pandas的简单使用-2-常用函数
Posted 南风丶轻语
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas的简单使用-2-常用函数相关的知识,希望对你有一定的参考价值。
pandas的简单使用-2-常用函数
记录一下潘大师的常用的函数和实现的功能
常用函数
查看头N行数据
df.head() # 查看前5行数据
df.head(10) # 查看前10行数据
查看尾N行数据
df.tail() # 查看后5行数据
df.tail(10) # 查看后10行数据
查看索引
df.index # 查看索引
查看列名
df.columns # 查看列名
df.keys() # 查看列名
# keys() 等同于 columns
按照X轴和Y轴排序
df.sort_index(axis=\'index\', ascending=True) # 按照X轴升序排序
df.sort_index(axis=\'index\', ascending=False) # 按照X轴降序排序
df.sort_index(axis=\'columns\', ascending=True) # 按照Y轴升序排序
df.sort_index(axis=\'columns\', ascending=False) # 按照Y轴降序排序
按照X轴排序,即按照索引排序
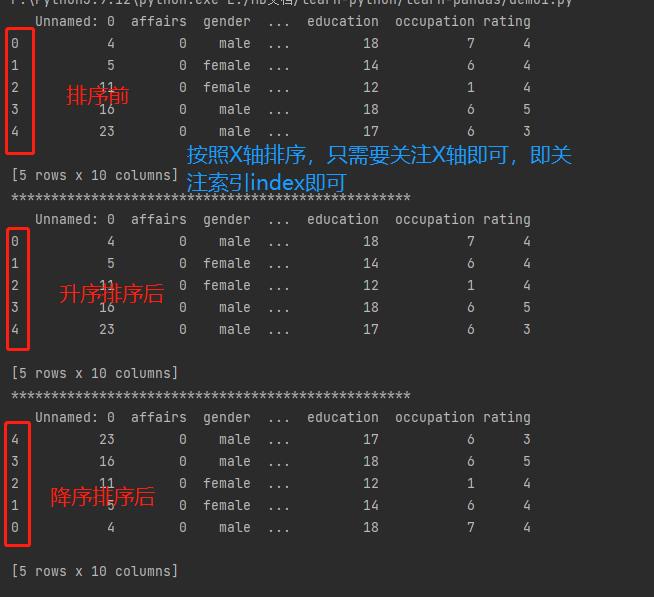
按照Y轴排序,即按照列名排序

上述几个函数参考代码
import pandas as pd
from pandas import DataFrame
def see_data(df):
data = df.head() # 查看前5行数据
print(data)
print("*" * 50)
data = df.head(10) # 查看前10行数据
print(data)
print("*" * 50)
data = df.tail() # 查看后5行数据
print(data)
print("*" * 50)
data = df.tail(10) # 查看后10行数据
print(data)
print("*" * 50)
def see_index_columns(df: DataFrame):
index = df.index # 查看索引
print(index)
columns = df.columns # 查看列名
print(columns)
keys = df.keys() # 查看列名
print(keys)
print(df.columns is df.keys()) # keys() 等同于 columns
def sort_by_index(df: DataFrame):
# axis : 0 or \'index\', 1 or \'columns\', default 0
print(df)
print("*" * 50)
ret = df.sort_index(axis=\'index\', ascending=True) # 按照X轴升序排序
print(ret)
print("*" * 50)
ret = df.sort_index(axis=\'index\', ascending=False) # 按照X轴降序排序
print(ret)
def sort_by_columns(df: DataFrame):
# axis : 0 or \'index\', 1 or \'columns\', default 0
print(df)
print("*" * 50)
ret = df.sort_index(axis=\'columns\', ascending=True) # 按照Y轴升序排序
print(ret)
print("*" * 50)
ret = df.sort_index(axis=\'columns\', ascending=False) # 按照Y轴降序排序
print(ret)
def main():
df: DataFrame = pd.read_csv("csvs/Src-Affairs.csv") # 返回DataFrame二维数组对象
# see_data(df)
# see_index_columns(df)
df2 = df[:5]
# sort_by_index(df2)
sort_by_columns(df2)
if __name__ == \'__main__\':
main()
选择某一行
df.loc[RangeIndex(1)] # 默认是RangeIndex类型的索引,所以可以这么选择第1行 但不会降维 不会从二维数组降到一维数组
df.loc[0] # 默认是RangeIndex类型的索引,所以可以这么选择第1行 会降维 直接从二维数组降到一维数组
df.loc[RangeIndex(start=5, stop=6)] # 默认是RangeIndex类型的索引,所以可以这么选择第5行 但不会降维 不会从二维数组降到一维数组
df.loc[5] # 默认是RangeIndex类型的索引,所以可以这么选择第5行 会降维 直接从二维数组降到一维数组
选择某些行(切片)
df[1:3] # 从第1行截取到第3行,不包括第3行, 和python的切片一致
df[1:] # 从第1行截取到尾, 和python的切片一致
df[:5] # 从头截取到第5行,不包括第5行, 和python的切片一致
