详解GaussDB(DWS)的query_band负载识别与应用
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解GaussDB(DWS)的query_band负载识别与应用相关的知识,希望对你有一定的参考价值。
摘要:query_band是一个会话级别(session)的GUC参数,本身是字符串类型,支持任意形式字符组合。
本文分享自华为云社区《GaussDB(DWS)的query_band负载识别与应用》,作者:门前一棵葡萄树。
query_band概述
GaussDB(DWS)实现了基于query_band的负载识别和优先级调度,一方面提供了更为灵活的负载识别手段,不再局限于依据“用户-资源池”的映射关系将作业路由至对应资源池,提供了“键值对-资源池”的路由方式;另一方面实现了作业优先级调度,出现排队时按照优先级调度作业。
管理员用户可根据业务场景及作业类别配置query_band关联的资源池和优先级等实现更为灵活的负载管理。如果业务未配置query_band或用户未将query_band关联行为时,作业会默认使用用户关联的资源池和默认优先级(Medium)。
query_band是什么?
query_band是一个会话级别(session)的GUC参数,本身是字符串类型,支持任意形式字符组合。query_band用于负载识别时,为了便于区分、解决无意义字符串难以理解的问题,仅支持识别键值对形式的字符串。query_band键值对有以下限制:
- 仅支持识别键值对形式的字符串,即:“key=value”;
- 有效字符:数字0~9、大写字母A~Z、小写字母a~z以及部分符号(‘.’、‘-’、‘_’ 以及‘#’);
- 单个键值对最大长度1024;
- 支持多个键值对组合,键值对之间使用分号分隔;
- 示例:SET query_band = ‘JobName=abc;AppName=test;ApplicationName=jdbc’。
query_band负载识别
GaussDB(DWS)提供的资源管理功能,从资源池维度实现了资源隔离管控和查询调度,借此实现了不同业务间的资源隔离。资源池作为资源管控和查询调度的基本单位,查询运行前需要确定使用哪个资源池,在查询调度和查询运行过程中使用该资源池资源(计算资源/并发等)。
查询是由用户发起运行的,而且一般情况下用户都是按业务划分的,因此理所当然地就想到将用户和资源池关联起来,以此实现用户的查询在对应资源池运行的效果。GaussDB(DWS)提供了用户-资源池关联的能力,默认情况下用户关联默认资源池,可根据业务需求创建自定义资源,并将用户关联至自定义资源池,用户查询依据“用户-资源池”的关联关系将查询路由至对应资源池执行,以此实现对查询并发、内存及CPU资源的管控。从而实现对不同业务之间的资源限制和隔离,满足数据库混合负载需求,保证查询执行时资源调度的有序可控。
“用户-资源池”提供的用户和资源池的关联关系,对于用户和业务混合交叉(多个用户均对应多个业务)的场景就不适用了。此外一个资源池内不同用户的作业可能有不同优先级,此时就需要给不同用户或业务配置不同优先级,实现优先级调度。因此就需要提供一种能力,一方面不再局限于“用户-资源池”的关联方式,一方面还可以实现资源池内的优先级调度。这种情况下,query_band负载识别应运而生。
query_band负载识别提供了两方面能力:
- 一方面提供了更为灵活的负载识别手段,不再局限于依据“用户-资源池”的映射关系将作业路由至对应资源池,提供了“键值对-资源池”的路由方式;
- 另一方面实现了优先级调度,支持为不同用户或业务设置不同的优先级,实现资源池内的优先级调度。
query_band功能实现
工作原理
query_band负载识别以键值对为单位,用户使用的键值对可能有很多,但实际上关联负载行为的键值对只有很少的一部分,为方便后续理解,这里按是否关联负载行为,将键值对分为有效键值对和无效键值对:
