java故障处理基础命令行工具
Posted Mars.wang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java故障处理基础命令行工具相关的知识,希望对你有一定的参考价值。
一、基础命令行工具
1.jps:虚拟机进程状况工具
可以列出本机正在运行的虚拟机进程,并显示主类
1.1.选项:
| 选项 | 作用 |
|---|---|
| -q | 省略主类,只显示id |
| -l | 显示主类全名,或jar包路径 |
| -m | 显示传递给主类main方法的参数 |
| -v | 输出jvm启动时所有参数 |
2.jstat:虚拟机统计信息监控
用于监视虚拟机运行状态的命令行工具,可以显示本地或远程进程的类加载、内存、垃圾收集,即时编译等运行时数据;
使用jstat工具在纯文本状态下监视虚拟机状态的变化, 在用户体验上也许不如JMC、 VisualVM等可视化的监视工具直接以图表展现那样直观, 但在实际生产环境中不一定可以使用图形界面, 直接在控制台中使用jstat命令依然是一种常用的监控方式
2.1.命令行格式:
jstat [ option vmid [interval[s|ms] [count]] ]
参数interval和count代表查询间隔和次数, 如果省略这2个参数, 说明只查询一次
选项option代表用户希望查询的虚拟机信息, 主要分为三类: 类加载、 垃圾收集、 运行期编译状况。
2.2.选项
| 选项 | 作用 |
|---|---|
| -class | 监视类加载、卸载数量,及类加载所耗时间 |
| -gc | 监视java堆,含Eden区,2个survivor区,老年代、永久代容量,已用空间,gc时间 |
| -gccapacity | 与-gc相同,主要输出java堆各区使用到的最大最小空间 |
| -gcutil | 与-gc相同,主要输出已用空间在总空间的占比 |
| -gccause | 与-gcutil相同,但会输出上次gc的原因 |
| -gcnew | 监视新生代垃圾收集状况 |
| -gcnewcapacity | 与-gcnew相同,主要关注使用的最大最小空间 |
| -gcold | 监视老年代垃圾收集状况 |
| -gcoldcapacity | 与-gcold相同,主要关注使用的最大最小空间 |
| -gcpermcapacity | 监视永久代使用最大最小空间 |
| -compiler | 输出即时编译器编译的方法和耗时 |
| -printcompilation | 输出已被编译过的方法 |
3.jinfo:java配置信息
使用jps命令的-v参数可以查看虚拟机启动时显式指定的参数列表, 但如果想知道未被显式指定的参数的系统默认值, 就只能使用jinfo的-flag选项进行查询了
4.jmap:java内存映像工具
jmap用于生产堆转储快照
4.1.选项
| 选项 | 作用 |
|---|---|
| -dump | 生产java堆内存转储快照 |
| -finalizerinfo | 显示等待finalizer线程执行finalize的对象,只在Linux有用 |
| -heap | 显示java堆详细信息,只在Linux有用 |
| -histo | 显示堆对象统计信息,包括类、实例、合计容量 |
| -permstat | 显示永久代内存数量,只在Linux有用 |
| -F | 强制生成dump快照 |
4.2.案例
jmap -dump:format=b,file=eclipse.bin 3500
5.jstack:java堆栈跟踪工具
用于生成虚拟机当前时刻的线程快照。 线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合, 生成线程快照的目的通常是定位线程出现长时间停顿的原因, 如线程间死锁、 死循环、 请求外部资源导致的长时间挂 起等, 都是导致线程长时间停顿的常见原因。 线程出现停顿时通过jstack来查看各个线程的调用堆栈,就可以获知没有响应的线程到底在后台做些什么事情, 或者等待着什么资源。
5.1.选项
| 选项 | 作用 |
|---|---|
| -F | 强制输出线程堆栈 |
| -l | 除堆栈外,显示关于锁的附加信息 |
| -m | 如果调用本地方法,可以显示c/c++堆栈 |
jvm,深入理解java虚拟机,虚拟机性能监控与故障处理工具(JDK的命令行工具和 JDK的可视化工具)
给一个系统定位问题的时候,知识、经验是关键基础,数据是依据,工具是运用知识处
理数据的手段。这里说的数据包括:运行日志、异常堆栈、GC日志、线程快照
(threaddump/javacore文件)、堆转储快照(heapdump/hprof文件)等。经常使用适当的虚拟
机监控和分析的工具可以加快我们分析数据、定位解决问题的速度,但在学习工具前,也应
当意识到工具永远都是知识技能的一层包装,没有什么工具是“秘密武器”,不可能学会了就
能包治百病。
JDK的命令行工具
Java开发人员肯定都知道JDK的bin目录中有“java.exe”、“javac.exe”这两个命令行工具,
但并非所有程序员都了解过JDK的bin目录之中其他命令行程序的作用。每逢JDK更新版本之
时,bin目录下命令行工具的数量和功能总会不知不觉地增加和增强。
表4-1中说明了JDK主要命令行监控工具的用途。
注意 如果读者在工作中需要监控运行于JDK 1.5的虚拟机之上的程序,在程序启动时
请添加参数“-Dcom.sun.management.jmxremote”开启JMX管理功能,否则由于部分工具都是基
于JMX(包括4.3节介绍的可视化工具),它们都将会无法使用,如果被监控程序运行于JDK
1.6的虚拟机之上,那JMX管理默认是开启的,虚拟机启动时无须再添加任何参数。

jps:虚拟机进程状况工具
JDK的很多小工具的名字都参考了UNIX命令的命名方式,jps(JVM Process Status
Tool)是其中的典型。除了名字像UNIX的ps命令之外,它的功能也和ps命令类似:可以列出
正在运行的虚拟机进程,并显示虚拟机执行主类(Main Class,main()函数所在的类)名称
以及这些进程的本地虚拟机唯一ID(Local Virtual Machine Identifier,LVMID)。虽然功能比较
