Python爬虫基础知识入门一
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫基础知识入门一相关的知识,希望对你有一定的参考价值。
一、什么是爬虫,爬虫能做什么
爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来。比如它在抓取一个网页,在这个网中他发现了一条道路,其实就是指向网页的超链接,那么它就可以爬到另一张网上来获取数据。
爬虫可以抓取的某个网站或者某个应用的内容,提取有用的价值。也可以模拟用户在浏览器或者App应用上的操作,实现自动化的程序。以下行为都可以用爬虫实现:
- 咨询报告(咨询服务行业)
- 抢票神器
- 投票神器
- 预测(股市预测、票房预测)
- 国民情感分析
- 社交关系网络
- 政府部门舆情监控
二、爬虫基本原理
爬虫是 模拟用户在浏览器或者App应用上的操作,把操作的过程、实现自动化的程序
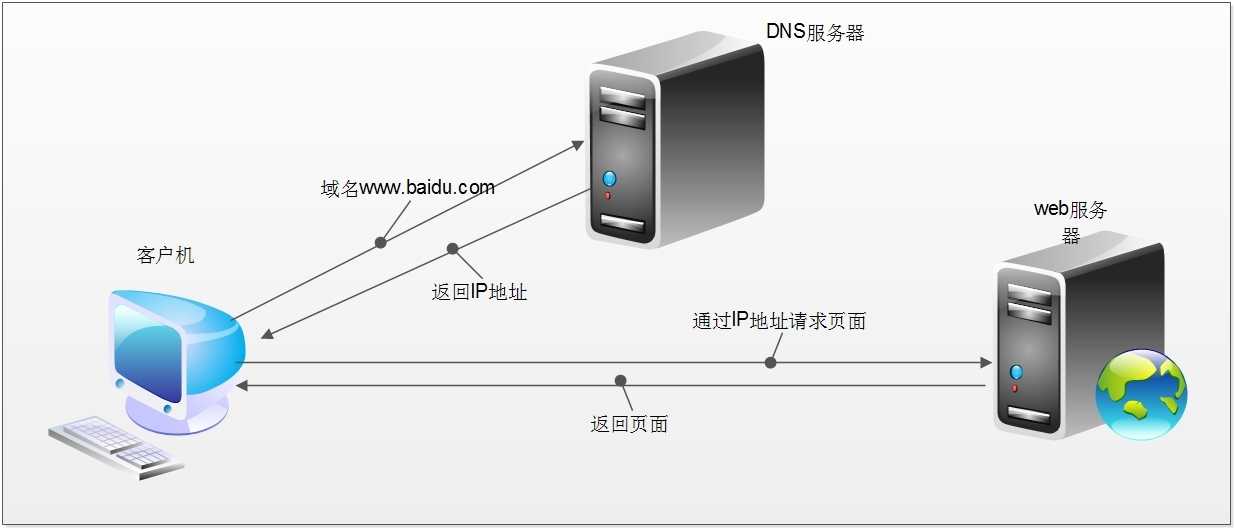
当我们在浏览器中输入一个url后回车,后台会发生什么?比如说你输入https://www.baidu.com
简单来说这段过程发生了以下四个步骤:
-
查找域名对应的IP地址。
浏览器首先访问的是DNS(Domain Name System,域名系统),dns的主要工作就是把域名转换成相应的IP地址
-
向IP对应的服务器发送请求。
-
服务器响应请求,发回网页内容。
-
浏览器显示网页内容。
网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据, 而不需要一步步人工去操纵浏览器获取。
三、使用urllib爬取数据
1. urlopen( )
打开一个url的方法,返回一个文件对象,然后可以进行类似文件对象的操作
>>> # 导入模块
>>> import urllib
>>>
>>> # 打开指定的url,就好比操作本地文件一样
>>> f = urllib.urlopen(‘http://www.baidu.com‘)
>>>
>>> #读取html页面的第一行
>>> firstLine = f.readline()
