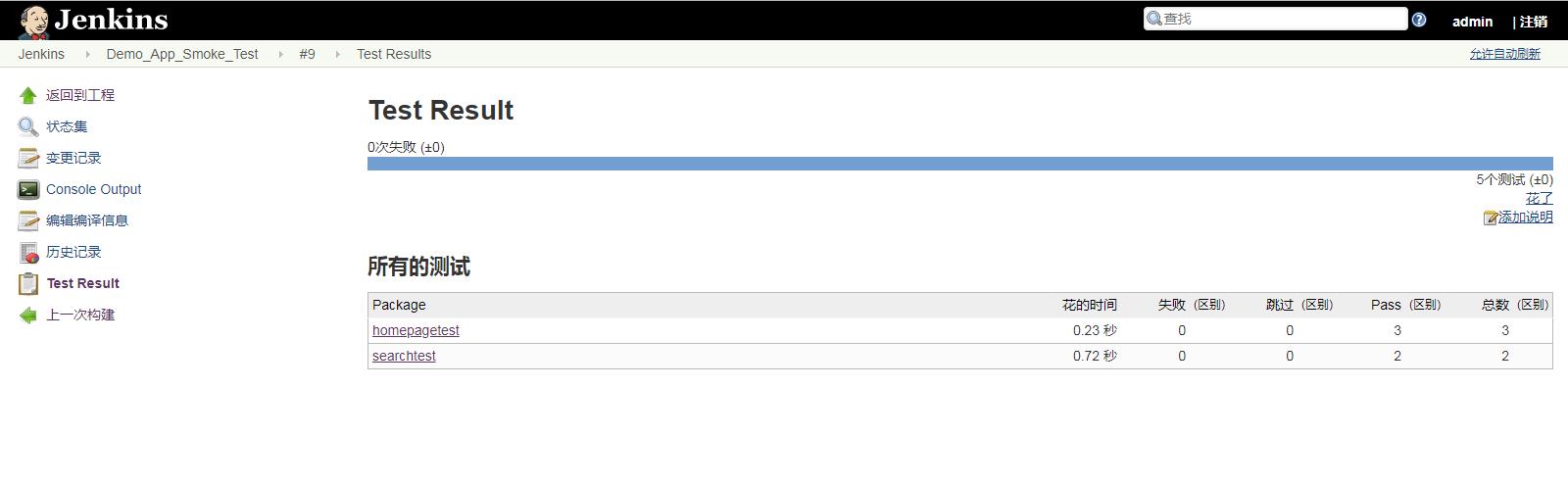
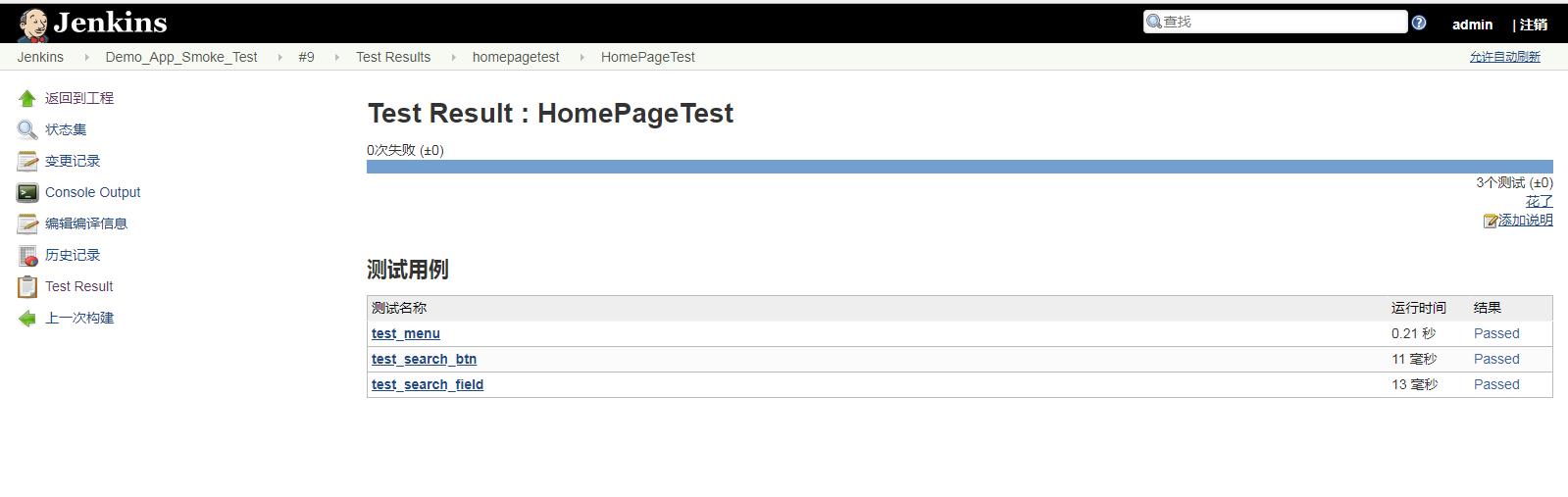
下面的代码部分,主要的就是测试套件中的这句,其他的自己随便写一个或几个测试用例就行了
xmlrunner.XMLTestRunner(verbosity=2,output=\'测试报告\').run(smoke_tests)
(四)smoketests.py
1 import unittest 2 from searchtest import SearchTest 3 from homepagetest import HomePageTest 4 from xmlrunner import xmlrunner 5 #获取SearchTest类 和 HomePageTest类中的所有测试方法 6 search_test = unittest.TestLoader().loadTestsFromTestCase(SearchTest) 7 home_page_test = unittest.TestLoader().loadTestsFromTestCase(HomePageTest) 8 #创建一个包括SearchTest和HomePageTest的测试套件 9 smoke_tests = unittest.TestSuite([home_page_test,search_test]) 10 #运行测试套件 11 # unittest.TextTestRunner(verbosity=2).run(smoke_tests) 12 xmlrunner.XMLTestRunner(verbosity=2,output=\'测试报告\').run(smoke_tests)
(五)searchtest.py
1 import sys 2 import unittest 3 from selenium import webdriver 4 from selenium.webdriver.common.action_chains import ActionChains 5 from selenium.webdriver.support.ui import WebDriverWait 6 class SearchTest(unittest.TestCase): 7 @classmethod 8 def setUpClass(cls): 9 cls.driver = webdriver.Chrome() 10 # cls.driver.implicitly_wait(20) 11 cls.driver.maximize_window() 12 cls.driver.get("https://www.cnblogs.com/") 13 14 def test_search_by_category(self): 15 category_list = [\'Java\', \'C++\', \'PHP\', \'Delphi\', \'Python\', \'Ruby\',\\ 16 \'C语言\', \'Erlang\', \'Go\', \'Swift\', \'Scala\', \'R语言\', \'Verilog\', \'其它语言\'] 17 #定位首页网站分类中的编程语言 18 search_class = self.driver.find_element_by_xpath(\'//li/a[@href="/cate/2/"]\') 19 #光标悬停在“编程语言”上 20 