单一,但它是使用频率最高的JDK命令行工具,因为其他的JDK工具大多需要输入它查询到
的LVMID来确定要监控的是哪一个虚拟机进程。对于本地虚拟机进程来说,LVMID与操作系
统的进程ID(Process Identifier,PID)是一致的,使用Windows的任务管理器或者UNIX的ps命
令也可以查询到虚拟机进程的LVMID,但如果同时启动了多个虚拟机进程,无法根据进程名
称定位时,那就只能依赖jps命令显示主类的功能才能区分了
jsp命令格式:jps[options][hostid]
jps执行样例:
C:\\Users\\mucha>jps -l
2388 D:\\Develop\\glassfish\\bin\\..\\modules\\admin-cli.jar
2764 com.sun.enterprise.glassfish.bootstrap.ASMain
3788 sun.tools.jps.Jpsjps的其他常用选项见表4-2

jstat:虚拟机统计信息监视工具
jstat(JVM Statistics Monitoring Tool)是用于监视虚拟机各种运行状态信息的命令行工
具。它可以显示本地或者远程
虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数
据,在没有GUI图形界面,只提供了纯文本控制台环境的服务器上,它将是运行期定位虚拟
机性能问题的首选工具。
jstat命令格式为:jstat[option vmid[interval[s|ms][count]]]
对于命令格式中的VMID与LVMID需要特别说明一下:如果是本地虚拟机进程,VMID与
LVMID是一致的,如果是远程虚拟机进程,那VMID的格式应当是:
[protocol:][//]lvmid[@hostname[:port]/servername]
参数interval和count代表查询间隔和次数,如果省略这两个参数,说明只查询一次。假设
需要每250毫秒查询一次进程2764垃圾收集状况,一共查询20次,那命令应当是:
jstat-gc 2764 250 20
选项option代表着用户希望查询的虚拟机信息,主要分为3类:类装载、垃圾收集、运行
期编译状况,具体选项及作用请参考表4-3中的描述。
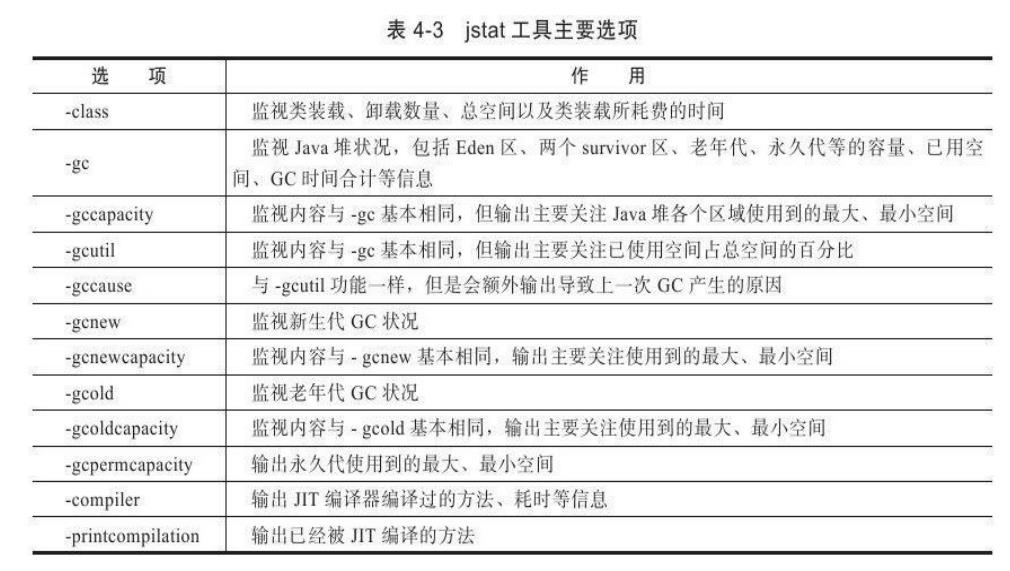
jstat监视选项众多,囿于版面原因无法逐一演示,这里仅举监视一台刚刚启动的
GlassFish v3服务器的内存状况的例子来演示如何查看监视结果。监视参数与输出结果如代码
清单4-1所示。
代码清单4-1 jstat执行样例
C:\\Users\\mucha>jstat -gcutil 2764
S0 S1 E O P YGC YGCT FGC FGCT GCT
0.00 0.00 6.20 41.42 47.20 16 0.105 3 0.472 0.577查询结果表明:这台服务器的新生代Eden区(E,表示Eden)使用了6.2%的空间,两个
Survivor区(S0、S1,表示Survivor0、Survivor1)里面都是空的,老年代(O,表示Old)和
永久代(P,表示Permanent)则分别使用了41.42%和47.20%的空间。程序运行以来共发生
Minor GC(YGC,表示Young GC)16次,总耗时0.105秒,发生Full GC(FGC,表示Ful
GC)3次,Full GC总耗时(FGCT,表示Full GC Time)为0.472秒,所有GC总耗时(GCT,
表示GC Time)为0.577秒。
使用jstat工具在纯文本状态下监视虚拟机状态的变化,确实不如后面将会提到的
VisualVM等可视化的监视工具直接以图表展现那样直观。但许多服务器管理员都习惯了在文
本控制台中工作,直接在控制台中使用jstat命令依然是一种常用的监控方式。
jinfo:Java配置信息工具
jinfo(Configuration Info for Java)的作用是实时地查看和调整虚拟机各项参数。使用jps
命令的-v参数可以查看虚拟机启动时显式指定的参数列表,但如果想知道未被显式指定的参
数的系统默认值,除了去找资料外,就只能使用jinfo的-flag选项进行查询了(如果只限于
JDK 1.6或以上版本的话,使用java-XX:+PrintFlagsFinal查看参数默认值也是一个很好的选
择),jinfo还可以使用-sysprops选项把虚拟机进程的System.getProperties()的内容打印出
来。这个命令在JDK 1.5时期已经随着Linux版的JDK发布,当时只提供了信息查询的功
能,JDK 1.6之后,jinfo在Windows和Linux平台都有提供,并且加入了运行期修改参数的能
力,可以使用-flag[+|-]name或者-flag name=value修改一部分运行期可写的虚拟机参数值。
JDK 1.6中,jinfo对于Windows平台功能仍然有较大限制,只提供了最基本的-flag选项。
jinfo命令格式:
jinfo [option] pid
执行样例:查询CMSInitiatingOccupancyFraction参数值。
C:\\>jinfo -flag CMSInitiatingOccupancyFraction 1444
-XX:CMSInitiatingOccupancyFraction=85jmap:Java内存映像工具
jmap(Memory Map for Java)命令用于生成堆转储快照(一般称为heapdump或dump文
件)。如果不使用jmap命令,要想获取Java堆转储快照,还有一些比较“暴力”的手段:譬如
在第2章中用过的-XX:+HeapDumpOnOutOfMemoryError参数,可以让虚拟机在OOM异常出
现之后自动生成dump文件,通过-XX:+HeapDumpOnCtrlBreak参数则可以使用[Ctrl]+[Break]
键让虚拟机生成dump文件,又或者在Linux系统下通过Kill-3命令发送进程退出信号“吓唬”一
下虚拟机,也能拿到dump文件。
jmap的作用并不仅仅是为了获取dump文件,它还可以查询finalize执行队列、Java堆和永
久代的详细信息,如空间使用率、当前用的是哪种收集器等。
和jinfo命令一样,jmap有不少功能在Windows平台下都是受限的,除了生成dump文件的-
