室内单目深度估计-4
Posted 抚琴尘世客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了室内单目深度估计-4相关的知识,希望对你有一定的参考价值。
注: 研究方向为depth estimation,欢迎同一个方向的加入QQ群(602708168)交流。
1. 论文简介
论文题目:Toward Practical Monocular Indoor Depth Estimation
Paper地址:https://openaccess.thecvf.com/content/CVPR2022/papers/Wu_Toward_Practical_Monocular_Indoor_Depth_Estimation_CVPR_2022_paper.pdf
发表刊物:CVPR
发表时间:2022
发表作者:Cho-Ying Wu, Jialiang Wang, Michael Hall, Ulrich Neumann and Shuochen Su
发表单位:元现实实验室(Meta Reality Labs),南加州大学(University of Southern California)
2. Abstract
室外单目深度估计方法应用到室内场景效果很差。本文给的原因是室内目标杂乱无序,任意排列。
为了获得更多的鲁棒性,本文提出了一种结构蒸馏方法,从现成的相对深度估计器中学习技巧,该相对深度估计器产生结构化但度量不可知的深度。
通过将结构蒸馏与从左右一致性学习度量的分支相结合,获得了通用室内场景的结构化和度量深度,并进行实时推断。
为了便于学习和评估,本文收集了来自数千个环境的模拟数据集SimSIN和包含约500个通用室内环境的真实扫描序列的UniSIN数据集。
我们在模拟到真实和真实设置中进行了实验,并展示了改进,以及使用深度图的下游应用程序。这项工作提供了一个全面的研究,涵盖方法,数据和应用方面。

3. Introduction
本文工作的总结:
- 从现成的估计器和左右图像对中学习,无需深度注释,高效的训练数据收集,跨数据集推理的高度泛化,以及准确和实时的深度感知。

现有方法主要集中在室外场景,但对于如何把这些方法应用到室内场景没有说明。这可能就是本文为提蒸馏的原因。
这一段还是很有意思(分析了室内单目深度估计存在挑战):
- 结构先验:
室外场景具有明确的场景结构:
首先,图像的上部分一般是天空或者建筑物,通常距离较远;
其次,图像的低端通常是延伸到远处道路。
室内场景:
室内环境的结构先验要弱得多,因为物体可以在近场中杂乱和任意排列。
- 分布:
室外场景:
分布均匀,场景深度在道路上从近到远均匀分布;
室内场景:
分布不均,室内深度可以集中在近或远的范围内,比如放大的桌子或天花板视图。(深度分布的不均匀使得预测室内场景的精确度量深度具有挑战性。)
- 相机位姿(深度传感设备可以在室内进行6DoF移动):
室外场景:
主要是平移运动,旋转主要有偏航角决定。
室内场景:
旋转,仰角等。(理想的位姿估计网络需要对室内情况下的任意摄像机姿态和复杂场景结构具有更强的鲁棒性。)
- 无纹理表明:
室外场景:
较少
室内场景:
较多,较大,如墙面,桌面等。(使常用的光度损失不明确)


在这项工作中,我们提出了DistDepth,一种结构蒸馏方法,以提高由自监督学习训练的深度精度。DistDepth使用现成的相对深度估计器DPT[59,60],它只生成结构化的相对深度(输出值反映深度排序关系,但与度量无关)。我们的结构蒸馏策略鼓励深度结构相似性统计和空间。这样,DPT的深度排序关系可以有效地融合到由左右一致性训练的度量深度估计分支中。我们的学习模式只需要一个现成的相对深度估计器和立体图像输入,而不需要它们的深度注释。在测试时给定一个单目图像,我们的深度估计器可以预测结构化和度量精确的深度,对未见过的室内场景具有很高的泛化性(第3.2节)。蒸馏还有助于将DPT的大型视觉转换器缩小到更小的架构,从而在便携式设备上实现实时推断。

