零基础Python爬虫实现(爬取最新电影排行)
Posted 夏天一去,又是冬季
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了零基础Python爬虫实现(爬取最新电影排行)相关的知识,希望对你有一定的参考价值。
提示:本学习来自Ehco前辈的文章, 经过实现得出的笔记。
目标网站
http://dianying.2345.com/top/
网站结构
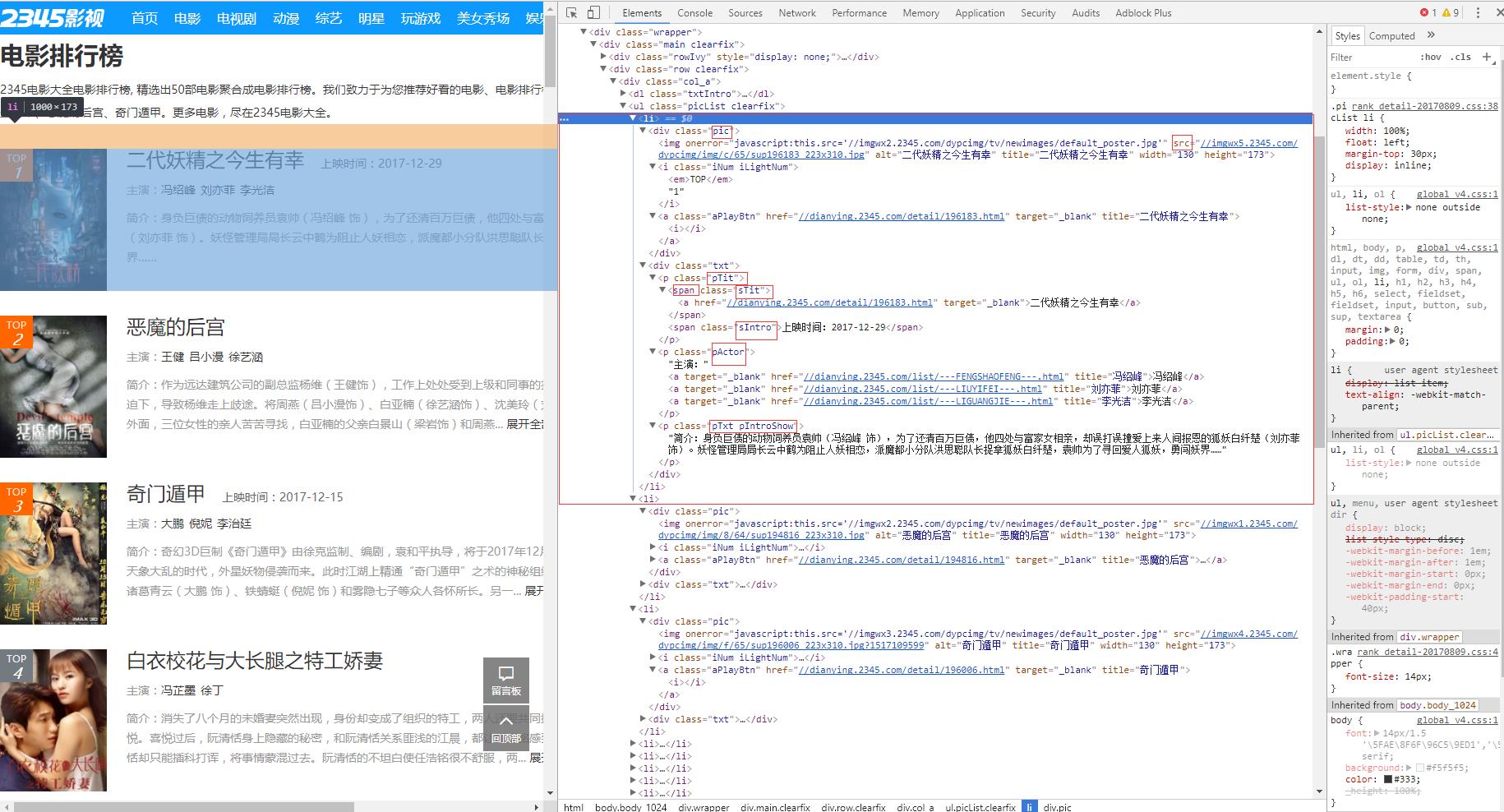
要爬的部分,在ul标签下(包括li标签), 大致来说迭代li标签的内容输出即可。
遇到的问题?
