ansible中过滤器的介绍以及如何自定义过滤器
Posted dogfei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ansible中过滤器的介绍以及如何自定义过滤器相关的知识,希望对你有一定的参考价值。
- 一、过滤器介绍
- 二、常用过滤器介绍
- 2.1 类型转换
- 2.2 数学运算
- 2.3 字典转换为列表
- 2.4 将字典中的所有key生成一个list
- 2.5 总结
- 三、自定义过滤器
- 四、总结
之前介绍了关于如何通过shell, python, golang等语言实现自定义模块,可以参考这篇文章:
今天主要是介绍下如何实现自定义过滤器来应对各种各样的场景。
一、过滤器介绍
在ansible中由于使用了模板引擎jinja2,因此可以在使用jinja2语法的时候可以使用jinja2自带的一些过滤器工具,以及ansible自带的一些过滤器来处理数据,举一个简单的例子:
# 设置一个变量
- name: Set vars
set_fact:
name: tom
# 使用过滤器来处理上面的变量
- name: Upper vars
set_fact:
name: " name | upper "
# 打印结果
- name: Debug result
debug:
msg: " name "
# 结果应为:TOM以上就是使用过滤器来修改数据的一个小示例,通过此例其实能很方便的帮我们去处理数据,例如下面这个示例,当我们想去获取主机的磁盘挂载信息(通过ansible_mounts变量获取),然后想获取到挂载目录的大小最大的那个挂载点,这个示例在日常的运维中也许是一个很常见的需求,下面是实现方式:
首先ansible内置了一个变量用来获取主机的挂载信息,我们可以执行一下,来看下输出的挂载信息是什么样的?
# ansible localhost -m setup -a "filter=ansible_mounts"
localhost | SUCCESS =>
"ansible_facts":
"ansible_mounts": [
"block_available": 224897220,
"block_size": 4096,
"block_total": 262016000,
"block_used": 37118780,
"device": "/dev/vdb",
"fstype": "xfs",
"inode_available": 520245464,
"inode_total": 524288000,
"inode_used": 4042536,
"mount": "/data",
"options": "rw,seclabel,relatime,attr2,inode64,noquota",
"size_available": 921179013120,
"size_total": 1073217536000,
"uuid": "e2f217b1-e17b-4e90-8a34-015c8585a809"
,
"block_available": 85589,
"block_size": 4096,
"block_total": 127145,
"block_used": 41556,
"device": "/dev/vda1",
"fstype": "xfs",
"inode_available": 255667,
"inode_total": 256000,
"inode_used": 333,
"mount": "/boot",
"options": "rw,seclabel,relatime,attr2,inode64,noquota",
"size_available": 350572544,
"size_total": 520785920,
"uuid": "5c98020e-1b57-4f08-9bd6-e3af97f097ce"
,