有效键值对:有关联负载行为;
无效键值对:未关联任何负载行为。
会话内设置的query_band可能包含多个键值对,不同场景下可能要使用不同的键值对进行负载识别,以实现负载控制(分时/分天)。当query_band内包含唯一有效键值对时,使用该键值对进行负载识别;当query_band内包含多个有效键值对时,按以下规则选择有效键值对进行负载识别:
- 键值对匹配顺序不同时,优先选择匹配序号最小的键值对进行负载识别;
- 所有键值对匹配顺序相同时,按照先后顺序选择靠前的键值对进行负载识别
示例:假设set query_band=\'b=1;a=3;c=1\'中所有键值对匹配顺序都一样,则选择b=1进行负载识别;假设set query_band=‘b=1;a=3;c=1’ ,其中b=1顺序为-1,a=3顺序为4,c=1顺序为1,则选择c=1进行负载识别。
识别能力
管理员用户根据业务场景和负载变化,调整业务(不同业务对应不同query_band键值对)使用的资源池和调度优先级。业务运行过程中负载识别与query_band工作机制如下:
- 会话内设置query_band,示例:SET query_band=\'JobName=abc;UserName=elk\';
- 负载管理模块解析query_band,判断其中是否包含有效键值对;
- query_band内不包含有效键值对,则使用"用户-资源池"的方式将作业路由至对应资源池运行,同时设置作业优先级为Medium;
- query_band内包含有效键值对,则使用“键值对-资源池”的方式将作业路由至对应资源池运行,同时设置作业优先级为键值对关联优先级;
- 作业在对应资源池,按照设置的优先级进行排队,等待查询调度。
优先级调度
query_band支持高中低(High/Medium/Low)三个优先级,同时提供Rush作为特殊优先级(绿色通道),默认优先级为Medium。实践过程中,建议大部分作业使用Medium优先级,优先级较低作业使用Low优先级,特权作业使用High优先级,High作业不建议过多。Rush优先级作为特殊场景下应急使用,平时不建议使用。
调度时优先调度高优作业,高优作业全部调度完才调度低优作业,GaussDB(DWS)包含多个优先级队列。除动态负载管理场景下,CN全局并发控制队列不支持优先级调度外,以下队列均支持优先级调度(按优先级顺序调度):
- 静态负载管理场景下,CN全局并发控制队列;
- 动态负载管理场景下,CCN全局内存管控队列;
- 资源池并发控制和内存管控队列。(动态静态均支持)
作业运行过程中可通过pgxc_session_wlmstat/pg_session_wlmstat视图查询作业优先级,视图中优先级显示为INT类型,数字和优先级对应关系如下:

query_band对外接口
gs_wlm_set_queryband_action
提供FUNCTION:gs_wlm_set_queryband_action(query_band cstring, action cstring, order int4)用于设置query_band负载行为,函数返回值类型为bool,表示函数调用是否成功,包含三个入参,含义如下:
- query_band:query_band键值对
- action:负载行为
- order:匹配顺序(序号),缺省参数,默认值-1
应用示例:设置query_band键值对“UserName=elk”关联资源池p1、优先级Rush、匹配顺序为1。
SELECT * FROM gs_wlm_set_queryband_action(\'UserName=elk\',\'respool=p1;priority=rush\',1);
gs_wlm_set_queryband_order
提供FUNCTION:gs_wlm_set_queryband_order(query_band cstring, order int4)用于修改query_band匹配顺序,函数返回值类型为bool,表示函数调用是否成功,包含两个入参,含义如下:
- query_band:query_band键值对
- order:匹配顺序(序号),缺省参数,默认值-1
除-1外,不允许两个query_band键值对使用相同匹配顺序,设置query_band键值对匹配顺序时,如果存在query_band持有该匹配顺序,则其顺序自动+1,重复上述步骤直至无相同匹配顺序的query_band键值对存在。匹配顺序中-1最大,代表匹配优先级最低,最小值为0,代表匹配优先级最高。
应用示例:假设query_band键值对“UserName=elk”的匹配顺序为1,“UserName=bin”的匹配顺序为2,“UserName=yagao”的匹配顺序为3,此时设置query_band键值对“UserName=on”匹配顺序为1。
SELECT * FROM gs_wlm_set_queryband_order(\'UserName=on\',1);
设置完成后,query_band键值对匹配顺序如下:

系统表pg_workload_action
query_band支持多种负载行为,使用系统表pg_workload_action存储不同query_band键值对对应的负载行为。为了后续扩展性(新增负载行为不需要新增字段),系统表设计采用一行对应一个负载行为的方式存储,当一个query_band键值对关联多个负载行为时,每个负载行为存储一行数据。系统表包含四个字段:
- qband:键值对
- class:负载行为类别
- object:负载行为名称
- action:关联的负载行为
query_band目前支持以下负载行为,其中query_band键值对的匹配顺序(序号)也作为一种负载行为存储在系统表中。

备注:默认值不需要存储在系统表中;资源池保存的是OID。
示例:假设已经设置query_band键值对“UserName=elk”关联资源池p1、优先级Rush、匹配顺序为1;“UserName=on”关联资源池p1、优先级Medium、匹配顺序为-1。查询pg_workload_action结果如下:
postgres=# select * from pg_workload_action order by 1,2; qband | classname | objname | action --------------+-----------+----------+-------- UserName=elk | order | respool | 1 UserName=elk | workload | respool | 16722 UserName=elk | workload | priority | rush UserName=on | workload | respool | 16722 (4 rows)
pg_queryband_action视图
pg_workload_action系统表用于存储query_band键值对负载行为,查询query_band行为可以直接查询该表,但是随着每一个负载行为显示一行的方式易用性较差,因此我们提供了pg_queryband_action用于查询所有query_band键值对的负载行为,每一行对应一个键值对的所有负载行为。
示例:假设已经设置query_band键值对“UserName=elk”关联资源池p1、优先级Rush、匹配顺序为1;“UserName=on”关联资源池p1、优先级Medium、匹配顺序为-1。查询pg_queryband_action结果如下:
postgres=# select * from pg_queryband_action; qband | respool_id | respool | priority | qborder --------------+------------+---------+----------+--------- UserName=on | 16722 | p1 | Medium | -1 UserName=elk | 16722 | p1 | rush | 1 (2 rows)