df[:] # 截取所有数据, 和python的切片一致
选择某一列
df[\'gender\'] # 类似字典形式选择某列
df.gender # 类似属性形式选择某列
# df[\'gender\']等效于df.gender
选择某些列
df.loc[:, [\'affairs\', \'gender\', \'education\']] # loc[:,] 形式 冒号表示所有行
同时选择某些行某些列
df.loc[[1, 2, 4], [\'affairs\', \'gender\']]
df.loc[1:5, [\'affairs\', \'education\']]
df.loc[:, [\'affairs\', \'gender\', \'education\']]
df.loc[6:, [\'affairs\', \'gender\', \'education\']]
df.loc[:5, [\'affairs\', \'gender\', \'education\']]
备注:
①公式
【,】逗号前面是选择的行,行可以是切片,可以是列表。后面是选择的列,列可以是列表
②loc可以使用iloc代替,唯一不同的是iloc传递的参数是位置下标
df.iloc[[1, 2, 4], [1, 2, 3]]
df.iloc[1:5, 2:]
df.iloc[:, :5]
df.iloc[6:, 2:5]
df.iloc[:5, :]
获取某个位置的值
df.at[1, \'gender\'] # 获取第1行, 第gender列的值
df.at[5, \'education\'] # 获取第5行, 第education列的值
df.iat[5, 3] # 获取第5行第3列的值
df.iat[3, 8] # 获取第3行第8列的值
备注:
①iat函数类似于iloc函数,都是需要传递下标
②at函数类似于loc函数,可以直接传递索引名和列名
上述几个函数参考代码
import pandas as pd
from pandas import DataFrame, RangeIndex
def choose_one_row(df: DataFrame):
data = df.loc[RangeIndex(1)] # 默认是RangeIndex类型的索引,所以可以这么选择第1行 但不会降维 不会从二维数组降到一维数组
print(data)
print("*" * 50)
data = df.loc[0] # 默认是RangeIndex类型的索引,所以可以这么选择第1行 会降维 直接从二维数组降到一维数组
print(data)
print("*" * 50)
data = df.loc[RangeIndex(start=5, stop=6)] # 默认是RangeIndex类型的索引,所以可以这么选择第5行 但不会降维 不会从二维数组降到一维数组
print(data)
print("*" * 50)
data = df.loc[5] # 默认是RangeIndex类型的索引,所以可以这么选择第5行 会降维 直接从二维数组降到一维数组
print(data)
print("*" * 50)
def choose_rows(df: DataFrame):
print(df)
print("*" * 50)
data = df[1:3] # 从第1行截取到第3行,不包括第3行, 和python的切片一致
print(data)
print("*" * 50)
data = df[1:] # 从第1行截取到尾, 和python的切片一致
print(data)
print("*" * 50)
data = df[:5] # 从头截取到第5行,不包括第5行, 和python的切片一致
print(data)
print("*" * 50)
data = df[:] # 截取所有数据, 和python的切片一致
print(data)
def choose_one_column(df: DataFrame):
gender = df[\'gender\'] # 类似字典形式选择某列
print(gender)
print("*" * 50)
other = df.gender # 类似属性形式选择某列
print(other)
print("*" * 50)
print(gender is other) # df[\'gender\']等效于df.gender
def choose_columns(df: DataFrame):
print(df)
print("*" * 50)
data = df.loc[:, [\'affairs\', \'gender\', \'education\']] # loc[:,] 形式 冒号表示所有行
print(data)
def choose_rows_columns(df: DataFrame):
print(df)
print("*" * 50)
data = df.loc[[1, 2, 4], [\'affairs\', \'gender\']]
print(data)
print("*" * 50)
data = df.loc[1:5, [\'affairs\', \'education\']]
print(data)
print("*" * 50)
data = df.loc[:, [\'affairs\', \'gender\', \'education\']]