"block_available": 2715012,
"block_size": 4096,
"block_total": 10480385,
"block_used": 7765373,
"device": "/dev/vda3",
"fstype": "xfs",
"inode_available": 20361285,
"inode_total": 20971008,
"inode_used": 609723,
"mount": "/",
"options": "rw,seclabel,relatime,attr2,inode64,noquota",
"size_available": 11120689152,
"size_total": 42927656960,
"uuid": "9f8f7093-b959-42dc-aa85-28219a02fac0"
]
,
"changed": false
可以看到ansible_mounts这个变量的数据类型是一个列表,列表中的元素是一个字典,每一个字典下主要包含:磁盘挂载点、磁盘大小、磁盘可用大小、磁盘分区类型、磁盘设备名称、以及块大小、inode信息等。对于这个示例,我们只需要关注磁盘挂载点、以及磁盘大小即可。
但是ansible_mounts获取的结果是一个列表,而我们只想获取挂载点的目录大小最大的那个挂载点,那我们该如何实现呢?是不是需要先对ansible_mounts进行排序(按照磁盘大小排序),然后对排序后的结果进行取值即可。在python中对列表中的元素为字典中的值进行排序时可以使用sorted结合lambda,在ansible中可以直接使用sort过滤器实现
# cat demo.yaml
- hosts: localhost
tasks:
- name: 对ansible_mounts进行排序
debug:
msg: " ansible_mounts | sort(attribute=\'size_total\') "看一下运行结果
# ansible-playbook demo.yaml 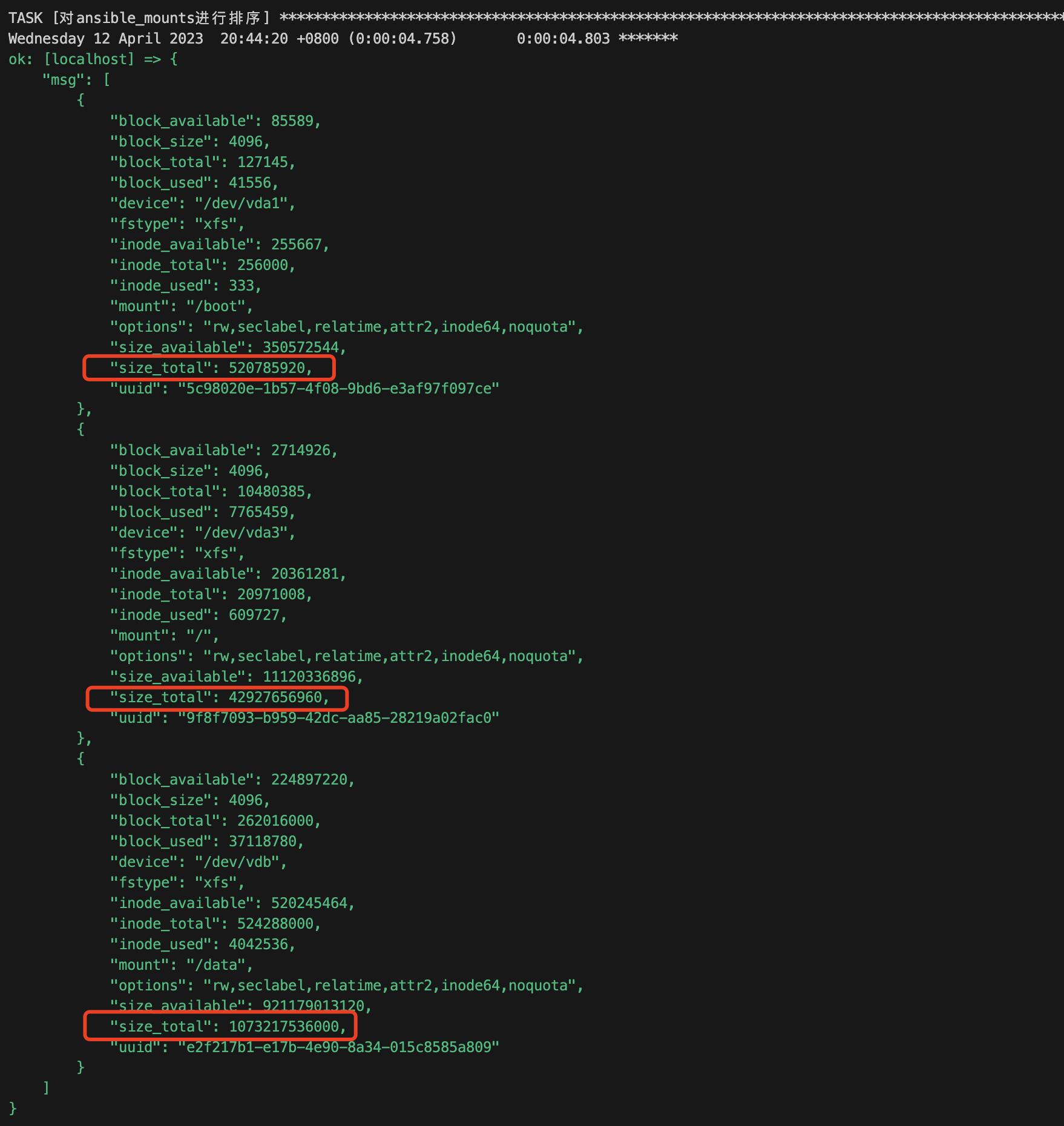
接下来我们来获取这个挂载点,通过使用last过滤器对排序后的数据获取最后一个元素的值
# cat demo.yaml
- hosts: localhost
tasks:
- name: 对ansible_mounts进行排序
debug:
msg: " ansible_mounts | sort(attribute=\'size_total\') "
- name: 对ansible_mounts进行排序,然后再获取最大的挂载点
debug:
msg: " ansible_mounts | sort(attribute=\'size_total\') | last "运行结果
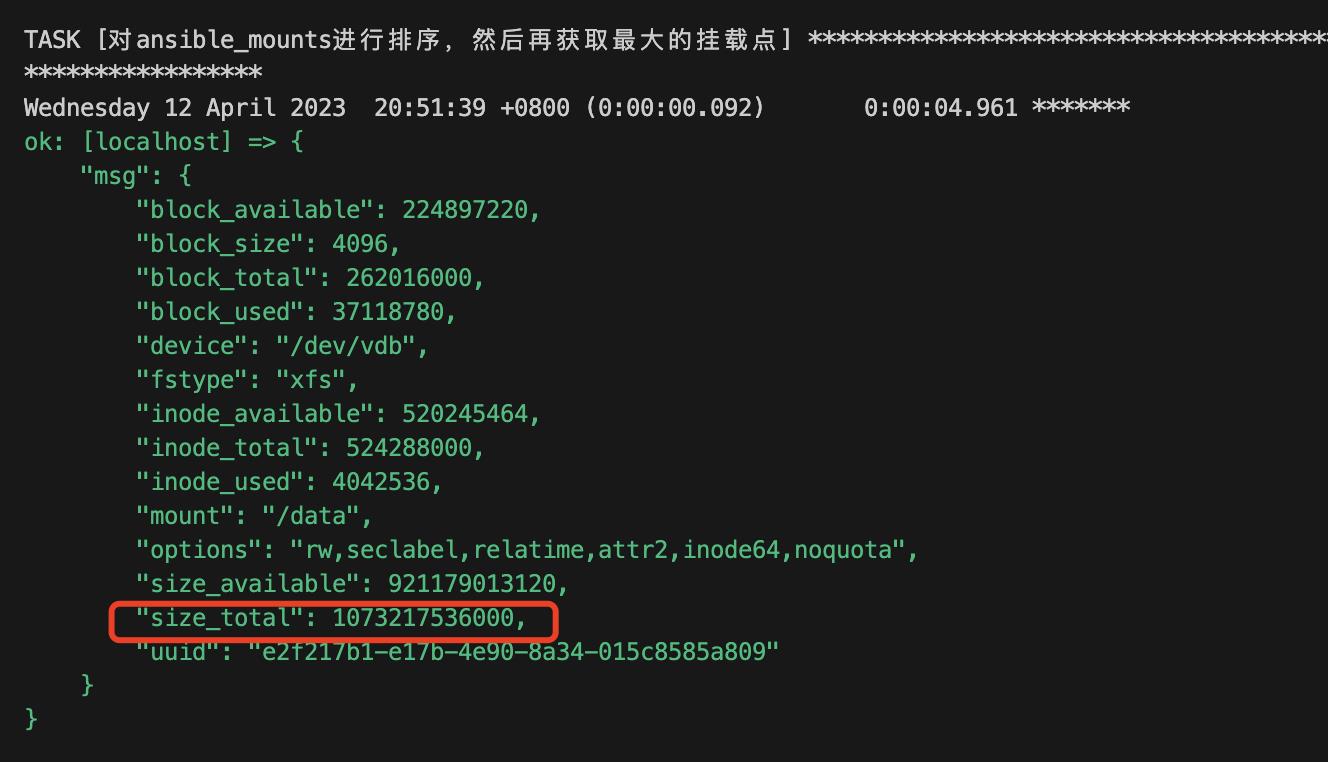
接下来我们可以把这个赋值给一个新的变量,然后来获取挂载点名称
# cat demo.yaml
- hosts: localhost
tasks:
- name: 对ansible_mounts进行排序,然后再获取最大的挂载点,最后赋值给新的变量
set_fact:
get_max_mount: " ansible_mounts | sort(attribute=\'size_total\') | last "
- name: 获取最大的挂载点
debug:
msg: " get_max_mount.mount "运行此playbook,获取结果如下:
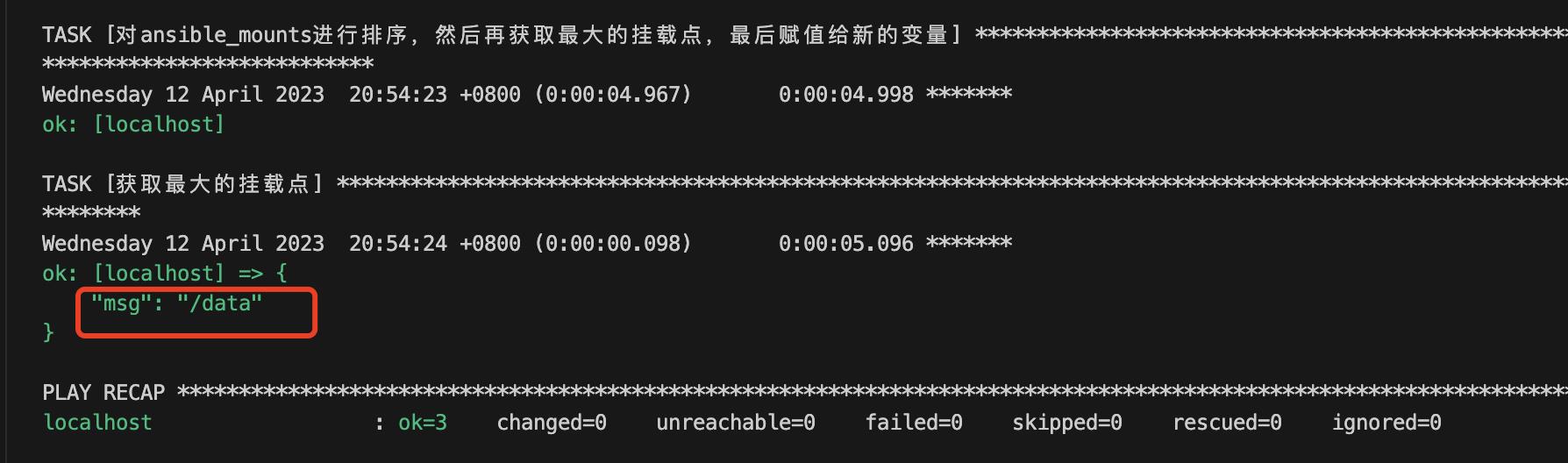
以上示例使用了sort, last两个过滤器终于获取到了我们想要的数据,可以看出ansible的过滤器让我们对数据的处理更加的得心应手。
二、常用过滤器介绍