dump选项和用于查看每个类的实例、空间占用统计的-histo选项在所有操作系统都提供之
外,其余选项都只能在Linux/Solaris下使用。
jmap命令格式:
jmap[option]vmid
option选项的合法值与具体含义见表4-4。
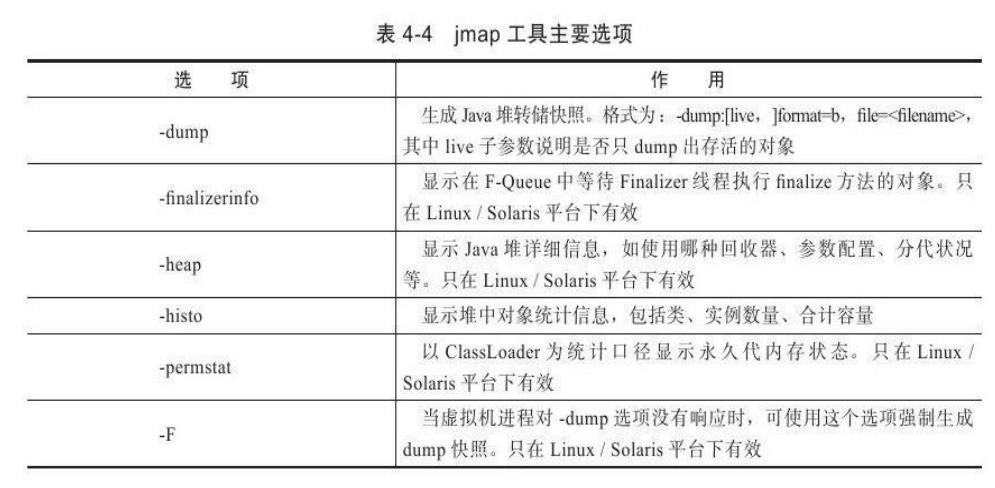
代码清单4-2是使用jmap生成一个正在运行的Eclipse的dump快照文件的例子,例子中的
3500是通过jps命令查询到的LVMID。
代码清单4-2 使用jmap生成dump文件
C:\\Users\\IcyFenix>jmap -dump:format=b,file=eclipse.bin 3500
Dumping heap to C:\\Users\\IcyFenix\\eclipse.bin……
Heap dump file createdjhat:虚拟机堆转储快照分析工具
Sun JDK提供jhat(JVM Heap Analysis Tool)命令与jmap搭配使用,来分析jmap生成的堆
转储快照。jhat内置了一个微型的HTTP/HTML服务器,生成dump文件的分析结果后,可以在
浏览器中查看。不过实事求是地说,在实际工作中,除非笔者手上真的没有别的工具可用,
否则一般都不会去直接使用jhat命令来分析dump文件,主要原因有二:一是一般不会在部署
应用程序的服务器上直接分析dump文件,即使可以这样做,也会尽量将dump文件复制到其
他机器
上进行分析,因为分析工作是一个耗时而且消耗硬件资源的过程,既然都要在其他
机器进行,就没有必要受到命令行工具的限制了;另一个原因是jhat的分析功能相对来说比
较简陋,后文将会介绍到的VisualVM,以及专业用于分析dump文件的Eclipse Memory
Analyzer、IBM HeapAnalyzer
等工具,都能实现比jhat更强大更专业的分析功能。下面代码演示了使用jhat分析采用jmap生成的Eclipse IDE的内存快照文件。
C:\\Users\\IcyFenix>jhat eclipse.bin
Reading from eclipse.bin……
Dump file created Fri Nov 19 22:07:21 CST 2010
Snapshot read,resolving……
Resolving 1225951 objects……
Chasing references,expect 245 dots……
Eliminating duplicate references……
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.屏幕显示“Server is ready.”的提示后,用户在浏览器中键入http://localhost:7000/就可以
看到分析结果,如图4-3所示。
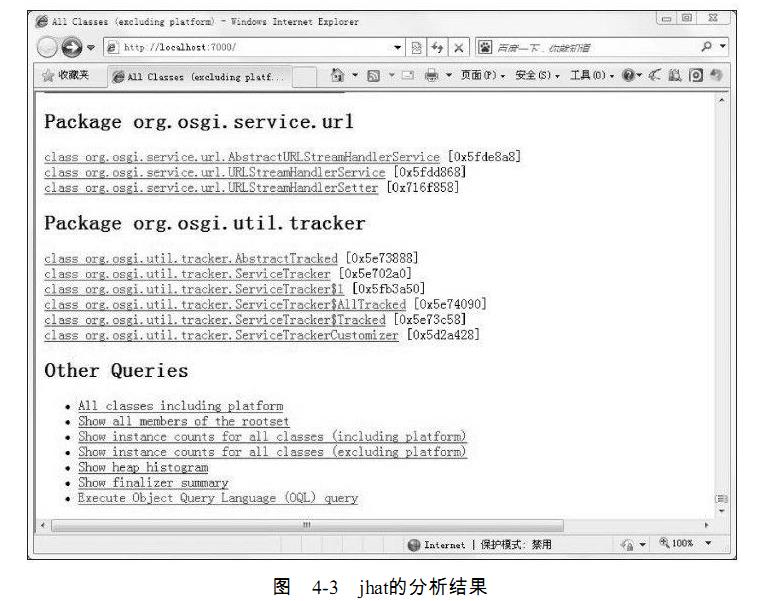
分析结果默认是以包为单位进行分组显示,分析内存泄漏问题主要会使用到其中
的“Heap Histogram”(与jmap-histo功能一样)与OQL页签的功能,前者可以找到内存中总容
量最大的对象,后者是标准的对象查询语言,使用类似SQL的语法对内存中的对象进行查询
统计,读者若对OQL有兴趣的话,可以参考本书附录D的介绍。
jstack:Java堆栈跟踪工具
jstack(Stack Trace for Java)命令用于生成虚拟机当前时刻的线程快照(一般称为
threaddump或者javacore文件)。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈
的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循
环、请求外部资源导致的长时间等待等都是导致线程长时间停顿的常见原因。线程出现停顿
的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做些
什么事情,或者等待着什么资源。
jstack命令格式:
jstack[option]vmid
option选项的合法值与具体含义见表4-5。

代码清单4-4是使用jstack查看Eclipse线程堆栈的例子,例子中的3500是通过jps命令查询
到的LVMID。
代码清单4-4 使用jstack查看线程堆栈(部分结果)
C:\\Users\\IcyFenix>jstack -l 3500
2010-11-19 23:11:26
Full thread dump Java HotSpot(TM)64-Bit Server VM(17.1-b03 mixed mode): "[ThreadPool Manager]-Idle Thread"daemon prio=6 tid=0x0000000039dd4000 nid=0xf50 in Object.wait()[0x000000003c96f000]
java.lang.Thread.State:WAITING(on object monitor) at java.lang.Object.wait(Native Method) -waiting on<0x0000000016bdcc60>(a org.eclipse.equinox.internal.util.impl.tpt.threadpool.Executor) at java.lang.Object.wait(Object.java:485) at org.eclipse.equinox.internal.util.impl.tpt.threadpool.Executor.run(Executor.java:106) -locked<0x0000000016bdcc60>(a org.eclipse.equinox.internal.util.impl.tpt.threadpool.Executor) Locked ownable synchronizers: -None在JDK 1.5中,java.lang.Thread类新增了一个getAllStackTraces()方法用于获取虚拟机
中所有线程的StackTraceElement对象。使用这个方法可以通过简单的几行代码就完成jstack的