我们将描述我们的数据集级贡献。目前公开的立体数据集要么是针对驾驶场景[9,13,20,22,76],规模小且缺乏场景可变性[65,66],由不真实规模的3D动画[6,52]渲染,要么是在野外收集[35,70]。流行的室内数据集要么是小规模的(Middlebury[65]),要么缺乏立体声对(NYUv2[54])。目前还没有大规模的室内立体声数据集来促进自我监督研究的左右一致性。我们利用流行的Habitat模拟器[63,69]来收集3D室内环境中的立体声对。选择常用的环境,包括Replica[68]、Matterport3D (MP3D)[8]和Habitat-Matterport 3D (HM3D)[57],以创建SimSIN,这是一个由大约1K室内环境中约500K模拟立体室内图像组成的新数据集(第4节)。使用SimSIN,我们能够研究先前自监督框架在室内场景上的性能[24,74,75]。我们表明,我们可以通过直接训练这些模型来拟合SimSIN,但这些模型对未见环境的异构域的泛化效果很差。然而,使用我们的结构蒸馏策略,可以在未见数据上产生高度结构化和度量精确的深度(第5节)。


一些商业质量的模拟和真实数据被用于评估,包括具有挑战性的虚拟公寓(Va)序列[1,2]、Hypersim中的预渲染场景[61]和NYUv2中的真实单目图像[67]。为了进一步研究模拟训练与真实数据训练之间的差距,我们进一步收集了UniSIN,这是一个数据集,包括500个真实的室内立体序列,总计200K张图像,在一所大学中使用现成的高性能立体摄像机,跨越建筑和空间。我们表明,在模拟数据上训练的DistDepth仅与在真实数据上训练的DistDepth具有相同的性能。

本文提出的方法具有一下功能:
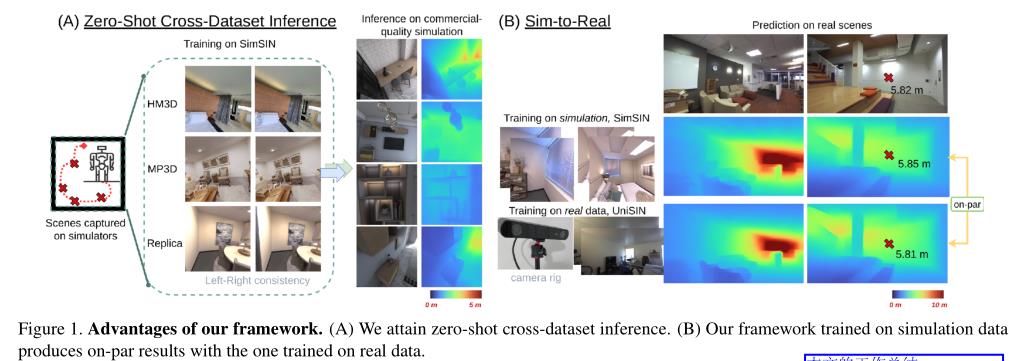
1 实现zero-shot跨数据集推理;
2. 缩小了虚实学习和真实学习之间的差距,如图1所示。
在整个工作过程中,除非标记为相对深度,否则我们将在实际的度量范围内可视化深度图。
贡献总结如下:
1. 我们提出了DistDepth,这是一个将深度域结构知识提取为自监督深度估计器的框架,以获得高度结构化和度量精确的深度图。
2. 我们提出了SimSIN,一个大型室内模拟数据集,通过左右一致性促进室内深度估计的研究,以及一个真实数据集,UniSIN,旨在研究模拟训练和真实数据之间的差距。
3.我们实现了一种实用的室内深度估计器:在无GT下学习,通过模拟高效有效地收集数据,高度的可泛化性和准确实时的深度感知推理。

3. Related Work
单目场景深度估计。许多研究兴趣集中在基于学习的方法来学习映射:I→D,从图像到深度域。
3.1 Supervised Scene Depth Estimation
监督学习需要像素级深度注释。早期的方法[17-19,33,45,46,49,58,79,81]使用卷积神经网络对深度值进行像素级回归,以最小化预测与真实值之间的损失。最近,Bhat等[4]采用自适应箱进行深度回归,并使用视觉变压器[16]。MiDaS[60]和Wei等[82]巧妙地混合多个数据集,使用尺度和位移不变损失实现大规模深度训练。BoostingDepth[53]融合了MiDaS中基于[34]观测的多尺度深度线索,但对深度图进行后期处理需要几分钟。DPT (MiDaSV3)[59]设计了一个密集视觉转换器,取得了比原来MiDaS更好的效果。