上面的几个示例如果你很有耐心的看完,或跟着实验了一遍,你应该就会对ansible的过滤器有了一个清晰的认识,但ansible和jinja2提供的过滤器太多了,接下来我会介绍几个常用的
2.1 类型转换
顾名思义,就是要将数据类型进行转换,例如
# cat demo.yaml
- hosts: localhost
vars:
age: "18"
json_str: \'"name": "tom", "age": 18\'
tasks:
- name: 将字符串类型转换层整型
debug:
msg: " age | int "
- name: 将json字符串转为json对象
debug:
msg: " json_str | from_json "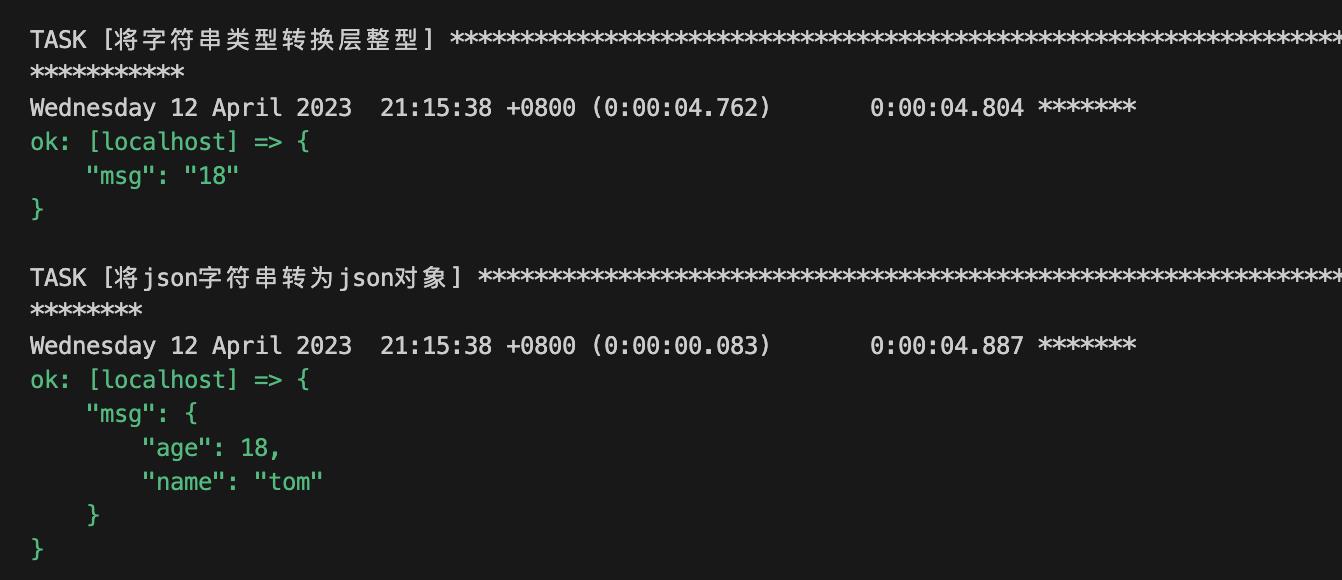
与之类似的,还有以下一些:
- bool:将变量转换为布尔值。
- int:将变量转换为整数。
- float:将变量转换为浮点数。
- string:将变量转换为字符串。
- json_query:将 JSON 字符串转换为 JSON 对象。
- from_json:将 JSON 字符串转换为 JSON 对象。
- to_json:将 JSON 对象转换为 JSON 字符串。
- yaml:将变量转换为 YAML 字符串。
2.2 数学运算
这个我个人用的不是很多,可以参考下
# cat demo.yaml
- hosts: localhost
tasks:
- name: 取对数
debug:
msg: " 8 | log "
- name: 幂运算
debug:
msg: " 8 | pow(5) "
- name: 求根
debug:
msg: " 8 | root "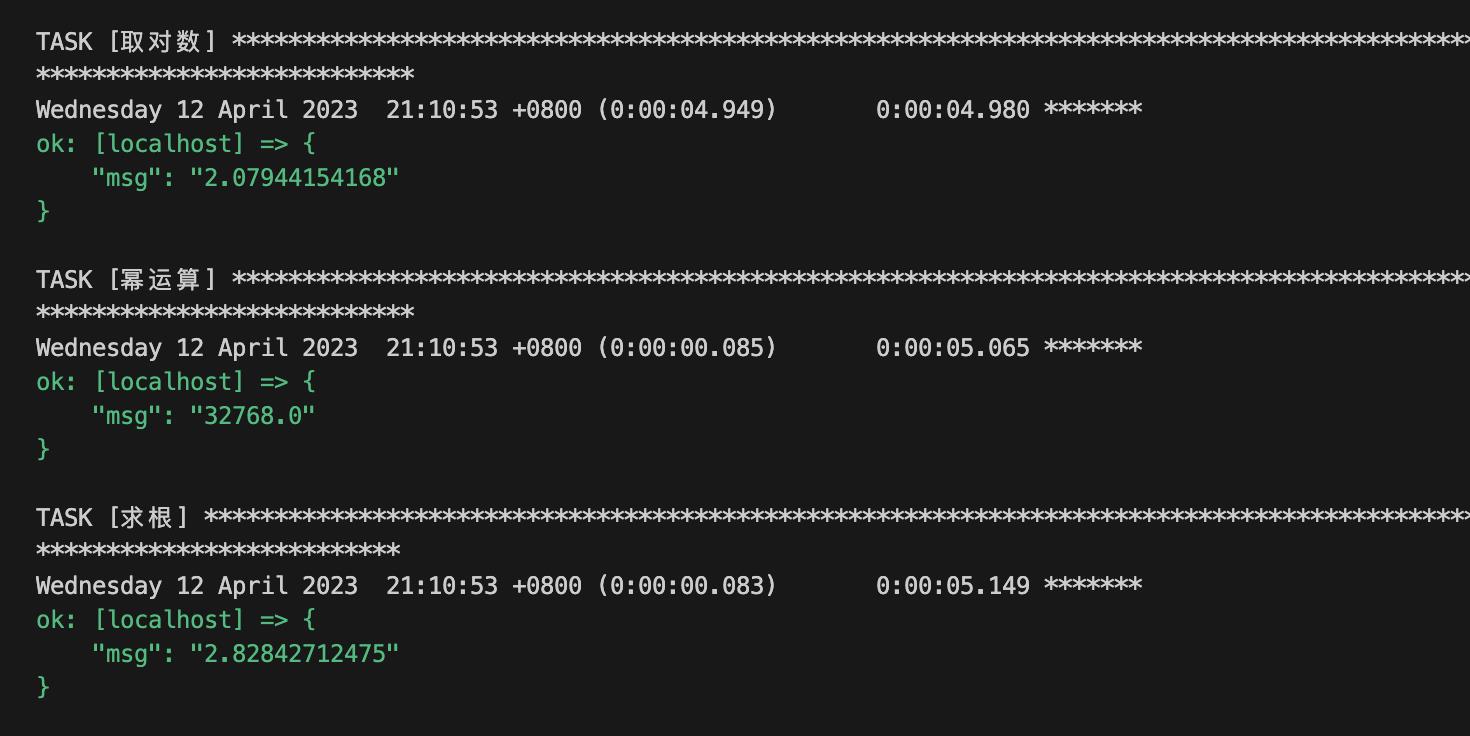
2.3 字典转换为列表
# cat demo.yaml
- hosts: localhost
vars:
is_dict:
name: tom
age: 18
tasks:
- name: 将字典转为列表
debug:
msg: " is_dict | dict2items "
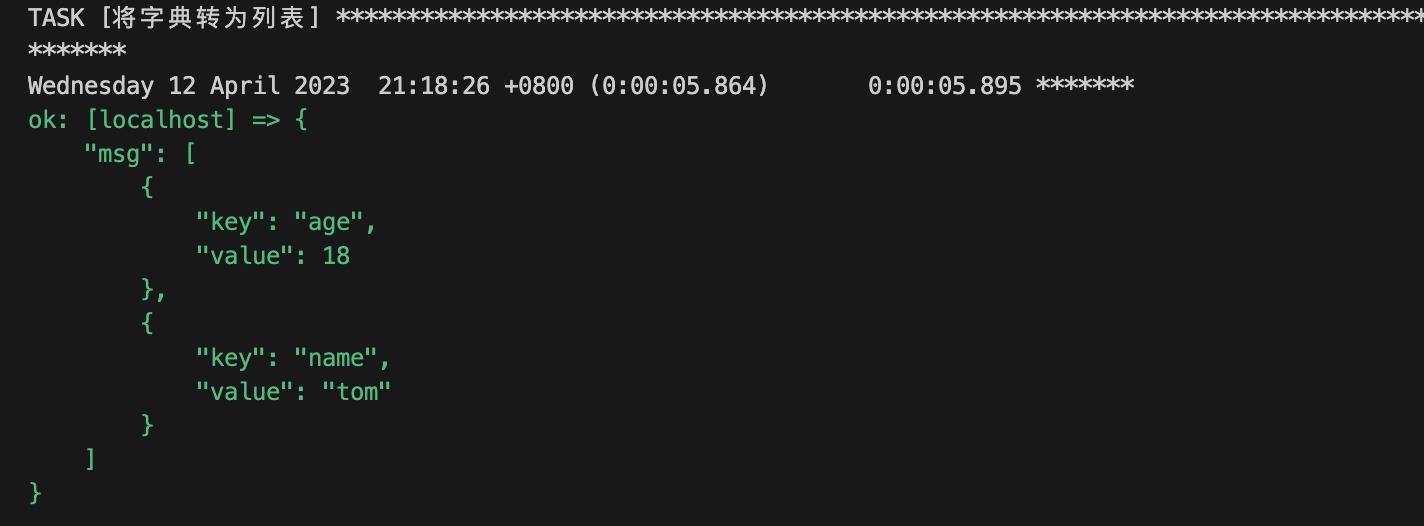
转换后的列表的元素会是一个固定格式的字典,之前字典中的k, v会分别作为一个value存储到key和value下
这个我用的比较多,在处理数据时经常用到,上面演示了如何获取最大的挂载点,下面来演示如何获取最大的磁盘设备,需要用到ansible_devices这个内置变量,下面来打印下ansible_devices的内容
# ansible localhost -m setup -a "filter=ansible_devices"执行结果是一个字典,key为设备名称,value为设备的详细信息,如下:
"vdb":
"holders": [],
"host": "SCSI storage controller: Red Hat, Inc. Virtio block device",
"links":
"ids": [
"virtio-17d4e0d5-fabb-46c6-b"
],
"labels": [],
"masters": [],
"uuids": [
"e2f217b1-e17b-4e90-8a34-015c8585a809"
]
,
"model": null,
"partitions": ,
"removable": "0",
"rotational": "1",
"sas_address": null,
"sas_device_handle": null,
"scheduler_mode": "mq-deadline",
"sectors": "2097152000",
"sectorsize": "512",
"size": "1000.00 GB",
"support_discard": "0",
"vendor": "0x1af4",
"virtual": 1
,
"vda":
...
