系统稳定性与哪些因素
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统稳定性与哪些因素相关的知识,希望对你有一定的参考价值。
参考技术A系统稳定性与哪些因素有关
系统稳定性与哪些因素有关,稳定性是指“测量仪器保持其计量特性随时间恒定的能力。通常稳定性是指测量仪器的计量特性随时间不变化的能力。以下分享系统稳定性与哪些因素有关。
系统稳定性与哪些因素1
夜幕降临
方法异常线上报警,定位日志,空指针异常,查询数据库结果为空,定位此业务线查询从库,数据库正常,查询结果正常,初步确定是主从延迟。问题在几秒钟恢复,影响次数个位数,接下来几个月数次出现此问题,直到双11备战第一天延迟更加严重了。
长夜慢慢
定位主从同步延迟问题了,查看从库的机器情况及慢日志。从库执行大量的删除某表记录操作,性能非常差。在看其执行语句,发现没有索引,在看下主库这张表上有这个索引。这种情况下为什么出现主从延迟高呢?在这里简单介绍下mysql主从同步原理。
mysql主从复制需要三个线程,masterbinlog dump thread、、slaveI/O thread 、SQL thread、。
master
1、 binlog dump线程: 当主库中有数据更新时,那么主库就会根据按照设置的binlog格式,将此次更新的事件类型写入到主库的binlog文件中,此时主库会创建log dump线程通知slave有数据更新,当I/O线程请求日志内容时,会将此时的binlog名称和当前更新的位置同时传给slave的I/O线程。
slave
2、I/O线程 :该线程会连接到master,向log dump线程请求一份指定binlog文件位置的副本,并将请求回来的binlog存到本地的relay log中,relay log和binlog日志一样也是记录了数据更新的事件,它也是按照递增后缀名的方式,产生多个relay log hostname-relay-bin.000001、文件,slave会使用一个index文件 hostname-relay-bin.index、来追踪当前正在使用的relay log文件。
3、SQL线程 :该线程检测到relay log有更新后,会读取并在本地做redo操作,将发生在主库的事件在本地重新执行一遍,来保证主从数据同步。此外,如果一个relay log文件中的全部事件都执行完毕,那么SQL线程会自动将该relay log 文件删除掉。
下面是整个复制过程的原理图:
结合以上的mysql主从同步原理,我们线上这次问题原因已经出来了,其实慢SQL只是我们原因的表象,更加深层次的原因是从库 SQL thread顺序执行Relay log的事件。执行任意事件性能不好的话都会给我们在来主从的高延迟。
黎明曙光
从库建立索引,降低主从延迟性,对线上业务影响无感知。
我们系统架构情况如下:
为了减少数据库主库的压力,每条业务线都有自己从库,目前我们数据库的情况是1主8从。如果说主从延迟非常高的话最明显的影响就是我们每条业务线的读延迟,依赖读的业务都会有问题。
主从延迟是影响我们系统稳定性的因素之一。如何降低主从延迟减少其对我们系统的影响?业界内减少主从延迟方案有多种下面简单介绍几种:
服务的基础架构在业务和mysql之间加入memcache或者Redis的cache层。降低mysql的读压力;
使用比主库更好的硬件设备作为slave;
sync_binlog在slave端设置为0;
–logs-slave-updates 从服务器从主服务器接收到的更新不记入它的二进制日志;
禁用slave的binlog。
系统稳定性与哪些因素2
系统的稳定性以及稳定性的几种定义
一、系统 研究系统的稳定性之前,