大部分功能,在实际项目中不妨调用这个方法做个管理员页面,可以随时使用浏览器来查看
线程堆栈,如代码清单4-5所示,这是笔者的一个小经验。
代码清单4-5 查看线程状况的JSP页面
<%@page language="java" import="java.util.Map" %>
<html>
<head>
<title>服务器线程信息</title>
</head>
<body>
<pre>
<%
for(Map.Entry<Thread,StackTraceElement[]> stackTrace:Thread.getAllStackTraces().entrySet())
Thread thread=(Thread)stackTrace.getKey();
StackTraceElement[] stack=(StackTraceElement[])stackTrace.getValue();
if(thread.equals(Thread.currentThread()))
continue;
out.print("\\n线程:"+thread.getName()+"\\n");
for(StackTraceElement element:stack)
out.print("\\t"+element+"\\n");
%>
</pre>
</body>
</html>
JDK的可视化工具
JDK中除了提供大量的命令行工具外,还有两个功能强大的可视化工具:JConsole和
VisualVM,这两个工具是JDK的正式成员,没有被贴上“unsupported and experimental”的标
签。
其中JConsole是在JDK 1.5时期就已经提供的虚拟机监控工具,而VisualVM在JDK 1.6
Update7中才首次发布,现在已经成为Sun(Oracle)主力推动的多合一故障处理工具[1]
,并且
已经从JDK中分离出来成为可以独立发展的开源项目。
为了避免本节的讲解成为对软件说明文档的简单翻译,笔者准备了一些代码样例,都是
笔者特意编写的“反面教材”。后面将会使用这两款工具去监控、分析这几段代码存在的问
题,算是本节简单的实战分析。读者可以把在可视化工具观察到的数据、现象,与前面两章
中讲解的理论知识互相印证。
JConsole:Java监视与管理控制台
JConsole(Java Monitoring and Management Console)是一种基于JMX的可视化监视、管
理工具。它管理部分的功能是针对JMX MBean进行管理,由于MBean可以使用代码、中间件
服务器的管理控制台或者所有符合JMX规范的软件进行访问,所以本节将会着重介绍
JConsole监视部分的功能。
1.启动JConsole
通过JDK/bin目录下的“jconsole.exe”启动JConsole后,将自动搜索出本机运行的所有虚拟
机进程,不需要用户自己再使用jps来查询了,如图4-4所示。双击选择其中一个进程即可开
始监控,也可以使用下面的“远程进程”功能来连接远程服务器,对远程虚拟机进行监控。
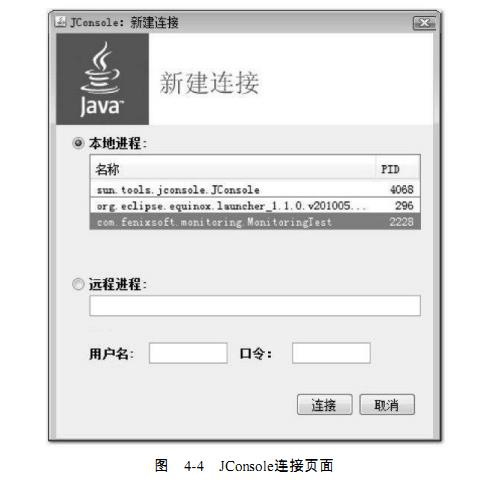
从图4-4可以看出,笔者的机器现在运行了Eclipse、JConsole和MonitoringTest三个本地虚
拟机进程,其中MonitoringTest就是笔者准备的“反面教材”代码之一。双击它进入JConsole主
界面,可以看到主界面里共包括“概述”、“内存”、“线程”、“类”、“VM摘要”、“MBean”6个
页签,如图4-5所示。
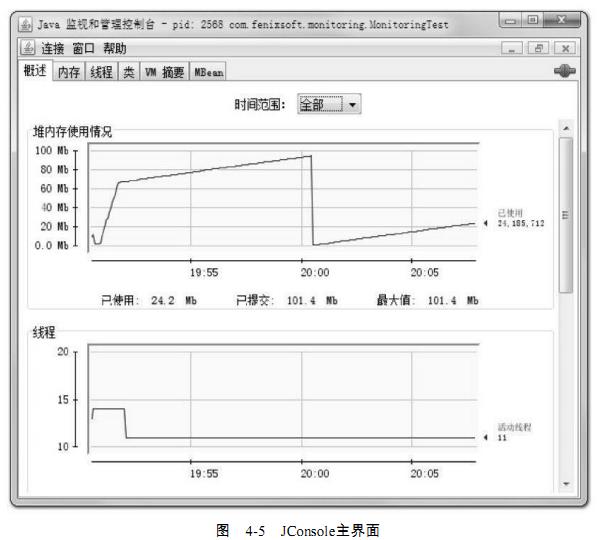
“概述”页签显示的是整个虚拟机主要运行数据的概览,其中包括“堆内存使用情况”、
线程”、“类”、“CPU使用情况”4种信息的曲线图,这些曲线图是后面“内存”、“线程”、
类”页签的信息汇总,具体内容将在后面介绍。
2.内存监控
“内存”页签相当于可视化的jstat命令,用于监视受收集器管理的虚拟机内存(Java堆和
永久代)的变化趋势。我们通过运行代码清单4-8中的代码来体验一下它的监视功能。运行
时设置的虚拟机参数为:-Xms100m-Xmx100m-XX:+UseSerialGC,这段代码的作用是以
4KB/50毫秒的速度往Java堆中填充数据,一共填充1000次,使用JConsole的“内存”页签进行
监视,观察曲线和柱状指示图的变化。
代码清单4-8 JConsole监视代码
import java.util.ArrayList;
import java.util.List;
/**
* JConsole监视代码
*
*/
public class MonitoringTest
public static void fillHeap(int num)throws InterruptedException
List<OOMObject> oomObjects=new ArrayList<>();
for(int i=0;i<num;i++)
//稍作延时,令监视曲线的变化更加明显
Thread.sleep(100);
oomObjects.add(new OOMObject());
System.gc();
public static void main(String[] args) throws InterruptedException
fillHeap(1000);
/**
*内存占位符对象,一个OOMObject大约占64KB
*/
static class OOMObject
public byte[] placeholder=new byte[64*1024];
程序运行后,在“内存”页签中可以看到内存池Eden区的运行趋势呈现折线状,如图4-6
所示。而监视范围扩大至整个堆后,会发现曲线是一条向上增长的平滑曲线。并且从柱状图
可以看出,在1000次循环执行结束,运行了System.gc()后,虽然整个新生代Eden和
Survivor区都基本被清空了,但是代表老年代的柱状图仍然保持峰值状态,说明被填充进堆
中的数据在System.gc()方法执行之后仍然存活。笔者的分析到此为止,现提两个小问题供
读者思考一下,答案稍后给出。
1)虚拟机启动参数只限制了Java堆为100MB,没有指定-Xmn参数,能否从监控图中估
计出新生代有多大?