>>> firstLine
‘<!DOCTYPE html><!--STATUS OK--><html><head><meta http-equiv="content-type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=Edge"><meta content="always" name="referrer"><meta name="theme-color" content="#2932e1"><link rel="shortcut icon" href="/favicon.ico" type="image/x-icon" /><link rel="search" type="application/opensearchdescription+xml" href="/content-search.xml" title="\\xe7\\x99\\xbe\\xe5\\xba\\xa6\\xe6\\x90\\x9c\\xe7\\xb4\\xa2" /><link rel="icon" sizes="any" mask href="//www.baidu.com/img/baidu.svg"><link rel="dns-prefetch" href="//s1.bdstatic.com"/><link rel="dns-prefetch" href="//t1.baidu.com"/><link rel="dns-prefetch" href="//t2.baidu.com"/><link rel="dns-prefetch" href="//t3.baidu.com"/><link rel="dns-prefetch" href="//t10.baidu.com"/><link rel="dns-prefetch" href="//t11.baidu.com"/><link rel="dns-prefetch" href="//t12.baidu.com"/><link rel="dns-prefetch" href="//b1.bdstatic.com"/><title>\\xe7\\x99\\xbe\\xe5\\xba\\xa6\\xe4\\xb8\\x80\\xe4\\xb8\\x8b\\xef\\xbc\\x8c\\xe4\\xbd\\xa0\\xe5\\xb0\\xb1\\xe7\\x9f\\xa5\\xe9\\x81\\x93</title>\\n‘