我们首先要对系统的概念有初步的认识。在数字信号处理的理论中,人们把能加工、变换数字信号的实体称作系统。由于处理数字信号的系统是在指定时刻或时序对信号进行加工运算所以这种系统被看作是离散时间的\',也可以用基于时间的语言、表格、公式、波形等四种方法来描述。从抽象的意义来说,系统和信号都可以看作是
序列。但是,系统是加工信号的机构,这点与信号是不同的。人们研究系统还要设计系统,利用系统加工信号、
服务人类,系统还需要其它方法进一步描述。描述系统的方法还有符号、单位脉冲响应、差分方程和图形。中国学者钱学森认为:
系统是由相互作用相互依赖的若干组成部分结合而成的,具有特定功能的有机整体,而且这个有机整体又是它从属的更大系统的组成部分。
二、系统的稳定性
一个系统,若对任意的有界输入,其零状态响应也是有界的,则称该系统是有界输 有界输出(Bound Input Bound Output------ BIBO)稳定的系统,简称为稳定系统。即,若系统对所有的激励|f·)|≤Mf,其零状态响应|yzs(·)|≤My(M为有限常数),则称该系统稳定。
三、连续(时间)
系统与离散(时间)系统 连续系统:时间和各个组成部分的变量都具有连续变化形式的系统。系统的激励和响应均为连续信号。离散系统。当系统 各物理量随时间变化的规律不能用连续函描述时,而只在离散的瞬间给出数值,这种系统称为离散系统 。系统的激励和响应均为离散信号。
四、因果系统
因果系统 (causal system)是指当且仅当输入信号激励系统时,才会出现输出(响应)的系统。也就是说,因果系统的(响应)不会出现在输入信号激励系统的以前时刻。即输入的响应不可能在此输入到达的时刻之前出现的系统;也就是说系统的输出仅与当前与过去的输入有关,而与将来的输入无关的系统。
系统稳定性与哪些因素3
什么叫做稳定性
稳定性是指“测量仪器保持其计量特性随时间恒定的能力。通常稳定性是指测量仪器的计量特性随时间不变化的能力。若稳定性不是对时间而言,而是对其他量而言,则应该明确说明。稳定性可以进行定量的表征,主要是确定计量特性随时间变化的关系。自动控制系统的种类很多,完成的功能也千差万别,有的用来控制温度的变化,有的却要跟踪飞机的飞行轨迹。但是所有系统都有一个共同的特点才能够正常地工作,也就是要满足稳定性的要求。
仪器测量
通常可以用以下两种方式:用计量特性变化某个规定的量所需经过的时间,或用计量特性经过规定的时间所发生的变化量来进行定量表示。例如:对于标准电池,对其长期稳定性(电动势的年变化幅度)和短期稳定性(3~5天内电动势变化幅度)均有明确的要求;如量块尺寸的稳定性,以其规定的长度每年允许的最大变化量(微米年)来进行考核,上述稳定性指标均是划分准确度等级的重要依据。
对于测量仪器,尤其是基准、测量标准或某些实物量具,稳定性是重要的计量性能之一,示值的稳定是保证量值准确的基础。测量仪器产生不稳定的因素很多,主要原因是元器件的老化、零部件的磨损、以及使用、贮存、维护工作不仔细等所致。测量仪器进行的周期检定或校准,就是对其稳定性的一种考核。稳定性也是科学合理地确定检定周期的重要依据之一。 [1]
示例
什么叫稳定性呢?我们可以通过一个简单的例子来理解稳定性的概念。一个钢球分别放在不同的两个木块上,A图放在木块的顶部,B图放在木块的底部。如果对钢球施加一个力,使钢球离开原来的位置。A图的钢球就会向下滑落,不会再回到原来的位置。而B图的钢球由于地球引力的作用,会在木块的底部做来回的滚动运动,当时间足够长时,小球最终还是要回到原来的位置。我们说A图的情况就是不稳定的,而B图的情况就是稳定的。
