一、名称空间与作用域
1.名称空间
存放名字的地方,名称空间共有三种(之前遗留的问题x=1,1存放于内存中,那名字x存放在哪里呢?名称空间正是存放名字x与1绑定关系的地方)
2.名称空间的加载顺序
python test.py
#1、python解释器先启动,因而首先加载的是:内置名称空间
#2、执行test.py文件,然后以文件为基础,加载全局名称空间
#3、在执行文件的过程中如果调用函数,则临时产生局部名称空间
3.名字的查找顺序
局部名称空间--->全局名称空间--->内置名称空间
#需要注意的是:在全局无法查看局部的,在局部可以查看全局的,如下示例
# max=1
# def f1():
# max=2
# def f2():
# max=3
# print(max)
# f2()
# f1() #打印3
# print(max) #打印1
4.作用域
#作用域即范围
- 全局范围(内置名称空间与全局名称空间属于该范围):全局存活,全局有效
- 局部范围(局部名称空间属于该范围):临时存活,局部有效
###全局变量
程序一开始定义的变量,作用域为整个程序
# NAME = "产品经理"
# def yangjian():
# print(‘我要搞‘, NAME)
# print(‘我要搞‘, NAME)
# yangjian()
###局部变量
在子程序中定义的变量,作用域为定义该变量的子程序内
# def qupengfei():
# NAME = "基"
# print(‘我要搞‘, NAME)
# qupengfei()
二、global与nonlocal
1.global关键字
能够将子程序里面的变量声明为全局变量的东西,如下示例:
# 如果函数的内部无global关键字
# - 有声明局部变量
# NAME = ["产品经理","廖波湿"]
# def qupengfei():
# NAME = "自己" #只找自己的局部变量
# print(‘我要搞‘, NAME)
# qupengfei() #打印我要搞自己
# - 无声明局部变量
# NAME = ["产品经理","廖波湿"]
# def qupengfei():
# NAME.append(‘XXOO‘) #自己没有局部变量就找全局变量
# print(‘我要搞‘, NAME)
# qupengfei() #打印我要搞["产品经理","廖波湿"]
# 如果函数的内容有global关键字
# - 有声明局部变量
# NAME = ["产品经理","廖波湿"]
# def qupengfei():
# global NAME
# NAME = "自己" # 跟“无声明同名的局部变量”一样的
# print(‘我要搞‘, NAME)
# qupengfei() #打印我要搞自己
- # 错误示例
# NAME = ["产品经理","廖波湿"]
# def qupengfei():
# NAME = "自己"
# global NAME
# print(‘我要搞‘, NAME)#报错,global是一定要紧贴在函数def的下面
# qupengfei()
# - 无声明同名的局部变量
# NAME = ["产品经理","廖波湿"]
# def qupengfei():
# global NAME
# NAME = ["阿毛"] #OK的
# NAME.append(‘XXOO‘)
# print(‘我要搞‘, NAME)
# qupengfei() #打印我要搞["阿毛"],列表中的元素为["阿毛",‘XXOO‘]
# 总结
# 如果函数的内部无global关键字,优先读取局部变量,没有局部变量则读取全局变量,无法对全局重新赋值(NAME=“fff”),但是对于可变类型(list、字典等),可以对内部元素进行操作.
# 如果函数中有global关键字,变量本质上就是全局的那个变量,可读取可重新赋值 NAME=“fff”
# 规范:全局变量变量名大写,局部变量小写
#在定义局部变量的子程序内,局部变量起作用,在其他地方,全局变量起作用
2.nonlocal关键字
指定上一级变量,如果没有就继续往上直到找到为止,如下示例:
name = "刚娘"
def weihou():
name = "陈卓"
def weiweihou():
global name # 指的是全局变量
name = "冷静" # 所以修改的是全局变量
weiweihou()
print(name)
print(name)
weihou()
print(name)# 刚娘--->陈卓--->冷静
name = "刚娘"
def weihou():
name = "陈卓"
def weiweihou():
nonlocal name # nonlocal,指定上一级变量,如果没有就继续往上直到找到为止
name = "冷静"
weiweihou()
print(name)
print(name)
weihou()
print(name) # 刚娘--->冷静----> 刚娘
三、嵌套函数
1.定义
一个函数体内包含一个或多个函数体
2.嵌套函数的执行过程
#1.name=‘yyq‘
#2.def huangwei():
# 4.1.name = "zyh"
# 4.2.print(name)
# 4.3.def liuyang():
# 4.4.1.name = "yjj"
# 4.4.2.print(name)
# 4.4.3.def nulige():
# 4.4.5.1.name = ‘zjq‘
# 4.4.5.2.print(name)
# 4.4.4.print(name)
# 4.4.5.nulige()
# 4.4.liuyang()
# 4.5.print(name)
#3.print(name)
#4.huangwei()
#5.print(name)
四、函数即变量
先看几个例子:
# def foo():
# print(‘from foo‘)
# bar()
# foo() #报错,bar()没有定义
# def bar():
# print(‘from bar‘)
# def foo():
# print(‘from foo‘)
# bar()
# foo() #执行通过
# def foo():
# print(‘from foo‘)
# bar()
# def bar():
# print(‘from bar‘)
# foo() #执行通过
# def foo():
# print(‘from foo‘)
# bar()
# foo() # 报错,找不到bar()
# def bar():
# print(‘from bar‘)
总结:在计算机中,函数体会被当做一长串字符串存到内存中,得到一个内存地址,而函数名就相当于一个变量名(门牌号),函数名加括号就是在调用函数的内存地址。
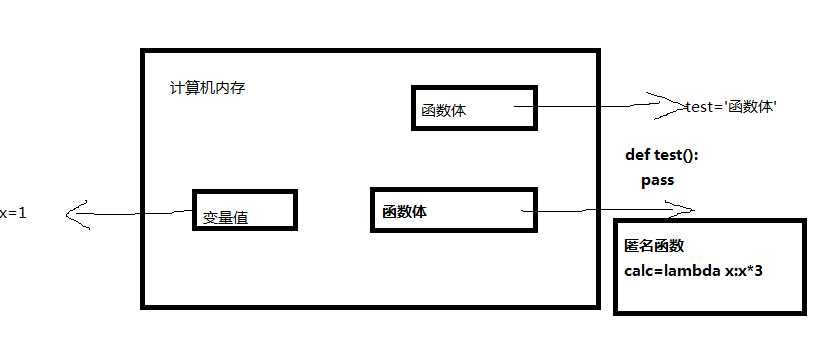
五、递归
1.定义
一个函数调用自己就叫做递归,最大的递归次数是999次,例子如下:
# def calc(n):
# print(n)
# if int(n / 2) == 0:
# return n
# res=calc(int(n / 2))
# return res
#
# res=calc(10) #每一层都print一个数字
# print(res) #返回最后的结果1
2.递归的特性
必须有一个明确的结束条件(所以需要return);每进入更深一层递归,问题规模都比上一层有所减少;递归效率不高(递归写不好,很容易内存溢出)
再举一个问路的例子:
# import time
# person_list=[‘yyq‘,‘zyh‘,‘ljy‘,‘zsc‘]
# def ask_way(person_list):
# print(‘-‘*60)
# if len(person_list) == 0:
# return ‘根本没人知道‘
# person=person_list.pop(0)#使得列表中的人不断减少(问题规模减少),放在len(person_list)后面是为了以防一开始传进来的是空列表导致报错
# if person == ‘linhaifeng‘:
# return ‘%s说:我知道,南基就在高塘路‘ %person
#
# print(‘hi 美男[%s],敢问路在何方‘ % person)
# print(‘%s回答道:我不知道,但念你慧眼识猪,你等着,我帮你问问%s...‘ % (person, person_list))
# time.sleep(10)
# res=ask_way(person_list)#第一个人不知道,所以他去问另外一个人,如此类推下去,知道问到结果,然后一层层返回
#
# print(‘%s问的结果是: %res‘ %(person,res))
# return res
#
# res=ask_way(person_list) #把函数的返回值暂时保存,用于下一句打印出来
# print(res)