说明:
-
read( ) , readline( ) ,readlines( ) , fileno( ) , close( ) :这些方法的使用方式与文件对象完全一样
-
info( ):返回一个httplib.HTTPMessage对象,表示远程服务器返回的头信息
-
getcode( ):返回Http状态码。如果是http请求,200请求成功完成;404网址未找到
-
geturl( ):返回请求的url
-
如果urlopen( )不能够成功打开一个url,那么会产生一个异常,此时可以通过try来捕获然后处理
2. urlretrieve( )
urlretrieve方法将url定位到的html文件下载到你本地的硬盘中。
如果不指定filename,则会存为临时文件。
urlretrieve()返回一个二元组(filename,mine_hdrs)
2.1 不指定路径
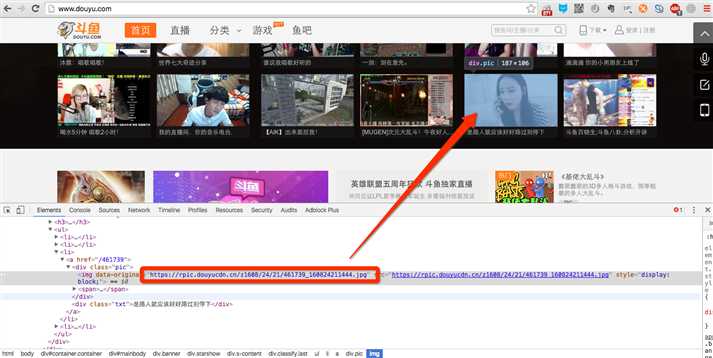
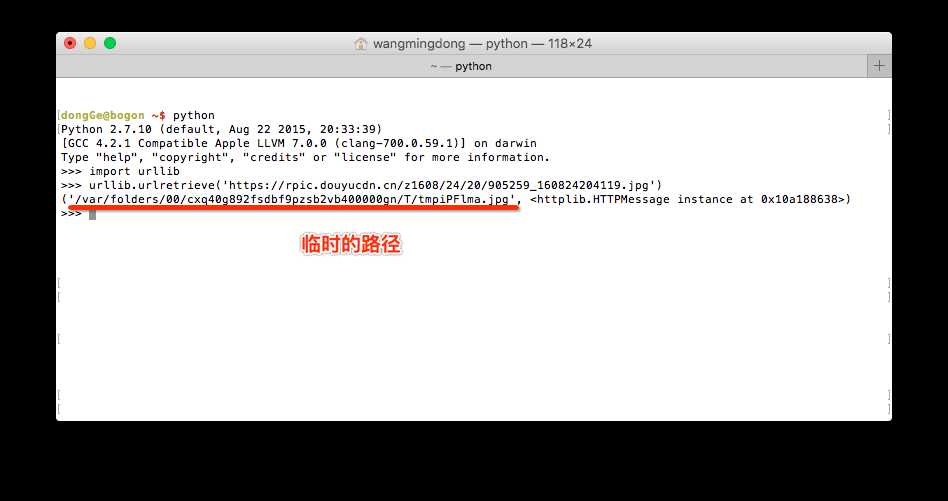
说明:
- 清除由于urllib.urlretrieve()所产生的缓存
2.2 指定路径
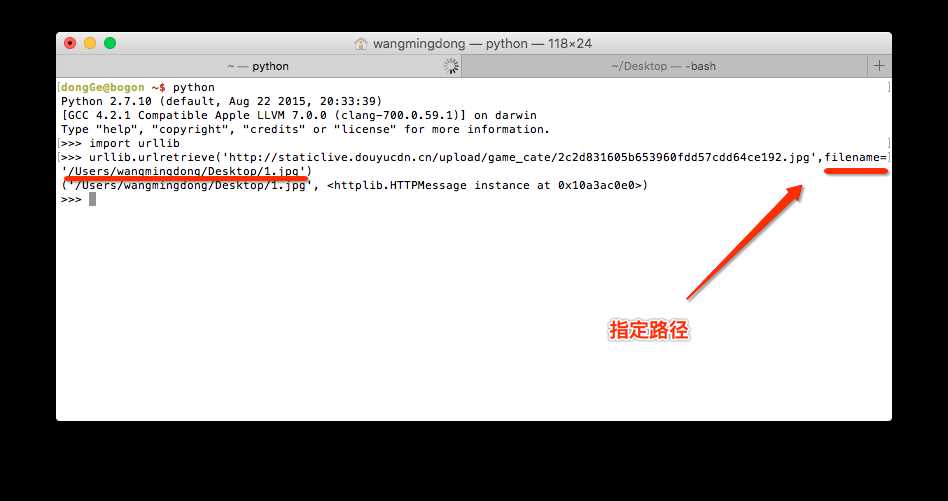
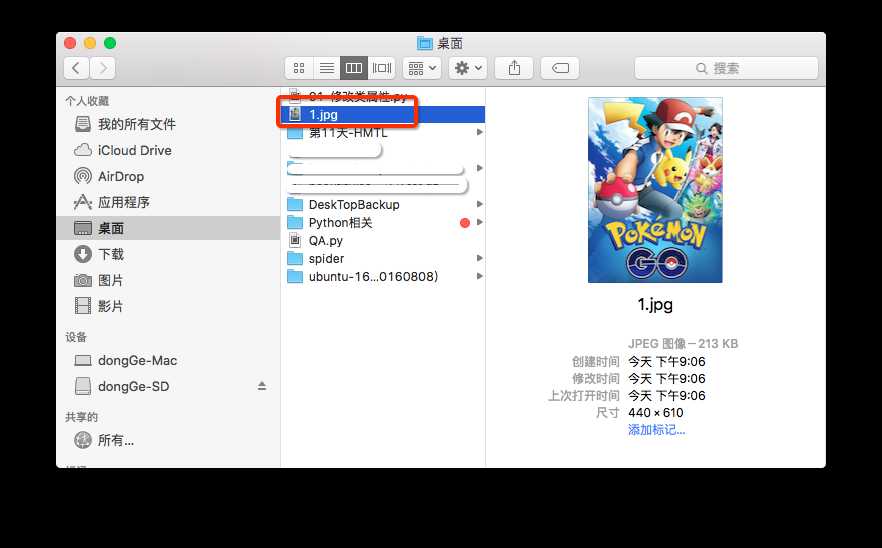
2.3 urlencode( )
上面的程序演示了最基本的网页抓取,不过,现在大多数网站都是动态网页,需要你动态地传递参数给它,它做出对应的响应。所以,在访问时,我们需要传递数据给它。最常见的情况是什么?对了,就是登录注册的时候呀。 把数据用户名和密码传送到一个URL,然后你得到服务器处理之后的响应,这个该怎么办?下面让我来为小伙伴们揭晓吧! 数据传送分为POST和GET两种方式
两种方式有什么区别呢?
