Python 随笔之Redis
Posted SunQi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 随笔之Redis相关的知识,希望对你有一定的参考价值。
Python学习记录 ——redis
2018-03-07
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。redis是一个key-value存储系统(线程安全)。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Linux安装redis
wget http://download.redis.io/releases/redis-3.0.6.tar.gz tar -xzf redis-3.0.6.tar.gz cd redis-3.0.6 make
LInux终端使用redis
[sunqi@localhost src]$ ./redis-server#启动redis服务 [sunqi@localhost src]$ ./redis-cli #启动redis客户端 127.0.0.1:6379> #连接成功,默认本地6379端口 127.0.0.1:6379> set age 123 OK 127.0.0.1:6379> get age "123" 127.0.0.1:6379> set age 3 ex 5#设置key生存时间,到期后会自动销毁 OK 127.0.0.1:6379> get age "3" 127.0.0.1:6379> get age (nil)
在进行Python操作redis之前先用cmd控制简单连接一下redis进行试验便发现了问题我的Windows连接报错
redis.exceptions.ConnectionError: Error 10060 connecting to 192.168.30.129:6379. .
经过一番辛苦百度得知是因为Linux防火墙关闭了6379端口的对外访问,日!
解决这个问题用了我一晚上加一上午的时间,主要是因为前段时间学习的Linux知识,有点忘记了,看来不复习,不经常使用真的不行啊!
解决办法如下:
关闭防火墙 CentOS 7、RedHat 7 之前的 Linux 发行版防火墙开启和关闭( iptables ): 即时生效,重启失效 #开启 service iptables start #关闭 service iptables stop 重启生效 #开启 chkconfig iptables on #关闭 chkconfig iptables off CentOS 7、RedHat 7 之后的 Linux 发行版防火墙开启和关闭( firewall ): systemctl stop firewalld.service 开放端口 CentOS 7、RedHat 7 之前的 Linux 发行版开放端口 #命令方式开放5212端口命令 #开启5212端口接收数据 /sbin/iptables -I INPUT -p tcp --dport 5212 -j ACCEPT #开启5212端口发送数据 /sbin/iptables -I OUTPUT -p tcp --dport 5212 -j ACCEPT #保存配置 /etc/rc.d/init.d/iptables save #重启防火墙服务 /etc/rc.d/init.d/iptables restart #查看是否开启成功 /etc/init.d/iptables status CentOS 7、RedHat 7 之后的 Linux 发行版开放端口 firewall-cmd --zone=public --add-port=5121/tcp --permanent # --zone 作用域 # --add-port=5121/tcp 添加端口,格式为:端口/通讯协议 # --permanent 永久生效,没有此参数重启后失效
在我的LInux虚拟机敲入命令开放端口6379:
[root@localhost init.d]# systemctl stop firewalld.service [root@localhost init.d]# firewall-cmd --zone=public --add-port=6379/tcp --permanent
一番庆祝:
C:\\Users\\1234567890>python Python 2.7.12 (v2.7.12:d33e0cf91556, Jun 27 2016, 15:24:40) [MSC v.1500 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import redis >>> r = redis.Redis(host = \'192.168.30.129\',port = 6379) >>> r.set(\'name\',\'sunqi\') True >>> print r.get(\'name\') sunqi >>>

String操作:
redis中的String在在内存中按照一个name对应一个value来存储。