...
...
这里只截取了其中一个设备,很明显输出的内容是一个字典,那么我们如何对字典中的嵌套字典中的指定健进行排序呢?另外上面的输出信息中,我们可以看到size字段是一个字符串,而sectors也是一个字符串,但是我们可以将sectors转成int再进行对此值进行排序,要完成这些操作,我们需要生成一个新的字典,直接上示例:
# cat demo.yaml
- hosts: localhost
tasks:
- name: 生成一个新的字典
set_fact:
new_ansible_devices: " new_ansible_devices | default() | combine(item.key: item.value.sectors | int) "
with_dict: " ansible_devices "
- name: 打印新生成的字典
debug:
msg: " new_ansible_devices "运行结果如下:
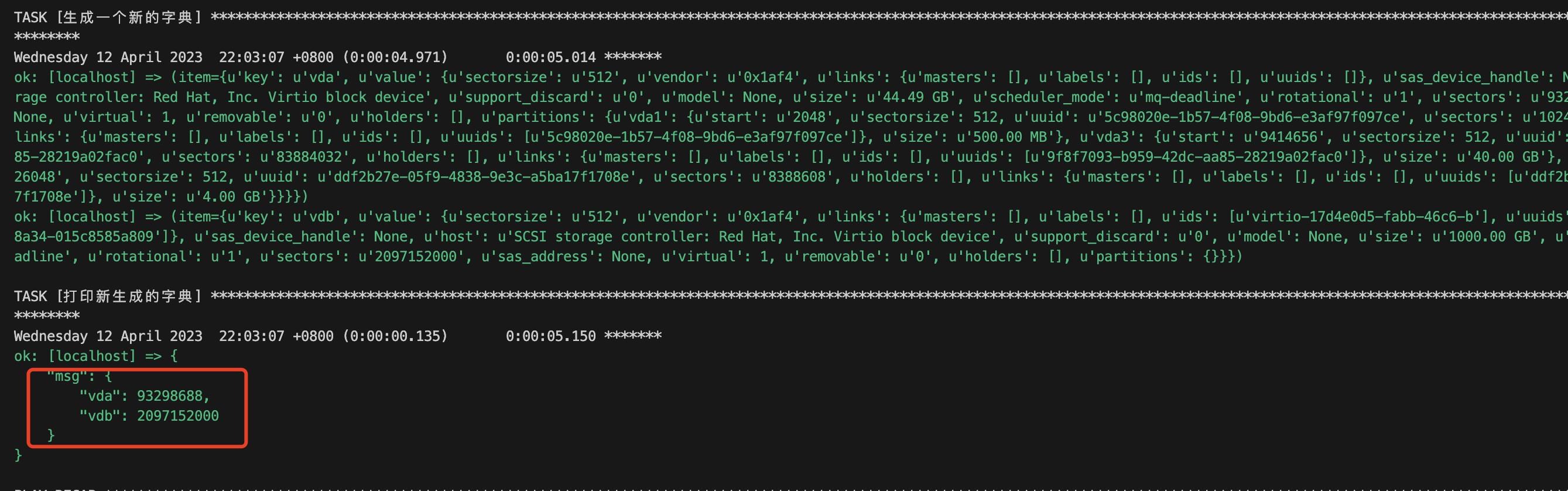
接下来的操作是不是就比较好处理了,可以按照我们一开始说的获取最大的挂载点的方式来操作
# cat demo.yaml
- hosts: localhost
tasks:
- name: 生成一个新的字典
set_fact:
new_ansible_devices: " new_ansible_devices | default() | combine(item.key: item.value.sectors | int) "
with_dict: " ansible_devices "
- name: 打印新生成的字典
debug:
msg: " new_ansible_devices "
- name: 转成列表,并进行排序
set_fact:
sort_disk_devices: " new_ansible_devices | dict2items | sort(attribute=\'value\') "
- name: 打印排序后的结果
debug:
msg: " sort_disk_devices "
- name: 使用last获取最大的设备名称
set_fact:
get_max_device: " sort_disk_devices | last "
- name: 打印最大的设备名称
debug:
msg: " get_max_device.key "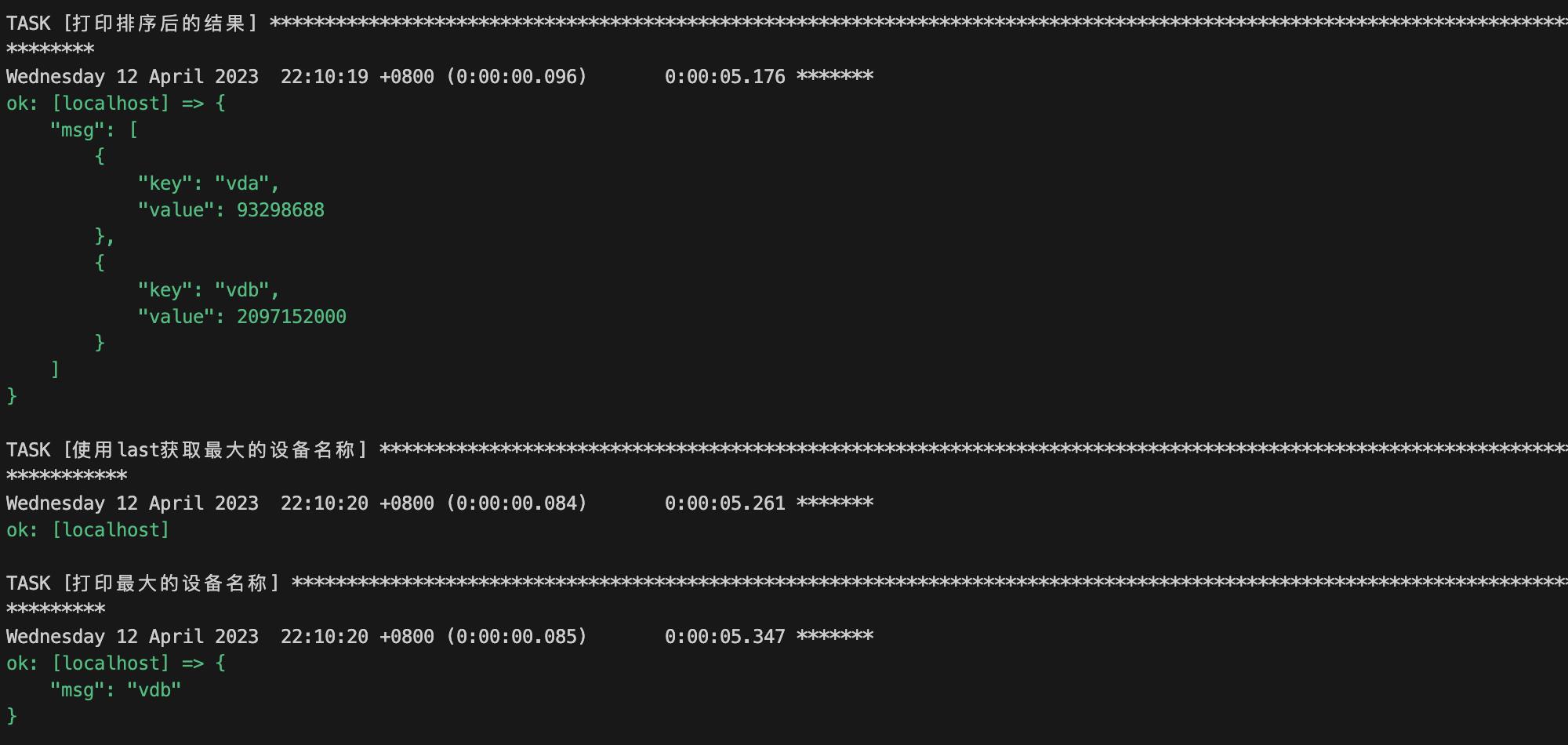
以上示例用到的东西很多,总结如下:
- 使用到了default来设置一个默认值,这里主要是为了生成一个新的字典
- 使用到了int来对字符串进行了类型转换
- 使用到了combine来将k, v 组合成一个字典
- 使用到了dict2items来将字典转成一个列表
- 使用到了sort来对列表中的元素进行排序
- 使用到了last来获取列表中的最后一个元素
2.4 将字典中的所有key生成一个list
这个也很常用,例如我想获取当前节点都有哪些磁盘设备,并且以列表的形式输出出来
# cat demo.yaml
- hosts: localhost
tasks:
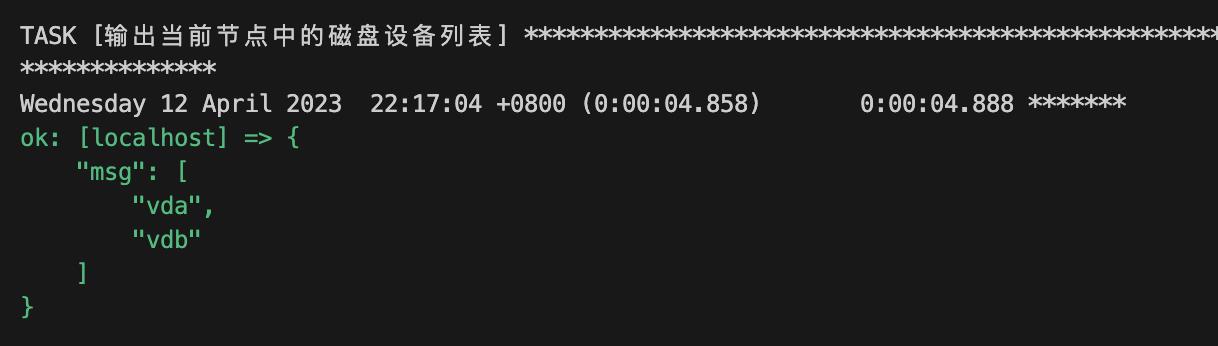
- name: 输出当前节点中的磁盘设备列表
debug:
msg: " ansible_devices.keys() | list "执行结果为:
除此之外,还可以使用map来实现
# cat demo.yaml
- hosts: localhost
tasks:
- name: 输出当前节点中的磁盘设备列表
debug:
msg: " ansible_devices | dict2items | map(attribute=\'key\') | list "输出的结果是一样的,这里不再赘述
2.5 总结
ansible提供的过滤器太多了,这里结合了实际的一些例子进行了展示,过程中使用到了很多的过滤器,总而言之过滤器就是来帮助我们来处理数据,或者对数据进行二次加工,最终来获取到我们想要的一些数据,或者数据类型。
由于过滤器太多,这里不再一一介绍,建议多看官方文档进行参考
官方参考文档:https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_filters.html#playbooks-filters
三、自定义过滤器
上面介绍了过滤器的使用,但是总有一些情况无法满足我们的需求,我们需要开发自己的一些过滤器,下面我将会演示如何通过python来实现一个自定义的过滤器,来实现对数据的处理
自定义过滤器和自定义模块类似,需要我们提前修改ansible.cfg文件,或者我们在编写playbook时,需要在roles下面对应的目录下创建filter_plugins目录,如下所示:
# 修改配置文件: /etc/ansible/ansible.cfg
[defaults]
filter_plugins = /opt/workspace/scripts/filter_plugins或者直接在roles下对应的role创建filter_plugins目录,例如:
roles/demo/filter_plugins需求:给一个字符串,该字符串可能是以,分割,可能以|, 也可能以:分割,需要自定义过滤器,将该字符串按照分隔符进行拆分,最终生成一个列表
# 过滤器名称:split_everything
from __future__ import absolute_import, division, print_function
__metaclass__ = type
def split_everything(content, sep=","):
return content.strip(sep).split(sep)
class FilterModule(object):
def filters(self):
return
"split_everything": split_everything,
使用方法:
# cat demo.yaml
- hosts: localhost
vars:
type_a: "a,b,c,d,e,"
type_b: "a|b|c|d"
type_c: "a:b"
type_d: "d@"
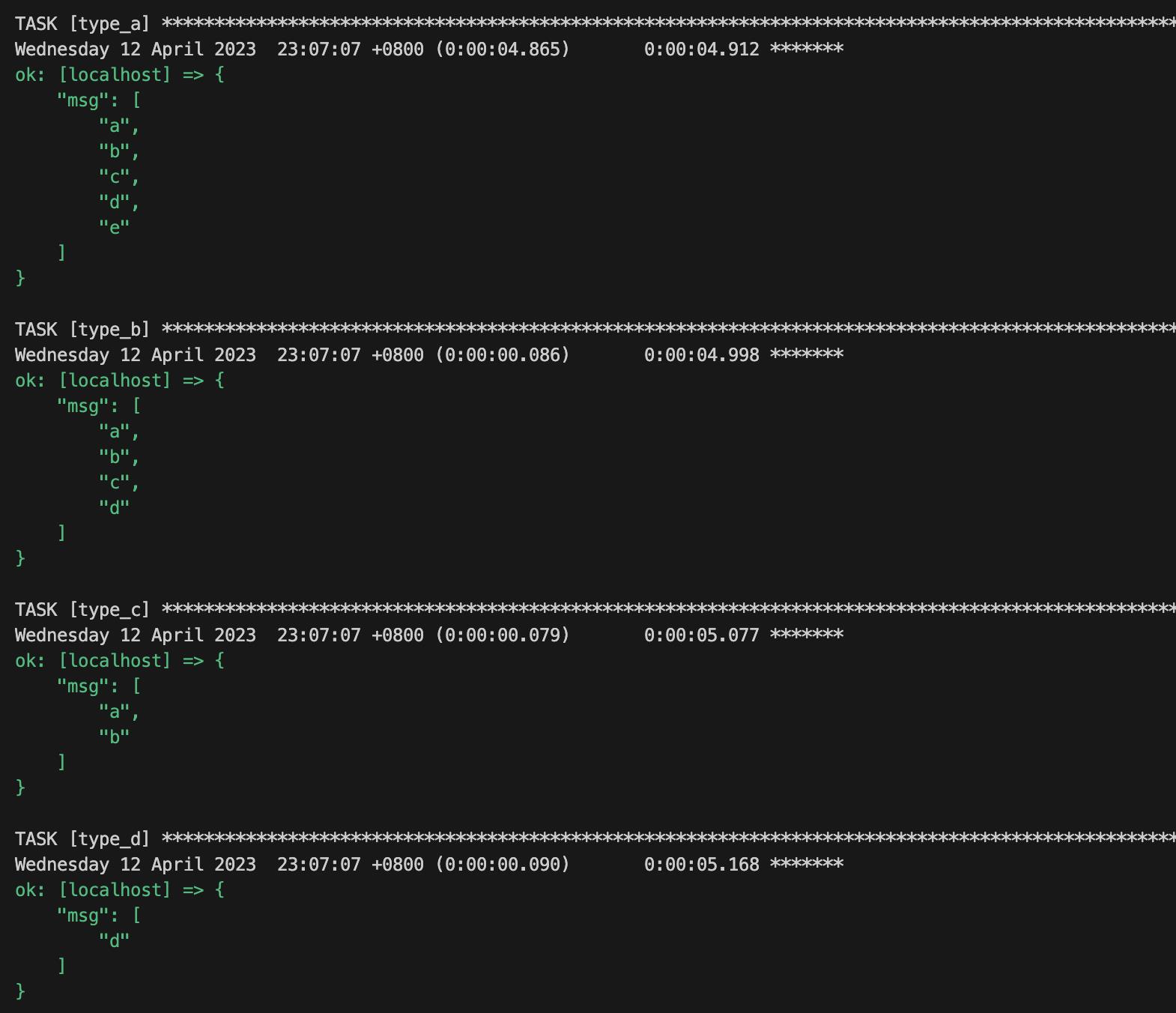
tasks:
- name: type_a
debug:
msg: " type_a | split_everything(sep=\',\') "
- name: type_b
debug:
msg: " type_b | split_everything(sep=\'|\') "
- name: type_c
debug:
msg: " type_c | split_everything(sep=\':\') "
- name: type_d
debug:
msg: " type_d | split_everything(sep=\'@\') "执行结果
四、总结
本文主要介绍了过滤器的作用,以及常用的过滤器,以磁盘设备、磁盘挂载等实际工作中的例子进行演示,同时还介绍了自定义模块的方法,通过自定义过滤器来满足我们多样化的需求,使我们在自动化中更加得心应手。
另外本篇文章并不是一个教程,而是结合工作中的事例来介绍如何使用过滤器,建议大家还是多阅读官方文档。
官方文档:https://docs.ansible.com/ansible/latest/plugins/filter.html#plugin-list

最后,欢迎关注公众号:feelwow
Ansible如何使用Filter插件转换数据
写在前面
- 今天和小伙伴分享一些Ansible中过滤器
- 博文内容比较简单
- 主要介绍的常用过滤器和对应的Demo
- 使用过滤器如何处理变量
- 理解不足小伙伴帮忙指正
- 食用方式:了解Ansible基础语法
傍晚时分,你坐在屋檐下,看着天慢慢地黑下去,心里寂寞而凄凉,感到自己的生命被剥夺了。当时我是个年轻人,但我害怕这样生活下去,衰老下去。在我看来,这是比死亡更可怕的事。--------王小波
Ansible 过滤器