尽管最先进的MiDaS[60]和DPT[59]可以估计野外图像的细粒度深度结构,但由于混合数据集训练策略,它们只能提供相对深度,这取决于未知的规模和移位因子,以与实际大小保持一致。我们的DistDepth采用这样的野外场景预训练,作为深度结构蒸馏的专家,从左右一致性训练的分支中获得结构化深度和度量深度。

3.2 Left-Right and Temporal Consistency
左右一致性和时间一致性有助于实现自监督学习,从而提高训练对groundtruth深度的要求,更接近于实际的深度感知[27,41,43,44,55]。MonoDepth[23]从立体声对中学习深度,并使用带有光度损失最小化的左右深度重投影。MonoDepth2[24]进一步包括时间邻近帧,也尽量减少光度一致性损失。DepthHints[74]采用来自立体声对的预先计算的SGM[30,31]深度作为代理,并且仍然保持自监督。ManyDepth[75]使用成本-体积最小化的测试时间多帧输入来获得更准确的预测。然而,这些方法都集中在驾驶场景,其对室内数据的适用性还有待研究。我们的工作是基于深度结构蒸馏的左右一致性和时间一致性,以获得结构化的、度量的和可泛化的深度估计,而大多数工作没有讨论泛化性[24 - 26,75,80]。请注意,我们的结构蒸馏不同于常规蒸馏[29,62,84],因为我们的专家只能估计深度排序,它需要与学生推断的指标相结合才能获得最终输出。其他一些作品仅通过时间一致性来实现自我监督[5,36],这使得量表的鲁棒性较差。另一项工作[47],基于曼哈顿世界假设,最小化共面和正态损失,但只显示了鲁棒性的平面区域固有的模糊尺度。

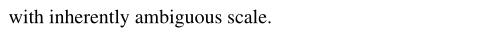
4. Method
图2的解释:
训练过程:
输入的图像为一对立体图像,一幅用于输入,一幅用于计算loss。
对于输入的I_t,分别经过两个分支,上分支使用现有模型得到相对深度(作者取名为结构+相对 的深度,我觉得引入结构词很牵强),相对深度用来作为监督信号,下分支为本文的深度预测器预测绝对深度以及一个姿态估计网络(作者没画出来,用来投影)。
接着计算损失:Depth-Domain structure Loss包含两个损失,公式(2)和公式(3),我完全没看出哪里提现结构了,作者好牵强(灬ꈍ ꈍ灬)。Left-Right Consistency Loss,也是包含两个损失函数,left-right consistency loss+temporal consistency loss。
最终的损失函数为公式(4)。
图(b)的作用:作者认为SSIM损失仅限制统计深度分布,而丢失空间信息。因此,提出了一个使用深度遮挡边界图的空间控制。根据文字描述和图的表示,作者是想保持一些边缘细节的一致性。(按照个人的经验,边缘信息损失不太靠谱,有时还起反作用)。
测试过程:
输入一张图,直接进入下分支,预测绝对深度图。
4.1 Basic Problem Setup
这里主要介绍了自监督方法的做法。左右一致性,时间光度一致性。
基于立体对的:就是已知相机内参,变换矩阵;将RGB图像输入深度预测网络输出深度图,就可以根据深度图和已知条件根据投影公式得到另外一副图像的重建图。再将重建图与真实的图像做光度loss(Photometric loss),具体如公式(1)。
时间一致性:这里除了depth estimation network之外,还需要个posenet用于估计相机位姿,然后根据已知相机内参,相机位姿,深度图,上一帧(或下一帧图像),就可以投影到下一帧(或上一帧)图像,以计算Photometric loss。

我们在SimSIN数据集上训练MonoDepth2、DepthHints和ManyDepth,并在图4中举例说明了稍后的场景拟合。现有技术适合训练集,但由于室内环境中看不到的复杂物体排列,不能很好地泛化跨数据集推理。

4.2 DistDepth: Structure Distillation from Expert
这一段主要描述了作者引入一个在其他数据上训练好的模型,用于生成深度图D*t做监督信号。


这里作者应该还引入了一个网络用于预测尺度因子as和at,然后再得到最终的监督信号。

4.2.1 Statical loss
SSIM损失函数,由已经训练好的DPT模型生成的深度图和预测的深度图。

4.2.2 Spatial refinemnet loss
计算空间损失。首先对两个深度图使用sobel滤波得到梯度图。然后计算分位数,这个我不太了解,大家可以自己查一下,盲猜应该是过滤掉一些不明显区域的意思。然后转为二值图。
基于二值图使用公式(3)计算汉明距离。