2)为何执行了System.gc()之后,图4-6中代表老年代的柱状图仍然显示峰值状态,代
码需要如何调整才能让System.gc()回收掉填充到堆中的对象?
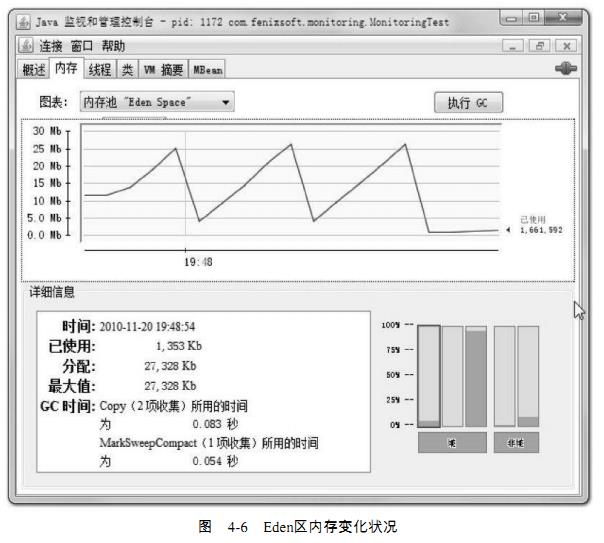
问题1答案:图4-6显示Eden空间为27 328KB,因为没有设置-XX:SurvivorRadio参数,
所以Eden与Survivor空间比例为默认值8:1,整个新生代空间大约为27 328KB×125%=34
160KB。
问题2答案:执行完System.gc()之后,空间未能回收是因为List<OOMObject>list对象
仍然存活,fillHeap()方法仍然没有退出,因此list对象在System.gc()执行时仍然处于作
用域之内[2]
。如果把System.gc()移动到fillHeap()方法外调用就可以回收掉全部内存。
3.线程监控
如果上面的“内存”页签相当于可视化的jstat命令的话,“线程”页签的功能相当于可视化
的jstack命令,遇到线程停顿时可以使用这个页签进行监控分析。前面讲解jstack命令的时候
提到过线程长时间停顿的主要原因主要有:等待外部资源(数据库连接、网络资源、设备资
源等)、死循环、锁等待(活锁和死锁)。通过代码清单4-9分别演示一下这几种情况。
代码清单4-9 线程等待演示代码
/**
* 线程等待演示代码
*
*/
public class MonitoringTest2
public static void createBusyThread()
Thread thread=new Thread(new Runnable()
@Override
public void run()
while (true)
,"createBusyThread");
thread.start();
public static void createLockThread(final Object lock)
Thread thread=new Thread(new Runnable()
@Override
public void run()
synchronized (lock)
try
lock.wait();
catch (Exception e)
e.printStackTrace();
,"createLockThread");
thread.start();
/**
*线程死循环演示 */
public static void main(String[] args) throws InterruptedException, IOException
BufferedReader bufferedReader=new BufferedReader(new InputStreamReader(System.in));
System.out.println("111");
bufferedReader.readLine();
System.out.println("222");
createBusyThread();
bufferedReader.readLine();
Object o=new Object();
createLockThread(o);
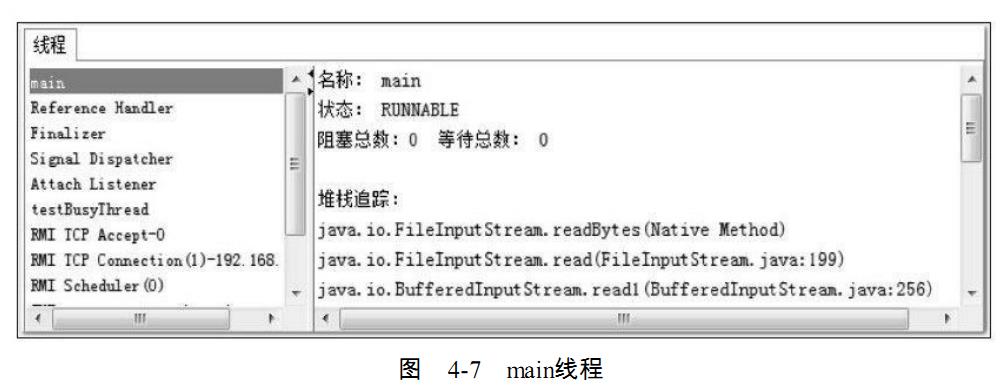
程序运行后,首先在“线程”页签中选择main线程,如图4-7所示。堆栈追踪显示
bufferedReader在readBytes方法中等待System.in的键盘输入,这时线程为Runnable状
态,Runnable状态的线程会被分配运行时间,但readBytes方法检查到流没有更新时会立刻归
还执行令牌,这种等待只消耗很小的CPU资源。
接着监控testBusyThread线程,如图4-8所示,testBusyThread线程一直在执行空循环,从
堆栈追踪中看到一直在MonitoringTest.java代码的41行停留,41行为:while(true)。这时候
线程为Runnable状态,而且没有归还线程执行令牌的动作,会在空循环上用尽全部执行时间
直到线程切换,这种等待会消耗较多的CPU资源。
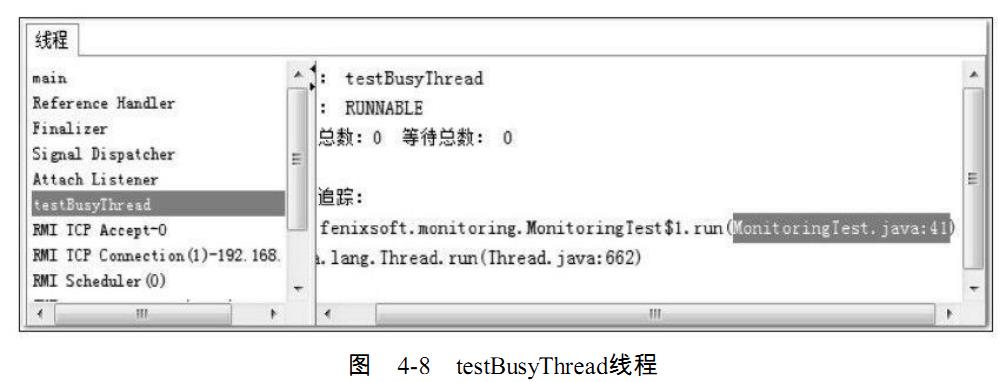
图4-9显示testLockThread线程在等待着lock对象的notify或notifyAll方法的出现,线程这时
候处于WAITING状态,在被唤醒前不会被分配执行时间。