关于Ansible 的过滤器,主要由两部分构成,一部分过滤器通过ansible filter插件提供,包含在 Ansible Engine 中,一部分过滤器通过python模板引擎jinja2提供
在模板引擎中,Ansible 使用 Jinja2 表达式将变量值应用到Playbook和模板。Jinja2 表达式也支持过滤器。过滤器用于修改或处理Playbook或模板中放入的变量的值。关于Jinja2,是基于python的模板引擎,类似Java的Freemarker,在Python Web 中也经常使用,比如Flask常常结合Jinja2 实现前后端不分离的小型Web项目
具体的过滤器列表,小伙伴们可以在下面的路劲看到,当在内网的时候,可以直接查找:
jinja2:/usr/lib/python3.6/site-packages/jinja2/filters.pyAnsible:/usr/lib/python3.6/site-packages/ansible/plugins/filter/core.py
过滤器具体的说明文档:
jinja2:https://jinja.palletsprojects.com/en/3.0.x/templates/#builtin-filtersAnsible:https://docs.ansible.com/ansible/2.8/user_guide/playbooks_filters.html
学习之前,简单回顾下 YAML格式数据文件中的变量的定义方式,熟悉小伙伴可以直接跳过
变量类型
YAML 结构或值内容定义了确切的数据类型。类型包括:
- 字符串(字符序列)
- 数字(数值)
- 布尔值
- 日期(ISO-8601 日历日期)
- Null(将变量设置为未定义的变量)
- 列表或数组(值的有序集合)
- 字典(键值对的集合)
字符串
字符串是一系列字符,是Ansible中的默认数据类型。字符串不需要使用引导或双引号括起:
YAML 格式允许定义多行字符,使用竖线(|)保留换行符,或使用大于运算符(>)来取消换行符,(最后一个换行符还是会存在):
---
- name: demo var type
hosts: servera
tasks:
- name: var1
vars:
string_var: |
liruilong
and
students
string_vars: >
liruilong
and
students
debug:
msg: " string_var ||| string_vars "
测试一下
$ ansible-playbook var_type.yaml
PLAY [demo var type] *********************************************************************************
TASK [var1] ******************************************************************************************
ok: [servera] =>
"msg": "liruilong \\nand \\nstudents\\n ||| liruilong and students \\n"
PLAY RECAP *******************************************************************************************
servera : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
数字
当变量内容是数字时,YAML 会解析字符串,并生成一个数字值,即 Integer 或 Float 类型。
- Integers 包含十进制字符,并且可以选择在前面加上 + 或 - 符号:
- 如果数值中包含小数点,则将其解析为 Float:
- 也可以使用科学记数法表示很大的 Integers 或 Floats:
- 十六进制数字以 0x 开头,后面仅跟十六进制字符:
- 如果将数字放在引号中,其将被视为 String:
$ cat var_type.yaml
---
- name: demo var type
hosts: servera
tasks:
- name: var1
vars:
string_var: 2.165
string_vars: 456
debug:
msg: " string_var ||| string_vars + 3 "
$ ansible-playbook var_type.yaml
PLAY [demo var type] *********************************************************************************
TASK [var1] ******************************************************************************************
ok: [servera] =>
"msg": "2.165 ||| 459"
PLAY RECAP *******************************************************************************************
servera : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
$
布尔值
布尔值包含 yes、no、y、n、on、off、true 或 false 字符串。不区分大小写,但是 Jinja2 文档中建议使用小写来保持一致。
$ cat var_type.yaml
---
- name: demo var type
hosts: servera
tasks:
- name: var1
vars:
string_var: 2.165
string_vars: 456
boo: yes
shell: echo " string_var "
when: boo
$ ansible-playbook var_type.yaml
PLAY [demo var type] *********************************************************************************
TASK [var1] ******************************************************************************************
changed: [servera]
PLAY RECAP *******************************************************************************************
servera : ok=1 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
$
日期
如果字符串符合 ISO-8601 标准,YAML 会将字符串转换为 date 类型的值:
Null
特殊的 Null 值将变量声明为 undefined:
$ ansible-playbook var_demo.yaml
PLAY [var demo] **************************************************************************************
TASK [var1 demo] *************************************************************************************
ok: [servera] =>
"msg": " \\n"
PLAY RECAP *******************************************************************************************