1、set
源码
def set(self, name, value, ex=None, px=None, nx=False, xx=False): """ Set the value at key ``name`` to ``value`` ``ex`` sets an expire flag on key ``name`` for ``ex`` seconds. ``px`` sets an expire flag on key ``name`` for ``px`` milliseconds. ``nx`` if set to True, set the value at key ``name`` to ``value`` only if it does not exist. ``xx`` if set to True, set the value at key ``name`` to ``value`` only if it already exists. """
中文翻译(我的理解):
ex:name的生存时间,单位秒,也就是ex= n n秒后name在内存中将不存在
px:生存时间,单位毫秒
nx:如果nx = True,当name不存在时,才会设置name-->value
xx:如果xx = True,当name已经存在时,才会设置name-->value
eg:
>>> r.set(\'sunqi\',\'123\',ex=5)#生存时间为5秒 True >>> print r.get(\'sunqi\') 123 >>> print r.get(\'sunqi\') None >>>
import redis r = redis.Redis(host=\'192.168.30.129\', port=6379) r.set(\'age\',\'32\') print(r.get(\'age\')) r.set(\'age\',\'42\',nx=True)#age已经存在,设置nx不会改变age的value print(r.get(\'age\')) r.set(\'age\',\'42\',xx=True)#age已经存在,设置xx会改变age的value print(r.get(\'age\')) b\'32\' b\'32\' b\'42\' Process finished with exit code 0
2、mset(*args, **kwargs)
批量设置值 如: mset(k1=\'v1\', k2=\'v2\') 或 mget({\'k1\': \'v1\', \'k2\': \'v2\'})
r.mset(k1=\'v1\', k2=\'v2\') print(r.get(\'k1\')) print(r.get(\'k2\'))
3.mget()
批量获取结果返回列表
r.mset(k1=\'v1\', k2=\'v2\') print(r.mget(\'k1\',\'k2\'))
4.getset(name, value)
设置新值返回旧值
r.set(\'age\',\'32\') s = r.getset(\'age\',\'42\') print(r.get(\'age\')) print(s) b\'42\' b\'32\' Process finished with exit code 0
5.getrange(key, start, end)
获取子序列(根据字节获取,非字符)
r.set(\'name\',\'kongdelin\') print(r.getrange(\'name\',1,5)) b\'ongde\' Process finished with exit code 0
6.setrange(name, offset, value)
修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
r.set(\'name\',\'kongdelin\') r.setrange(\'name\',6,\'qwertyui\') print(r.get(\'name\')) b\'kongdeqwertyui\' Process finished with exit code 0
7.setbit(name, offset, value)
对name对应值的二进制表示的位进行操作
先转换成ASCII码的二进制形式,然后对offset位进行修改
import redis #setbit(name, offset, value) r.set(\'a\',3) s = r.get(\'a\') print(\'before\',r.get(\'a\')) print(\'bofore:\',bin(ord(s.decode()))) r.setbit(\'a\',6,0) s = r.get(\'a\') print(\'after\',r.get(\'a\')) print(\'after\',bin(ord(s.decode())))
8.getbit(name, offset)
获取name对应的值的二进制表示中的某位的值 (0或1)