testLockThread线程正在处于正常的活锁等待,只要lock对象的notify()或notifyAll()
方法被调用,这个线程便能激活以继续执行。代码清单4-10演示了一个无法再被激活的死锁
等待。
代码清单4-10 死锁代码样例
import java.io.IOException;
/**
* 死锁代码样例
*
*/
public class MonitoringTest3
public static void main(String[] args) throws InterruptedException, IOException
for(int i=0;i<100;i++)
new Thread(new SynAddRunalbe(1,2)).start();
new Thread(new SynAddRunalbe(2,1)).start();
static class SynAddRunalbe implements Runnable
int a,b;
public SynAddRunalbe(int a, int b)
this.a = a;
this.b = b;
@Override
public void run()
synchronized (Integer.valueOf(a))
synchronized (Integer.valueOf(b))
System.out.println(a+b);
这段代码开了200个线程去分别计算1+2以及2+1的值,其实for循环是可省略的,两个线
程也可能会导致死锁,不过那样概率太小,需要尝试运行很多次才能看到效果。一般的话,
带for循环的版本最多运行2~3次就会遇到线程死锁,程序无法结束。造成死锁的原因是
Integer.valueOf()方法基于减少对象创建次数和节省内存的考虑,[-128,127]之间的数字会
被缓存[3]
,当valueOf()方法传入参数在这个范围之内,将直接返回缓存中的对象。也就是
说,代码中调用了200次Integer.valueOf()方法一共就只返回了两个不同的对象。假如在某
个线程的两个synchronized块之间发生了一次线程切换,那就会出现线程A等着被线程B持有
的Integer.valueOf(1),线程B又等着被线程A持有的Integer.valueOf(2),结果出现大家都
跑不下去的情景。
出现线程死锁之后,点击JConsole线程面板的“检测到死锁”按钮,将出现一个新的“死
锁”页签,如图4-10所示。
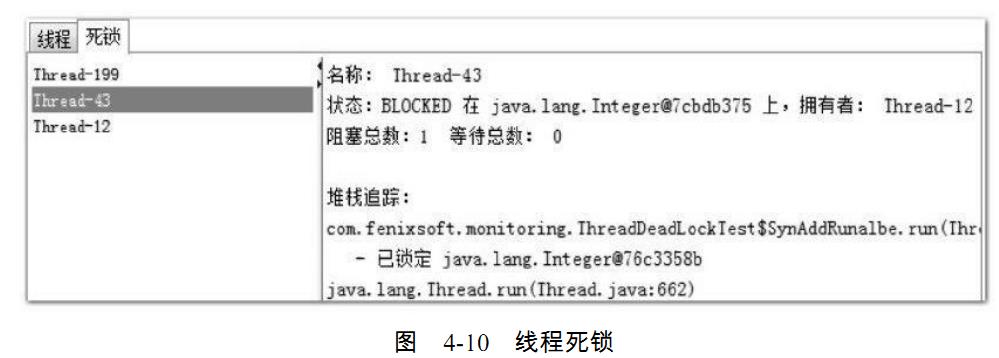
图4-10中很清晰地显示了线程Thread-43在等待一个被线程Thread-12持有Integer对象,而
点击线程Thread-12则显示它也在等待一个Integer对象,被线程Thread-43持有,这样两个线程
就互相卡住,都不存在等到锁释放的希望了。
VisualVM:多合一故障处理工具
VisualVM(All-in-One Java Troubleshooting Tool)是到目前为止随JDK发布的功能最强大
的运行监视和故障处理程序,并且可以预见在未来一段时间内都是官方主力发展的虚拟机故
障处理工具。官方在VisualVM的软件说明中写上了“All-in-One”的描述字样,预示着它除了
运行监视、故障处理外,还提供了很多其他方面的功能。如性能分析
(Profiling),VisualVM的性能分析功能甚至比起JProfiler、YourKit等专业且收费的Profiling
工具都不会逊色多少,而且VisualVM的还有一个很大的优点:不需要被监视的程序基于特殊
Agent运行,因此它对应用程序的实际性能的影响很小,使得它可以直接应用在生产环境
中。这个优点是JProfiler、YourKit等工具无法与之媲美的。
1.VisualVM兼容范围与插件安装
VisualVM基于NetBeans平台开发,因此它一开始就具备了插件扩展功能的特性,通过插
件扩展支持,VisualVM可以做到:
显示虚拟机进程以及进程的配置、环境信息(jps、jinfo)。
监视应用程序的CPU、GC、堆、方法区以及线程的信息(jstat、jstack)。
dump以及分析堆转储快照(jmap、jhat)。
方法级的程序运行性能分析,找出被调用最多、运行时间最长的方法。
离线程序快照:收集程序的运行时配置、线程dump、内存dump等信息建立一个快照,
可以将快照发送开发者处进行Bug反馈。
其他plugins的无限的可能性……
首次启动VisualVM后,读者先不必着急找应用程序进行监测,因为现在VisualVM还没有