代码简单, 但遇到的问题很多。
一: 编码
这里统一使用gbk了。
二: 库
过程中缺少requests,bs4,idna,certifi,chardet,urllib3等库, 需要手动添加库, 我说一下我的方法
库的添加方法:
例如:urllib3
百度urllib3,通过链接下载到本地
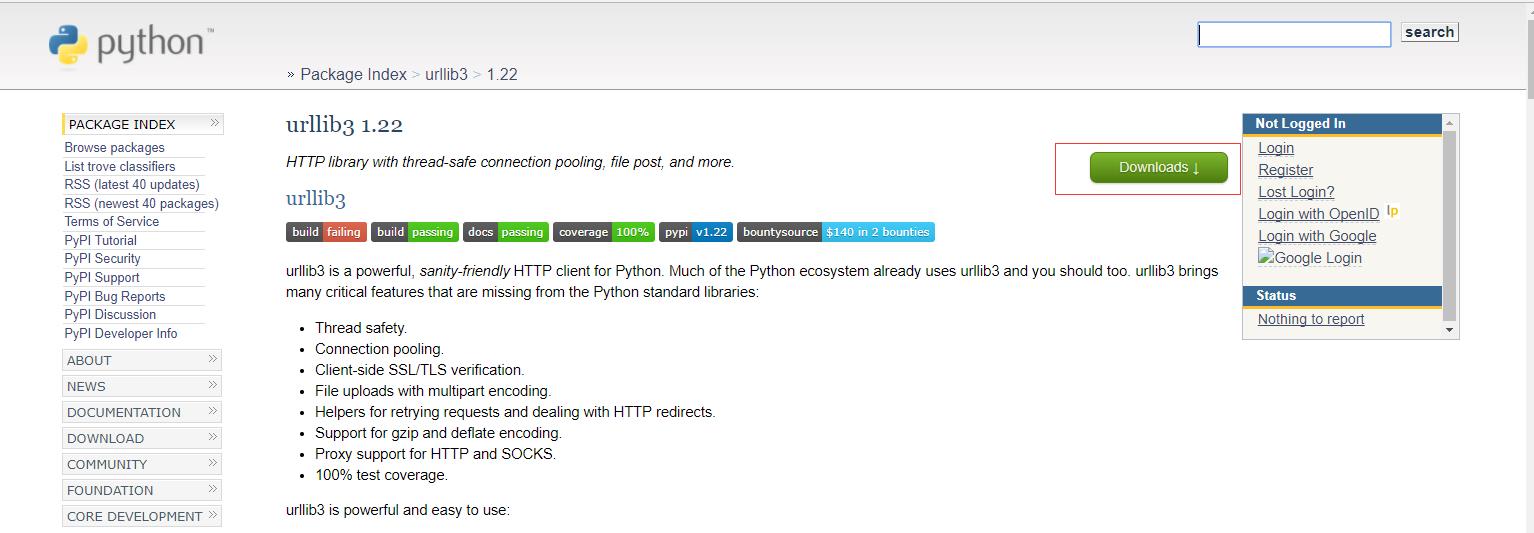
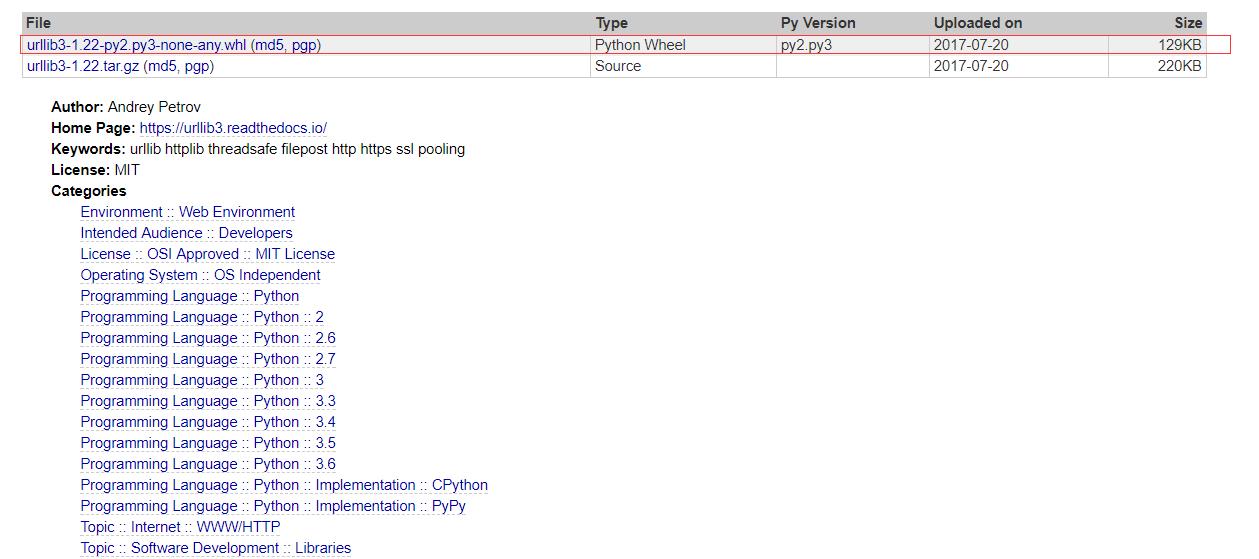
我下载第一个
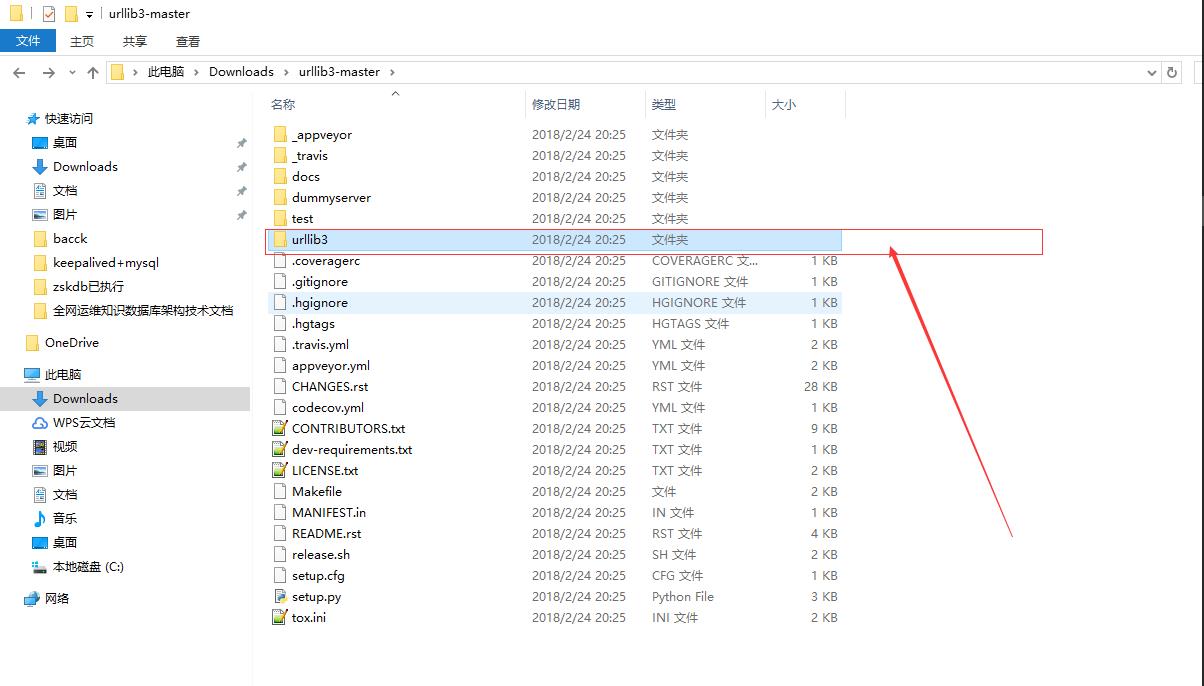
解压把urllib3文件夹扔进python安装目录的Lib目录下即可
三: 下载图片链接
这个就有意思了, 之前我是这样写的
f.write(requests.get(img_url).content)
报错
File "C:\\Users\\Shinelon\\AppData\\Local\\Programs\\Python\\Python36\\lib\\requests\\models.py", line 379, in prepare_url
raise MissingSchema(error)
requests.exceptions.MissingSchema: Invalid URL \'//imgwx5.2345.com/dypcimg/img/c/65/sup196183_223x310.jpg\': No schema supplied. Perhaps you meant http:////imgwx5.2345.com/dypcimg/img/c/65/sup196183_223x310.jpg?