query_band应用
基础应用
创建资源池respool_1,并创建用户user_1关联资源池respool_1、respool_2。不设置query_band负载行为场景下,使用user_1用户运行作业,此时user_1作业全部路由至respool_1运行,优先级为Medium。
设置query_band键值对"JobName=elk"的负载行为为关联资源池respool_2,优先级为Medium;设置query_band键值对"JobName=on"的负载行为为优先级High。user_1用户分别设置不同的query_band运行作业,不同作业运行方式、关联资源池及作业优先级如下表所示:

扩展应用(用户优先级调度)
创建资源池respool_1,并创建用户user_1、user_2、user_3关联资源池respool_1。不设置query_band负载行为场景下,使用user_1、user_2和user_3用户运行作业,此时user_1、user_2和user_3作业全部路由至respool_1运行,优先级均为Medium。
设置query_band键值对"UserName=elk"的优先级为High;设置query_band键值对"UserName=on"的优先级为Low。
备注:“UserName=elk”、“UserName=on”只用于用户标识,没有特殊含义,用户可按需配置。
按以下方式设置用户默认query_band:
ALTER USER user_2 SET query_band=\'UserName=elk\'; ALTER USER user_3 SET query_band=\'UserName=on\';
会话内不单独设置query_band,使用user_1、user_2和user_3用户运行作业,此时user_1作业优先级为Medium(默认优先级),user_2作业优先级为High(对应键值对“UserName=elk”),user_3作业优先级为Low(对应键值对“UserName=on”)。
此外,用户还可设置包含多个键值对的query_band,在不同场景下(或不同时间段),按照不同键值对进行负载识别,实现更为灵活的负载控制,这里就不再赘述了。
基于SpringBoot实现操作GaussDB(DWS)的项目实战
摘要:本文就使用springboot结合mybatis plus在项目中实现对GaussDB(DWS)的增删改查操作。
本文分享自华为云社区《基于SpringBoot实现操作GaussDB(DWS)的项目实战【玩转PB级数仓GaussDB(DWS)】》,作者:清雨小竹。
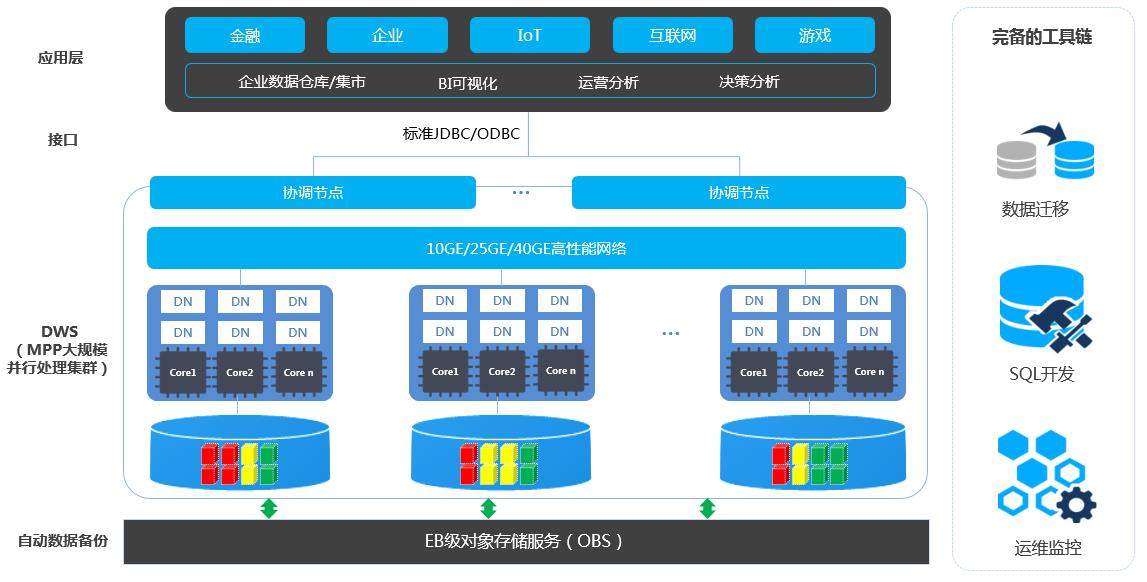
GaussDB(DWS)
数据仓库服务GaussDB(DWS) 是一种基于华为云基础架构和平台的在线数据处理数据库,提供即开即用、可扩展且完全托管的分析型数据库服务。GaussDB(DWS)是基于华为融合数据仓库GaussDB产品的云原生服务 ,兼容标准ANSI SQL 99和SQL 2003,同时兼容PostgreSQL/Oracle数据库生态,为各行业PB级海量大数据分析提供有竞争力的解决方案。
GaussDB(DWS) 基于Shared-nothing分布式架构,具备MPP (Massively Parallel Processing)大规模并行处理引擎,由众多拥有独立且互不共享的CPU、内存、存储等系统资源的逻辑节点组成。在这样的系统架构中,业务数据被分散存储在多个节点上,数据分析任务被推送到数据所在位置就近执行,并行地完成大规模的数据处理工作,实现对数据处理的快速响应。
Spring Boot