加载任何插件,虽然基本的监视、线程面板的功能主程序都以默认插件的形式提供了,但是
不给VisualVM装任何扩展插件,就相当于放弃了它最精华的功能,和没有安装任何应用软件
操作系统差不多。
插件可以进行手工安装,在相关网站[2]
上下载*.nbm包后,点击“工具”→“插件”→“已下
载”菜单,然后在弹出的对话框中指定nbm包路径便可进行安装,插件安装后存放在
JDK_HOME/lib/visualvm/visualvm中。不过手工安装并不常用,使用VisualVM的自动安装功
能已经可以找到大多数所需的插件,在有网络连接的环境下,点击“工具”→“插件菜单”,弹
出如图4-11所示的插件页签,在页签的“可用插件”中列举了当前版本VisualVM可以使用的插
件,选中插件后在右边窗口将显示这个插件的基本信息,如开发者、版本、功能描述等。
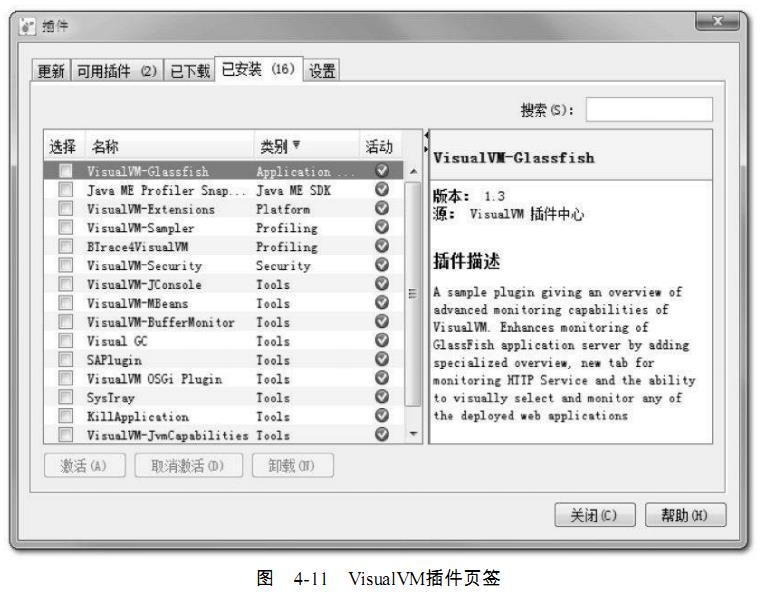
大家可以根据自己的工作需要和兴趣选择合适的插件,然后点击安装按钮,弹出如图4-
12所示的下载进度窗口,跟着提示操作即可完成安装。
打开VisualVM,点击工具=》插件-》可用插件报错,说叫你检查代理设置或稍后重试。当前该服务器不可用。 您可能还需要确保防火墙不会阻塞网络通信。他没说错,就是你的插件路径不可用,你可以先关闭防火墙,但还是一样的错,有503,连接超时等等,解决办法。
第一执行网址: https://visualvm.github.io/pluginscenters.html

第二找到对应的jdk,我是JDK7选择第二个,打开
第三步复制上面那个catalog URL地址。
第四部点击设置,编辑,把复制的路径放入URL中,点击确定。

第五步点击可用插件,勾选需要安装的插件,如我这里的Visual GC,点安装,再重启就可以了。
VisualVM中“概述”、“监视”、“线程”、“MBeans”的功能与前面介绍的JConsole差别不
大,读者根据上文内容类比使用即可,下面挑选几个特色功能、插件进行介绍。
2.生成、浏览堆转储快照
在VisualVM中生成dump文件有两种方式,可以执行下列任一操作:
在“应用程序”窗口中右键单击应用程序节点,然后选择“堆Dump”。
在“应用程序”窗口中双击应用程序节点以打开应用程序标签,然后在“监视”标签中单
击“堆Dump”。
生成了dump文件之后,应用程序页签将在该堆的应用程序下增加一个以[heapdump]开头
的子节点,并且在主页签中打开了该转储快照,如图4-14所示。如果需要把dump文件保存或
发送出去,要在heapdump节点上右键选择“另存为”菜单,否则当VisualVM关闭时,生成的
dump文件会被当做临时文件删除掉。要打开一个已经存在的dump文件,通过文件菜单中
的“装入”功能,选择硬盘上的dump文件即可。
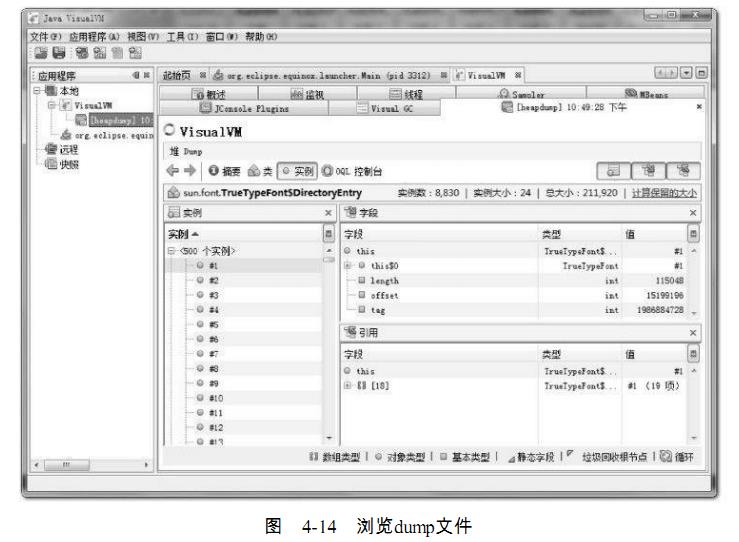
从堆页签中的“摘要”面板可以看到应用程序dump时的运行时参数、
System.getProperties()的内容、线程堆栈等信息,“类”面板则是以类为统计口径统计类的实
例数量、容量信息,“实例”面板不能直接使用,因为不能确定用户想查看哪个类的实例,所
以需要通过“类”面板进入,在“类”中选择一个关心的类后双击鼠标,即可在“实例”里面看见
此类中500个实例的具体属性信息。“OQL控制台”面板中就是运行OQL查询语句的,同jhat中
介绍的OQL功能一样。如果需要了解具体OQL语法和使用,可参见本书附录D的内容。
3.分析程序性能
在Profiler页签中,VisualVM提供了程序运行期间方法级的CPU执行时间分析以及内存分
析,做Profiling分析肯定会对程序运行性能有比较大的影响,所以一般不在生产环境中使用
这项功能。
要开始分析,先选择“CPU”和“内存”按钮中的一个,然后切换到应用程序中对程序进行
操作,VisualVM会记录到这段时间中应用程序执行过的方法。如果是CPU分析,将会统计每
个方法的执行次数、执行耗时;如果是内存分析,则会统计每个方法关联的对象数以及这些
对象所占的空间。分析结束后,点击“停止”按钮结束监控过程。
注意 在JDK 1.5之后,在Client模式下的虚拟机加入并且自动开启了类共享——这是一
个在多虚拟机进程中共享rt.jar中类数据以提高加载速度和节省内存的优化,而根据相关Bug
报告的反映,VisualVM的Profiler功能可能会因为类共享而导致被监视的应用程序崩溃,所以