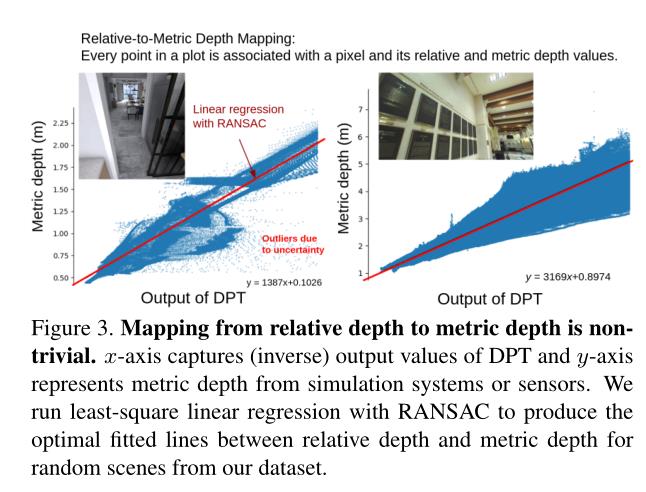
另一种替代方法是根据对齐关系[60]预测尺度和移位因子,将相对深度与度量深度对齐。然而,这种看似简单的方法存在一个缺点,神经网络的深度估计不可避免地包含不确定性,不确定性要么是由神经网络模型引起的,要么是由数据引起的[38,39,51]。相对深度和度量深度之间的转换呈现出总体线性但有噪声的趋势,不同场景的最优直线方程会有很大差异,如图3所示。因此,这种替代方法不能仅用尺度和移位项分解噪声和异常值。我们在补充部分展示了使用这种方法的实验。

我们采用ResNet[28]作为DepthNet(fd)。尽管可以使用密集视觉变压器获得更高的预测精度,但由于网络规模较大和操作复杂,它们的推理速度较低,无法满足实时设备深度感知。因此,我们最大限度地利用DPT中嵌入的结构知识,并将大型视觉转换器缩小到较小尺寸的ResNet,这使我们能够以交互速率(35+ fps vs . 8-11 fps,对于不同版本的DPT,在RTX 2080 GPU的笔记本电脑上测量)运行深度传感,以实现实际的深度估计目的。参见补充说明。

5. Datasets
5.1 Training: SimSIN
为了利用左右和时间相邻帧来获得光度一致性以进行自我监督训练,我们采用了流行的Habitat模拟器[63,69],该模拟器启动了一个虚拟代理并呈现相机捕获的3D室内环境。我们采用Replica、MP3D和HM3D作为后端3D模型,遵循之前的具身AI作品[10 - 12,14,21,56]。
我们采用[7]相机设置下的13cm立体基线,以512 × 512分辨率渲染。代理导航多次并捕获立体序列。然后,我们手动过滤掉故障序列,例如当代理太接近墙壁或导航到零空间时。
我们的数据集分别由来自Replica、MP3D和HM3D的约80K、205K和215K图像组成,在我们提出的SimSIN数据集中,总计来自约1000个不同环境的500K立体图像,这是迄今为止用于通用室内环境的最大立体数据集。

5.2 Training: UniSIN
研究模拟与现实的差距,比较模拟训练模型和真实数据训练模型的性能。
我们使用ZED-2i[3],一种高性能立体摄像系统,从大学周围的各种室内空间收集大规模立体序列,并创建UniSIN数据集。它的训练分割包含500个序列,每个序列有200个立体对,总计200K张训练图像。


5.3 Evaluation Sets
5.3.1 Commercial-Quality similation
我们选择一个精心设计的虚拟公寓(virtual apartment, VA),沿轨迹渲染约3.5K真实感图像作为评价集[1,2]。V A数据集包含具有挑战性的室内场景,用于深度传感,例如具有不同照明、薄结构和复杂装饰的机柜立方体。这些场景使我们能够在私人室内空间进行深度传感的详细研究,这是AR/VR最常见的用例。我们进一步包括预渲染Hypersim[61]数据集的样本,其中包含虚拟环境的单目图像,用于定性演示。