Spring Boot是一个构建在Spring框架顶部的项目。它提供了一种简便,快捷的方式来设置,配置和运行基于Web的简单应用程序。它是一个Spring模块,提供了 RAD(快速应用程序开发)功能。它用于创建独立的基于Spring的应用程序,因为它需要最少的Spring配置,因此可以运行。简而言之,Spring Boot是 Spring Framework 和 嵌入式服务器的组合。在Spring Boot不需要XML配置(部署描述符)。它使用约定优于配置软件设计范例,这意味着可以减少开发人员的工作量。我们可以使用Spring STS IDE 或 Spring Initializr 进行开发Spring Boot Java应用程序。

Mybatis plus(MP)
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集,MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Ordinary Java Object,普通的 Java对象)映射成数据库中的记录。MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
华为云官方文档给出了使用JDBC连接GaussDB(DWS)并实现增删改查基本操作的教程和代码示例。教程:使用JDBC或ODBC开发_数据仓库服务 GaussDB(DWS)_8.1.3推荐版_华为云,在java开发中springboot作为一个常用的开发框架在很多项目中使用,下面就使用springboot结合mybatis plus在项目中实现对GaussDB(DWS)的增删改查操作。
一、新建springboot项目
1.打开idea基于向导新建springboot项目。
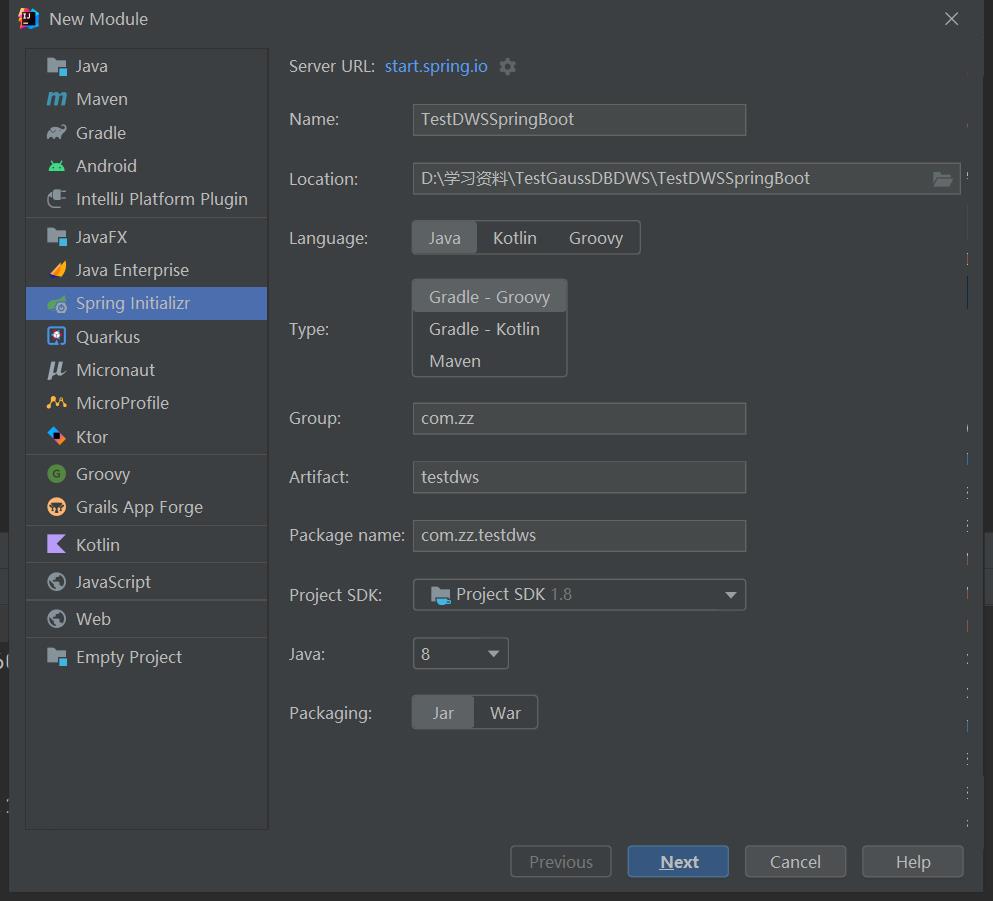
2.添加依赖JDBC API和SpringWeb
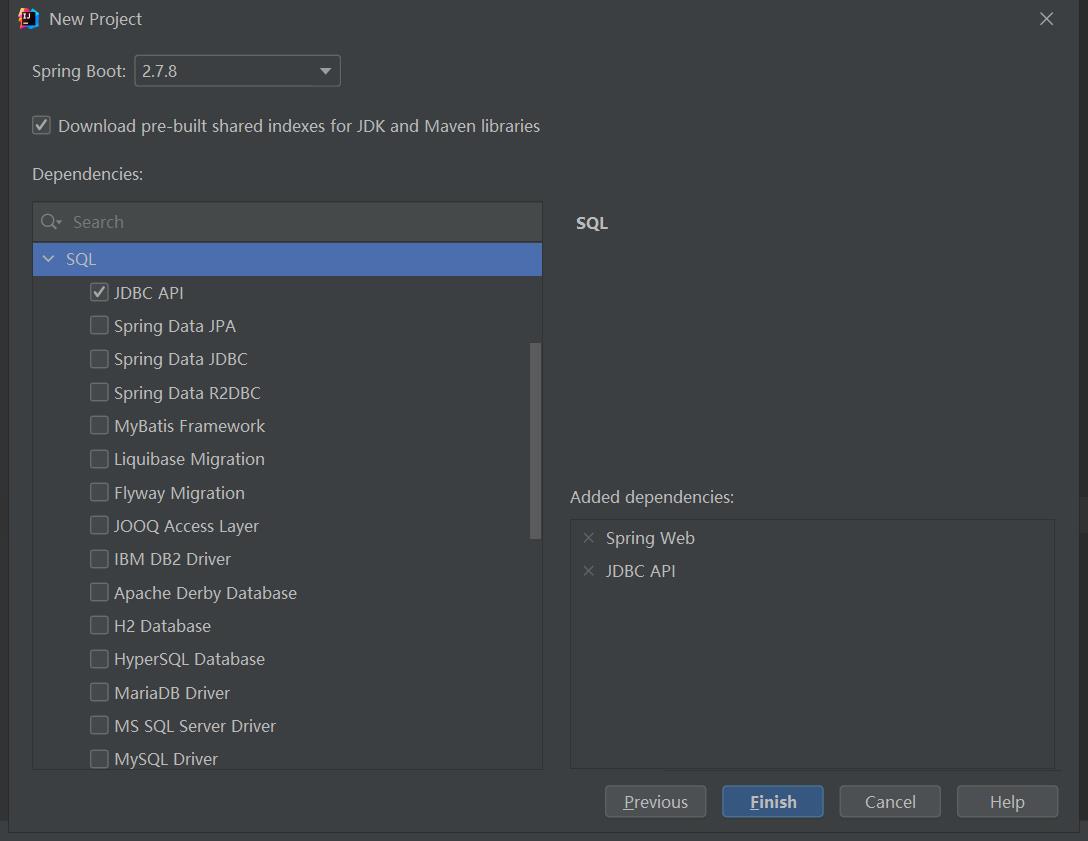
3.项目新建完成后打开新建libs文件夹,把jdbc驱动复制到libs目录下。下载JDBC或ODBC驱动_数据仓库服务 GaussDB(DWS)_集群管理指南_连接集群_使用JDBC和ODBC连接集群_华为云
- gsjdbc4.jar:与PostgreSQL保持兼容,其中类名、类结构与PostgreSQL驱动完全一致,曾经运行于PostgreSQL的应用程序可以直接移植到当前系统中使用。
- gsjdbc200.jar:如果同一JVM进程内需要同时访问PostgreSQL及GaussDB(DWS) 请使用该驱动包。该包主类名为“com.huawei.gauss200.jdbc.Driver”(即将“org.postgresql”替换为“com.huawei.gauss200.jdbc”) ,数据库连接的URL前缀为“jdbc:gaussdb”,其余与gsjdbc4.jar相同。、
4.jar包上鼠标点击右键,点击Add as Library。

5.打开build.gradle,添加mybatis plus依赖,由于GaussDB DWS兼容PostgreSQL所以runtimeOnly可以使用org.postgresql:postgresql
dependencies
//mybatis-plus
implementation 'com.baomidou:mybatis-plus-boot-starter:3.5.2'
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
implementation 'org.springframework.boot:spring-boot-starter-web'
runtimeOnly 'org.postgresql:postgresql'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
6.打开application.properties配置数据库源信息。