最重要的区别是GET方式是直接以链接形式访问,链接中包含了所有的参数,当然如果包含了密码的话是一种不安全的选择,不过你可以直观地看到自己提交了什么内容。
POST则不会在网址上显示所有的参数,不过如果你想直接查看提交了什么就不太方便了,大家可以酌情选择。
这里可以与urlopen结合以实现post方法和get方法:
GET方法
>>> import urllib
>>> params=urllib.urlencode({‘t‘:1,‘eggs‘:2,‘bacon‘:0})
>>> params
‘eggs=2&bacon=0&spam=1‘
>>> f=urllib.urlopen("http://python.org/query?%s" % params)
>>> print f.read()
POST方法
>>> import urllib
>>> parmas = urllib.urlencode({‘spam‘:1,‘eggs‘:2,‘bacon‘:0})
>>> f=urllib.urlopen("http://python.org/query",parmas)
>>> f.read()四、使用urllib2爬取数据
1. urlopen( )
import urllib2
response = urllib2.urlopen("http://www.baidu.com")
print response.read()
我们来分析这两行代码,第一行
response = urllib2.urlopen("http://www.baidu.com")
首先我们调用的是urllib2库里面的urlopen方法,传入一个URL,这个网址是百度首页,协议是HTTP协议,当然你也可以把HTTP换做FTP,FILE,HTTPS 等等,只是代表了一种访问控制协议
print response.read()
response对象有一个read方法,可以返回获取到的网页内容
如果不加read直接打印会是什么?答案如下:
<addinfourl at 139728495260376 whose fp = <socket._fileobject object at 0x7f1513fb3ad0>>