servera : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
$
列表或数组
列表(数组)是值的有序集合。列表是数据收集和循环的基本结构。将列表写成以逗号分隔的值序列并用方括号括起,或每行一个元素并加上短划线前缀:可以使用从 0 开始的索引编号来访问列表的特定元素:
$ ansible-playbook var_demo.yaml
PLAY [var demo] **************************************************************************************
TASK [var1 demo] *************************************************************************************
ok: [servera] =>
"msg": "v1 ['v1', 'v2', 'v3'] \\n"
PLAY RECAP *******************************************************************************************
servera : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
$ cat var_demo.yaml
---
- name: var demo
hosts: servera
vars:
param:
- v1
- v2
- v3
tasks:
- name: var1 demo
debug:
msg: >
param.0 param
$
字典
字典(映射或散列)是将字符串键链接到值以进行直接访问的结构,键括在方括号中来访问字典中的项:
$ ansible-playbook var_demo.yaml
PLAY [var demo] **************************************************************************************
TASK [var1 demo] *************************************************************************************
ok: [servera] =>
"msg": "'v1': 10, 'v2': 11, 'v3': 12 10 \\n"
PLAY RECAP *******************************************************************************************
servera : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
$ cat var_demo.yaml
---
- name: var demo
hosts: servera
vars:
param_dist:
v1: 10
v2: 11
v3: 12
tasks:
- name: var1 demo
debug:
msg: >
param_dist param_dist['v1']
$
使用Jinja2过滤器处理数据
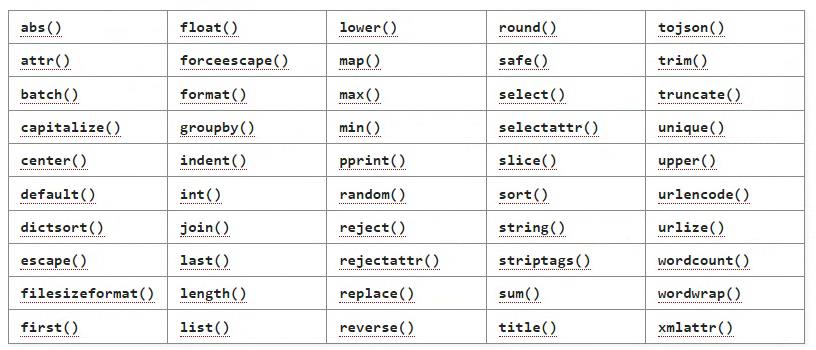
应用过滤器,需要在变量名称后面加上竖线字符和要应用的过滤器的名称。某些过滤器可能需要将可选参数或选项放在括号中。可以在一个表达式中串联多个过滤器。
jinja2支持的过滤器:https://jinja.palletsprojects.com/en/3.0.x/templates/#jinja-filters
看几个demo
使用 Jinja2 过滤器来将首字母进行大写小写转化:
$ ansible servera -m debug -a 'msg= "liruilong" | lower'
servera | SUCCESS =>
"msg": "liruilong"
$ ansible servera -m debug -a 'msg= "liruilong" | capitalize '
servera | SUCCESS =>
"msg": "Liruilong"
将变量转换为另一种类型,如转换为 String 类型:
$ ansible servera -m debug -a 'msg= "liruilong" | string '
servera | SUCCESS =>
"msg": "liruilong"
使用unique过滤器来删除重复数据,使用sort过滤器对其进行排序:
$ ansible servera -m debug -a 'msg= [2,3,4,5,3,1,6] | unique | sort '
servera | SUCCESS =>
"msg": [
1,
2,
3,
4,
5,
6
]
常用过滤器
检查变量是否定义
mandatory:如果变量未定义,则会失败并中止 Ansible Playbook。
$ ansible servera -m debug -a 'msg= name | mandatory ' -e name=liruilong
servera | SUCCESS =>
"msg": "liruilong"
$ ansible servera -m debug -a 'msg= name | mandatory '
servera | FAILED! =>
"msg": "Mandatory variable 'name' not defined."
可以通过设置未定义变量的处理策略来忽略未定义的变量
$ ansible-config dump | grep -i unde
DEFAULT_UNDEFINED_VAR_BEHAVIOR(default) = True
$
通过配置文件查看可以看到,可以通过变量的方式,在命令行或者清单文件中定义
$ ansible-config list
env:
- name: ANSIBLE_ERROR_ON_UNDEFINED_VARS
ini:
- key: error_on_undefined_vars, section: defaults
name: Jinja2 fail on undefined
type: boolean
version_added: '1.3'
ansible.cfg
error_on_undefined_vars=false
default:如果变量未定义,或者为null,则过滤器会将其设置为圆括号中指定的值。
$ ansible servera -m debug -a 'msg= name | default( "liruilong",True) '
servera | SUCCESS =>
"msg": "liruilong"
如果括号中的第二个参数为 True ,那么变量的初始值是空字符串或布尔值 False 时,过滤器也会将变量设置为默认值。
$ ansible servera -m debug -a 'msg= name | default( "liruilong",True) ' -e name=''
servera | SUCCESS =>
"msg": "liruilong"
default 过滤器也可以取特殊值omit,会导致值在没有初始值时保留为未定义状态。如果变量已具有值,则 omit不会更改值。
$ ansible servera -m debug -a 'msg= names | default(omit) '
servera | SUCCESS =>
"msg": "Hello world!"
$ ansible servera -m debug -a 'msg= names | default(omit) ' -e names=liruilong
servera | SUCCESS =>
"msg": "liruilong"
$
执行数学计算
Jinja2 提供了多个数学过滤器,可以对数字进行运算。