上面给出的是一个简单的物理系统,通过它我们对于稳定性有了一个基本的认识。稳定性可以这样定义:当一个实际的系统处于一个平衡的状态时就相当于小球在木块上放置的状态一样、如果受到外来作用的影响时相当于上例中对小球施加的力、,系统经过一个过渡过程仍然能够回到原来的平衡状态,我们称这个系统就是稳定的,否则称系统不稳定。一个控制系统要想能够实现所要求的控制功能就必须是稳定的。在实际的应用系统中,由于系统中存在储能元件,并且每个元件都存在惯性。这样当给定系统的输入时,输出量一般会在期望的输出量之间摆动。此时系统会从外界吸收能量。对于稳定的系统振荡是减幅的,而对于不稳定的系统,振荡是增幅的振荡。前者会平衡于一个状态,后者却会不断增大直到系统被损坏。
判别
既然稳定性很重要,那么怎么才能知道系统是否稳定呢?控制学家们给我们提出了很多系统稳定与否的判定定理。这些定理都是基于系统的数学模型,根据数学模型的形式,经过一定的计算就能够得出稳定与否的结论,这些定理中比较有名的有:劳斯判据、赫尔维茨判据、李亚谱若夫三个定理。这些稳定性的判别方法分别适合于不同的数学模型,前两者主要是通过判断系统的特征值是否小于零来判定系统是否稳定,后者主要是通过考察系统能量是否衰减来判定稳定性。
当然系统的稳定性只是对系统的一个基本要求,一个令人满意的控制系统必须还要满足许多别的指标,例如过渡时间、超调量、稳态误差、调节时间等。一个好的系统往往是这些方面的综合考虑的结果。
哪些因素影响了数据库性能
网络宽带,磁盘IO,查询速度都会影响到数据库的性能。
具体问题具体分析,举例来说明为什么磁盘IO成瓶颈数据库的性能急速下降了。
为什么当磁盘IO成瓶颈之后, 数据库的性能不是达到饱和的平衡状态,而是急剧下降。为什么数据库的性能有非常明显的分界点,原因是什么?
相信大部分做数据库运维的朋友,都遇到这种情况。 数据库在前一天性能表现的相当稳定,数据库的响应时间也很正常,但就在今天,在业务人员反馈业务流量没有任何上升的情况下,数据库的变得不稳定了,有时候一个最简单的insert操作, 需要几十秒,但99%的insert却又可以在几毫秒完成,这又是为什么了?
dba此时心中有无限的疑惑,到底是什么原因呢? 磁盘IO性能变差了?还是业务运维人员反馈的流量压根就不对? 还是数据库内部出问题?昨天不是还好好的吗?
当数据库出现响应时间不稳定的时候,我们在操作系统上会看到磁盘的利用率会比较高,如果观察仔细一点,还可以看到,存在一些读的IO. 数据库服务器如果存在大量的写IO,性能一般都是正常跟稳定的,但只要存在少量的读IO,则性能开始出现抖动,存在大量的读IO时(排除配备非常高速磁盘的机器),对于在线交易的数据库系统来说,大概性能就雪崩了。为什么操作系统上看到的磁盘读IO跟写IO所带来的性能差距这么大呢?
如果亲之前没有注意到上述的现象,亲对上述的结论也是怀疑。但请看下面的分解。
在写这个文章之前,作者阅读了大量跟的IO相关的代码,如异步IO线程的相关的,innodb_buffer池相关的,以及跟读数据块最相关的核心函数buf_page_get_gen函数以及其调用的相关子函数。为了将文章写得通俗点,看起来不那么累,因此不再一行一行的将代码解析写出来。
咱们先来提问题。 buf_page_get_gen函数的作用是从Buffer bool里面读数据页,可能存在以下几种情况。
提问. 数据页不在buffer bool 里面该怎么办?
回答:去读文件,将文件中的数据页加载到buffer pool里面。下面是函数buffer_read_page的函数,作用是将物理数据页加载到buffer pool, 图片中显示
buffer_read_page函数栈的顶层是pread64(),调用了操作系统的读函数。
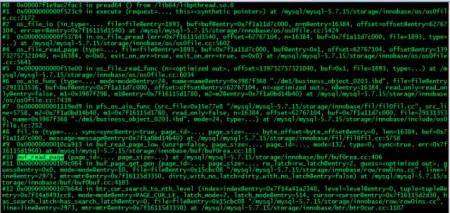
buf_read_page的代码
如果去读文件,则需要等待物理读IO的完成,如果此时IO没有及时响应,则存在堵塞。这是一个同步读的操作,如果不完成该线程无法继续后续的步骤。因为需要的数据页不再buffer 中,无法直接使用该数据页,必须等待操作系统完成IO .