spring.datasource.driver-class-name=org.postgresql.Driver
spring.datasource.url=jdbc:postgresql://xx.xx.xx.xx:8000/database?currentSchema=traffic_data
spring.datasource.username=dbadmin
spring.datasource.password=xxxxxx二、配置mybatis plus
7.新增数据表
CREATE TABLE "traffic_data"."customer" (
"id" int4,
"c_customer_sk" int4,
"c_customer_name" varchar(32)
);8.新增包名com.zz.testdws.mapper和com.zz.testdws.entity

9.新建实体类对象customer.java和Mappder对象CustomerMapper.java文件
package com.zz.testdws.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
/**
* <p>
*
* </p>
*
* @author zzzili
* @since 2023-02-16
*/
public class customer
private static final long serialVersionUID = 1L;
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
private Integer cCustomerSk;
private String cCustomerName;
@Override
public String toString()
return "customer" +
"id=" + id +
", cCustomerSk=" + cCustomerSk +
", cCustomerName='" + cCustomerName + '\\'' +
'';
public Integer getId()
return id;
public void setId(Integer id)
this.id = id;
public Integer getcCustomerSk()
return cCustomerSk;
public void setcCustomerSk(Integer cCustomerSk)
this.cCustomerSk = cCustomerSk;
public String getcCustomerName()
return cCustomerName;
public void setcCustomerName(String cCustomerName)
this.cCustomerName = cCustomerName;
package com.zz.testdws.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.zz.testdws.entity.customer;
/**
* <p>
* Mapper 接口
* </p>
*
* @author zzzili
* @since 2023-02-15
*/
public interface CustomerMapper extends BaseMapper<customer>
10.打开TestDwsSpringBootApplication.java文件,添加mapper扫描器注解@MapperScan("com.zz.testdws.mapper")
package com.zz.testdws;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.zz.testdws.mapper")