直接打印出了该对象的描述,所以记得一定要加read方法,否则它不出来内容可就不怪我咯!
2. 构造Requset
其实上面的urlopen参数可以传入一个request请求,它其实就是一个Request类的实例,构造时需要传入Url,Data等等的内容。比
如上面的两行代码,我们可以这么改写
import urllib2
request = urllib2.Request("http://www.baidu.com")
response = urllib2.urlopen(request)
print response.read()
运行结果是完全一样的,只不过中间多了一个request对象,推荐大家这么写,因为在构建请求时还需要加入好多内容,通过构建一个request,服务器响应请求得到应答,这样显得逻辑上清晰明确。
3. POST和GET
3.1 GET方法
import urllib
import urllib2
values={}
values[‘username‘] = "[email protected]"
values[‘password‘]="XXXX"
data = urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request = urllib2.Request(geturl)
response = urllib2.urlopen(request)
print response.read()
可以通过print geturl,打印输出一下url,发现其实就是原来的url加?然后加编码后的参数
http://passport.csdn.net/account/login?username=993484988%40qq.com&password=X
3.2 POST方法
import urllib
import urllib2
values = {"username":"[email protected]","password":"XXXX"}
data = urllib.urlencode(values)
url = "https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn"
request = urllib2.Request(url,data)
response = urllib2.urlopen(request)
print response.read()
说明:
我们引入了urllib库,现在我们模拟登陆CSDN,当然上述代码可能登陆不进去,因为还要做一些设置头部header的工作,或者还有一些参数 没有设置全,还没有提及到在此就不写上去了,在此只是说明登录的原理。我们需要定义一个字典,名字为values,参数我设置了username和 password,下面利用urllib的urlencode方法将字典编码,命名为data,构建request时传入两个参数,url和data,运行程序,即可实现登陆,返回的便是登陆后呈现的页面内容。
获取响应头信息
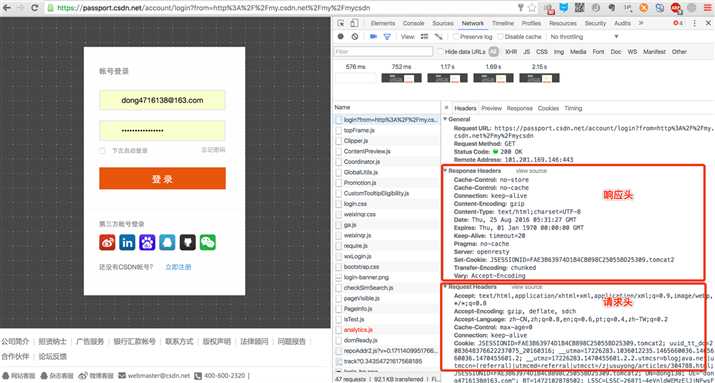
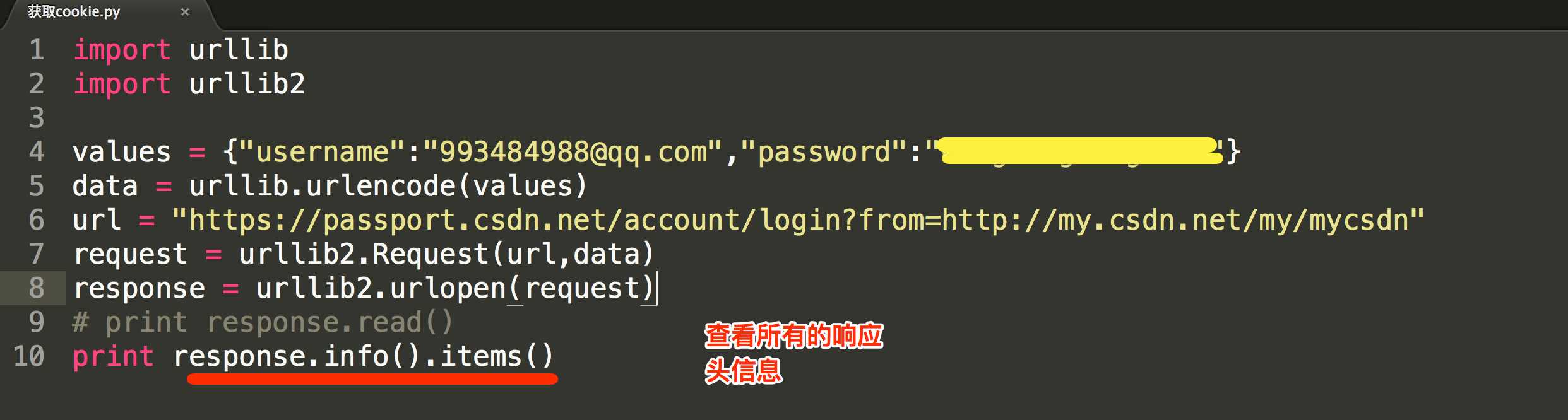
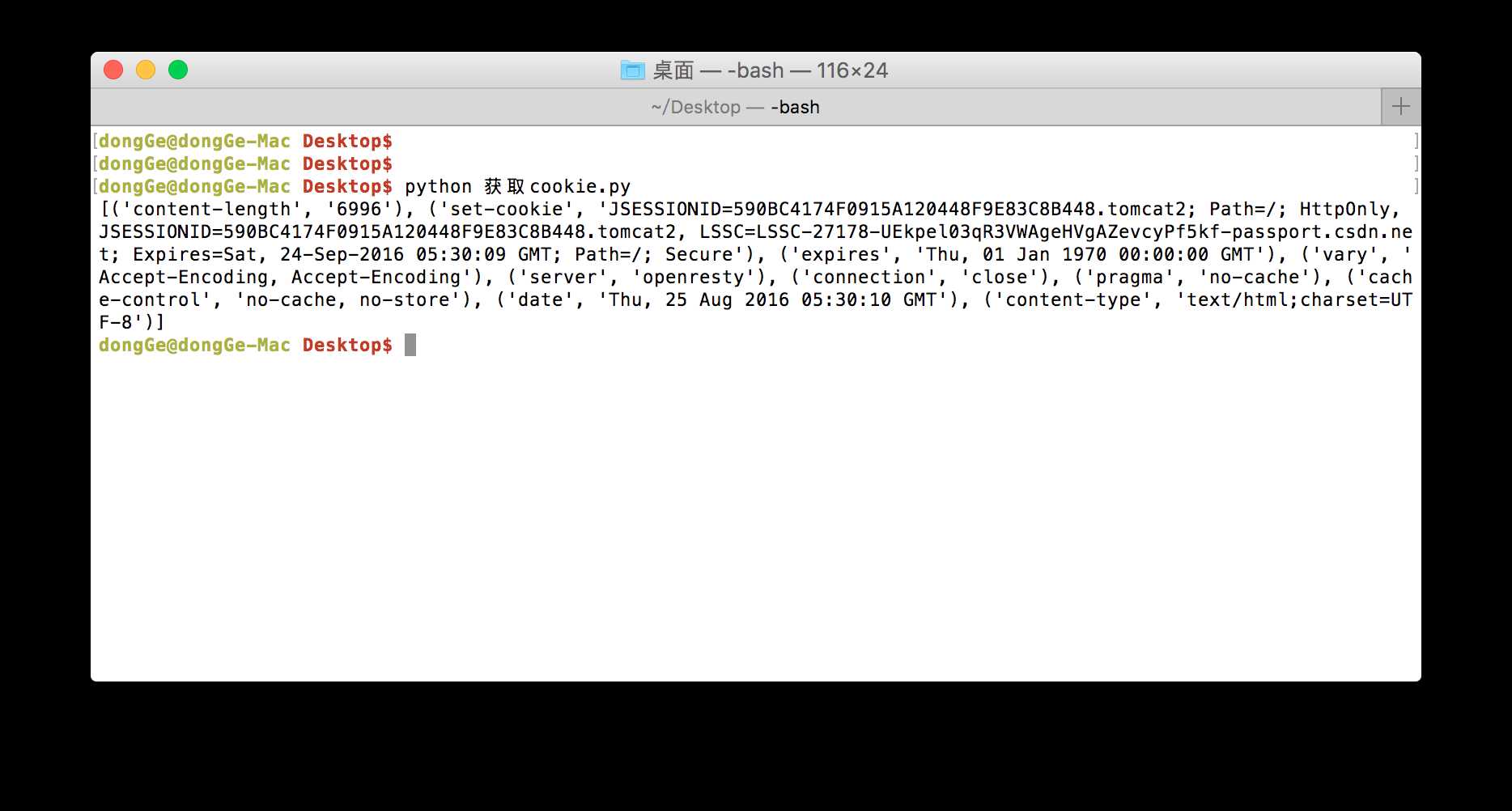
伪造请求头信息
#coding=utf-8
import urllib2
import sys
#抓取网页内容-发送报头-1
url= "http://www.phpno.com"
send_headers = {
‘Host‘:‘www.phpno.com‘,
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0‘,
‘Accept‘:‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘,
‘Connection‘:‘keep-alive‘
}
req = urllib2.Request(url,headers=send_headers)
r = urllib2.urlopen(req)
...省略后面的代码...