5.3.2 Real Data
我们采用流行的NYUv2[67],其测试集包含654张带有飞行时间激光深度图的单目图像,使用Kinect v1。为了弥补Kinect较旧的成像系统和低分辨率,以服务于更实际的AR/VR使用,我们收集了ZED-2i提供的深度经过精细优化的1K高清图像,用于数值评估。
我们在补充部分展示了所有数据集的示例集合

6. Experiments and Analysis
我们将输入大小设置为256×256,批处理大小设置为24,epoch编号设置为10。Adam[40]被用作优化器,初始学习率为2×10−4,在第8和第10 epoch下降了10倍。我们采用常见的颜色抖动和随机翻转数据增强。我们在PoseNet fp中使用ResNet50,在DepthNet fd中使用ResNet152,在MonDepth2、DepthHints和ManyDepth中使用同样的方法进行比较。DPT采用大型密集变压器网络,应用于野外场景。
因此,我们为DepthNet选择了更大的架构来演示泛化性,但仍然可以在交互帧率下运行(在补充部分中说明)。

6.1 Experiments on Simulation Data
我们使用SimSIN作为第5.1节中的训练数据集,并对各种商业质量的模拟数据进行评估。
6.1.1 Prior self-supervised methods trained on SimSIN
我们首先在SimSIN上直接训练MonoDepth2、DepthHints和ManyDepth,并在图4中对训练数据和VA推理进行拟合,以考察其泛化性。ManyDepth和DepthHints比MonoDepth2获得更好的结果。我们的DistDepth生成高度正则化的结构,具有对未见示例的鲁棒性,w.r.t groundtruth。预测范围也有所改善,我们认为这是由于更好的结构遮挡边界推理。

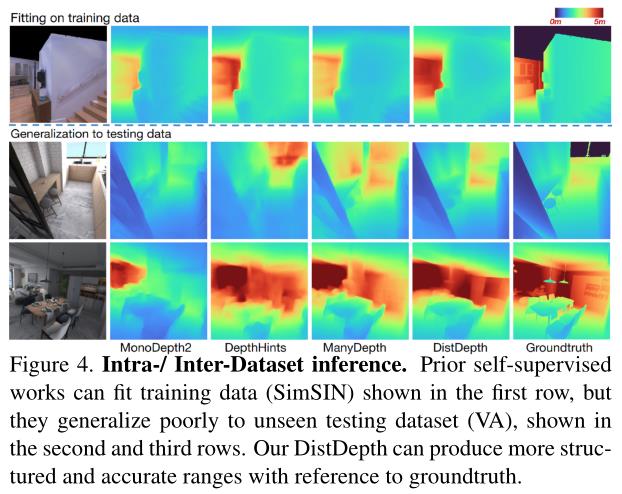

6.1.2 Error analysis on VA
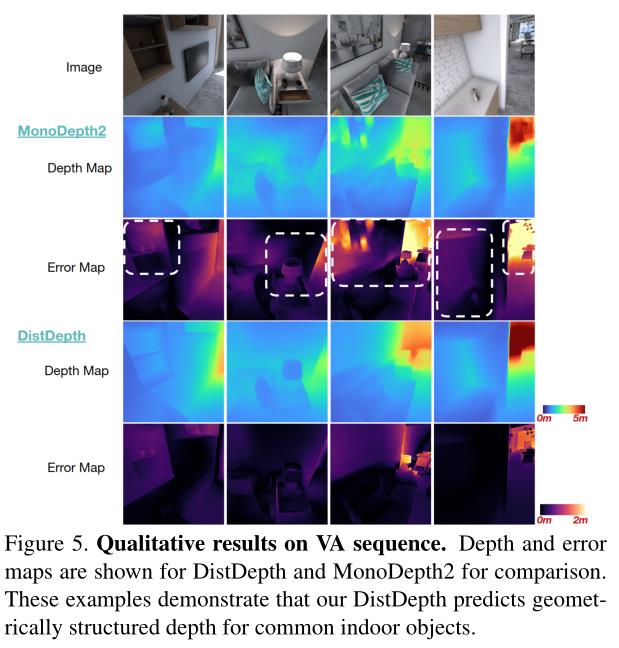
V A数据集包括室内空间中各种具有挑战性的场景。定性误差分析如图5所示。在误差图中突出显示,我们的DistDepth在估计各种光照条件下的绘画、架子和墙壁等潜在几何结构方面具有更好的泛化性。更多示例见补充。
我们进一步在表1中显示整个V - A序列的数值比较。所有比较的方法都是在SimSIN上训练的。我们进一步为DistDepth配备了在ManyDepth中引入成本-体积最小化的测试时间多帧策略,并用DistDepth- m表示这种变体。方法分为测试时间单帧和测试时间多帧。在这两种情况下,DistDepth的误差都比先前的技术低。这验证了我们的网络设计:使用专家进行深度域结构蒸馏,学生网络fd可以生成更接近地面真相的结构化深度和度量深度。