public class TestDwsSpringBootApplication
public static void main(String[] args)
SpringApplication.run(TestDwsSpringBootApplication.class, args);
三、测试数据
11.打开TestDwsSpringBootApplicationTests.java文件编写代码,测试用sql执行增删改查数据。
@Autowired
DataSource dataSource;
@Test
void testDoSQL() throws SQLException
System.out.println(dataSource.getClass());
//获取连接
Connection con = dataSource.getConnection();
//调用Connection的createStatement方法创建语句对象
Statement stmt = con.createStatement();
//调用Statement的executeUpdate方法执行SQL语句
//int rc = stmt.executeUpdate("CREATE TABLE customer_t1(c_customer_sk INTEGER, c_customer_name VARCHAR(32));");
//System.out.println("rc = " + rc);
//int rc = stmt.executeUpdate("INSERT INTO customer_t1(c_customer_sk,c_customer_name) values('1001','zhangsan');");
//System.out.println("insert rc = " + rc);
//查询数据
ResultSet rs= stmt.executeQuery("select * from customer_t1");
//遍历数据
while(rs.next())
String sk = rs.getString("c_customer_sk");
String name = rs.getString("c_customer_name");
System.out.println("sk:"+sk+" 姓名:"+name);
con.close();

12.编写代码测试使用mybatis plus实现增删改查。
@Autowired
CustomerMapper customerMapper;
@Test
void testMybatis()
//增加
customer cus=new customer();
cus.setcCustomerName("zzzili");
cus.setcCustomerSk(123456);
cus.setId(8);
customerMapper.insert(cus);
//改
cus.setcCustomerSk(66666);
customerMapper.updateById(cus);
//查
List<customer> list = customerMapper.selectList(null);
System.out.println("list size="+list.size());
for(customer node :list)
System.out.println(node);
//删除
customerMapper.deleteById(1);


总结:通过以上实验实现了在springboot框架中利用mybatis ORM框架对GaussDB(DWS)的增删改查(ARUD)操作,在项目开发中更具有实用性。本示例项目已上传至附件。
附件:测试项目代码.rar9.50MB
以上是关于详解GaussDB(DWS)的query_band负载识别与应用的主要内容,如果未能解决你的问题,请参考以下文章