print(data)
print("*" * 50)
data = df.loc[6:, [\'affairs\', \'gender\', \'education\']]
print(data)
print("*" * 50)
data = df.loc[:5, [\'affairs\', \'gender\', \'education\']]
print(data)
print("*" * 50)
def choose_rows_columns2(df: DataFrame):
print(df)
print("*" * 50)
data = df.iloc[[1, 2, 4], [1, 2, 3]]
print(data)
print("*" * 50)
data = df.iloc[1:5, 2:]
print(data)
print("*" * 50)
data = df.iloc[:, :5]
print(data)
print("*" * 50)
data = df.iloc[6:, 2:5]
print(data)
print("*" * 50)
data = df.iloc[:5, :]
print(data)
print("*" * 50)
def choose_value(df: DataFrame):
print(df)
print("*" * 50)
data = df.at[1, \'gender\'] # 获取第1行, 第gender列的值
print(data)
print("*" * 50)
data = df.at[5, \'education\'] # 获取第5行, 第education列的值
print(data)
print("*" * 50)
data = df.iat[5, 3] # 获取第5行第3列的值
print(data)
print("*" * 50)
data = df.iat[3, 8] # 获取第3行第8列的值
print(data)
print("*" * 50)
def main():
df: DataFrame = pd.read_csv("csvs/Src-Affairs.csv") # 返回DataFrame二维数组对象
# choose_one_column(df)
df2 = df[:10]
# choose_rows(df2)
# choose_one_row(df2)
# choose_columns(df2)
# choose_rows_columns(df2)
choose_value(df2)
if __name__ == \'__main__\':
main()
Pandas中常用的函数使用
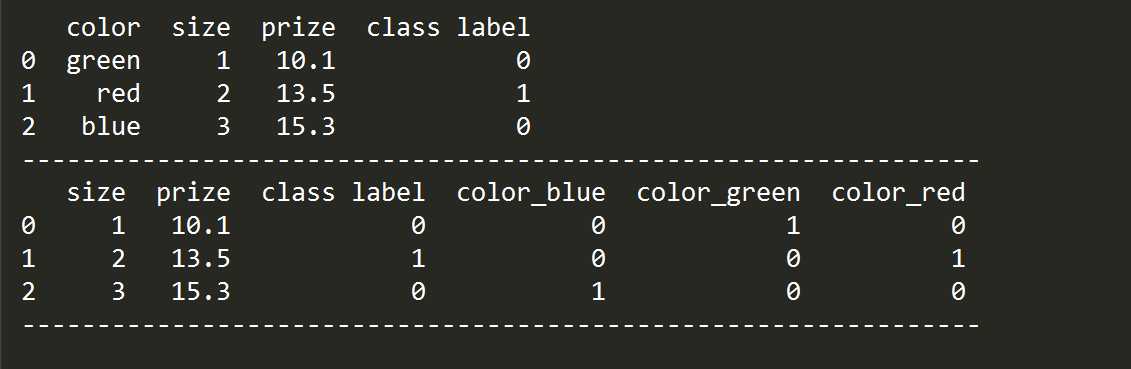
1、离散值的onehot编码
pd.get_dummies()
import pandas as pd #对于离散值不能进行编码的利用onehot编码 df = pd.DataFrame([ [‘green‘, ‘M‘, 10.1, ‘class1‘], [‘red‘, ‘L‘, 13.5, ‘class2‘], [‘blue‘, ‘XL‘, 15.3, ‘class1‘]]) df.columns = [‘color‘, ‘size‘, ‘prize‘, ‘class label‘] size_mapping = { ‘XL‘: 3, ‘L‘: 2, ‘M‘: 1} df[‘size‘] = df[‘size‘].map(size_mapping) class_mapping = {label: idx for idx, label in enumerate(set(df[‘class label‘]))} df[‘class label‘] = df[‘class label‘].map(class_mapping) print(‘----------------------------------------------------------------‘) print(df) print(‘----------------------------------------------------------------‘) df = pd.get_dummies(df) print(df) print(‘----------------------------------------------------------------‘)
2、DROP——删除pandas DataFrame的某一/几列
1. DF= DF.drop(‘column_name‘, 1);
2. DF.drop(‘column_name‘,axis=1, inplace=True)
3. DF.drop([DF.columns[[0,1, 3]]], axis=1,inplace=True) # Note: zero indexed
凡是会对原数组作出修改并返回一个新数组的,往往都有一个 inplace可选参数。如果手动设定为True(默认为False),那么原数组直接就被替换。也就是说,采用inplace=True之后,原数组名(如2和3情况所示)对应的内存值直接改变;而采用inplace=False之后,原数组名对应的内存值并不改变,需要将新的结果赋给一个新的数组或者覆盖原数组的内存位置。
以上是关于pandas的简单使用-2-常用函数的主要内容,如果未能解决你的问题,请参考以下文章