通过
help(urllib2)可以查看这个模块中的很多类以及方法
通过urlopen().info() 可以查看到很多的操作方法
4. urllib和urllib2的区别
- urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL。这意味着,你不可以通过urllib模块伪装你的User Agent字符串等(伪装浏览器)。
- urllib提供urlencode方法用来GET查询字符串的产生,而urllib2没有。这是为何urllib常和urllib2一起使用的原因。
- urllib2模块比较优势的地方是urlliburllib2.urlopen可以接受Request对象作为参数,从而可以控制HTTP Request的header部。
五、使用简单的正则解析数据
#coding=utf-8
#正则表达式模块
import re
#获取路径模块
import urllib
def getHtml(url):
page=urllib.urlopen(url)
html=page.read()
return html
def getImag(html):
imglist = re.findall(r‘src="(.*?\\.(jpg|png))"‘,html)
x=0
for imgurl in imglist:
print(‘正在下载 %s‘imgurl[0])
urllib.urlretrieve(imgurl[0],‘./downloads/%d.jpg‘%x)
x+=1
html=getHtml("http://www.douyu.com/directory/game/LOL")
getImag(html)六、使用BeautifulSoup解析数据
有的小伙伴们对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Beautiful Soup,有了它我们可以很方便地提取出HTML或XML标签中的内容,实在是方便,这一节就让我们一起来感受一下Beautiful Soup的魅力
1. Beautiful Soup的简介
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。 Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。 Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
2. 安装
下载地址:https://pypi.python.org/pypi/beautifulsoup4/4.3.2
官方文档:http://beautifulsoup.readthedocs.org/zh_CN/latest
3. 使用
from bs4 import BeautifulSoup
我们创建一个字符串,后面的例子我们便会用它来演示
html = """<html><head><title>The Dormouse‘s story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse‘s story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
创建 beautifulsoup 对象
soup = BeautifulSoup(html)
下面我们来打印一下 soup 对象的内容,格式化输出
print soup.prettify()
3.1 找标签
直接打印标签
print soup.title
#<title>The Dormouse‘s story</title>
print soup.head
#<head><title>The Dormouse‘s story</title></head>
print soup.a
#<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
print soup.p
#<p class="title" name="dromouse"><b>The Dormouse‘s story</b></p>
我们可以利用 soup加标签名轻松地获取这些标签的内容,是不是感觉比正则表达式方便多了?不过有一点是,它查找的是在所有内容中的第一个符合要求的标签
对于标签,它有两个重要的属性,是 name 和 attrs,下面我们分别来感受一下
print soup.name
print soup.head.name
#[document]
#head
soup 对象本身比较特殊,它的 name 即为 [document],对于其他内部标签,输出的值便为标签本身的名称
print soup.p.attrs
#{‘class‘: [‘title‘], ‘name‘: ‘dromouse‘}
在这里,我们把 p 标签的所有属性打印输出了出来,得到的类型是一个字典。
如果我们想要单独获取某个属性,可以这样,例如我们获取它的 class 叫什么
print soup.p[‘class‘]
#[‘title‘]
3.2 获取文字
既然我们已经得到了标签的内容,那么问题来了,我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可,例如
print soup.p.string
#The Dormouse‘s story
3.3 CSS选择器
在CSS中,标签名不加任何修饰,类名前加点,id名前加 #,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
3.3.1 通过标签名查找
print soup.select(‘title‘)
#[<title>The Dormouse‘s story</title>]
3.3.2 通过类名查找
print soup.select(‘.sister‘)
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
3.3.3 通过 id 名查找
print soup.select(‘#link1‘)
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
3.3.4 组合查找
组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开
print soup.select(‘p #link1‘)
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
3.3.5 直接子标签查找
print soup.select("head > title")
#[<title>The Dormouse‘s story</title>]
3.3.6 属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print soup.select(‘a[class="sister"]‘)
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print soup.select(‘a[href="http://example.com/elsie"]‘)
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
同样,属性仍然可以与上述查找方式组合,不在同一节点的空格隔开,同一节点的不加空格
print soup.select(‘p a[href="http://example.com/elsie"]‘)
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
以上的 select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容。
soup = BeautifulSoup(html, ‘lxml‘)
print type(soup.select(‘title‘))
print soup.select(‘title‘)[0].get_text()
for title in soup.select(‘title‘):
print title.get_text()以上是关于Python爬虫基础知识入门一的主要内容,如果未能解决你的问题,请参考以下文章