9.bitcount(key, start=None, end=None)
# 获取name对应的值的二进制表示中 1 的个数 # 参数: # key,Redis的name # start,位起始位置 # end,位结束位置
10.bitop(operation, dest, *keys)
# 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值 # 参数: # operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或) # dest, 新的Redis的name # *keys,要查找的Redis的name # 如: bitop("AND", \'new_name\', \'n1\', \'n2\', \'n3\') # 获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name 对应的值中
11.strlen(name)
返回name对应值的字节长度(一个汉字3个字节)
12.incr(self, name, amount=1)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 # 参数: # name,Redis的name # amount,自增数(必须是整数)
13.decr(self, name, amount=1)
自减name对应的值
14.append(key, value)
# 在redis name对应的值后面追加内容 # 参数: key, redis的name value, 要追加的字符串
Hash操作
redis中Hash在内存中的存储格式如下图:
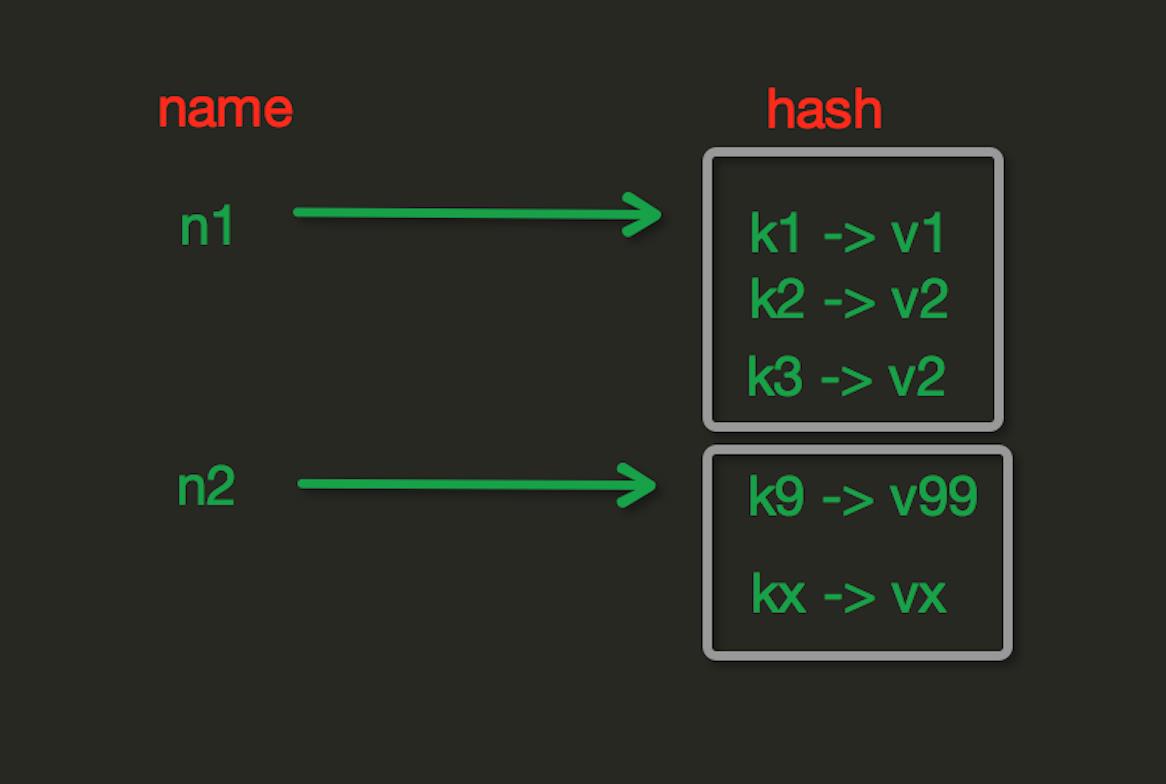
1.hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) # 参数: # name,redis的name # key,name对应的hash中的key # value,name对应的hash中的value
eg:
r.hset(\'sunqi\',\'age1\',\'12\') r.hset(\'sunqi\',\'age2\',\'14\') r.hset(\'sunqi\',\'age3\',\'13\') print(r.hget(\'sunqi\',\'age1\')) print(r.hget(\'sunqi\',\'age2\')) print(r.hget(\'sunqi\',\'age3\'))
2.hmset()
# 在name对应的hash中批量设置键值对 # 参数: # name,redis的name # mapping,字典,如:{\'k1\':\'v1\', \'k2\': \'v2\'} # 如: # r.hmset(\'xx\', {\'k1\':\'v1\', \'k2\': \'v2\'})
eg:
r.hmset(\'sunqi\',{\'k1\':\'v1\',\'k2\':\'v2\'}) print(r.hmget(\'sunqi\',\'k1\',\'k2\'))
3.hlen(name)
获取name对应的hash中键值对的个数
4.hgetall(name)
获取name对应hash的所有键值
5.hkeys(name)
获取name对应的hash中所有的key的值
6.hvals(name)
获取name对应的hash中所有的value的值
7.hdel(name,*keys)
将name对应的hash中指定key的键值对删除
8.hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount # 参数: # name,redis中的name # key, hash对应的key # amount,自增数(整数)
9.hscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆 # 参数: # name,redis的name # cursor,游标(基于游标分批取获取数据) # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # 第一次:cursor1, data1 = r.hscan(\'xx\', cursor=0, match=None, count=None) # 第二次:cursor2, data1 = r.hscan(\'xx\', cursor=cursor1, match=None, count=None) # ... # 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
10.hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据 # 参数: # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # for item in r.hscan_iter(\'xx\'): # print item