再接着上面的回答提问:
当第二会话线程执行sql的时候,也需要去访问相同的数据页,它是等待上面的线程将这个数据页读入到缓存中,还是自己再发起一个读磁盘的然后加载到buffer的请求呢? 代码告诉我们,是前者,等待第一个请求该数据页的线程读入buffer pool。
试想一下,如果第一个请求该数据页的线程因为磁盘IO瓶颈,迟迟没有将物理数据页读入buffer pool, 这个时间区间拖得越长,则造成等待该数据块的用户线程就越多。对高并发的系统来说,将造成大量的等待。 等待数据页读入的函数是buf_wait_for_read,下面是该函数相关的栈。
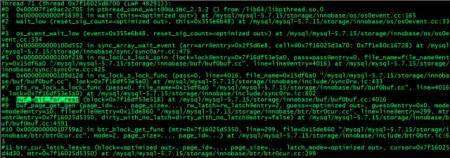
通过解析buf_wait_for_read函数的下层函数,我们知道其实通过首先自旋加锁pin的方式,超过设定的自旋次数之后,进入等待,等待IO完成被唤醒。这样节省不停自旋pin时消耗的cpu,但需要付出被唤起时的开销。
再继续扩展问题: 如果会话线程A 经过物理IO将数据页1001读入buffer之后,他需要修改这个页,而在会话线程A之后的其他的同样需要访问数据页1001的会话线程,即使在数据页1001被入读buffer pool之后,将仍然处于等待中。因为在数据页上读取或者更新的时候,同样需要上锁,这样才能保证数据页并发读取/更新的一致性。
由此可见,当一个高并发的系统,出现了热点数据页需要从磁盘上加载到buffer pool中时,造成的延迟,是难以想象的。因此排在等待热点页队列最后的会话线程最后才得到需要的页,响应时间也就越长,这就是造成了一个简单的sql需要执行几十秒的原因。
再回头来看上面的问题,mysql数据库出现性能下降时,可以看到操作系统有读IO。 原因是,在数据库对数据页的更改,是在内存中的,然后通过检查点线程进行异步写盘,这个异步的写操作是不堵塞执行sql的会话线程的。所以,即使看到操作系统上有大量的写IO,数据库的性能也是很平稳的。但当用户线程需要查找的数据页不在buffer pool中时,则会从磁盘上读取,在一个热点数据页不是非常多的情况下,我们设置足够大的innodb_buffer_pool的size, 基本可以缓存所有的数据页,因此一般都不会出现缺页的情况,也就是在操作系统上基本看不到读的IO。 当出现读的IO时,原因时在执行buf_read_page_low函数,从磁盘上读取数据页到buffer pool, 则数据库的性能则开始下降,当出现大量的读IO,数据库的性能会非常差。
参考技术A 1、1、调整数据结构的设计。这一部分在开发信息系统之前完成,程序员需要考虑是否使用ORACLE数据库的分区功能,对于经常访问的数据库表是否需要建立索引等。2、2、调整应用程序结构设计。这一部分也是在开发信息系统之前完成,程序员在这一步需要考虑应用程序使用什么样的体系结构,是使用传统的Client/Server两层体系结构,还是使用Browser/Web/Database的三层体系结构。不同的应用程序体系结构要求的数据库资源是不同的。
3、3、调整数据库SQL语句。应用程序的执行最终将归结为数据库中的SQL语句执行,因此SQL语句的执行效率最终决定了ORACLE数据库的性能。ORACLE公司推荐使用ORACLE语句优化器(Oracle
Optimizer)和行锁管理器(row-level
manager)来调整优化SQL语句。