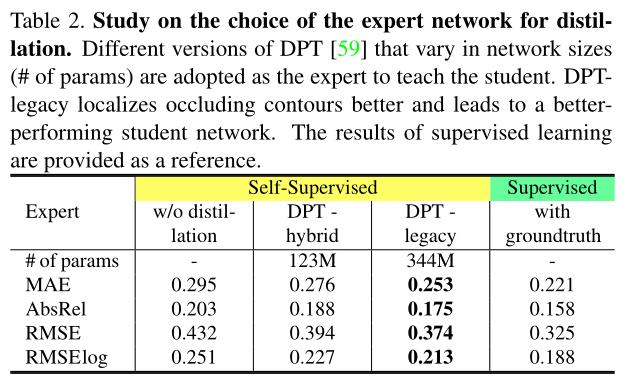
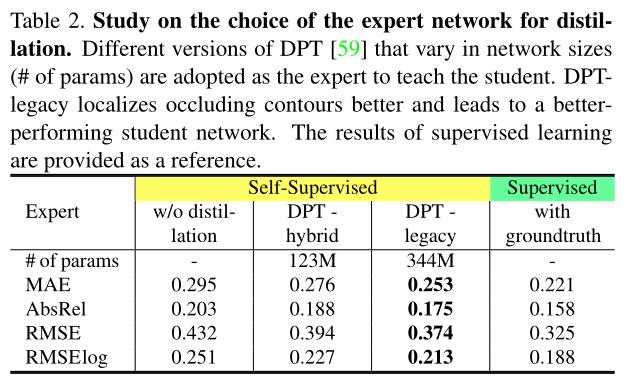
6.1.3 Ablation study on VA
我们首先研究专家网络,采用不同版本的DPT(混合和遗留),其网络规模不同。表2显示了规模较大的专家教授的学生网络,DTP策略实现更低的深度估计误差。如果没有蒸馏,结果会更糟,因为它的估计只依赖光度损失,而对墙壁等无纹理的区域无效。作为完整性检查,我们还提供了使用SimSIN的groundtruth深度和像素级MSE损失的监督训练结果,并在V a数据集上进行测试,这显示了在策划深度和专家网络预测深度上的训练之间的差距。
接下来,我们将在第3.2节中研究不同蒸馏损失的训练策略和启动水平α的影响。
比较(1)无蒸馏,(2)只有统计损失的蒸馏,(3)有统计和空间细化损失的蒸馏。我们在图6中展示了定性结果,以显示深度域结构的改进。没有蒸馏,空间结构就无法清晰地推理。
通过统计细化,深度结构更加清晰。添加空间细化,深度域结构显示了细粒度的细节。我们进一步分析了不同α启动水平的影响。低α使结构模糊,因为细化不像高α那样关注高梯度遮挡边界,它只识别高梯度区域作为遮挡边界,有利于结构知识的转移。