Process finished with exit code 1
图片是这样的,也无法进行迭代输出下载

没办法,后来自己自动给链接加上http:
img_url2 = \'http:\' + img_url
f.write(requests.get(img_url2).content)
print(img_url2)
f.close()
然后就正常了。
附上代码
import requests
import bs4
def get_html(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status
r.encoding = \'gbk\'
return r.text
except:
return "someting wrong"
def get_content(url):
html = get_html(url)
soup = bs4.BeautifulSoup(html, \'lxml\')
movieslist = soup.find(\'ul\', class_=\'picList clearfix\')
movies = movieslist.find_all(\'li\')
for top in movies:
#爬取图片src
img_url = top.find(\'img\')[\'src\']
#爬取影片name
name = top.find(\'span\', class_=\'sTit\').a.text
try:
#爬取影片上映时间
time = top.find(\'span\', class_=\'sIntro\').text
except:
time = "暂无上映时间"
#爬取电影角色主演
actors = top.find(\'p\', class_=\'pActor\')
actor = \'\'
for act in actors.contents:
actor = actor + act.string + \' \'
#爬取电影简介
intro = top.find(\'p\', class_=\'pTxt pIntroShow\').text
print("片名:{}\\t{}\\n{}\\n{} \\n \\n ".format(name, time, actor,intro))
#下载图片到指定目录
with open(\'/Users/Shinelon/Desktop/1212/\'+name+\'.png\',\'wb+\') as f:
img_url2 = \'http:\' + img_url
f.write(requests.get(img_url2).content)
print(img_url2)
f.close()
def main():
url = \'http://dianying.2345.com/top/\'
get_content(url)
if __name__ == "__main__":
main()
结果
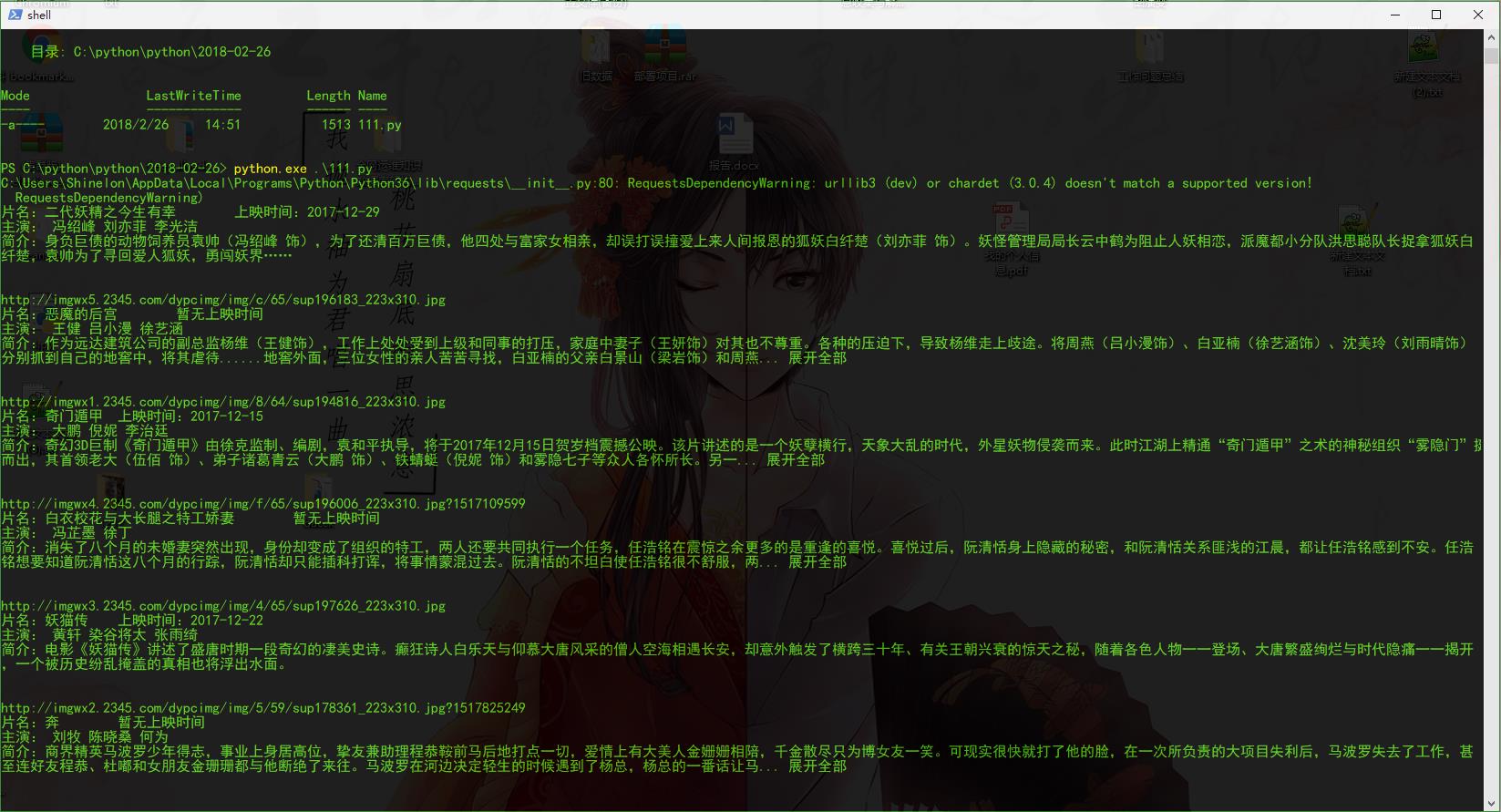
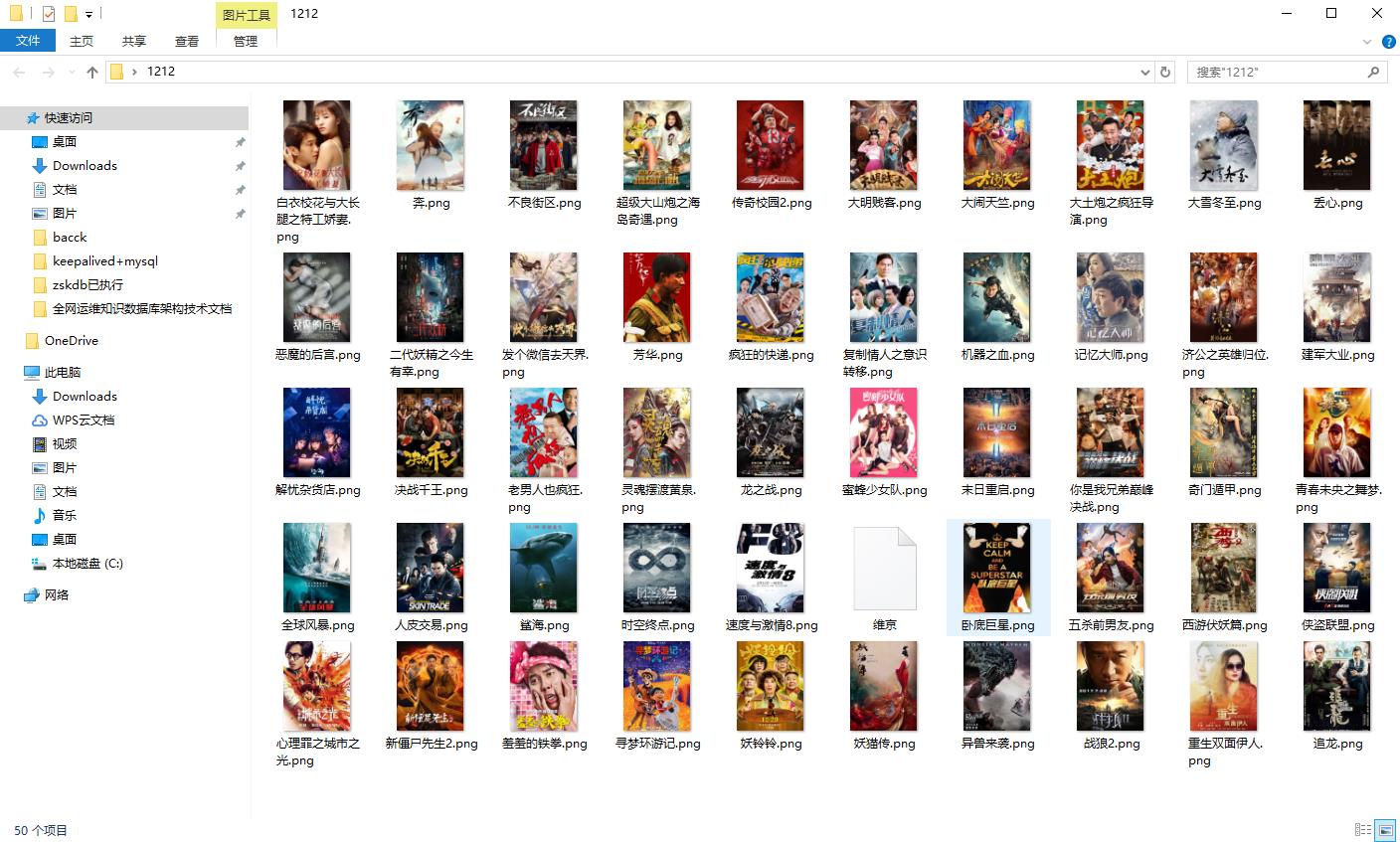
以上是关于零基础Python爬虫实现(爬取最新电影排行)的主要内容,如果未能解决你的问题,请参考以下文章