Selenium(Python)页面对象+数据驱动测试框架
Posted 此生不换Yang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Selenium(Python)页面对象+数据驱动测试框架相关的知识,希望对你有一定的参考价值。
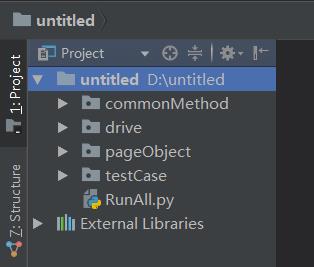
整个工程的目录结构:

常用方法类:
class SeleniumMethod(object):
# 封装Selenium常用方法
def __init__(self, driver):
self.driver = driver
def getTitle(self):
# 获取页面标题
return self.driver.title
def clearAndInput(self, location, value):
# 根据xpath定位元素并清除、输入
element = self.driver.find_element_by_xpath(location)
element.clear()
element.send_keys(value)
def click(self, location):
# 根据xpath定位元素并点击
return self.driver.find_element_by_xpath(location).click()
def getText(self, location):
# 根据xpath定位元素并获取文本值
return self.driver.find_element_by_xpath(location).text
页面对象类:
from commonMethod.WebDriverMethod import SeleniumMethod
class BaiduPage(SeleniumMethod):
# 百度页面对象
inputBox = ".//*[@id=\'kw\']"
# 百度输入框
searchBotton = ".//*[@id=\'su\']"
# 百度搜索按钮
oneResult = ".//*[@id=\'1\']/h3/a"
# 搜索结果第一行
def searchChinese(self, keyword):
# 搜索关键字
self.clearAndInput(self.inputBox, keyword)
self.click(self.searchBotton)
测试用例类:
import csv
import unittest
from time import sleep
from ddt import ddt, data, unpack
from selenium import webdriver
from pageObject.BaiduHome import BaiduPage
def getCsvData():
value_rows = []
dataPath = "testCase/testDirectory/testData/CsvTestData.csv"
with open(dataPath, encoding="UTF-8") as f:
f_csv = csv.reader(f)
next(f_csv)
for r in f_csv:
value_rows.append(r)
return value_rows
@ddt
class MyTestCase(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox(executable_path="drive/geckodriver.exe")
self.driver.maximize_window()
self.driver.get("https://www.baidu.com/")
assert self.driver.title, "百度一下,你就知道"
sleep(2)
@data(*getCsvData())
@unpack
def test_searchChinese(self, searchTerm, answerTitle, answerResult):
"""百度搜索的测试用例"""
homePage = BaiduPage(self.driver)
homePage.searchChinese(searchTerm)
sleep(3)
assert homePage.getTitle(), answerTitle
assert homePage.getText(homePage.oneResult), answerResult
def tearDown(self):
self.driver.close()
self.driver.quit()
if __name__ == \'__main__\':
unittest.main()
测试执行类:
import HTMLTestRunner
from time import strftime, localtime, time
from unittest import defaultTestLoader
if __name__ == "__main__":
testProject = "testCase"
organize = defaultTestLoader.discover(testProject, pattern="*Test.py")
now = strftime("%Y-%m-%M-%H_%M_%S", localtime(time()))
filename = "testCase/testDirectory/report/" + now + ".html"
fp = open(filename, "wb")
runner = HTMLTestRunner.HTMLTestRunner(
stream=fp,
verbosity=2,
title="测试报告的标题",
description="测试用例执行的情况")
runner.run(organize)
fp.close()
测试数据:
搜索关键词,搜索结果标题,搜索结果第一行
中国,中国_百度搜索,中国_百度百科
美国,美国_百度搜索,美国_百度百科
英国,英国_百度搜索,英国_百度百科
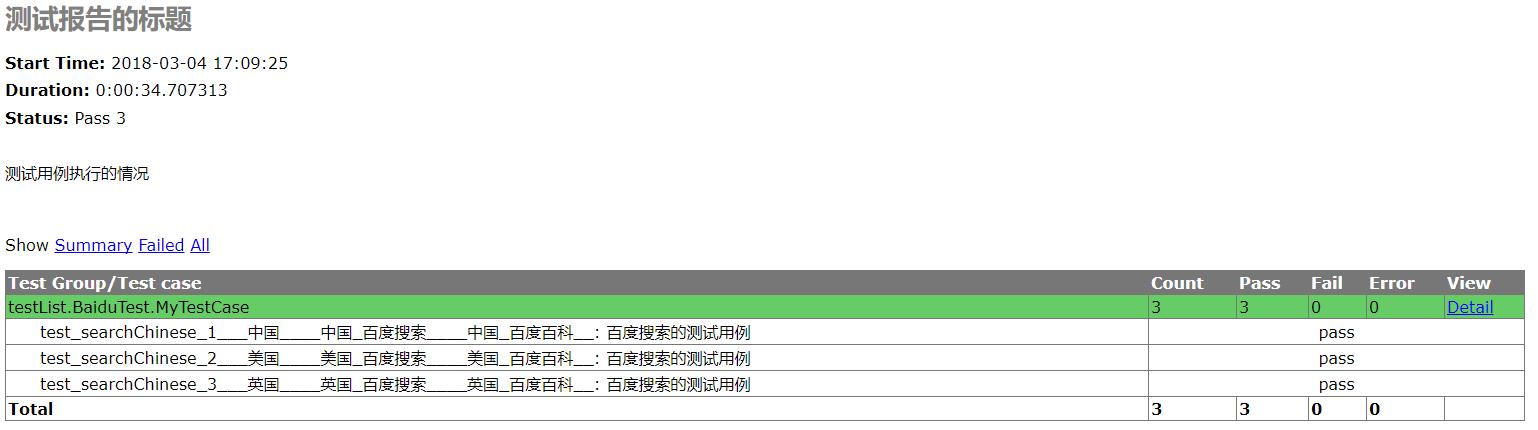
测试报告:
以上是关于Selenium(Python)页面对象+数据驱动测试框架的主要内容,如果未能解决你的问题,请参考以下文章