6.1.4 Comparison on Hypersim
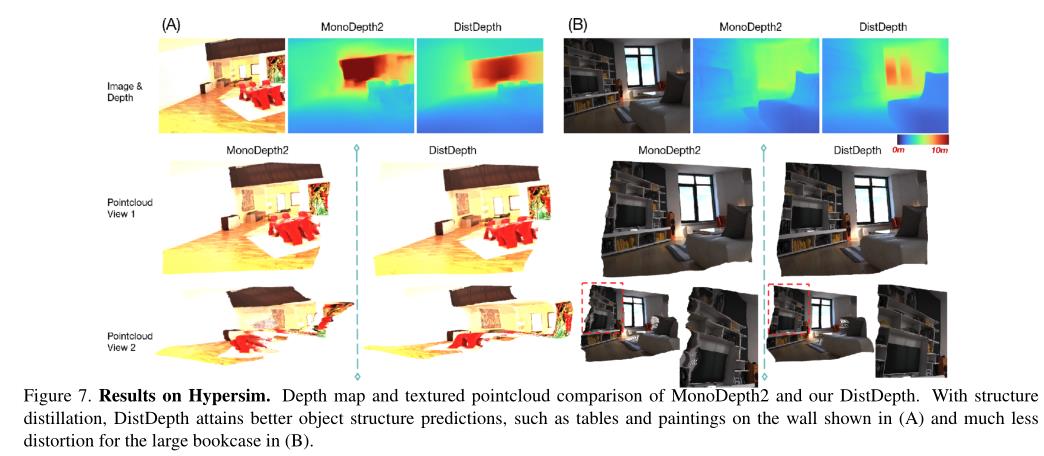
接下来,我们将在图7中为Hypersim中的一些场景展示深度和纹理点云。
点云可视化采用了两种不同的视图。我们可以发现DistDepth在深度图和点云中都能更好地预测几何形状。更多示例请参见补充部分。

6.2 Experiments on Real Data
6.2.1 Closing sim-to-real gap
我们比较了模拟训练(SimSIN)2和真实数据(UniSIN)的结果来研究性能差距。我们检查了(1)在模拟上训练MonoDepth2并在真实数据上评估,(2)在真实数据上训练MonoDepth2并在真实数据上评估,(3)在模拟上训练DistDepth并在真实数据上评估,以及(4)在真实数据上训练DistDepth并在真实数据上评估。图8示出了四种设置的结果。比较(1)和(2),可以发现在真实数据上训练的MonoDepth2比在模拟上训练产生更可靠的结果。相比之下,当比较(3)时,这种差距就不明显了。相比之下,当比较(3)和(4)时,这种差距就不明显了。(3)的结果与(4)相同,有时甚至可以产生更好的几何形状,如突出显示的区域。我们进一步在补充中包括数值分析。


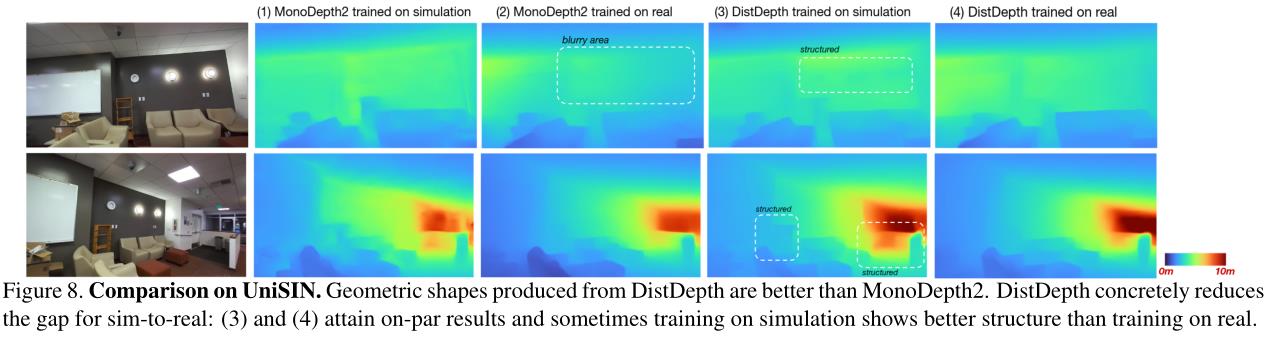
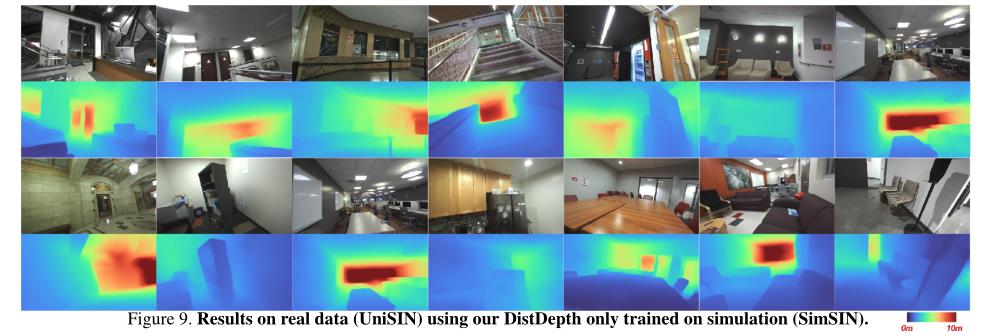
结果在方法和数据集层面验证了我们的建议。首先,DistDepth利用专家网络为学生提取小窍门。蒸馏极大地增加了在模拟数据上训练的模型的鲁棒性,并使结果与在真实数据上训练的模型相当。这显示了DistDepth缩小模拟和真实数据之间差距的能力。其次,立体模拟数据提供了一个左右一致性的平台,从立体三角测量中学习度量深度。我们在图9中展示了使用DistDepth进行纯模拟训练的结果集合。