4、4、调整服务器内存分配。内存分配是在信息系统运行过程中优化配置的,数据库管理员可以根据数据库运行状况调整数据库系统全局区(SGA区)的数据缓冲区、日志缓冲区和共享池的大小;还可以调整程序全局区(PGA区)的大小。需要注意的是,SGA区不是越大越好,SGA区过大会占用操作系统使用的内存而引起虚拟内存的页面交换,这样反而会降低系统。
5、5、调整硬盘I/O,这一步是在信息系统开发之前完成的。数据库管理员可以将组成同一个表空间的数据文件放在不同的硬盘上,做到硬盘之间I/O负载均衡。
6、6、调整操作系统参数,例如:运行在UNIX操作系统上的ORACLE数据库,可以调整UNIX数据缓冲池的大小,每个进程所能使用的内存大小等参数。
实际上,上述数据库优化措施之间是相互联系的。ORACLE数据库性能恶化表现基本上都是用户响应时间比较长,需要用户长时间的等待。但性能恶化的原因却是多种多样的,有时是多个因素共同造成了性能恶化的结果,这就需要数据库管理员有比较全面的计算机知识,能够敏感地察觉到影响数据库性能的主要原因所在。另外,良好的数据库管理工具对于优化数据库性能也是很重要的。
ORACLE数据库性能优化工具
常用的数据库性能优化工具有:
1、1、ORACLE数据库在线数据字典,ORACLE在线数据字典能够反映出ORACLE动态运行情况,对于调整数据库性能是很有帮助的。
2、2、操作系统工具,例如UNIX操作系统的vmstat,iostat等命令可以查看到系统系统级内存和硬盘I/O的使用情况,这些工具对于管理员弄清出系统瓶颈出现在什么地方有时候很有用。
3、3、SQL语言跟踪工具(SQL
TRACE
FACILITY),SQL语言跟踪工具可以记录SQL语句的执行情况,管理员可以使用虚拟表来调整实例,使用SQL语句跟踪文件调整应用程序性能。SQL语言跟踪工具将结果输出成一个操作系统的文件,管理员可以使用TKPROF工具查看这些文件。
4、4、ORACLE
Enterprise
Manager(OEM),这是一个图形的用户管理界面,用户可以使用它方便地进行数据库管理而不必记住复杂的ORACLE数据库管理的命令。
5、5、EXPLAIN
PLAN——SQL语言优化命令,使用这个命令可以帮助程序员写出高效的SQL语言。
ORACLE数据库的系统性能评估
信息系统的类型不同,需要关注的数据库参数也是不同的。数据库管理员需要根据自己的信息系统的类型着重考虑不同的数据库参数。
1、1、在线事务处理信息系统(OLTP),这种类型的信息系统一般需要有大量的Insert、Update操作,典型的系统包括民航机票发售系统、银行储蓄系统等。OLTP系统需要保证数据库的并发性、可靠性和最终用户的速度,这类系统使用的ORACLE数据库需要主要考虑下述参数:
l
l
数据库回滚段是否足够?
l
l
是否需要建立ORACLE数据库索引、聚集、散列?
l
l
系统全局区(SGA)大小是否足够?
l
l
SQL语句是否高效?
2、2、数据仓库系统(Data
Warehousing),这种信息系统的主要任务是从ORACLE的海量数据中进行查询,得到数据之间的某些规律。数据库管理员需要为这种类型的ORACLE数据库着重考虑下述参数:
l
l
是否采用B*-索引或者bitmap索引?
l
l
是否采用并行SQL查询以提高查询效率?
l
l
是否采用PL/SQL函数编写存储过程?