List操作
redis中的List在在内存中按照一个name对应一个List来存储。如图:
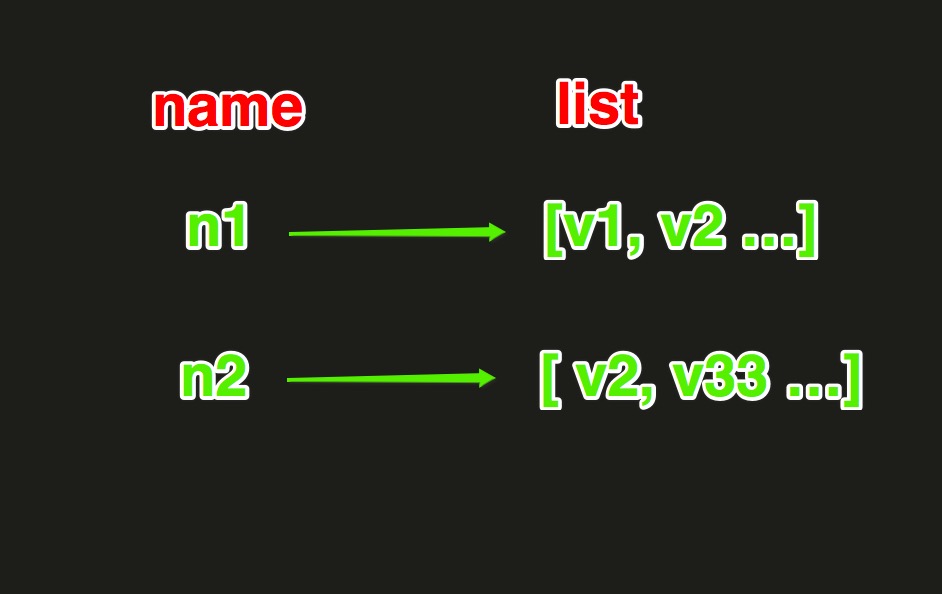
1.lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 # 如: # r.lpush(\'oo\', 11,22,33) # 保存顺序为: 33,22,11 # 扩展: # rpush(name, values) 表示从右向左操作
eg:
r.lpush(\'fooo\',11,22,33) print(r.lrange(\'fooo\',0,-1)) [b\'33\', b\'22\', b\'11\'] Process finished with exit code 0
2.lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边 # 更多: # rpushx(name, value) 表示从右向左操作
3.linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值 # 参数: # name,redis的name # where,BEFORE或AFTER # refvalue,标杆值,即:在它前后插入数据 # value,要插入的数据
r.lpush(\'fooo\',11,22,33) r.linsert(\'fooo\',\'BEFORE\',22,44) print(r.lrange(\'fooo\',0,-1)) [b\'33\', b\'44\', b\'22\', b\'11\']
4.r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值 # 参数: # name,redis的name # index,list的索引位置 # value,要设置的值
r.lpush(\'fooo\',11,22,33) print(r.lrange(\'fooo\',0,-1)) r.lset(\'fooo\',0,55) print(r.lrange(\'fooo\',0,-1)) [b\'33\', b\'22\', b\'11\'] [b\'55\', b\'22\', b\'11\'] Process finished with exit code 0
5.r.lrem(name, value, num)
# 在name对应的list中删除指定的值 # 参数: # name,redis的name # value,要删除的值 # num, num=0,删除列表中所有的指定值; # num=2,从前到后,删除2个; # num=-2,从后向前,删除2个
6.lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素 # 更多: # rpop(name) 表示从右向左操作
7.lindex(name, index)
在name对应的列表中根据索引获取列表元素
8.ltrim(name, start, end)
在name对应的列表中移除没有在start-end索引之间的值(两边的值)
9.rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边 # 参数: # src,要取数据的列表的name # dst,要添加数据的列表的name
10.自定义增量迭代
# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要: # 1、获取name对应的所有列表 # 2、循环列表 # 但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能: def list_iter(name): """ 自定义redis列表增量迭代 :param name: redis中的name,即:迭代name对应的列表 :return: yield 返回 列表元素 """ list_count = r.llen(name) for index in xrange(list_count): yield r.lindex(name, index) # 使用 for item in list_iter(\'pp\'): print item
Set操作
Set集合就是不允许重复的列表
1.sadd(name,values)
name对应的集合中添加元素
r.sadd(\'qwe\',1,2,3,4,2,33) print(r.smembers(\'qwe\'))
{b\'3\', b\'33\', b\'1\', b\'2\', b\'4\'}
Process finished with exit code 0
2.sdiff(keys, *args)
在第一个name对应的集合中且不在其他name对应的集合的元素集合
3.sdiffstore(dest, keys, *args)
获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