读者进行Profiling前,最好在被监视程序中使用-Xshare:off参数来关闭类共享优化。
4.BTrace动态日志跟踪
BTrace是一个很“有趣”的VisualVM插件,本身也是可以独立运行的程序。它的作用是
在不停止目标程序运行的前提下,通过HotSpot虚拟机的HotSwap技术
动态加入原本并不存
在的调试代码。这项功能对实际生产中的程序很有意义:经常遇到程序出现问题,但排查错
误的一些必要信息,譬如方法参数、返回值等,在开发时并没有打印到日志之中,以至于不
得不停掉服务,通过调试增量来加入日志代码以解决问题。当遇到生产环境服务无法随便停
止时,缺一两句日志导致排错进行不下去是一件非常郁闷的事情。
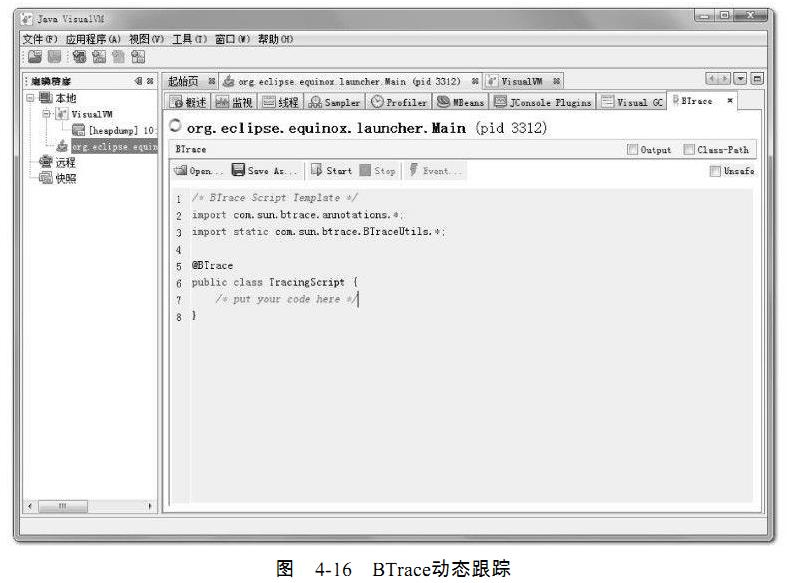
在VisualVM中安装了BTrace插件后,在应用程序面板中右键点击要调试的程序,会出
现“Trace Application……”菜单,点击将进入BTrace面板。这个面板里面看起来就像一个简单
的Java程序开发环境,里面还有一小段Java代码,如图4-16所示。
笔者准备了一段很简单的Java代码来演示BTrace的功能:产生两个1000以内的随机整
数,输出这两个数字相加的结果,如代码清单4-11所示。
代码清单4-11 BTrace跟踪演示
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
/**
* BTrace跟踪演示
*/
public class BTraceTest
public int add(int a,int b)
return a+b;
public static void main(String[] args) throws IOException
BTraceTest bTraceTest=new BTraceTest();
BufferedReader bufferedReader=new BufferedReader(new InputStreamReader(System.in));
for (;;)
bufferedReader.readLine();
int a=(int)Math.round(Math.random()*1000);
int b=(int)Math.round(Math.random()*1000);
System.out.println(bTraceTest.add(a,b));
程序运行后,在VisualVM中打开该程序的监视,在BTrace页签填充TracingScript的内
容,输入的调试代码如代码清单4-12所示。
代码清单4-12 BTrace调试代码
/* BTrace Script Template */
import com.sun.btrace.annotations.*;
import static com.sun.btrace.BTraceUtils.*;
@BTrace
public class TracingScript
/* put your code here */
@OnMethod(clazz="models2.jvm.BTraceTest",method="add",location=@Location(Kind.RETURN))
public static void func(
int a,int b,
@Return int result)
println("调用堆栈:trace: =======================");
jstack();
println(strcat("方法参数A;",str(a)));
println(strcat("方法参数B;",str(b)));
println(strcat("方法结果;",str(result)));
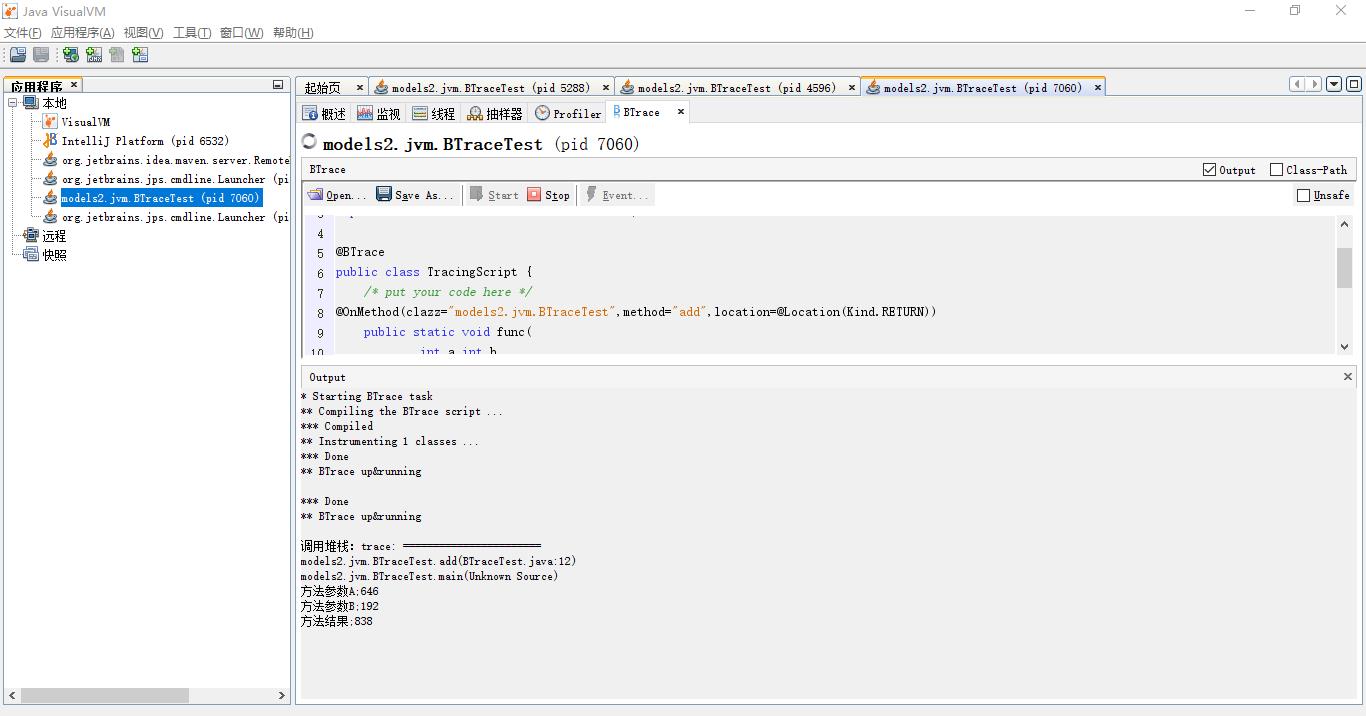
点击“Start”按钮后稍等片刻,编译完成后,可见Output面板中出现“BTrace code
successfuly deployed”的字样。程序运行的时候在Output面板将会输出如图4-17所示的调试信
息。
BTrace的用法还有许多,打印调用堆栈、参数、返回值只是最基本的应用,在它的网站
上有使用BTrace进行性能监视、定位连接泄漏和内存泄漏、解决多线程竞争问题等例子,有
兴趣的读者可以去相关网站了解一下。
以上是关于java故障处理基础命令行工具的主要内容,如果未能解决你的问题,请参考以下文章