l
l
有必要的话,需要建立并行数据库提高数据库的查询效率
SQL语句的调整原则
SQL语言是一种灵活的语言,相同的功能可以使用不同的语句来实现,但是语句的执行效率是很不相同的。程序员可以使用EXPLAIN
PLAN语句来比较各种实现方案,并选出最优的实现方案。总得来讲,程序员写SQL语句需要满足考虑如下规则:
1、1、尽量使用索引。试比较下面两条SQL语句:
语句A:SELECT
dname,
deptno
FROM
dept
WHERE
deptno
NOT
IN
(SELECT
deptno
FROM
emp);
语句B:SELECT
dname,
deptno
FROM
dept
WHERE
NOT
EXISTS
(SELECT
deptno
FROM
emp
WHERE
dept.deptno
=
emp.deptno);
这两条查询语句实现的结果是相同的,但是执行语句A的时候,ORACLE会对整个emp表进行扫描,没有使用建立在emp表上的deptno索引,执行语句B的时候,由于在子查询中使用了联合查询,ORACLE只是对emp表进行的部分数据扫描,并利用了deptno列的索引,所以语句B的效率要比语句A的效率高一些。
2、2、选择联合查询的联合次序。考虑下面的例子:
SELECT
stuff
FROM
taba
a,
tabb
b,
tabc
c
WHERE
a.acol
between
:alow
and
:ahigh
AND
b.bcol
between
:blow
and
:bhigh
AND
c.ccol
between
:clow
and
:chigh
AND
a.key1
=
b.key1
AMD
a.key2
=
c.key2;
这个SQL例子中,程序员首先需要选择要查询的主表,因为主表要进行整个表数据的扫描,所以主表应该数据量最小,所以例子中表A的acol列的范围应该比表B和表C相应列的范围小。
3、3、在子查询中慎重使用IN或者NOT
IN语句,使用where
(NOT)
exists的效果要好的多。
4、4、慎重使用视图的联合查询,尤其是比较复杂的视图之间的联合查询。一般对视图的查询最好都分解为对数据表的直接查询效果要好一些。
5、5、可以在参数文件中设置SHARED_POOL_RESERVED_SIZE参数,这个参数在SGA共享池中保留一个连续的内存空间,连续的内存空间有益于存放大的SQL程序包。
6、6、ORACLE公司提供的DBMS_SHARED_POOL程序可以帮助程序员将某些经常使用的存储过程“钉”在SQL区中而不被换出内存,程序员对于经常使用并且占用内存很多的存储过程“钉”到内存中有利于提高最终用户的响应时间。
CPU参数的调整
CPU是服务器的一项重要资源,服务器良好的工作状态是在工作高峰时CPU的使用率在90%以上。如果空闲时间CPU使用率就在90%以上,说明服务器缺乏CPU资源,如果工作高峰时CPU使用率仍然很低,说明服务器CPU资源还比较富余。
使用操作相同命令可以看到CPU的使用情况,一般UNIX操作系统的服务器,可以使用sar
–u命令查看CPU的使用率,NT操作系统的服务器,可以使用NT的性能管理器来查看CPU的使用率。
数据库管理员可以通过查看v$sysstat数据字典中“CPU
used
by
this
session”统计项得知ORACLE数据库使用的CPU时间,查看“OS
User
level
CPU
time”统计项得知操作系统用户态下的CPU时间,查看“OS
System
call
CPU
time”统计项得知操作系统系统态下的CPU时间,操作系统总的CPU时间就是用户态和系统态时间之和,如果ORACLE数据库使用的CPU时间占操作系统总的CPU时间90%以上,说明服务器CPU基本上被ORACLE数据库使用着,这是合理,反之,说明服务器CPU被其它程序占用过多,ORACLE数据库无法得到更多的CPU时间。
数据库管理员还可以通过查看v$sesstat数据字典来获得当前连接ORACLE数据库各个会话占用的CPU时间,从而得知什么会话耗用服务器CPU比较多。
出现CPU资源不足的情况是很多的:SQL语句的重解析、低效率的SQL语句、锁冲突都会引起CPU资源不足。
1、数据库管理员可以执行下述语句来查看SQL语句的解析情况:
SELECT
*
FROM
V$SYSSTAT
WHERE
NAME