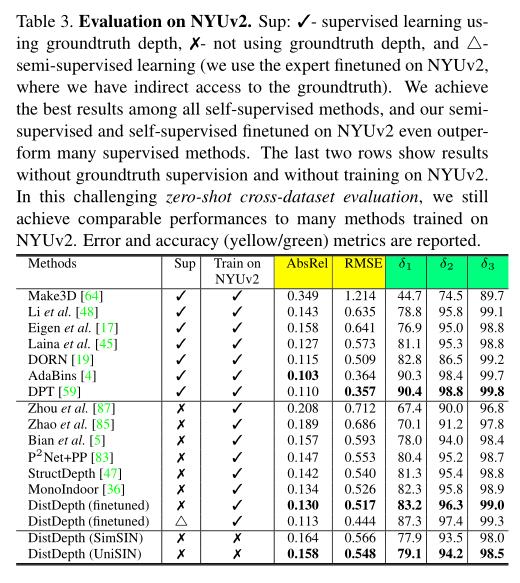
6.2.2 Evaluation on NYUv2
表3显示了对NYUv2的评估。我们首先在SimSIN上训练DistDepth,在NYUv2上训练finetune,只有时间一致性。请注意,一个经过微调的模型(Sup:4)被归类为半监督的,因为它利用了受过NYUv2的策划深度训练的专家。在没有NYUv2深度监督的方法中,经过微调的模型产生了最好的结果,甚至获得了与许多监督方法相当的结果。接下来,我们只在模拟(SimSIN)或真实数据(UniSIN)上训练DistDepth,并在NYUv2上进行评估。在SimSIN上训练的模型的性能与在UniSIN上训练的模型相比只下降了一点,这再次证明了我们的模拟到真实的优势。
在不涉及NYUv2中的任何训练数据的情况下,DistDepth仍然实现了与许多监督和自监督方法相当的性能,这进一步验证了我们的零射击跨数据集优势。我们还展示了实时深度传感、3D照片和深度感知AR应用。

7. Conclusion
亮点:
- 本文基于蒸馏思想,原模型使用室外场景训练好的模型,然后使用室内数据集进行finetune;蒸馏思想也是在该方向之前没用过。
不足:
- 个人感觉本文的工作量是不充分的,原因:使用现有方法来做蒸馏,说跟其他蒸馏方法不一致,其实就是用了个现有模型预测相对深度,而不用可以直接预测绝对深度的模型。绝对深度都不能预测准确,相对深度是不是更离谱了,拿一个离谱的相对深度做监督信号,意义何在?盲猜:如果用了能预测绝对深度的模型,那么肯定会被审稿人提问:那么你的优化目标最好也只能是别人的结果,根本不能超越,就不能提现价值,所以作者应该是为了避过这个坑。
8. 结语
努力去爱周围的每一个人,付出,不一定有收获,但是不付出就一定没有收获! 给街头卖艺的人零钱,不和深夜还在摆摊的小贩讨价还价。愿我的博客对你有所帮助(*^▽^*)(*^▽^*)!
如果客官喜欢小生的园子,记得关注小生哟,小生会持续更新(#^.^#)(#^.^#)。
以上是关于室内单目深度估计-4的主要内容,如果未能解决你的问题,请参考以下文章