1 r.sadd(\'qwe\',1,2,3,4,2,33) 2 r.sadd(\'asd\',1,2,3,5) 3 print(r.smembers(\'qwe\'))#输出集合的全部成员 4 print(r.scard(\'qwe\'))#输出集合的个数 5 print(r.sdiff(\'qwe\',\'asd\'))#在第一个集合中而不再第二个集合中 6 print(r.sdiffstore(\'zxc\',\'qwe\',\'asd\')) 7 print(r.smembers(\'zxc\'))#将在第一个集合中不再第二个集合中的成员存入第三个dest集合
4.sinter(keys, *args)
r.sadd(\'asd\',1,2,3,5) r.sadd(\'qwe\',1,2,3,4,2,33) print(r.sinter(\'qwe\',\'asd\'))#取交集即在第一个集合又在第二个集合的成员
5.sinterstore(dest, keys, *args)
将并集存放在目标集合dest中
6.sismember(name, value)
检查成员是否在集合中
7.smove(src, dst, value)
将某个成员从一个集合移动到另一个集合
r.sadd(\'qwe\',1,2,3,4,2,33) r.sadd(\'asd\',1,2,3,5) print(\'qwe-->before\',r.smembers(\'qwe\')) print(\'asd-->\',r.smembers(\'asd\')) r.smove(\'qwe\',\'asd\',33) print(\'qwe-->after\',r.smembers(\'qwe\')) print(\'asd-->\',r.smembers(\'asd\')) qwe-->before {b\'1\', b\'2\', b\'3\', b\'4\', b\'33\'} asd--> {b\'5\', b\'1\', b\'2\', b\'3\', b\'33\'} qwe-->after {b\'3\', b\'4\', b\'1\', b\'2\'} asd--> {b\'5\', b\'1\', b\'2\', b\'3\', b\'33\'}
8.spop(name)
从集合的右侧(尾部)移除一个成员,并将其返回
9.srem(name, values)
在name对应的集合中删除某些值
10.sunion(keys, *args)
取两个集合的交集
有序集合
在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
1.zadd(name, *args, **kwargs)
r.zadd(\'rty\',n1=1,n2=6,n3=5,n4=100) print(r.zrange(\'rty\',0,-1,withscores=True))
[(b\'n1\', 1.0), (b\'n3\', 5.0), (b\'n2\', 6.0), (b\'n4\', 100.0)]
Process finished with exit code 0
2.zcard(name)
获取name对应的有序集合元素的数量
3.zcount(name, min, max)
获取name对应的有序集合中分数 在 [min,max] 之间的个数
4.zincrby(name, value, amount)
自增name对应的有序集合的 name 对应的分数
5.r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素 # 参数: # name,redis的name # start,有序集合索引起始位置(非分数) # end,有序集合索引结束位置(非分数) # desc,排序规则,默认按照分数从小到大排序 # withscores,是否获取元素的分数,默认只获取元素的值 # score_cast_func,对分数进行数据转换的函数 # 更多: # 从大到小排序 # zrevrange(name, start, end, withscores=False, score_cast_func=float) # 按照分数范围获取name对应的有序集合的元素 # zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float) # 从大到小排序 # zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
6.zrank(name, value)
获取某个值在 name对应的有序集合中的排行(从 0 开始)
7.zrangebylex(name, min, max, start=None, num=None)
# 当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员 # 对集合中的每个成员进行逐个字节的对比(byte-by-byte compare),以上是关于Python 随笔之Redis的主要内容,如果未能解决你的问题,请参考以下文章