ActionChains(self.driver).move_to_element(search_class).perform() 21 WebDriverWait(self.driver, 20).until(lambda l: len(l.find_elements_by_xpath( \\ 22 \'//div[@id="cate_content_block_2"]/div[@class="cate_content_block"]/ul/li\')) == 14) 23 # 以列表形式返回编程语言下的所有小类 24 search_small = self.driver.find_elements_by_xpath(\\ 25 \'//div[@id="cate_content_block_2"]/div[@class="cate_content_block"]/ul/li\') 26 small_cate = [] 27 for s in search_small: 28 #去掉小类最后面的(0),并添加到列表small_cate中 29 small = str(s.text).split(\'(\') 30 small_cate.append(small[0]) 31 #检查表达式是否为true(此处检查编程语言下的小类是否与预期结果一致) 32 self.assertTrue(small_cate == category_list) 33 self.assertEqual(small_cate,category_list) 34 35 def test_search_by_look(self): 36 seach_class = self.driver.find_element_by_xpath(\'//li/a[@href="/cate/2/"]\') 37 #定位编程语言下的小类Python 38 seach_small = self.driver.find_element_by_xpath(\'//li/a[@href="/cate/python/"]\') 39 ActionChains(self.driver).move_to_element(seach_class).click(seach_small).perform() 40 #检查打开的网页标题是不是 Python - 网站分类 - 博客园 41 self.assertEqual(self.driver.title,"Python - 网站分类 - 博客园" ) 42 43 @classmethod 44 def tearDownClass(cls): 45 cls.driver.quit() 46 #加上下面2句,可以通过命令行运行测试,不加的话不影响通过IDE运行测试 47 if __name__ == \'__main__\':51 #加verbosity=2参数,在命令行中显示具体的测试方法 52 unittest.main(verbosity=2)
(六)homepagetest.py
1 import sys 2 import unittest 3 from selenium import webdriver 4 from selenium.common.exceptions import NoSuchElementException 5 from selenium.webdriver.common.by import By 6 class HomePageTest(unittest.TestCase): 7 @classmethod 8 def setUpClass(cls): 9 cls.driver = webdriver.Chrome() 10 cls.driver.implicitly_wait(10) 11 cls.driver.maximize_window() 12 cls.driver.get("https://www.cnblogs.com/") 13 14 def test_search_field(self): 15 #检查博客园首页有没有搜索框,is_element_present()是自定义的方法 16 self.assertTrue(self.is_element_present(By.ID,"zzk_q")) 17 def test_search_btn(self): 18 # 检查博客园首页有没有找找看按钮 19 self.assertTrue(self.is_element_present(By.CLASS_NAME,"search_btn")) 20 21 # 检查博客园首页菜单栏信息是否与预期一致 22 def test_menu(self): 23 menu_data =[\'园子https://home.cnblogs.com/\', \'新闻https://news.cnblogs.com/\', 24 \'博问https://q.cnblogs.com/\', \'闪存https://ing.cnblogs.com/\', 25 \'小组https://group.cnblogs.com/\', \'收藏https://wz.cnblogs.com/\', 26 \'招聘https://job.cnblogs.com/\', \'班级https://edu.cnblogs.com/\', 27 \'找找看http://zzk.cnblogs.com/\'] 28 #以列表形式返回博客园首页菜单栏信息 29 self.check_menu = self.driver.find_elements_by_xpath(\'//div[@id="nav_menu"]/a\') 30 the_menu = [] 31 for c in self.check_menu: 32 #将博客园首页的菜单名称和URL添加到列表the_menu 33 the_menu.append(c.text + c.get_attribute(\'href\')) 34 #检查2个列表是否一致(检查博客园首页的菜单名称及URL是否和预期一致) 35 self.assertListEqual(the_menu,menu_data) 36 37 # 找到元素,返回True,否则返回False 38 def is_element_present(self,how,what): 39 try: 40 self.driver.find_element(by=how,value = what) 41 except NoSuchElementException as e: 42 return False 43 return True 44 45 @classmethod 46 def tearDownClass(cls): 47 cls.driver.quit() 48 49 # 加上下面2句,可以通过命令行运行测试,不加的话不影响通过IDE运行测试 50 if __name__ == \'__main__\':54 # 加verbosity=2参数,在命令行中显示具体的测试方法 55 unittest.main(verbosity=2)
以上是关于Python+Selenium笔记(十八):持续集成jenkins的主要内容,如果未能解决你的问题,请参考以下文章