算术运算:某写情况下,可能需要首先使用 int 过滤器将值转换为整数,或使用 float 过滤器将值转换为浮点数。还有其它的可用于数学运算的过滤器:root、log、pow、abs 和 round 等。
$ ansible servera -m debug -a 'msg= (12.3 | int) + 1 '
servera | SUCCESS =>
"msg": "13"
$ ansible servera -m debug -a 'msg= (-12.3 | int) | abs '
servera | SUCCESS =>
"msg": "12"
操作列表
如果列表中包含数字,可以使用max、min 或 sum来查找所有列表项的最大数、最小数和总和:
$ ansible servera -m debug -a 'msg= [2,3,4,5,3,1,6] | max '
servera | SUCCESS =>
"msg": "6"
$ ansible servera -m debug -a 'msg= [2,3,4,5,3,1,6] | sum '
servera | SUCCESS =>
"msg": "24"
提取列表元素
- 通过
first、last、length来获取列表信息:
$ ansible servera -m debug -a 'msg= [2,3,4,5,3,1,6] | first '
servera | SUCCESS =>
"msg": "2"
$ ansible servera -m debug -a 'msg= [2,3,4,5,3,1,6] | last '
servera | SUCCESS =>
"msg": "6"
$ ansible servera -m debug -a 'msg= [2,3,4,5,3,1,6] | length '
servera | SUCCESS =>
"msg": "7"
random过滤器从列表中返回一个随机元素:
$ ansible servera -m debug -a 'msg= [2,3,4,5,3,1,6] | random '
servera | SUCCESS =>
"msg": "1"
修改列表元素的顺序
sort过滤器按照元素的自然顺序对列表进行排序。
$ ansible servera -m debug -a 'msg= [2,3,4,5,3,1,6] | sort '
servera | SUCCESS =>
"msg": [
1,
2,
3,
3,
4,
5,
6
]
reverse过滤器会返回一个顺序与原始顺序相反的列表。
$ ansible servera -m debug -a 'msg= [2,3,4,5,3,1,6] | sort | reverse | list '
servera | SUCCESS =>
"msg": [
6,
5,
4,
3,
3,
2,
1
]
shuffle过滤器返回一个列表,顺序为随机。
$ ansible servera -m debug -a 'msg= [2,3,4,5,3,1,6] | sort | reverse | shuffle|list '
servera | SUCCESS =>
"msg": [
3,
2,
4,
5,
6,
1,
3
]
合并列表
flatten 过滤器以递归方式取输入列表值中的任何内部列表,并将内部值添加到外部列表中:
$ ansible servera -m debug -a 'msg= [2,3,4,5,3,1,6,[[7,8],9]] | flat
ten'
servera | SUCCESS =>
"msg": [
2,
3,
4,
5,
3,
1,
6,
7,
8,
9
]
以集合形式操作列表
unique过滤器确保列表中没有重复元素。union并集:过滤器返回一个集合,包含两个集合中的元素。intersect交集:过滤器返回一个集合,包含两个集合中共有的元素。difference差集:过滤器返回一个集合,包含存在于第一个集合但不存在第二个集合的元素。
依次来看一下
unique 过滤器确保列表中没有重复元素。
$ ansible servera -m debug -a 'msg= [2,3,4,3] | unique '
servera | SUCCESS =>
"msg": [
2,
3,
4
]
union 过滤器返回一个集合,包含两个集合中的元素。
$ ansible servera -m debug -a 'msg= [2,3,4,3] | union([5]) '
servera | SUCCESS =>
"msg": [
2,
3,
4,
5
]
intersect 过滤器返回一个集合,包含两个集合中共有的元素。
$ ansible servera -m debug -a 'msg= [2,3,4,3] | intersect([4]) '
servera | SUCCESS =>
"msg": [
4
]
difference 过滤器返回一个集合,包含存在于第一个集合但不存在第二个集合的元素。
$ ansible servera -m debug -a 'msg= [2,3,4,3] | difference([4]) '
servera | SUCCESS =>
"msg": [
2,
3
]
操作字典
与列表不同,字典不会以任何方式进行排序。它们仅仅是键值对的集合。
$ ansible servera -m debug -a 'msg= "name":"liruilong" '
servera | SUCCESS =>
"msg":
"name": "liruilong"
连接字典
通过 combine 过滤器连接多个字典:
$ ansible servera -m debug -a 'msg= "name":"liruilong" | combine( "age": 27 ) ' servera | SUCCESS =>
"msg":
"age": 27,
"name": "liruilong"
重塑字典
字典可以通过 dict2items 过滤器重塑为列表
$ ansible servera -m debug -a 'msg= "name":"liruilong" | combine( "age": 27 )| dict2items '
servera | SUCCESS =>
"msg": [
"key": "name",
"value": "liruilong"
,
"key": "age",
"value": 27
]
列表也可通过items2dict过滤器重塑为字典:
$ ansible servera -m debug -a 'msg= "name":"liruilong" | combine( "age": 27 )| dict2items | items2dict '
servera | SUCCESS =>
"msg":
"age": 27,
"name": "liruilong"
$
散列、编码和操作字符串
有多个过滤器可用于操作值的文本。可以取各种校验和,创建密码哈希,并将文本和 Base64 编码相互转换。
散列字符串和密码
hash 过滤其可以利用提供的哈希算法,返回输入字符串的哈希值:
$ ansible servera -m debug -a 'msg= "liruilong" | hash("sha1") '
servera | SUCCESS =>
"msg": "bd588e37a86b3f527f61a70bc1ab65129abe4f2c"
$ ansible servera -m debug -a 'msg= "liruilong" | hash("md5") '
servera | SUCCESS =>
"msg": "5406f230fe5927a6ea9ac57ba6f4c6cf"
$
$ ansible servera -m debug -a 'msg= "liruilong" | hash("sha512") '
servera | SUCCESS =>
"msg": "1ca56023dcbce5b9e85ec6caf3bd721a227ee754afb31171970d19256a24bdbafa0c1f5a0ad66cd93c5b86ea2f7ad5e1d1a63aee7edaaa3533dfd71fcfbe5b06"