IN
('parse
time
cpu',
'parse
time
elapsed',
'parse
count
(hard)');
这里parse
time
cpu是系统服务时间,parse
time
elapsed是响应时间,用户等待时间
waite
time
=
parse
time
elapsed
–
parse
time
cpu
由此可以得到用户SQL语句平均解析等待时间=waite
time
/
parse
count。这个平均等待时间应该接近于0,如果平均解析等待时间过长,数据库管理员可以通过下述语句
SELECT
SQL_TEXT,
PARSE_CALLS,
EXECUTIONS
FROM
V$SQLAREA
ORDER
BY
PARSE_CALLS;
来发现是什么SQL语句解析效率比较低。程序员可以优化这些语句,或者增加ORACLE参数SESSION_CACHED_CURSORS的值。
2、数据库管理员还可以通过下述语句:
SELECT
BUFFER_GETS,
EXECUTIONS,
SQL_TEXT
FROM
V$SQLAREA;
查看低效率的SQL语句,优化这些语句也有助于提高CPU的利用率。
3、3、数据库管理员可以通过v$system_event数据字典中的“latch
free”统计项查看ORACLE数据库的冲突情况,如果没有冲突的话,latch
free查询出来没有结果。如果冲突太大的话,数据库管理员可以降低spin_count参数值,来消除高的CPU使用率。
内存参数的调整
内存参数的调整主要是指ORACLE数据库的系统全局区(SGA)的调整。SGA主要由三部分构成:共享池、数据缓冲区、日志缓冲区。
1、
1、
共享池由两部分构成:共享SQL区和数据字典缓冲区,共享SQL区是存放用户SQL命令的区域,数据字典缓冲区存放数据库运行的动态信息。数据库管理员通过执行下述语句:
select
(sum(pins
-
reloads))
/
sum(pins)
"Lib
Cache"
from
v$librarycache;
来查看共享SQL区的使用率。这个使用率应该在90%以上,否则需要增加共享池的大小。数据库管理员还可以执行下述语句:
select
(sum(gets
-
getmisses
-
usage
-
fixed))
/
sum(gets)
"Row
Cache"
from
v$rowcache;
查看数据字典缓冲区的使用率,这个使用率也应该在90%以上,否则需要增加共享池的大小。
2、
2、
数据缓冲区。数据库管理员可以通过下述语句:
SELECT
name,
value
FROM
v$sysstat
WHERE
name
IN
('db
block
gets',
'consistent
gets','physical
reads');
来查看数据库数据缓冲区的使用情况。查询出来的结果可以计算出来数据缓冲区的使用命中率=1
-
(
physical
reads
/
(db
block
gets
+
consistent
gets)
)。
这个命中率应该在90%以上,否则需要增加数据缓冲区的大小。
3、
3、
日志缓冲区。数据库管理员可以通过执行下述语句:
select
name,value
from
v$sysstat
where
name
in
('redo
entries','redo
log
space
requests');查看日志缓冲区的使用情况。查询出的结果可以计算出日志缓冲区的申请失败率:
申请失败率=requests/entries,申请失败率应该接近于0,否则说明日志缓冲区开设太小,需要增加ORACLE数据库的日志缓冲区。 参考技术B 以MySQL为例:
影响数据库性能的主要因素总结如下:
1、sql查询速度
2、网卡流量
3、服务器硬件
4、磁盘IO
以上因素并不是时时刻刻都会影响数据库性能,而就像木桶效应一样。如果其中一个因素严重影响性能,那么整个数据库性能就会严重受阻。另外,这些影响因素都是相对的。
例如:当数据量并没有达到百万千万这样的级别,那么sql查询速度也许就不是个重要因素,换句话说,你的sql语句效率适当低下可能并不影响整个效率多少,反之,这种情况,无论如何怎么优化sql语句,可能都没有太明显的效果。
以上是关于系统稳定性与哪些因素的主要内容,如果未能解决你的问题,请参考以下文章