使用password_hash过滤器来生成密码哈希:
看下机器上root的密码,
# cat /etc/shadow | grep root
root:$6$3kq6I94xqKs0Giut$sEWrjkl8QDpCCb3FECMpOGbVKwJFzxOMzeNJIr6LZjNpjwpU.njmf6bz2JPt6D1OocbCU2fOGchWPfUaI2plq1:18025:0:99999:7:::
通过密码串我们可以知道,盐为:3kq6I94xqKs0Giut ,加密类型为:$6(sha512),通过Ansilbe的插件生成
$ ansible servera -m debug -a 'msg= "redhat" | password_hash("sha512","3kq6I94xqKs0Giut") ' servera | SUCCESS =>
"msg": "$6$3kq6I94xqKs0Giut$sEWrjkl8QDpCCb3FECMpOGbVKwJFzxOMzeNJIr6LZjNpjwpU.njmf6bz2JPt6D1OocbCU2fOGchWPfUaI2plq1"
编码字符串
可以通过b64encode过滤器将二进制数据转换为 base64,并通过 b64decode 过滤器重新转换为二进制:在将字符串发送到 Shell 之前,为了避免解析或代码注入的问题,最好使用quote过滤器清理字符串,这个没有Demo。
格式化字符串
使用lower、upper、或 capitalize过滤器来强制字符串的大小写:
$ ansible servera -m debug -a 'msg= "Liruilong" | lower '
servera | SUCCESS =>
"msg": "liruilong"
$ ansible servera -m debug -a 'msg= "Liruilong" | upper '
servera | SUCCESS =>
"msg": "LIRUILONG"
$ ansible servera -m debug -a 'msg= "liruilong" | capitalize '
servera | SUCCESS =>
"msg": "Liruilong"
替换文本
regex_search过滤器,查找所有出现的子字符串,匹配行中第一个项目,并返回一个列表值。regex_findall过滤器,查找所有出现的子字符串,匹配行中所有项目,并返回一个列表值。replace过滤器,换输入字符串中所有出现的子字符串,不支持正则表达式。regex_replace过滤器,换输入字符串中所有出现的子字符串。
replace 过滤器用于替换字符串:
$ ansible servera -m debug -a 'msg= "liruilong" | replace("long","bo") '
servera | SUCCESS =>
"msg": "liruibo"
通过使用正则表达式和 regex_search 和 regex_replace 过滤器可以进行更加复杂的搜索替换:
$ ansible servera -m debug -a 'msg= "liruilong up " | regex_search("up") '
servera | SUCCESS =>
"msg": "up"
$ ansible servera -m debug -a 'msg= "liruilong up " | regex_replace("up","and") '
servera | SUCCESS =>
"msg": "liruilong and "
操作 JSON 数据
Ansible 使用的许多数据结构都采用 JSON 格式。JSON 和 YAML 表示法密切相关,Ansible 数据结构则可作为 JSON 来处理。
from_json和from_yaml过滤器,从已经格式化好的变量读取数据。
格式化数组
$ cat name_list.yaml
users:
- name: "liruilong"
job: "dev"
- name: "sy"
job: "ops"
$ ansible-playbook json.yaml
PLAY [json demo] *************************************************************************************
TASK [debug] *****************************************************************************************
ok: [servera] =>
"msg": [
"job": "dev",
"name": "liruilong"
,
"job": "ops",
"name": "sy"
]
PLAY RECAP *******************************************************************************************
servera : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
$ cat json.yaml
---
- name: json demo
hosts: servera
vars_files:
- name_list.yaml
tasks:
- debug:
msg: " users | from_yaml "
JSON 查询
使用 json_query 过滤器从 Ansible 数据结构中提取信息:
$ cat name_list.yaml
users:
- name: "liruilong"
job: "dev"
- name: "sy"
job: "ops"
$ ansible-playbook json.yaml
PLAY [json demo] *************************************************************************************
TASK [debug] *****************************************************************************************
ok: [servera] =>
"msg": [
"liruilong",
"sy"
]
$ cat json.yaml
---
- name: json demo
hosts: servera
vars_files:
- name_list.yaml
tasks:
- debug:
msg: " users | json_query('[*].name') "
分析和编码数据结构
数据结构使用to_json 和 to_yaml过滤器序列化为 JSON 或 YAML 格式。哈,这个感谢没啥区别,以后再研究下
$ ansible servera -m debug -a 'msg= file | to_json ' -e file='["name":"bastion","ip":["172.25.250.254","172.25.252.1"]]'
servera | SUCCESS =>
"msg": "\\"[\\\\\\"name\\\\\\":\\\\\\"bastion\\\\\\",\\\\\\"ip\\\\\\":[\\\\\\"172.25.250.254\\\\\\",\\\\\\"172.25.252.1\\\\\\"]]\\""
$ ansible servera -m debug -a 'msg= file | to_yaml ' -e file='["name":"bastion","ip":["172.25.250.254","172.25.252.1"]]'
servera | SUCCESS =>
"msg": "'[\\"name\\":\\"bastion\\",\\"ip\\":[以上是关于ansible中过滤器的介绍以及如何自定义过滤器的主要内容,如果未能解决你的问题,请参考以下文章